








©PaperWeekly 原创 · 作者 | 苏剑林
单位 | 追一科技
研究方向 | NLP、神经网络
对于生成扩散模型来说,一个很关键的问题是生成过程的方差应该怎么选择,因为不同的方差会明显影响生成效果。
在《生成扩散模型漫谈:DDPM = 自回归式 VAE》我们提到,DDPM 分别假设数据服从两种特殊分布推出了两个可用的结果;《生成扩散模型漫谈:DDIM = 高观点DDPM》中的 DDIM 则调整了生成过程,将方差变为超参数,甚至允许零方差生成,但方差为 0 的 DDIM 的生成效果普遍差于方差非 0 的 DDPM;而《生成扩散模型漫谈:一般框架之 SDE 篇》显示前、反向 SDE 的方差应该是一致的,但这原则上在 时才成立;《Improved Denoising Diffusion Probabilistic Models》则提出将它视为可训练参数来学习,但会增加训练难度。
所以,生成过程的方差究竟该怎么设置呢?今年的两篇论文《Analytic-DPM: an Analytic Estimate of the Optimal Reverse Variance in Diffusion Probabilistic Models》和《Estimating the Optimal Covariance with Imperfect Mean in Diffusion Probabilistic Models》算是给这个问题提供了比较完美的答案。接下来我们一起欣赏一下它们的结果。

不确定性
事实上,这两篇论文出自同一团队,作者也基本相同。第一篇论文(简称 Analytic-DPM)下面简称在 DDIM 的基础上,推导了无条件方差的一个解析解;第二篇论文(简称 Extended-Analytic-DPM)则弱化了第一篇论文的假设,并提出了有条件方差的优化方法。本文首先介绍第一篇论文的结果。
在《生成扩散模型漫谈:DDIM = 高观点 DDPM》中,我们推导了对于给定的 ,对应的 的一般解为
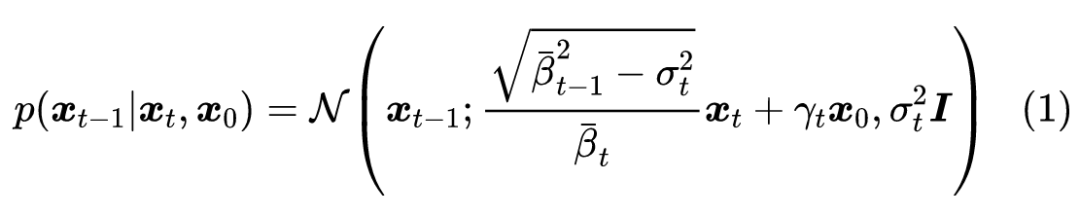
其中 , 就是可调的标准差参数。在 DDIM 中,接下来的处理流程是:用 来估计 ,然后认为
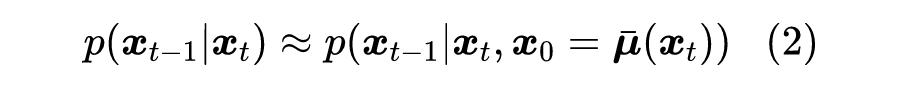
然而,从贝叶斯的角度来看,这个处理是非常不妥的,因为从 预测 不可能完全准确,它带有一定的不确定性,因此我们应该用概率分布而非确定性的函数来描述它。事实上,严格地有
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 1630
1630











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









