






 本文介绍了扩散模型的基本原理,包括其作为生成模型的角色,以及在加噪和去噪过程中的应用。文章详细讨论了加速扩散模型采样和可控生成的方法,如SDE和ODE求解器的运用,以及分类器指导和分类无关指导在条件生成中的作用。此外,还提到了未来研究方向,包括更好的模型优化和在不同领域的应用潜力。
本文介绍了扩散模型的基本原理,包括其作为生成模型的角色,以及在加噪和去噪过程中的应用。文章详细讨论了加速扩散模型采样和可控生成的方法,如SDE和ODE求解器的运用,以及分类器指导和分类无关指导在条件生成中的作用。此外,还提到了未来研究方向,包括更好的模型优化和在不同领域的应用潜力。

来源:智源社区
整理:熊宇轩
在刚刚过去的2022年,扩散模型(Diffusion Models)成为了深度生成模型中新的SOTA。近期,中国人民大学助理教授李崇轩和清华大学博士生鲍凡在由智源社区主办的“2022大模型创新论坛·峰会-模型技术分论坛”上分享了题为「扩散概率模型:原理、加速推断与可控生成」的报告,介绍了目前大火的扩散模型的基本原理。重点针对扩散模型领域的两大重点问题——「推断加速」、「可控生成」展开了讨论。同时,李崇轩和鲍凡也是ICLR2022杰出论文《Analytic-DPM: an Analytic Estimate of the Optimal Reverse Variance in Diffusion Probabilistic Models》的作者。智源社区整理主要技术内容如下:
扩散模型是一类生成模型。给定一组分布未知的数据,生成模型旨在刻画出其底层的数据分布。具体而言,我们设置参数化的模型,并最小化真实数据与生成数据分布之间的散度估计模型参数,近似未知的数据分布。在物理学领域中,扩散过程会将结构逐渐破坏。例如,染料逐渐从有序状态变为无序状态。这一过程的逆过程可以被看作对结构的恢复。

在扩散模型中,扩散过程对应于向原始数据分布添加马尔科夫高斯噪声,而恢复结构的过程则对应于从高斯先验出发,学习去躁/生成数据,从而对数据分布建模。
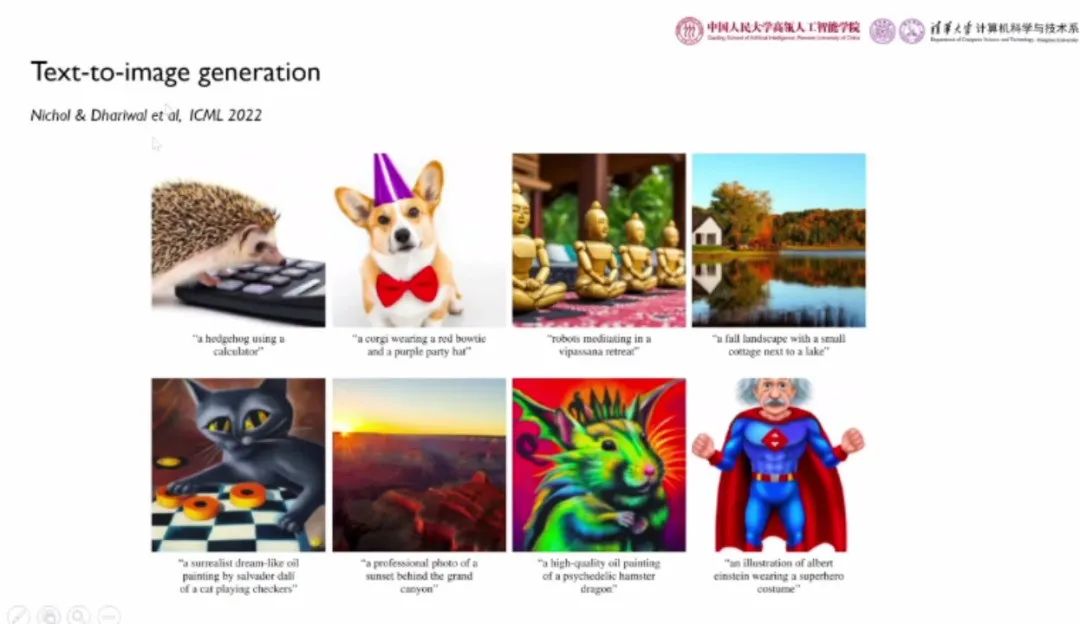
目前,扩散模型已经被广泛应用于“图文生成”、“视频生成”、“3D场景生成”、“分子结构生成”等技术,服务于“AI绘画”、“封面制作”、“AI制药”等业务场景。
“
扩散模型:基本原理

Sohl-Dickstein 等人在 ICML 2015 上首次提出了扩散概率模型。扩散概率模型的前馈扩散过程是一个采用高斯核的马尔科夫链,包含超过 1000 个状态。每一步的状态转移方程是一个线性的高斯函数,其中 为高斯噪声方差的大小。当加入噪声的步骤累计足够多时,修改后的数据可以被视为标准的高斯噪声。
为高斯噪声方差的大小。当加入噪声的步骤累计足够多时,修改后的数据可以被视为标准的高斯噪声。

我们希望通过模型近似扩散过程的逆过程,实现去躁的效果。由扩散模型的数学性质可知,当每一步加入的噪声足够小时,前向加噪和反向去躁过程具有相同的概率分布形式。
因此,我们仍然将反向扩散过程建模为采用高斯核的马尔科夫链,高斯函数的均值和协方差通过以时间为条件的神经网络被参数化。网络的输入为当前的状态 和时间节点 t,第 t 时刻的状态
和时间节点 t,第 t 时刻的状态 通过共享参数的若干卷积层提取特征,基于该特征用两个不同的预测分支分别输出高斯函数的均值和方差。
通过共享参数的若干卷积层提取特征,基于该特征用两个不同的预测分支分别输出高斯函数的均值和方差。

原始的扩散模型采用极大似然估计作为目标函数来训练,由于无法直接计算边缘概率,这里我们采用变分的证据下界 ELBO。其中变分后验对应于扩散模型的前向加噪过程,生成模型对应于逆向的马尔科夫链。值得一提的是,变分自编码器(VAE)中的变分后验是可学习的,而扩散模型中的变分后验是固定的前向过程。因此,可以将扩散概率模型看做具有固定变分后验的层次化隐变量模型。

ELBO 可以被分解为如上图所示的形式,包含 T 个 KL 散度之和。然而,直接对其进行每一次更新的时间复杂度为 O(T)。为了降低计算开销,我们将 KL 散度之和视为期望,并每次随机选择其中的一项进行优化,从而将时间复杂度降低为 O(1)。KL 散度中的 p 和 q 两项都是高斯分布,可以将 q 改写为如上图中绿色部分的封闭形式,采用回归目标函数学习。原始的扩散概率模型的生成效果并不理想,对轮廓、细节、结构的建模有待提高。
“
DDPM:去躁扩散概率模型
在 NeurIPS 2021 上,Jonathon 等人发表了论文《Denoising diffusion probablistic models》。对扩散概率模型进行了如下改进,大大提升了模型的生成效果:使用固定的方差归回均值;用 和噪声表示
和噪声表示 ,通过均值预测网络重参数化
,通过均值预测网络重参数化 ,将关于均值的差
,将关于均值的差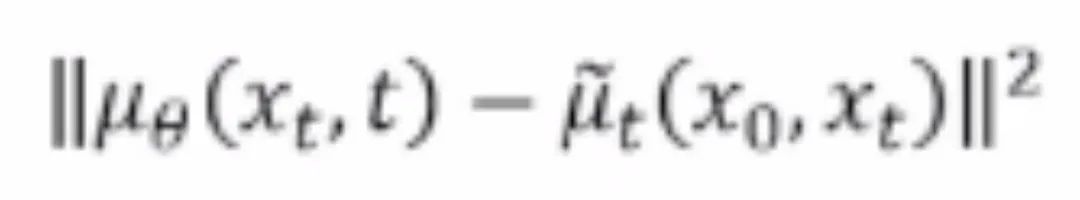 改写为噪声预测网络与噪声的差
改写为噪声预测网络与噪声的差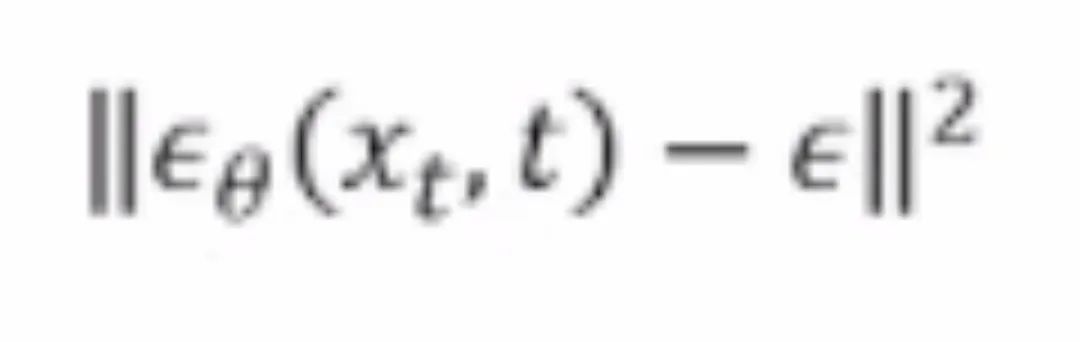 ,将目标函数改写为噪声预测的形式;对高斯噪声进行回归预测。值得一提的是,噪声预测的目标函数与去躁得分匹配(DSM)技术具有等价关系。
,将目标函数改写为噪声预测的形式;对高斯噪声进行回归预测。值得一提的是,噪声预测的目标函数与去躁得分匹配(DSM)技术具有等价关系。
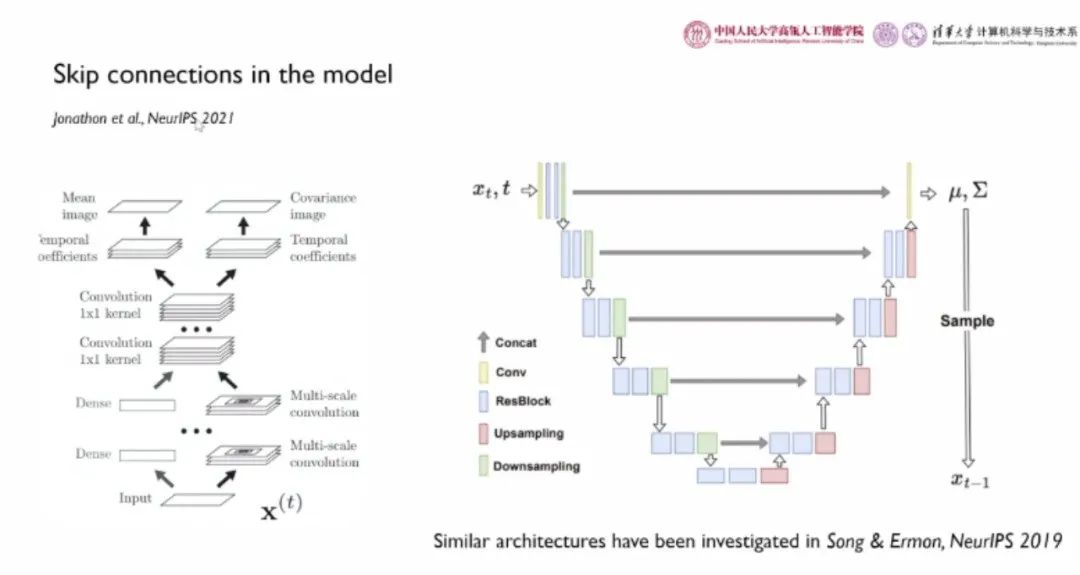
除此之外,DDPM 对扩散模型的架构也进行了相应改进。DDPM 采用了 U-net 形式的架构,引入了跳跃链接,将底层特征用于较深的层,更加适用于像素级别的预测任务,大大提升了模型性能。
此后,Song 等人在 ICLR 2021 上将扩散模型的前向扩散过程从离散时间拓展为连续时间。具体而言,他将前向过程重参数化为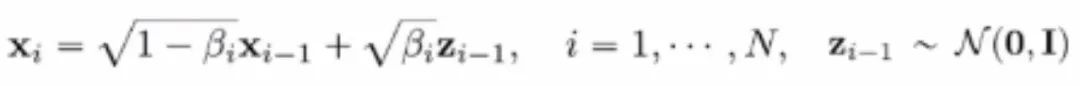 的迭代形式。
的迭代形式。
通过标准化处理后进一步将上式改写为离散化格式:
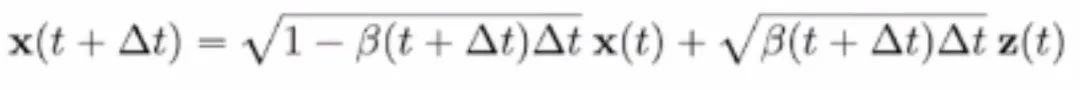
通过对时间步长取极限,我们得到:
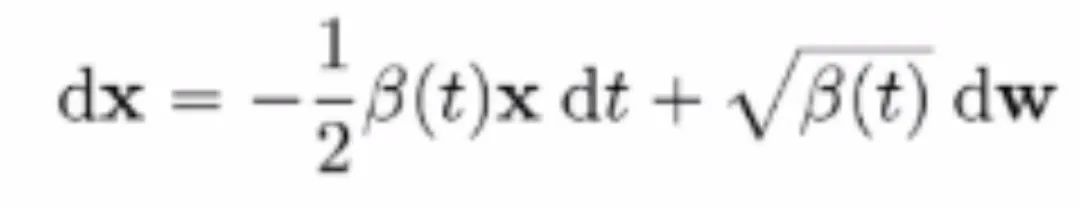
类似地,通过对扩散过程的逆过程进行时间上的连续化,得
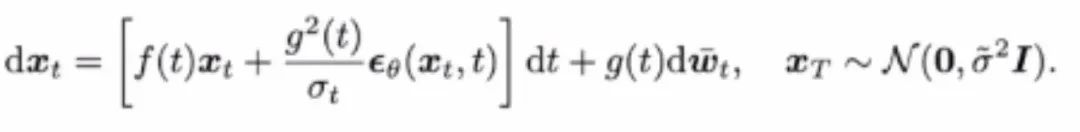
通过对目标函数进行时间上的连续化,目标函数会变成关于 t 的积分:
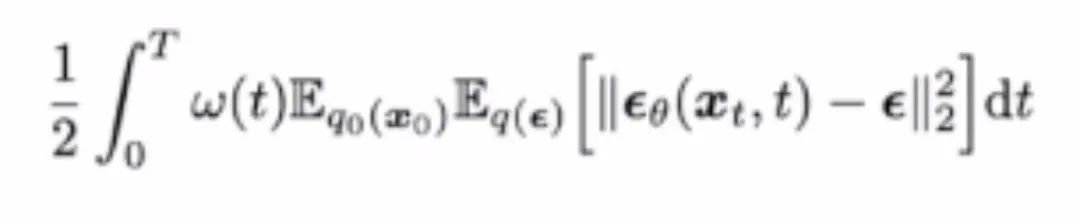
“
隐扩散模型
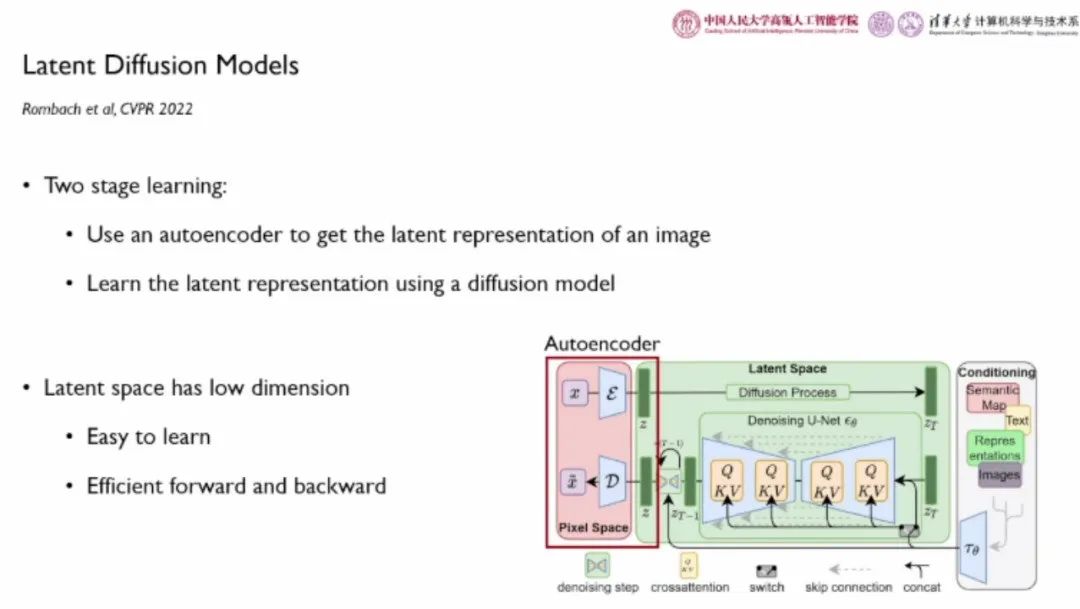
“隐扩散模型”在图像建模策略上进行了改进,它首先使用自编码器获取图像的高质量隐式表征 z,而非直接建模图像的像素。接着,使用扩散模型学习改表征。这里的隐空间维度较低,易于学习,其前馈和反向传播过程效率较高。目前大火的“Stable Diffusion”项目正是以隐扩散模型为基础。

Karras 等人在 NeurIPS 2022 上发表的论文“Elucidating the Design Space of Diffusion-Based Generative Models”将各种扩散模型统一在了同一个框架下。其中,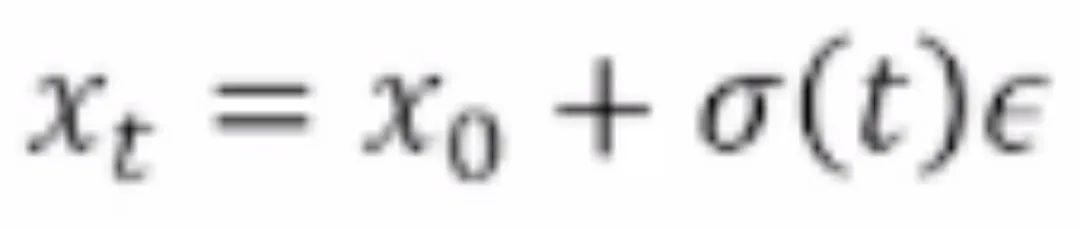 作者使用去躁函数
作者使用去躁函数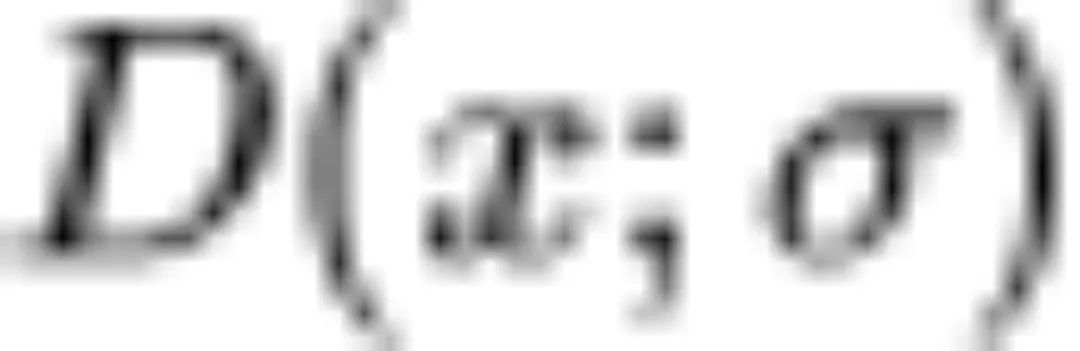 在给定
在给定 的情况下预测
的情况下预测 。去躁函数包含超参数
。去躁函数包含超参数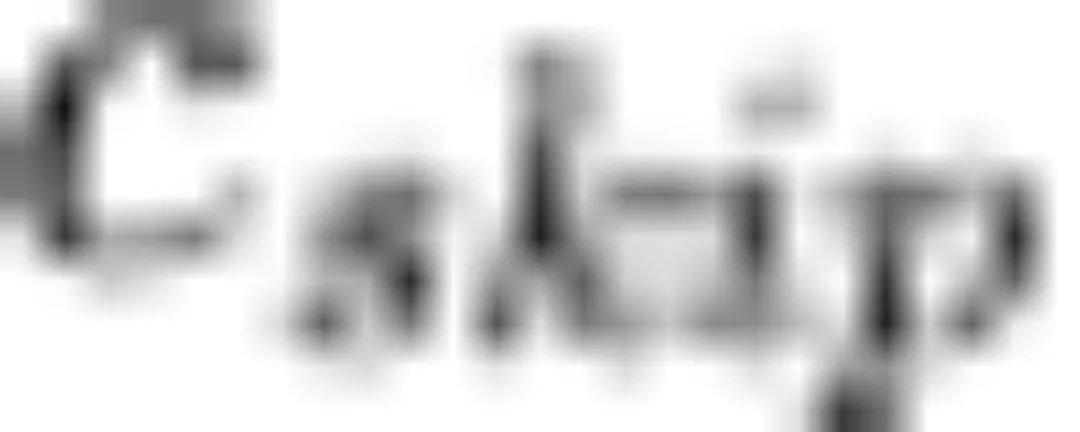 、
、 、
、 、
、 ,它们都是关于当前噪声的函数。通过选取不同的超参,可以恢复出已有的各种扩散模型。为了选取最合适的超参数,作者设计了一套基于数值稳定性的选择算法。
,它们都是关于当前噪声的函数。通过选取不同的超参,可以恢复出已有的各种扩散模型。为了选取最合适的超参数,作者设计了一套基于数值稳定性的选择算法。
“
扩散模型的采样加速

尽管扩散模型可以取得目前最优的生成效果,但是其逐步去噪的采样过程涉及非常多的迭代步骤。以 DDPM 模型为例,需要 1000 次函数估计进行采样。为此,加速扩散模型的采样成为了一项十分重要的研究课题。
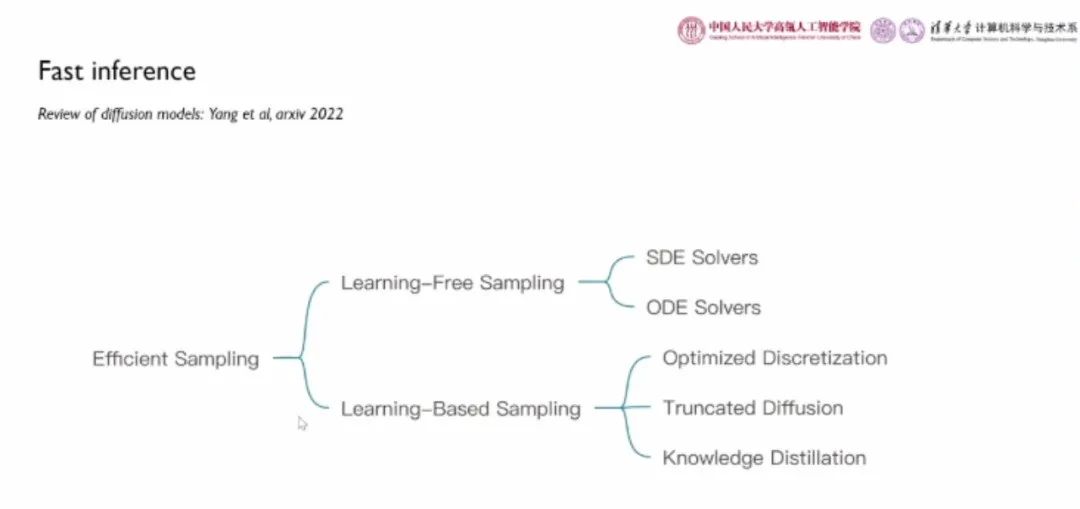
扩散模型的加速算法大致分为两种:
(1)无需额外学习的采样:直接针对给定的扩散模型,修改采样算法,包括随机微分方程(SDE)求解器、常微分方程(ODE)求解器;
(2)基于学习的采样:包括优化的离散化技术、截断扩散、知识蒸馏。
“
基于 SDE 求解器的扩散模型采样加速

DDPM 采用了手动的方式,考虑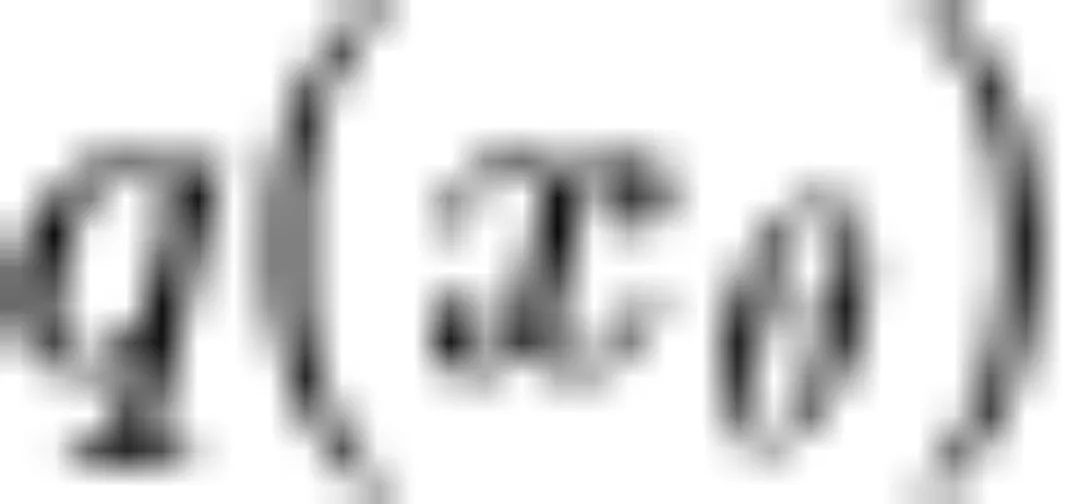 的极端情况选择方差
的极端情况选择方差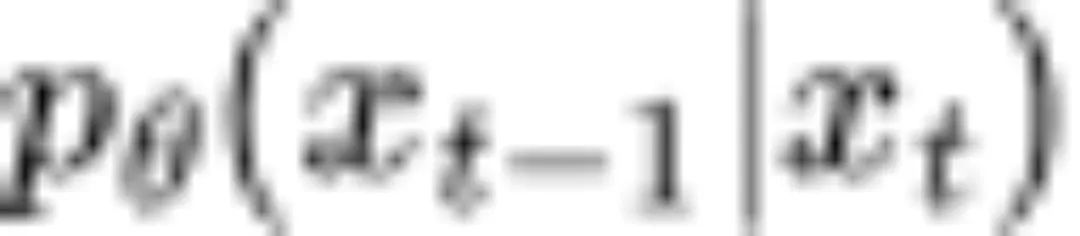 。而 OpenAI 则提出了一系列通过神经网络学习方差的工作,例如 NeurIPS 2021 的工作《Diffusion Models Beats GANs on Image Synthesis》。然而,从理论上说,最优的协方差存在解析解,可以直接求得。
。而 OpenAI 则提出了一系列通过神经网络学习方差的工作,例如 NeurIPS 2021 的工作《Diffusion Models Beats GANs on Image Synthesis》。然而,从理论上说,最优的协方差存在解析解,可以直接求得。

清华大学博士生鲍凡、中国人民大学李崇轩和合作者提出的「Analytic-DPM」(ICLR 2022 杰出论文奖)发现最优的均值和方差都由评分函数唯一决定,评分函数可以被视为噪声预测网络的等效表示。推导过程中用到的主要技术包括:
(1)矩匹配:用高斯分布近似目标分布等价于对分布 p 和 q 进行矩匹配;
(2)全方差公式:条件期望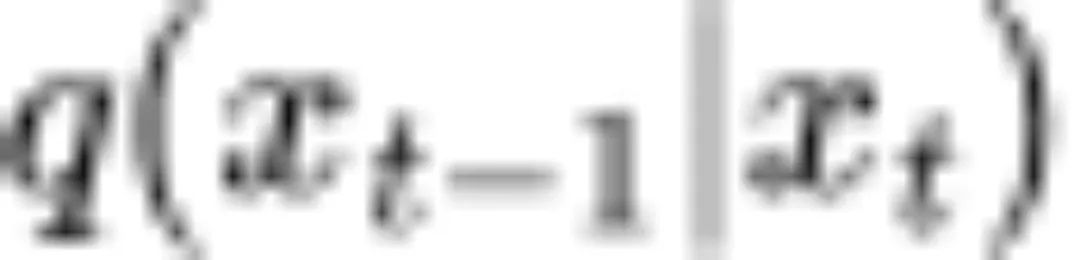 可以由条件期望
可以由条件期望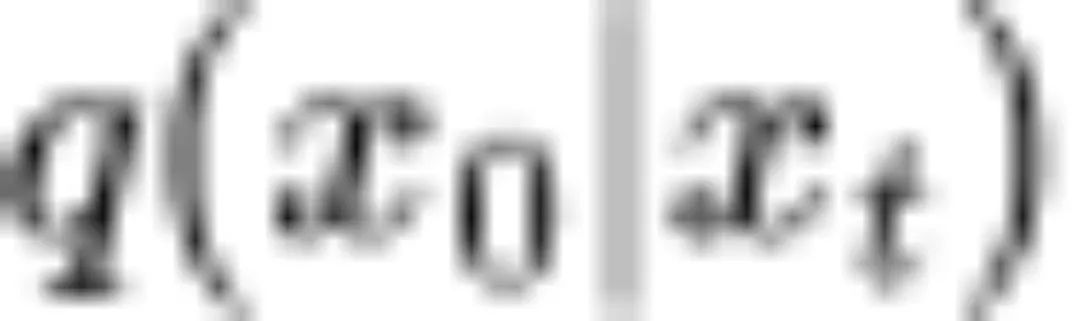 表示;
表示;
(3)当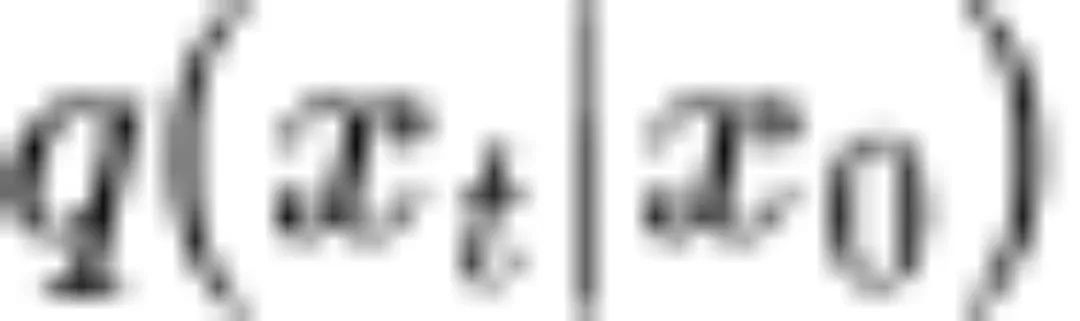 为高斯分布时,条件期望
为高斯分布时,条件期望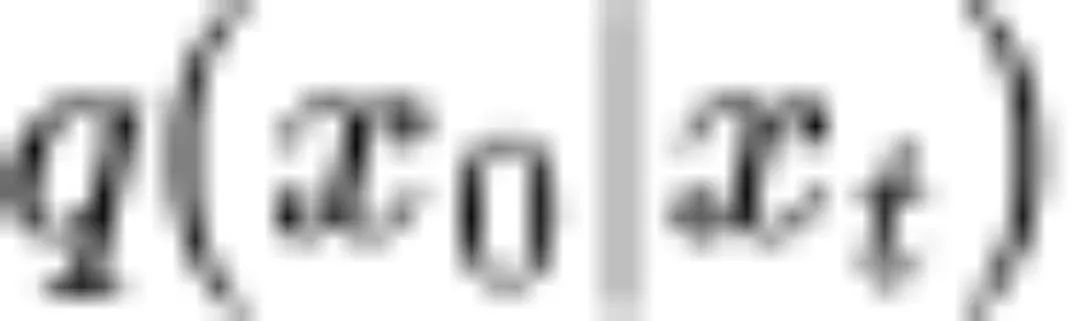 可以由评分函数
可以由评分函数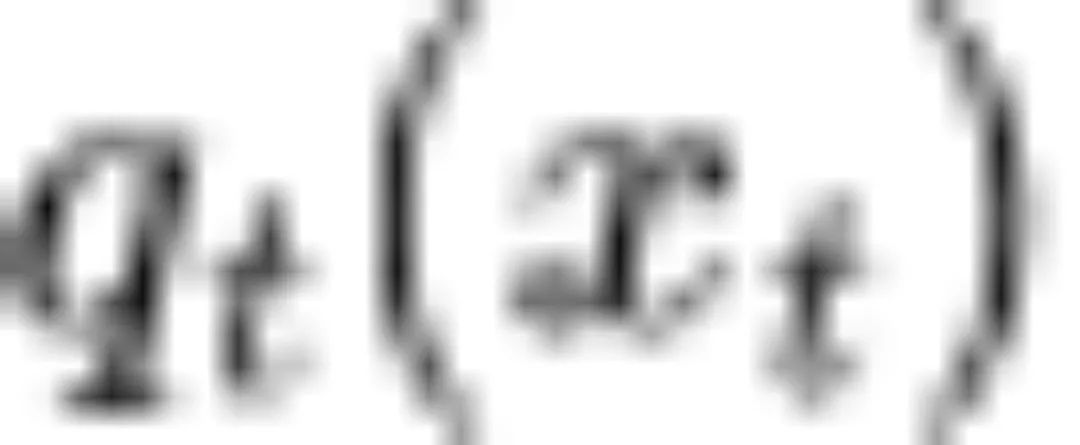 表示。
表示。
最优均值和方差与先前的参数化工作在形式上保持一致。从理论上说,最有均值和方差存在由评分函数决定的解析表达式。我们可以在无需额外训练的情况下,直接估计最优方差。
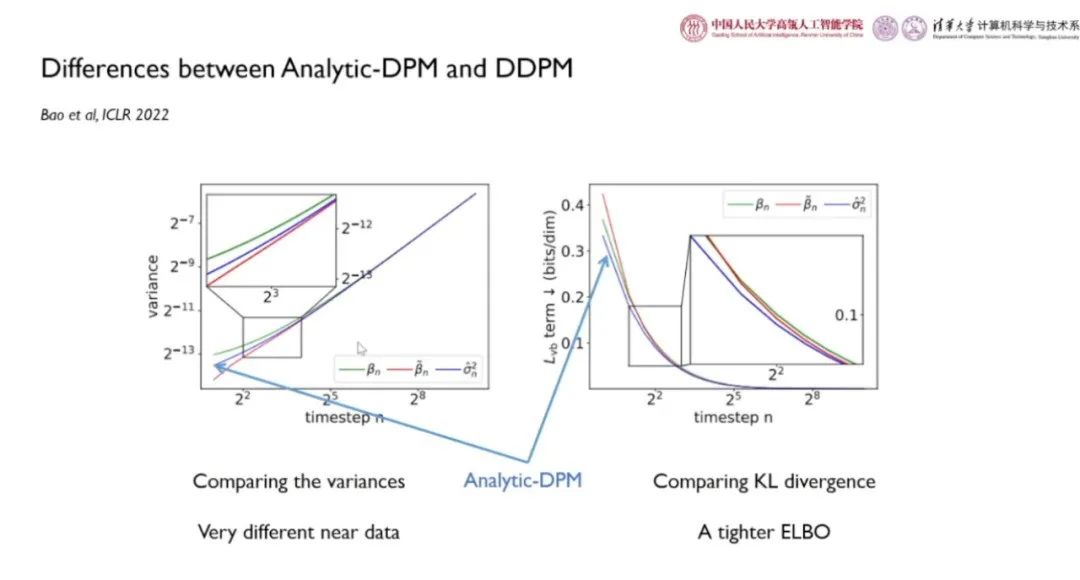
「Analytic-DPM」得到的方差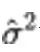 介于 DDPM 提出的
介于 DDPM 提出的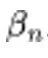 与
与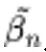 之间。在时间步较小时,
之间。在时间步较小时,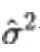 逐渐发散。使用最优方差后,似然得到了有效降低,模型效果更佳。
逐渐发散。使用最优方差后,似然得到了有效降低,模型效果更佳。

如上图所示,「Analytic-DPM」经过 50 步采样的效果优于 DDPM 采样 1000 步的效果,加速了近 20 倍。「Analytic-DPM」发布后,OpenAI 改变了 DALL·E2 模型处理方差的策略。
“
基于 ODE 求解器的扩散模型采样加速

通过时间连续化技术,我们可以在训练 DDPM 时进行随机微分方程建模。其中, 、
、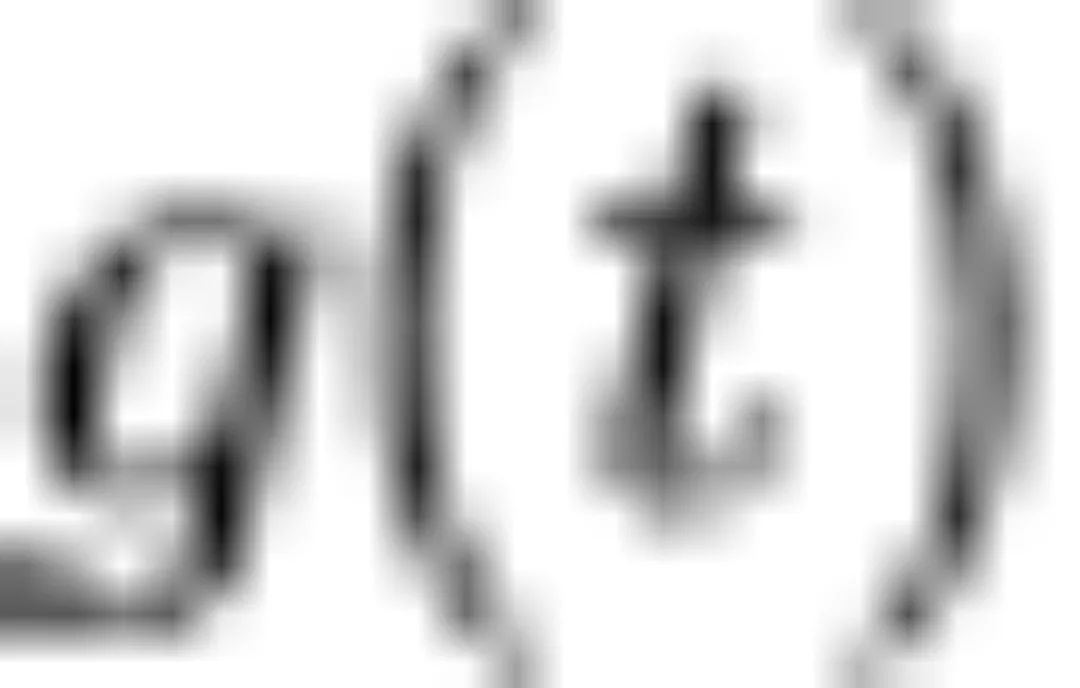 为可逆的线性函数,只有噪声预测网络是可学习的。我们可以通过随机微分方程的逆过程进行扩散模型的采样。DDPM、Analytic-DPM 都属于扩散随机微分方程形式的离散化。与每一个扩散随机微分方程离散化模型相对应,我们可以通过转化各组件,去掉布朗运动的随机游走项,得到一个等价的常微分方程形式。
为可逆的线性函数,只有噪声预测网络是可学习的。我们可以通过随机微分方程的逆过程进行扩散模型的采样。DDPM、Analytic-DPM 都属于扩散随机微分方程形式的离散化。与每一个扩散随机微分方程离散化模型相对应,我们可以通过转化各组件,去掉布朗运动的随机游走项,得到一个等价的常微分方程形式。
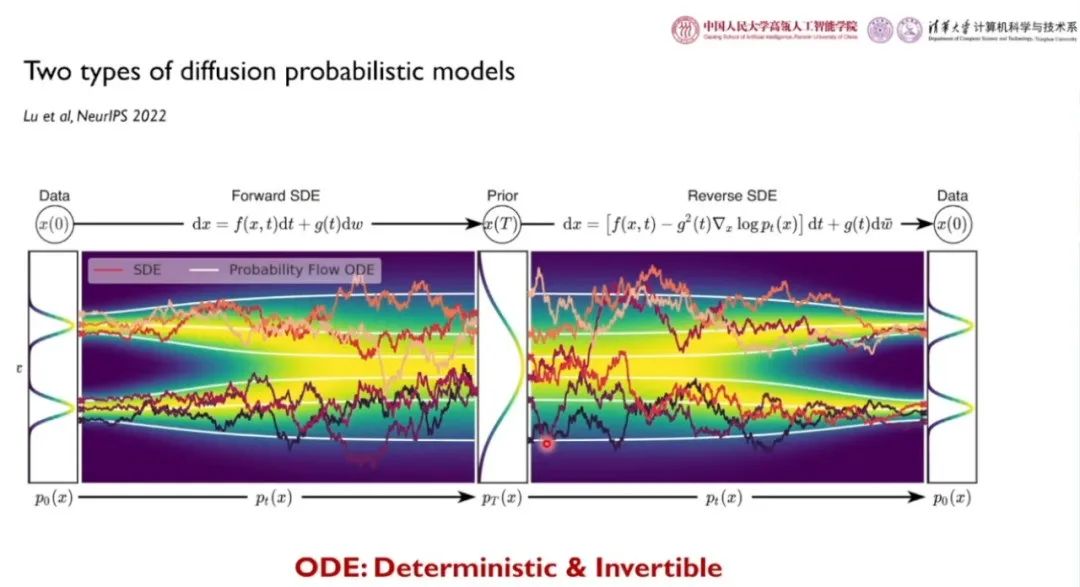
如上图所示,由于布朗运动随机游走项的存在,通过 SDE 采样得到的彩色轨迹抖动较为剧烈;而通过等价的 ODE 采样得到的白色曲线较为平缓,确定性较高。

DDIM 模型可以被视为扩散 ODE 的一阶离散化。当我们对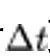 取极限时,得到 DDIM 更新过程的连续化形式为确定性的扩散 ODE。我们认为,当扩散模型被训练好之后,做采样的加速等价于对确定的 ODE 做离散化。
取极限时,得到 DDIM 更新过程的连续化形式为确定性的扩散 ODE。我们认为,当扩散模型被训练好之后,做采样的加速等价于对确定的 ODE 做离散化。

对 ODE 进行离散化是一个经久不衰的研究课题。然而,实验结果表明,直接将 Runge-Kutta 方法应用于 DPM 的离散化误差较大,收敛速度较慢。这是因为,该方法将 DPM 定义的 ODE 整体作为黑盒作近似,忽略掉了线性部件的内在结构。

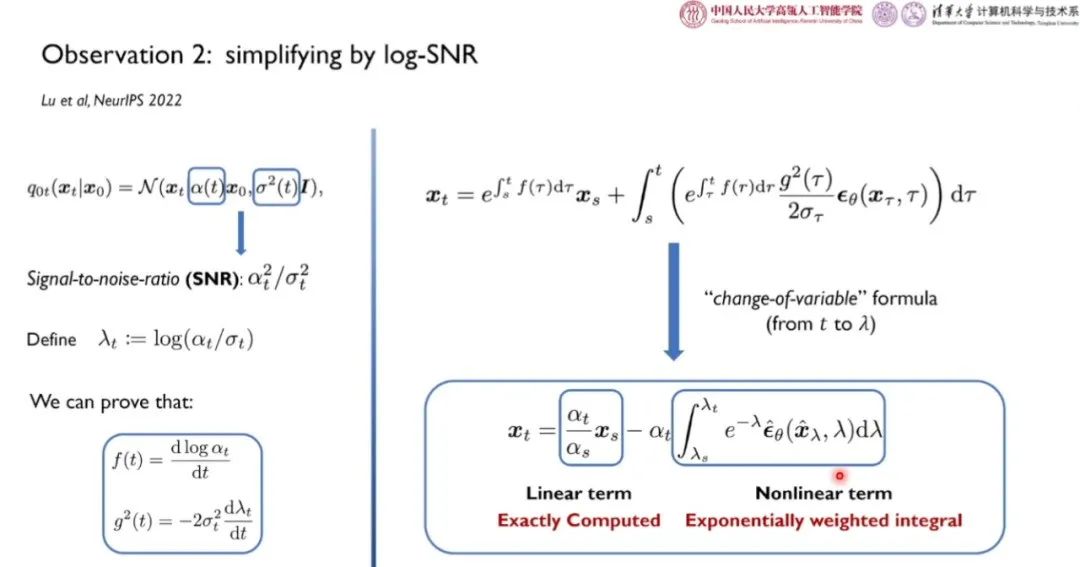
为此,清华大学路橙、中国人民大学李崇轩和合作者考虑尽量利用扩散 ODE 具有的特殊性质,尽可能求得能够化简、求出闭式解的部分,对神经网络部分做数值差分近似等操作,降低离散化误差。如上图所示,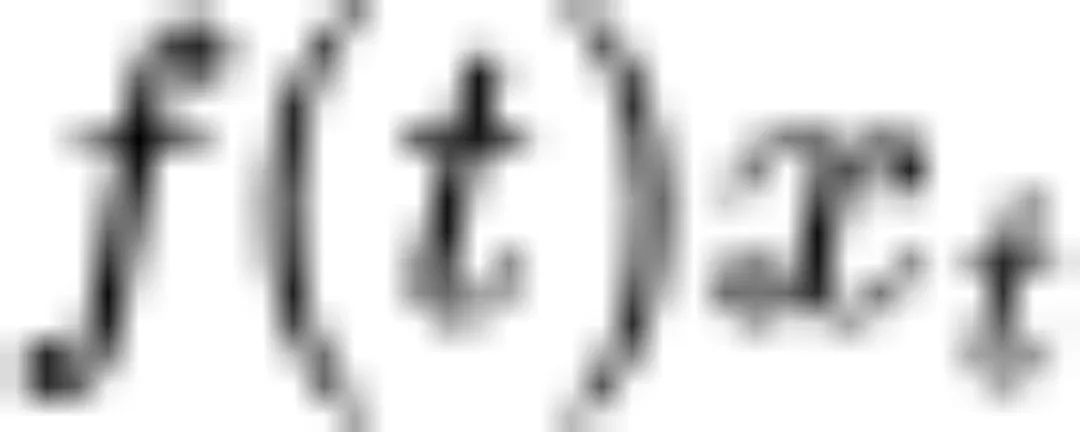 为线性项,可以通过「带数变值法」得到其闭式解。而噪声预测网络的积分无法直接求得。
为线性项,可以通过「带数变值法」得到其闭式解。而噪声预测网络的积分无法直接求得。
在扩散模型的前馈传播过程中,会将原始数据乘以小于 1 的因子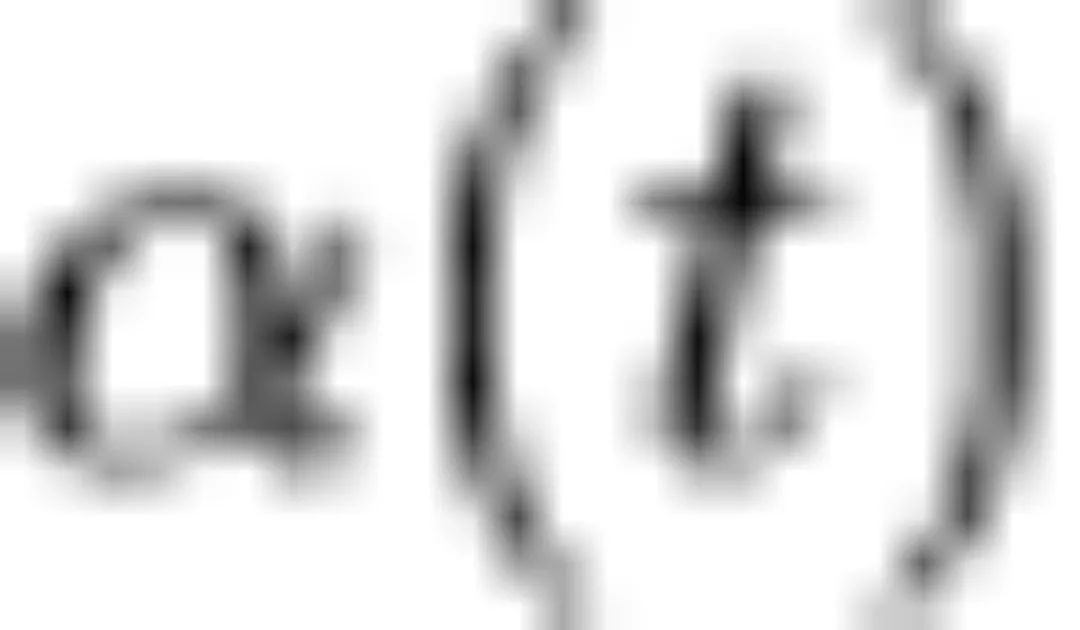 ,该值与信号的大小正相关,
,该值与信号的大小正相关,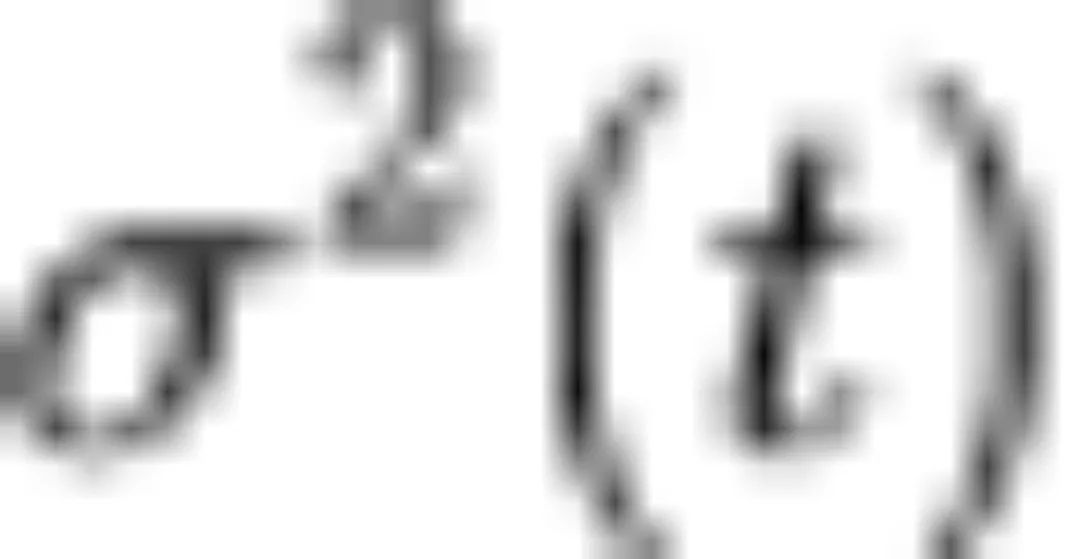 为高斯噪声的方差,表征噪声的大小。信噪比SNR为
为高斯噪声的方差,表征噪声的大小。信噪比SNR为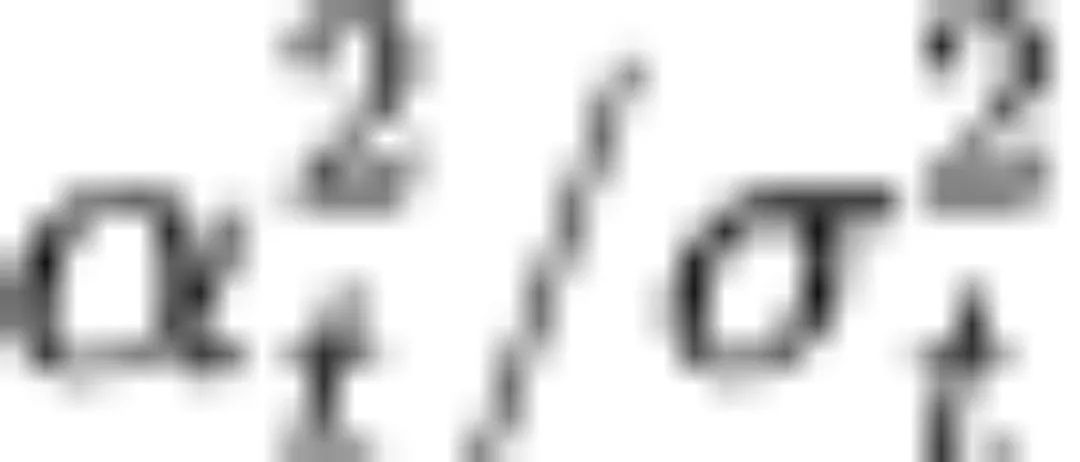 。基于 log-SNR 变换,我们可以将扩散 ODE 中噪声预测网络的求解转化为求解对数信噪比的形式。如上图所示,扩散 ODE 的第一项线性项为闭式解,第二项非线性项为指数加权积分。
。基于 log-SNR 变换,我们可以将扩散 ODE 中噪声预测网络的求解转化为求解对数信噪比的形式。如上图所示,扩散 ODE 的第一项线性项为闭式解,第二项非线性项为指数加权积分。
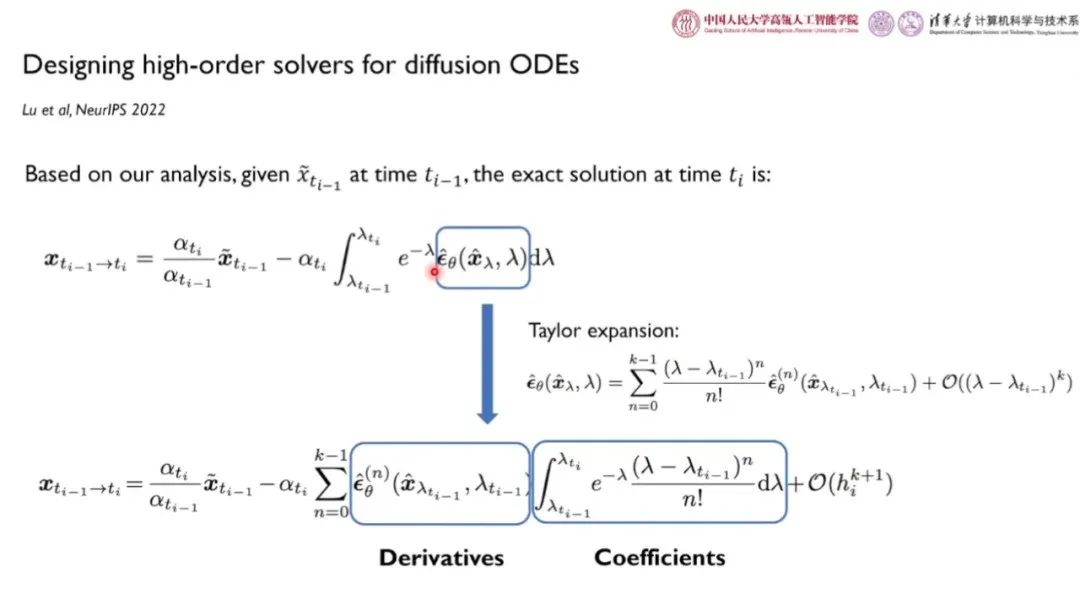
通过对非线性项做泰勒展开,泰勒展开的多项式系数与指数项做分部积分,可以得到系数项的闭式解。而神经网络的 n 阶导数只能通过差分近似等方式求得。
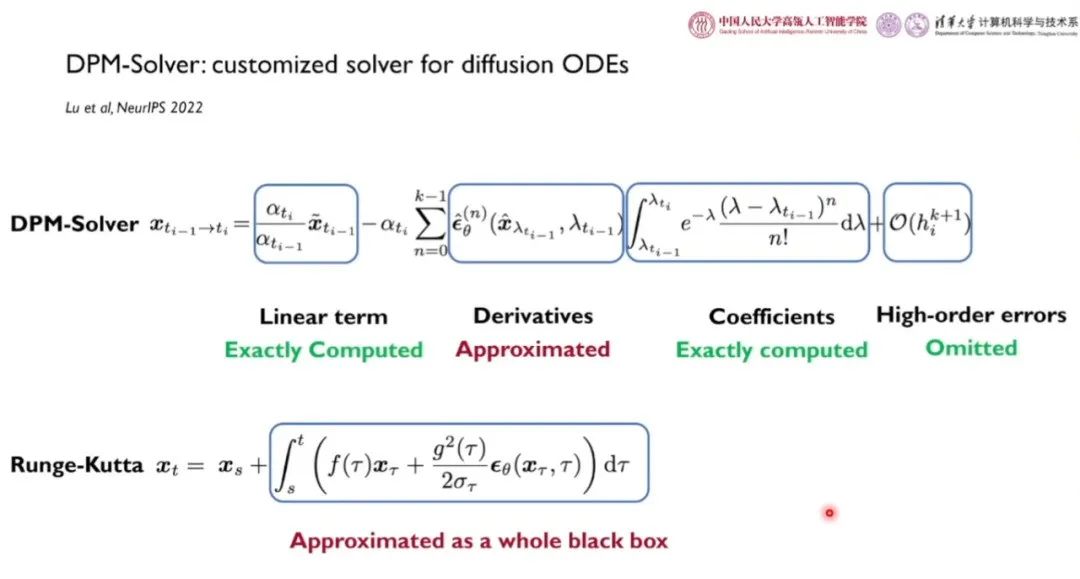
利用半线性性质、log-SNR 换元得到的简洁形式,求解线性项、系数项的闭式解,求出神经网络梯度的差分近似,我们得到了如上图所示的 DPM 求解器。与基于 Runge-Kutta 方法相比,我们充分利用了扩散 ODE 的性质。

「质量-效率」的权衡实验如上图所示,清华大学路橙、中国人民大学李崇轩和合作者提出的 DPM-Solver 能够以较少的计算开销得到较高的图像生成质量。通过将 DPM-Solver 加入到 stable-diffusion 模型中,可以经过 15-20 步迭代获得与原始模型迭代 1000 步相近的图像生成效果;出图延时从 8s 降低到了 4s。目前,DPM-Solver 已经成为了 Diffusers、Stable Diffusion v1&v2、Stable-diffusion-WebUI 等开源大模型的默认采样方法。基于 DPM-Solver 的 stable diffusion 模型的演示样例链接如下:
https://huggingface.co/spaces/LuChengTHU/dpmsolver_sdm
“
扩散概率模型的可控生成

在实际应用场景下,带条件的生成式模型往往具有更大的实用意义。例如,在「AI 绘画」等「文-图生成」任务中,我们需要给定相应的主题或故事,即我们需要基于成对数据训练一个条件分布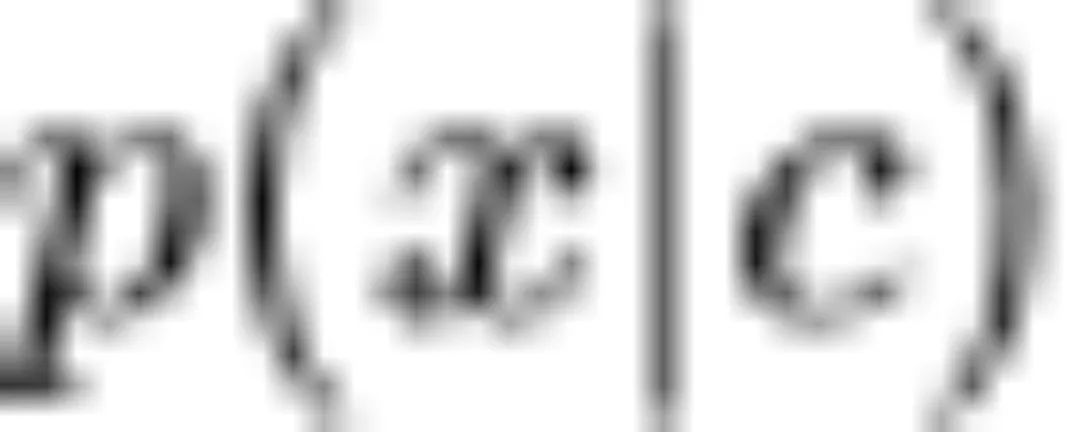 。
。
“
分类器指导

当在训练中没有成对数据时,只能训练无条件的扩散模型。在测试时,分类器指导方法旨在将无条件的扩散模型转化为有条件的模型。此外,扩散模型的规模往往较大,训练往往较为耗时。一些研究者在模型微调时面临缺乏数据和训练资源的窘境。我们也可以考虑利用先验条件实现预训练模型的高效迁移。
通过对贝叶斯公式取对数并对 x 求导,我们得到:
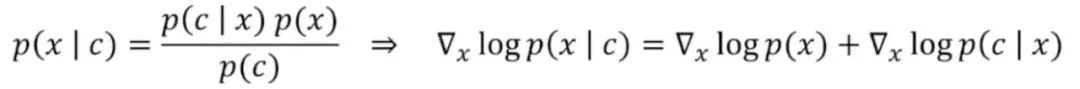
通过引入分类器与某个因子的乘积,我们得到分类器指导。此时,采样方向可以表示为预训练模型和温度系数与预训练分类器乘积之和(预训练扩散模型和预训练分类器单独训练):
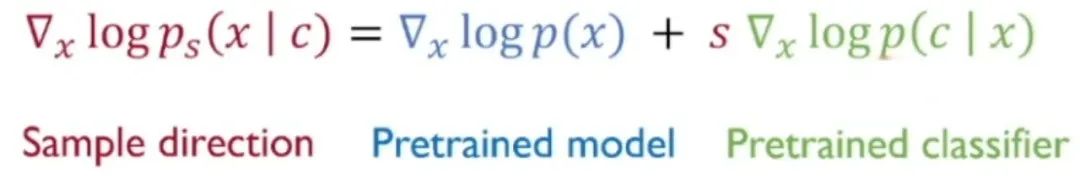
上式可以转化为噪声预测网络的形式,并延时间 t 进行迭代,在每个时间步上提供分类器指导:

有趣的是,当 s 较大时,上述方法可以很好地权衡生成质量和可控性,甚至当预训练扩散模型本身为条件评分函数时,加入分类器指导仍然有助于提升生成图像和对应条件之间的匹配度。
“
分类无关指导

「分类无关指导」旨在不训练分类器的情况下提升生成图像和条件之间的匹配程度的权衡,即仅仅利用评分函数近似分类器。为此,我们反向利用贝叶斯法则,对其取对数,并对 x 求梯度。我们发现,分类器项可以由条件评分函数和评分函数之差表示。通过将该式代入分类器指导中,我们得到:
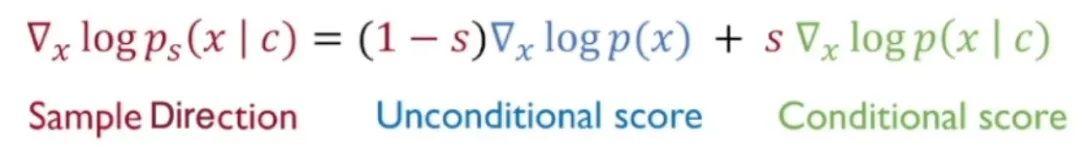
当 s 较大时,我们在训练时随机丢掉某些类别训练无条件评分函数,在不丢掉类别的情况下训练条件评分函数,上述两个模型可共享参数,一同训练。这二者之差可以替代分类器。

分类无关指导相较于分类器指导的优势在于:分类器和评分函数分开训时,二者的梯度大小有显著区别,稳定性较差,参数也更多。而分类无关指导中的条件评分函数和非条件评分函数的梯度较为一致,也可以节省参数量。目前,分类无关指导成为了「图文生成」等任务的常用技术之一。
“
分类标签之外的条件
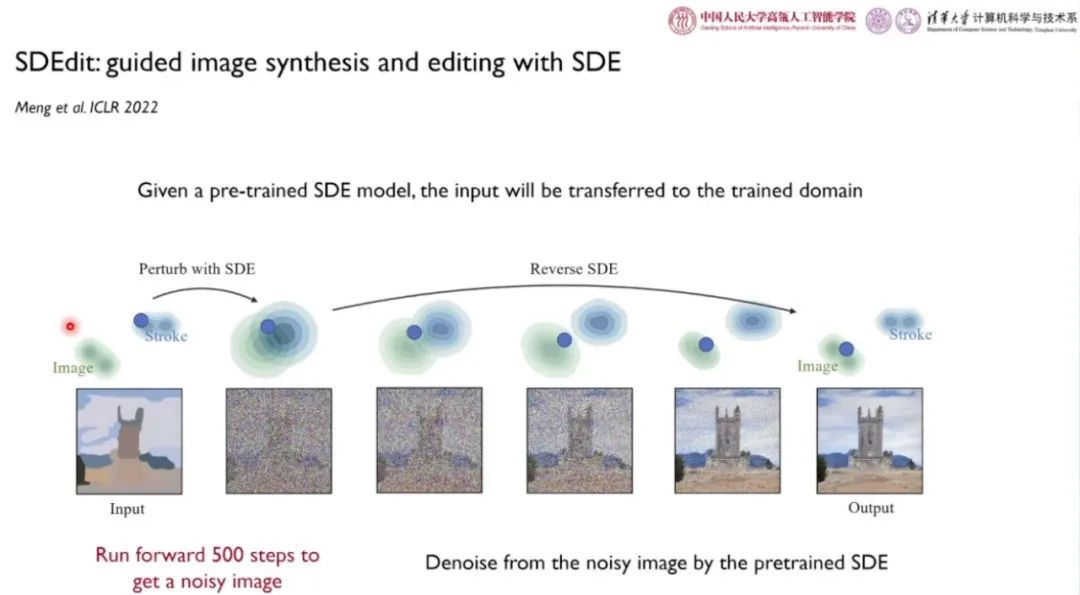
Meng 等人于 ICLR 2022 发表的 SDEdit 旨在为图到图的转换任务提供指导。给定一个预训练的 SDE 模型,输入的相关域中的图片会被迁移到训练的目标域中。具体而言,对于给定的草图,我们使用训练好的 SDE 过程迭代 500 步加入噪声,得到带噪声的图像(而非完全的高斯噪声)。此时的图像仍然带有一些语义信息,而局部细节信息被高频信号噪声「污染」。接着,我们对带噪声的图片执行反向 SDE 去躁,从而生成图像。

Amir 等人提出的「Prompt-to-prompt image editing with cross attention control」通过修改 cross-attention 模块控制修改的 prompt 的语义。在 cross-attention 模块中,有一些特征图对某些确定的语义有较强的激活,通过替换特定的语义对应的特征图,得到修改后的 prompt,实现图像生成中的语义保留。如上图所示,将「Photo of a cat riding on a bicycle」中的 bicycle 替换为 car,可以将图中的自行车修改为汽车的模样。
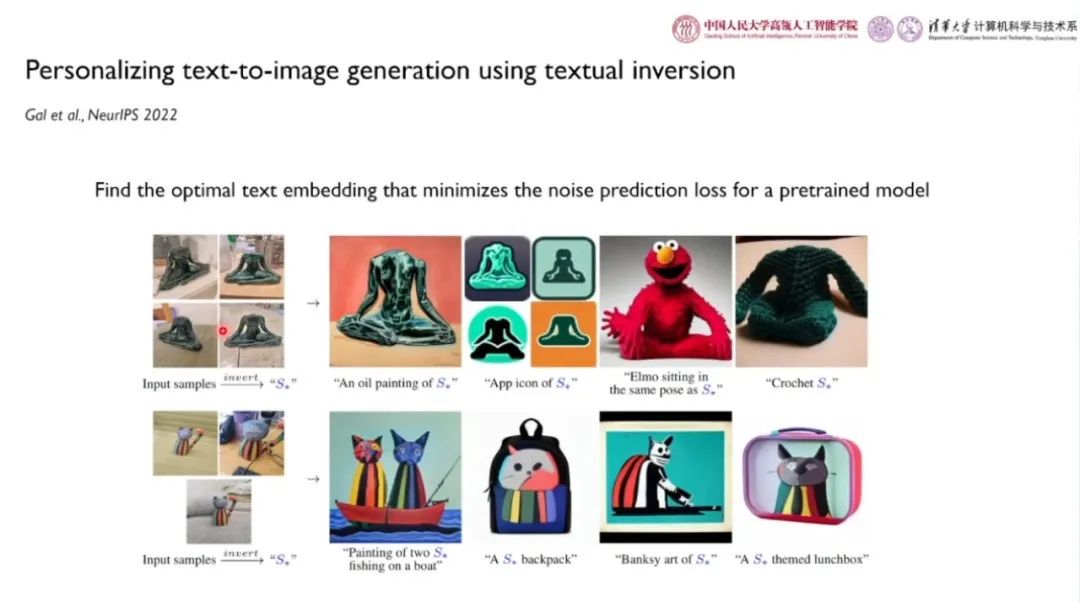
Gal 等人在 NeurIPS 2022 发表的论文「Personalizing text-to-image generation using textual inversion」提出能够找到最优的能够找出图片语义的文本嵌入的方法,从而最小化预训练「文-图生成」模型的噪声预测误差。如上图所示,给定包含某些特定语义的若干张图片,网络可以学习到特殊的语义,通过在输入的文本中加入该语义符号作为条件,可以生成相应的油画、APP 图表、雕塑等图像。

Ruiz 的人于 2022 年发表的论文「DreamBotth:fine tuning text-to-image diffusion models for subject-driven generation」以基于特殊辨识符的重建损失为条件,微调大规模预训练模型,同时保留生成同一类对象的多样化图像的能力。如上图所示,给定 3-5 张特定类型狗的图像,我们训练一个能够基于特殊辨识符重建该图像的网络,在去掉这些特殊类型狗的辨识符,仅仅输入「狗」的文本后,我们希望网络能够生成多样化的普通狗的图像。即通过特殊的辨识符控制生成对象的类别。

通过自然语言给定图像生成的条件会造成一定程度的信息损失。Yang 等人于 2022 年发表的论文「Paint by example:exemplar-based image editing with diffusion models」探索了利用真实图像中得到的 mask 生成训练数据集。具体而言,作者将参考图像中的前景部分用 mask 遮盖,并使用其它图像中的物体替换参考图像中被遮盖的部分,从而得到新的数据样本。该论文使用 CLIP 的分类词例作为条件,并加入了一系列数据增强方法。
“
基于能量的指导
——用于通用条件的指导采样框架

有一些一般化的条件无法用分类器建模。为此,李崇轩团队和合作者在 NeurIPS 2022 上发表的论文「Controllable generation is much more than classifier guidance」相较于分类器指导的优势如下:
(1)更通用的损失:范数、余弦相似度、三元组损失;
(2)特定邻域的性质:几何不变性;
(3)多种控制的融合。

基于能量的指导框架是一种对预训练评分函数采样时编码领域知识的通用框架,采样方向为预训练模型与能量函数之差。其中,能量函数由待解决任务的领域知识决定。能量指导的适用性较广,能量函数可微即可。相较之下,分类器指导是能量函数为分类器的指导的一种特例,即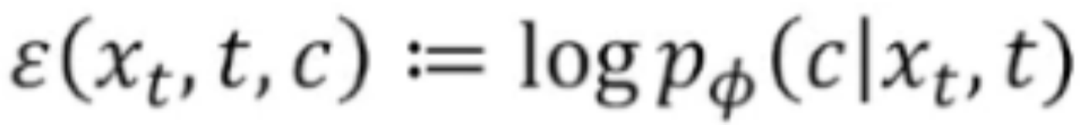 。能量指导可以是多个「子能量函数」的线性组合。
。能量指导可以是多个「子能量函数」的线性组合。

通过对能量函数取指数进行归一化,我们可以定义一个合法的概率分布。与分类器指导类似,采样分布与无条件模型和能量函数模型之积(PoE)成正比,能量指导从 PoE 中采样。此时,贝叶斯公式也是一种特殊形式的 PoE。
应用 1:不配对的图到图转换
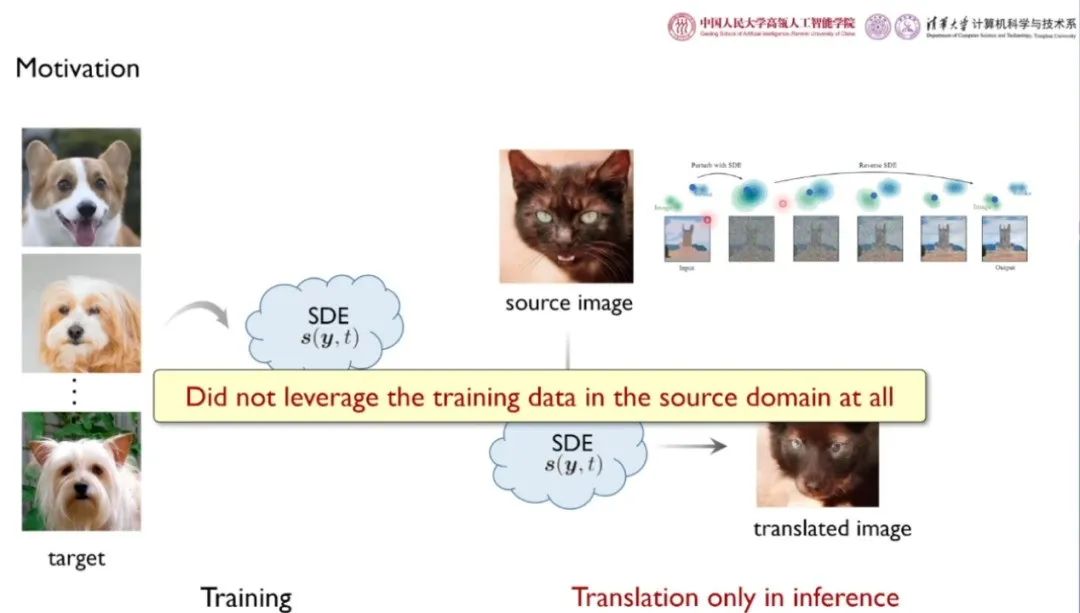
在该任务中,我们在训练时拥有源域和目标域(例如,猫和狗)的不配对数据。在推断时需要基于源域图像生成对应的目标域的图像。如果直接使用 SDEdit 类的方法直接利用目标域训练 SDE,在推断时对源域图像加噪再去躁生成对应图像,我们就完全没有利用源域中的训练数据。
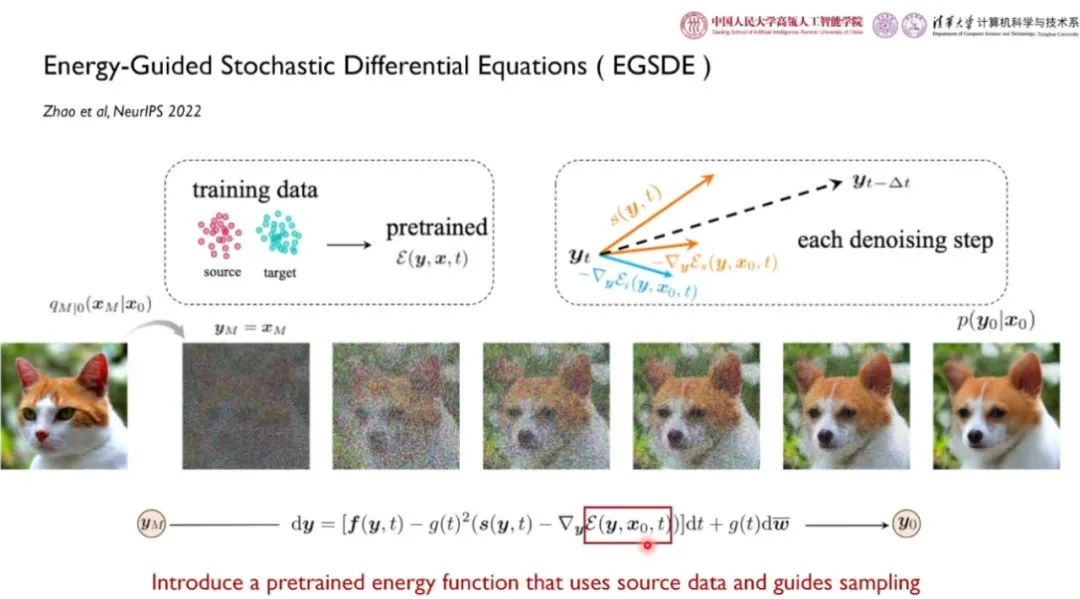
通过利用能量引导的随机微分方程方法,可以引入一个利用源域数据预训练的能量函数,并以此指导采样。好的图像转移过程要求模型尽可能改变领域相关的特定特征(例如,胡须、鼻子等特定的部位),而保留领域无关的特性(例如,姿态、颜色)。
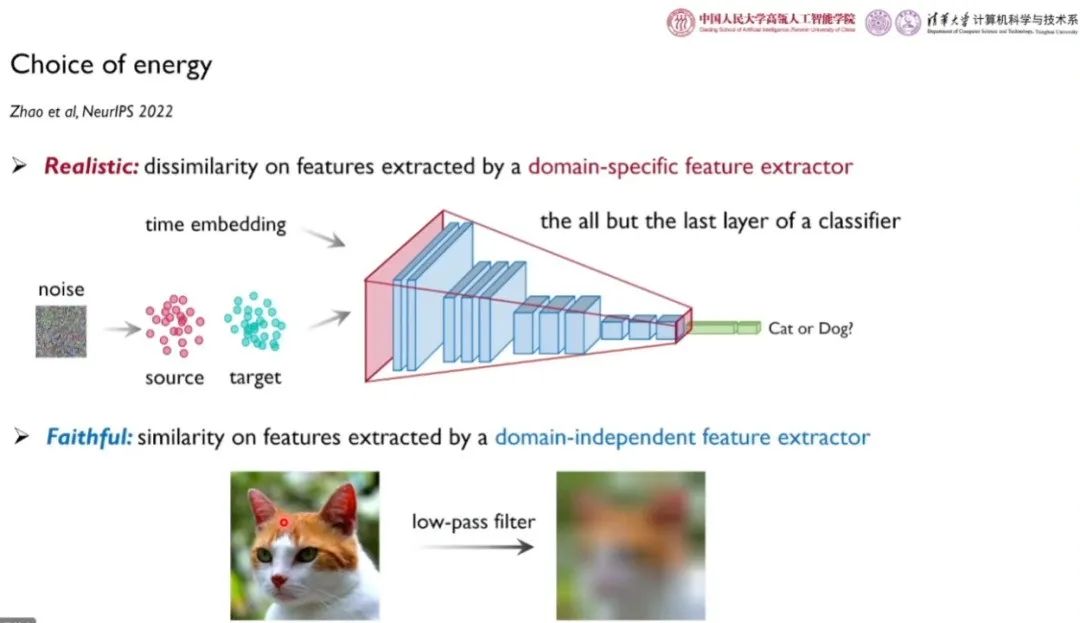
对于领域相关特征,李崇轩团队和合作者训练了一个二分类器,利用高层特征作为特定领域的特征,期望在图像转换过程中使源域和目标域特征差别较大。对于领域无关特征,我们采用低通滤波等可微操作提取语义轮廓。实验结果表明,基于能量指导的方法性能优于 SDEdit 以及基于 GAN 的方法。
应用 2:可控的分子构象生成
分子构象生成对可控性的要求十分高,要求设计出的分子具有某些特定的性质。
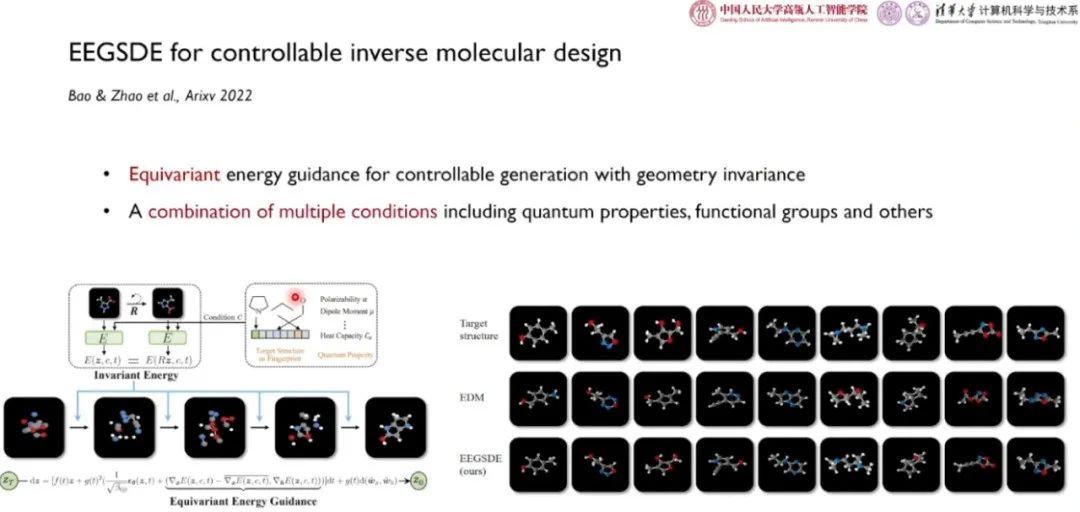
李崇轩团队和合作者在论文「EEGSDE for controllable inverse molecular design」中试图将能量指导用于三维分子构象生成。他们进一步加入了一些等变约束,将等变能量指导用于考虑几何不变性的可控分子生成。该工作考虑了极化、量子性、官能团等条件的组合。
“
条件扩散模型主干网络
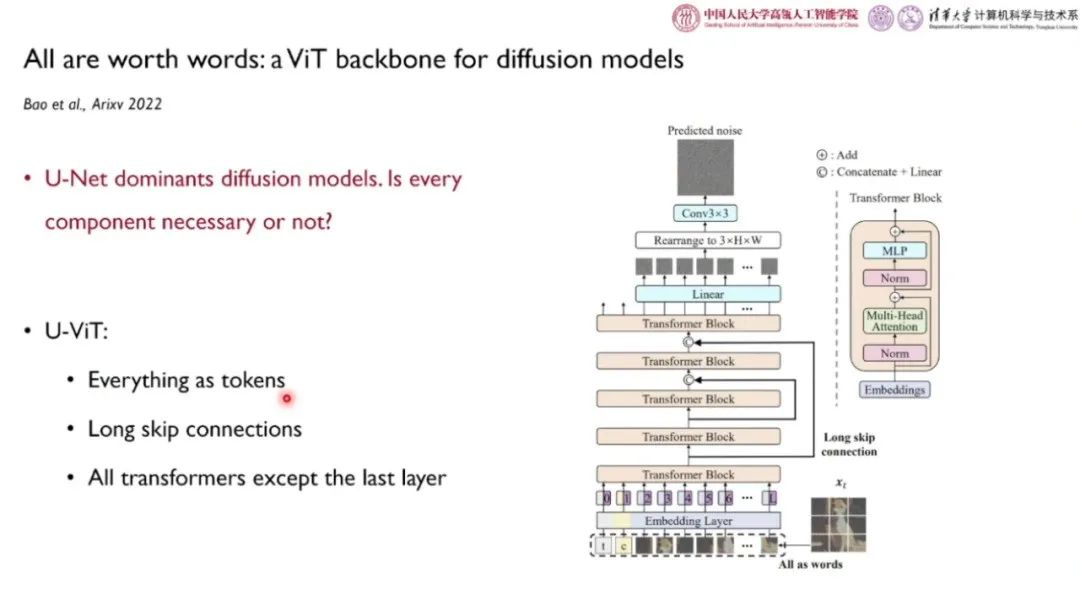
DDPM 发布之后,U-Net 类的主干网络成为了 DPM 领域中最为常用的框架。然而,鲜有研究探索其中各个组件的必要性。为此,清华大学鲍凡、中国人民大学李崇轩团队和合作者设计了 U-ViT 模型,将时间、条件、图块都作为词例输入,进入了长程的跳跃链接,将卷积层替换为 Transformer 模块。实验结果表明,在参数量相当的情况下,U-ViT 模型与 U-Net 类扩散模型相比,在条件化、无条件、文-图生成任务中性能相当,并且在MS-COCO文-图生成任务中取得了SOTA的FID表现。实验说明,长程跳跃链接是其中最重要的组件。在未来,U-ViT 模型可能有助于大规模多模态生成模型的性能提升。
“
未来研究方向:更好的扩散模型和更好地使用扩散模型
从理论层面上说,研究者们对于扩散模型的理解还有待提高,需要进一步刻画近似、优化、泛化的行为。在训练过程中,如何更好地进行参数优化、离散训练策略的设计也十分重要。在加速推断方面,探究如何通过更少的步数进行采样十分重要。利用量化、模型压缩实现更快的单步推断对于边缘设备上的模型运行也具有重大意义。扩散模型是否需要更具针对性的主干网络也是一个值得探究的课题。
为了更好地利用扩散模型,研究人员可以针对可控、可解释的生成展开研究,为支持用户友好的接口设计相应的算法。在大模型方面,会有一些大的公司和研究机构探索模型极限,也会有一些小机构朝着个性化、高效模型利用的方向展开研究。
未来智能实验室的主要工作包括:建立AI智能系统智商评测体系,开展世界人工智能智商评测;开展互联网(城市)大脑研究计划,构建互联网(城市)大脑技术和企业图谱,为提升企业,行业与城市的智能水平服务。每日推荐范围未来科技发展趋势的学习型文章。目前线上平台已收藏上千篇精华前沿科技文章和报告。
如果您对实验室的研究感兴趣,欢迎加入未来智能实验室线上平台。扫描以下二维码或点击本文左下角“阅读原文”


















 1711
1711

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









