







人类偏好对齐是大模型训练的重要阶段,通过偏好对齐可以进一步提升大模型的人机交互体验。目前被广泛使用的偏好对齐方法是 RLHF(reinforcement learning from human feedback)。然而 RLHF 有着计算复杂度高、实现复杂、训练不稳定等问题,为此最近一些方法(RRHF, DPO, Rejection Sampling 等)也在试图回避 RL 的训练范式进行偏好对齐。
但即使对 RLHF 进行了化简,目前的偏好对齐方法仍然有一个麻烦的问题无法回避,就是生成样本的分布偏移问题:当大模型经过一段时间迭代后,其生成回复的文本分布会产生偏移,然而新分布下的样本并未进行过偏好标注,导致对齐算法的效率大幅下降。
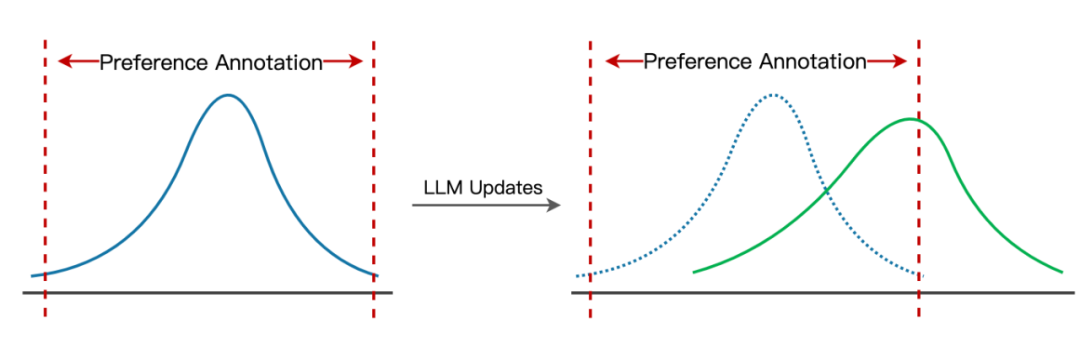
▲ 样本分布偏移:偏好标注(红色虚线)原本可以覆盖模型的输出分布(左图蓝色曲线),但当模型更新后,样本输出分布(右图绿色曲线)与偏好标注范围产生不一致。
对于分布偏移问题,目前普遍采用的解决方法是在模型迭代一定步数后,让模型重新生成回复样本,并在新样本上重新进行人工标注。这样的方式耗时耗力,严重影响了偏好对齐算法的效率。
为了更加高效地解决样本分布偏移问题,本篇文章提出了 Adversarial Preference Optimization(APO)方法,巧妙地让偏好奖励模型(Reward Model, RM)和大模型(LLM)进行对抗训练,使得 RM 可以自动适应 LLM 的分布变化,以此达到减少偏好标注数据量并提高对齐算法效率的效果。
文章在 Helpful&Harmless 数据集上进行了效果验证。实验结果表明,通过对抗方式进行大模型对齐,可以与现有对齐方法相结合,并在不增加偏好数据量的条件下,进一步提升 RM 和 LLM 的效果。

论文题目:
Adversarial Preference Optimization
论文链接:
https://arxiv.org/abs/2311.08045
代码链接:
https://github.com/Linear95/APO

对抗式对齐方法
人类偏好对齐方法目标是去优化 LLM 输出策略 在 RM 模型 评价下的期望得分:
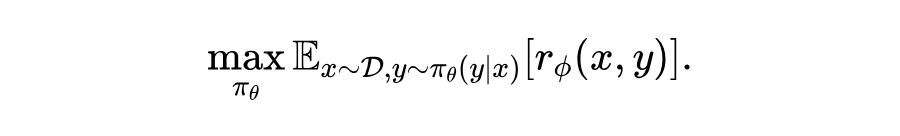
本文借助少量人工金标准数据(golden responses),将偏好对齐的目标转变成一个 min-max 博弈:
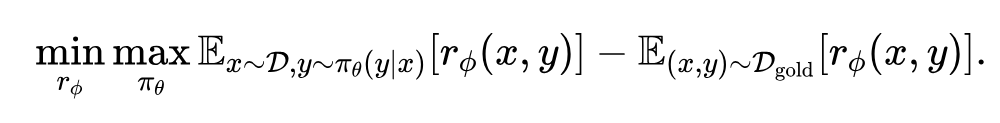
以上的博弈过程中,LLM 模型 需要不断提高回复质量以减少其得分和金标数据得分之间的差距,而 RM 模型 需要不断将模型生产的结果和金标准结果区分开。通过这种对抗的训练方式,RM 会时刻跟随 LLM 的变化而迭代,分布偏移的问题就此得到缓解。
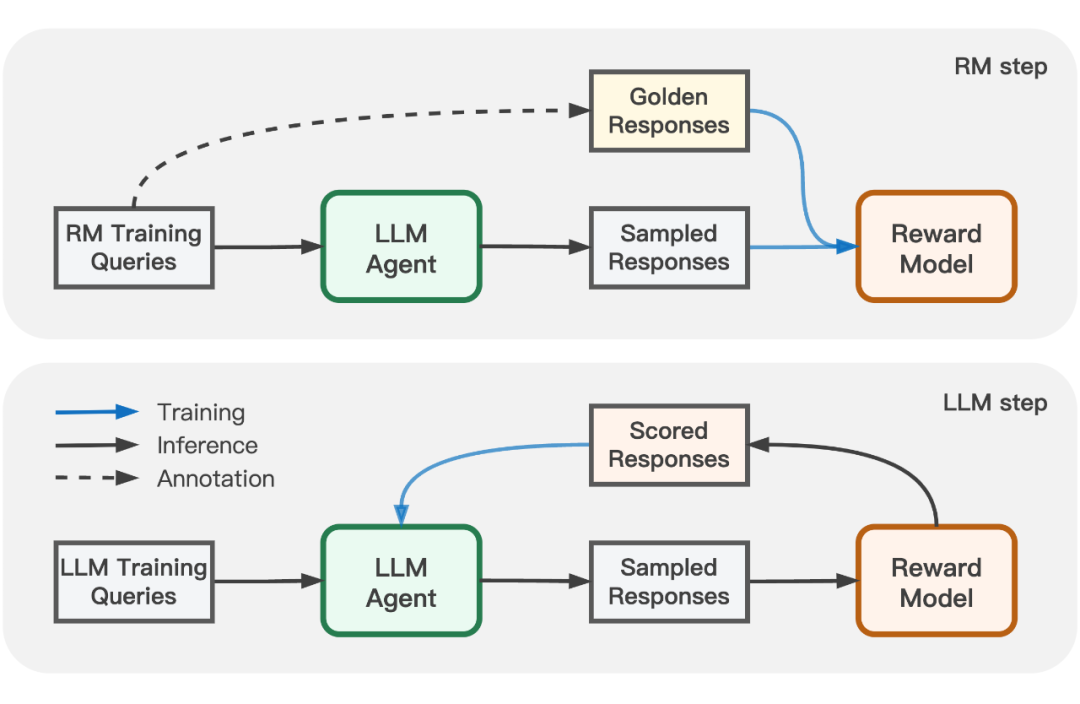
▲ APO 的 RM 和 LLM 交替训练流程
具体的对抗算法实现如上图所示。RM 和 LLM 将交替进行迭代:
在 LLM 迭代步骤中,RM 参数固定,博弈目标转换为正常的偏好对齐问题,可以使用 RLHF、RRHF、DPO、Rejection Sampling 等方法求解。流程上,作者将 LLM 训练用的 queries 经过 LLM 推理出对应的回复样本,再用 RM 模型进行打分,最后用打分反馈来更新 LLM 的回复策略。
在 RM 迭代步骤中,LLM 参数固定,作者将 RM 训练的 queries 经过 LLM 推理得到对应的样本回复。然后将生成的样本回复和金标准回复进行组合,得到新的 APO 偏好数据,用来更新 RM 模型。
此外,文章还在博弈过程中引入了 KL 散度作为正则项,以缓解对抗训练过拟合和收敛困难的问题。同时,文章还讨论了 APO 方法与 GAN 等经典对抗训练方法之间的联系和区别。

实验结果
为验证 APO 训练框架有效性,作者在 Helpful&Harmless 偏好数据集上进行了偏好对齐实验,并对该数据集中的问题调用 GPT-4 获得回答作为金标准回复。文章选择了 rejection sampling 方法作为基线进行比较,RM 模型选择 LLaMA-7B,LLM 的 SFT 模型选择 Alpaca-7B,并进行了三轮对抗迭代。
在对抗迭代中,作者尝试了两种 RM 的更新方式:
From Base:也就是每次 RM 都是基于 base model 利用新的 APO 对抗数据进行更新,
Sequential:每一轮 RM 都是在上一轮 RM 的 checkpoint 上继续用新的 APO 对抗数据进行训练。
关于 RM 和 LLM 表现的实验结果总结在下面的图表当中:
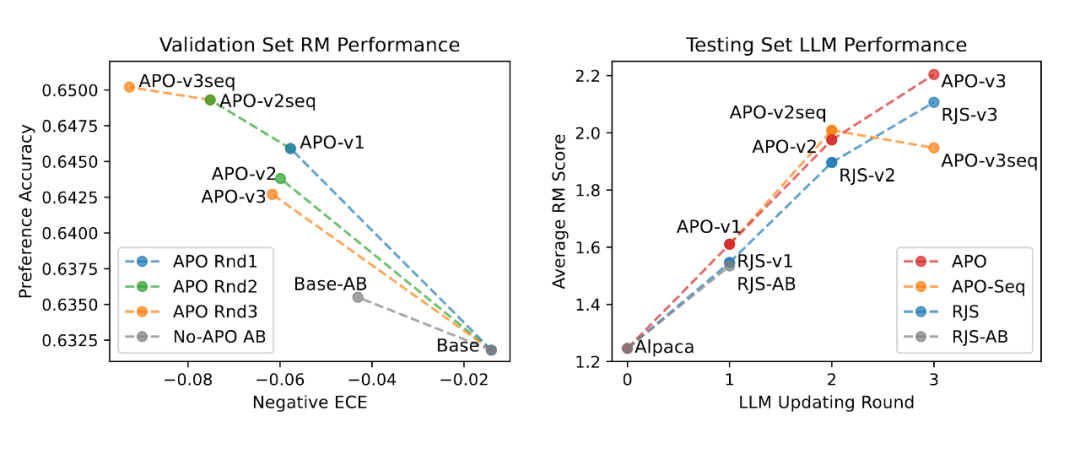
左侧的图表展示了 APO 训练后 RM 的表现变化,纵轴为 RM 在测试集上的准确率,横轴为模型的校准误差(Calibration Error)。可以看到,通过加入 APO训练数据,RM 模型的偏好准确率可以一致地获得提升,尤其是通过 Sequential 的方式更新 RM(APO-v1 APO-v2seq APO-v3seq)可以将 RM 的准确率持续提升。但于此同时 RM 校准表现会有一定的损失。
右侧图表展示了 APO 训练对 LLM 对齐效果的增益,纵轴为测试 RM 对 LLM 回复样本的平均打分,代表 LLM 的对齐质量,横轴为对抗迭代的轮数。可以看到,用 From Base 训练的 RM 进行 APO 对抗的结果(红色虚线)可以持续地跟 rejection sampling(RJS)基线(蓝色虚线,仅用 Base RM 进行对齐)拉开差距。而 Sequential 训练的 RM 可以在第二轮获得更好的效果,但是在第三轮时效果反而下降,作者分析原因可能是因为 overfit 导致 RM 的校准误差过大。
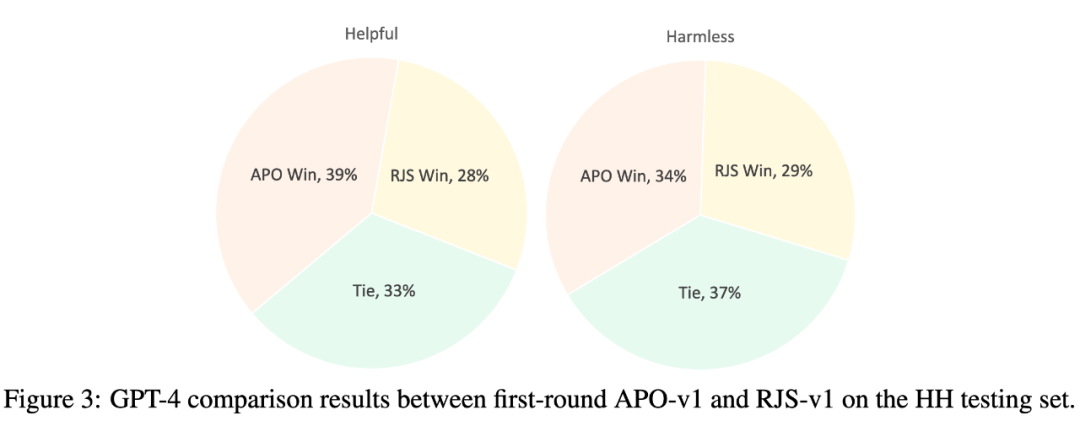
此外作者还利用 GPT-4 对 LLM 在测试集上的回复进行了评价。如下图所示,通过 APO 训练的模型可以相比于 RJS 基线获得显著提升。

总结
本文提出了一种新的人类偏好对齐训练范式 APO,通过 RM 和 LLM 进行对抗的方式,可以在不增加标注数据量的前提下进一步增强 RM 和 LLM 的表现,同时缓解 LLM 的样本分布偏移问题。
作为一种通用的训练框架,APO 可以跟现有的对齐方法(RLHF,RRHF,DPO等)做到兼容,可以进一步提升这些对齐方法的效果。
通过对抗的方式,RM 可以对 LLM 的迭代做到自适应,从而降低了重新对 LLM 样本进行偏好标注的需求,可以降低标注成本,提升大模型对齐的效率。
作者也提到,目前对 APO 的探索还在相对初步的阶段,后续还将持续扩充实验,探索如何降低 RM 在对抗过程中的校准误差,如何保证对抗过程不会 overfit,以及将 APO 与其他对齐方法结合的效果表现。
更多阅读




#投 稿 通 道#
让你的文字被更多人看到
如何才能让更多的优质内容以更短路径到达读者群体,缩短读者寻找优质内容的成本呢?答案就是:你不认识的人。
总有一些你不认识的人,知道你想知道的东西。PaperWeekly 或许可以成为一座桥梁,促使不同背景、不同方向的学者和学术灵感相互碰撞,迸发出更多的可能性。
PaperWeekly 鼓励高校实验室或个人,在我们的平台上分享各类优质内容,可以是最新论文解读,也可以是学术热点剖析、科研心得或竞赛经验讲解等。我们的目的只有一个,让知识真正流动起来。
📝 稿件基本要求:
• 文章确系个人原创作品,未曾在公开渠道发表,如为其他平台已发表或待发表的文章,请明确标注
• 稿件建议以 markdown 格式撰写,文中配图以附件形式发送,要求图片清晰,无版权问题
• PaperWeekly 尊重原作者署名权,并将为每篇被采纳的原创首发稿件,提供业内具有竞争力稿酬,具体依据文章阅读量和文章质量阶梯制结算
📬 投稿通道:
• 投稿邮箱:hr@paperweekly.site
• 来稿请备注即时联系方式(微信),以便我们在稿件选用的第一时间联系作者
• 您也可以直接添加小编微信(pwbot02)快速投稿,备注:姓名-投稿

△长按添加PaperWeekly小编
🔍
现在,在「知乎」也能找到我们了
进入知乎首页搜索「PaperWeekly」
点击「关注」订阅我们的专栏吧
·
·


















 4971
4971

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









