







近年来,以扩散模型为代表的生成式 AI 模型能力日新月异,尤其是近期 OpenAI 的文本到视频的生成模型 Sora,展现出了惊人的超长上下文关注能力,实现了连贯一致的长视频生成。
针对视频/图像序列生成过程中的一致性这一难题,上海交通大学与上海人工智能实验室联合团队提出了利用 AIGC 技术进行故事讲述,探索了一项新颖且极富挑战性的任务——开放式视觉故事生成(open-ended visual storytelling)。
和长视频生成任务相比,该任务可视为一项对计算资源需求更低,但同样关注一致性与连贯性的代理任务。具体来说,任务要求根据任意给定的故事情节,生成内容、角色和风格连贯的图像序列,可视为多场景复杂视频中连续关键帧的生成。
为此,团队提出了首个开放式视觉故事生成模型 StoryGen。与以往泛化能力极其有限、只能针对有限角色/词汇生成的模型不同,StoryGen 在训练完成后,无需任何微调即可泛化到训练时不可见的全新角色/故事剧本上,并生成内容连贯(coherent content)、角色一致(consistent character)的故事图像序列。除了技术上的创新,StoryGen 的视觉故事生成能力也在儿童教育和文化传播领域具有巨大潜力。
研究论文《Intelligent Grimm - Open-ended Visual Storytelling via Latent Diffusion Models》已被国际知名会议 Computer Vision and Pattern Recognition (CVPR) 2024 接收。作者团队来自上海交通大学、上海人工智能实验室、美团。

论文标题:
Intelligent Grimm - Open-ended Visual Storytelling via Latent Diffusion Models
论文地址:
https://arxiv.org/abs/2306.00973
代码地址:
https://github.com/haoningwu3639/StoryGen

Contributions

1. 新颖模型:我们提出了首个开放式视觉故事生成模型StoryGen,它是一种基于学习的自回归图像生成模型(learning-based auto-regressive image generation model),具有新颖的视觉语言上下文模块(visual-language context module),以扩散模型去噪过程的特征作为条件,能够在当前给定的text prompt和之前的image-caption pairs引导下生成连贯的图像;
2. 多样数据:为了解决开放式视觉故事生成的数据短缺问题,我们从多个数据来源(YouTube视频和开源电子图书馆)中收集了大量文本-图像样本对序列(paired image-text sequences),并建立了一套完善的数据处理流水线,构建了一个具有多种多样人物、故事情节和风格的大规模数据集,命名为StorySalon;
3. 优异性能:定量实验和人为评估彰显了我们所提出的StoryGen相较于以往的故事可视化(Story Visualization)及故事延续(Story Continuation)模型的优越性。
4. 解决痛点:StoryGen一经训练,无需任何微调即可泛化到未曾见过的新角色,并生成内容连贯(coherent content)、角色一致(consistent character)的故事图像序列。

Method

模型介绍:我们提出的 StoryGen 模型基于 Stable Diffusion-v1.5,使用扩散模型去噪过程中的特征(diffusion-denoising features)作为额外的上下文条件(context condition),通过并联的 cross-attention 层引导当前帧的生成,以自回归的形式逐步生成整个图像序列。模型的主要技术创新包括:
1. 上下文条件提取:我们为序列中已有的图像帧加噪,以其对应的文本为条件,使用 StoryGen 对其去噪并提取 diffusion-denoising features,作为条件引导当前帧的生成过程。
2. 条件引导的图像生成:当前帧同时以对应的文本特征和已生成图像的 diffusion-denoising features 作为条件,使用视觉-文本上下文模块(Visual-Language Context Module),根据 classifier-free guidance,进行多条件引导的生成。
3. 多帧条件生成:对于以多帧上下文作为条件的情况,我们根据与当前帧的时序距离远近,为已生成帧添加不同程度的噪声,作为天然的位置编码信息。
4. 模型训练:
单帧-风格迁移:我们首先以单帧的形式微调 SDM 的 self-attention 层,以保证模型的单帧生成能力和风格迁移;
多帧-条件生成:随后将 SDM 的所有参数冻结,引入额外的上下文模块,以当前文本提示和前文的上下文信息作为条件,进行多帧形式的训练模型利用上下文条件的能力。
5. 模型推理:在推理过程中,我们可以使用 ChatGPT/GPT-4 生成全新的剧本,将已有或生成的图像作为首帧,自回归地生成连续的图像序列。实验表明,我们的 StoryGen 能够生成与故事情节一致,且图像内容、风格、角色形象连贯的视觉故事,并且不需要任何微调或优化即可泛化到新的故事线/角色。

Dataset
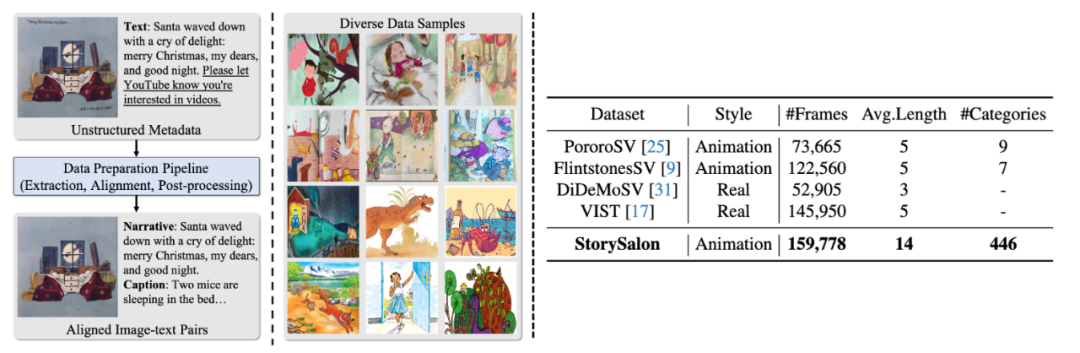
数据集介绍:为了训练适合开放式视觉故事生成任务的 StoryGen 模型,我们构建了一个角色和类别丰富多样的大规模数据集,命名为 StorySalon。
多样的数据源:我们从视频(提供下载 URLs)和开源电子书(遵循 CC-BY 4.0 许可证)中搜集了包含丰富人物、故事情节和艺术风格的视觉故事。
数据处理流水线:我们构建了包括视觉帧提取、重复帧筛除、异常帧检测、视觉-语言对齐、视觉描述文本生成、文字检测和后处理等多个步骤的完善的数据处理流水线,将元数据处理为适合模型训练的形式。随着元数据的扩充,该流水线可以很容易地完成迁移,进而进一步扩充 StorySalon 数据集的规模。
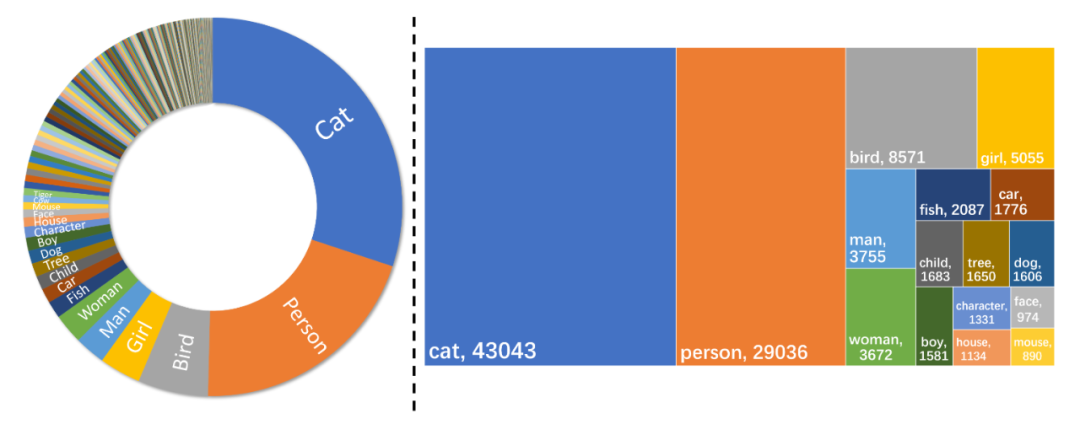
数据集优势:相较于以往仅包含不到 10 个角色且词汇量和故事长度有限的数据集,我们的 StorySalon 数据集具有规模更大的词汇表,包含数百个类别的数千个角色,因而更适合开放式任务。

Experiments
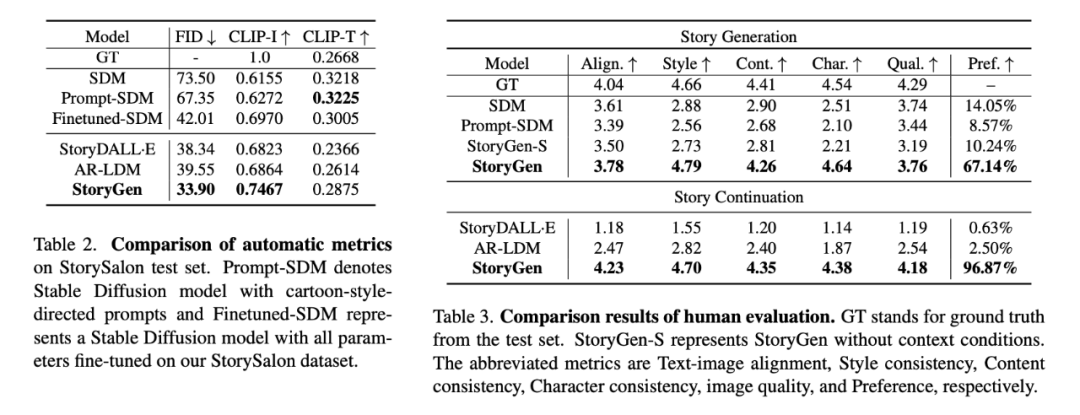
实验部分,我们考虑开放式视觉故事生成的两种子任务,即故事生成和故事延续,前者直接通过给定的故事线文本进行生成,后者除了文本条件外还提供序列中的第一帧作为图像条件信息。针对两种子任务,我们分别选择了合适的 baseline 进行比较定性和定量比较。
评价指标:以常用的 FID、CLIP-Image score 和 CLIP-Text Score 作为客观评价指标;
人工评测:考虑到上述指标不能全面地反映生成内容的质量,尤其是缺少对一致性(Consistency)的评价指标,我们还对上述模型和 StoryGen 进行了人工评测。
主观评分:我们使用 GPT-4 生成了一定数量的全新故事线作为输入,使用各模型生成相应的视觉故事,由受试者从文本-图像对齐性、风格一致性、内容一致性、角色一致性和图像质量五个维度分别为结果打分。
对比选择:我们将不同模型生成的同一故事一同展示给受试者,从上述五个维度综合考虑,选择质量最佳的结果。
结论:上表中的定量结果和下图中的定性结果有力证明了我们所提出的 StoryGen 能够生成高质量,内容、风格、角色一致的连贯视觉故事。更多可视化结果请参见我们的论文和附录。

消融实验:为了进一步证实我们所提出的使用扩散模型去噪特征作为条件的视觉-语言上下文模块的有效性,我们还将该模块直接插入到 Stable Diffusion 中,并在 MS-COCO 数据集上进行以参考图像为条件引导的图像生成。
定性和定量实验均表明我们所提出的上下文模块能够有效利用扩散模型去噪过程中的特征,比 VAE、CLIP、BLIP features 更适合保留参考图像中的细节信息。


Visualization Examples

▲ A story of a {white dog}. 具体文本故事线请参见我们论文的附录

▲ A story of a {red-haired girl}. 具体文本故事线请参见我们论文的附录

Conclusion
在这项工作中,我们探索了一个有趣且有挑战性的任务——开放式视觉故事生成,它需要生成模型能够基于给定的故事线生成讲述连贯视觉故事的图像序列。为此我们提出了基于学习的 StoryGen 模型,它可以根据前文的图像-文本上下文和当前文本提示作为输入,以自回归的方式生成连贯的图像序列,而不需要额外的微调。
在数据方面,我们建立了完善的数据处理流水线,收集了一个名为 StorySalon 的大规模数据集,包括具有多种多样人物、故事情节和艺术风格的故事书。定量实验和人为评估表明,在图像质量、内容连贯性、角色一致性和视觉-语言对齐等多个维度上,我们所提出的 StoryGen 显著优于现有模型。
更多详细的技术细节可以参照我们的论文和附录,代码、模型、数据均已开源,欢迎大家交流。
顺便宣传一下我们团队在 Diffusion models 领域为了方便设计和开发特定的模型,基于 diffusers 库搭建的几个便于 DIY 的代码仓库:
基于SDM-1.5的图像生成,SimpleSDM:
https://github.com/haoningwu3639/SimpleSDM
基于ZeroScope-v2的视频生成,SimpleSDM-Video:
https://github.com/haoningwu3639/SimpleSDM-Video
基于SDXL的图像生成,SimpleSDXL:https://github.com/haoningwu3639/SimpleSDXL
主要是将 diffusers library 中与上述三个模型训练/推理相关的 code 提炼出来,并集成了 DDIM inversion 功能以及 accelerator 库的分布式训练/混合精度推理。
更多阅读




#投 稿 通 道#
让你的文字被更多人看到
如何才能让更多的优质内容以更短路径到达读者群体,缩短读者寻找优质内容的成本呢?答案就是:你不认识的人。
总有一些你不认识的人,知道你想知道的东西。PaperWeekly 或许可以成为一座桥梁,促使不同背景、不同方向的学者和学术灵感相互碰撞,迸发出更多的可能性。
PaperWeekly 鼓励高校实验室或个人,在我们的平台上分享各类优质内容,可以是最新论文解读,也可以是学术热点剖析、科研心得或竞赛经验讲解等。我们的目的只有一个,让知识真正流动起来。
📝 稿件基本要求:
• 文章确系个人原创作品,未曾在公开渠道发表,如为其他平台已发表或待发表的文章,请明确标注
• 稿件建议以 markdown 格式撰写,文中配图以附件形式发送,要求图片清晰,无版权问题
• PaperWeekly 尊重原作者署名权,并将为每篇被采纳的原创首发稿件,提供业内具有竞争力稿酬,具体依据文章阅读量和文章质量阶梯制结算
📬 投稿通道:
• 投稿邮箱:hr@paperweekly.site
• 来稿请备注即时联系方式(微信),以便我们在稿件选用的第一时间联系作者
• 您也可以直接添加小编微信(pwbot02)快速投稿,备注:姓名-投稿

△长按添加PaperWeekly小编
🔍
现在,在「知乎」也能找到我们了
进入知乎首页搜索「PaperWeekly」
点击「关注」订阅我们的专栏吧
·
·
·


















 1314
1314

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









