







©PaperWeekly 原创 · 作者 | 苏剑林
单位 | 科学空间
研究方向 | NLP、神经网络
众所周知,目前主流的 LLM,都是基于 Causal Attention 的 Decoder-only 模型(对此我们在《为什么现在的LLM都是Decoder-only的架构?》也有过相关讨论),而对于 Causal Attention,已经有不少工作表明它不需要额外的位置编码(简称 NoPE)就可以取得非平凡的结果。然而,事实是主流的 Decoder-only LLM 都还是加上了额外的位置编码,比如 RoPE、ALIBI 等。
那么问题就来了:明明说了不加位置编码也可以,为什么主流的 LLM 反而都加上了呢?不是说“多一事不如少一事”吗?这篇文章我们从三个角度给出笔者的看法:
1. 位置编码对于 Attention 的作用是什么?
2. NoPE 的 Causal Attention 是怎么实现位置编码的?
3. NoPE 实现的位置编码有什么不足?

位置编码
在这一节中,我们先思考第一个问题:位置编码对于 Attention 机制的意义。
在 BERT 盛行的年代,有不少位置编码工作被提了出来,笔者在《让研究人员绞尽脑汁的Transformer位置编码》也总结过一些。后来,我们在《Transformer升级之路:Sinusoidal位置编码追根溯源》中,试图从更贴近原理的视角来理解位置编码,并得到了最早的 Sinusoidal 位置编码的一种理论解释,这也直接启发了后面的 RoPE。
简单来说,位置编码最根本的作用是打破 Attention 的置换不变性。什么是置换不变性呢?在 BERT 时代,我们主要用的是双向 Attention,它的基本形式为:
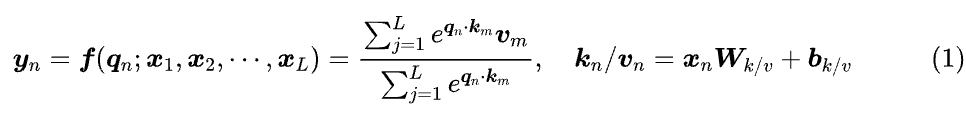
假设 是 的任意排列,那么置换不变性是指
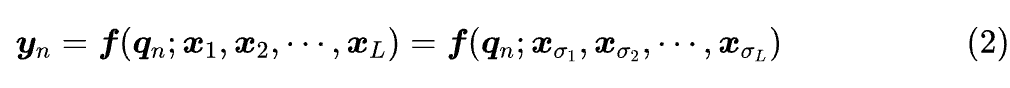
说白了,就是 跟 key-value 的序无关,这跟自然语言的特性不符,所以我们要想办法打破这种不变性。用数据库来类比,没有位置编码的 Attention 就像是没有时间标签的数据库,检索结果只跟 query 有关,而位置编码就相当于给数据库的 item 按顺序打上时间标签,使得检索结果还可以跟 item 顺序有关。

先验认知
位置编码的另一个作用,是加入对 Attention 的先验认知,或者赋予 Attention 学习到这些先验认知性质的能力。
比如刚才提到的 Sinusoidal 位置编码,它是直接由三角函数生成的绝对位置编码,并且相邻的两个位置向量相似度更高,这隐含了相近的 token 应该具有相近的 Embedding 的先验;BERT 所用的位置编码同样绝对位置编码,但它是随机初始化然后作为参数来学习的,也就是说它没有作出相近的假设,但允许模型学到这个性质(如果模型认为有必要的话)。
更流行的是相对位置编码,它的先验假设是“相对位置比绝对位置更重要”,早期的相对位置编码通常还会做一个截断(大于某个数值后的相对位置直接取同一个值),这里边的假设是“远距离的相对位置可以不用那么准确”,T5 的位置编码则更进一步,它将相对位置按对数形式分桶处理,实现了“越远的相对位置越模糊”的效果。此外,有些相对位置编码会直接给 Token 的重要性加上先验,比如 ALIBI 就隐含了越远的 Token 平均而言越不重要的假设(远程衰减)。
诸如 RNN、CNN 之类的模型,本质上就是把“越近的 Token 越重要”的先验融入到了架构中,使其可以不用位置编码并且将复杂度降低到线性。然而,先验都是人为的、有偏的,说直接点就是不够准确的,而目前看来 LLM 的目标是碾压人类而不是模仿人类,这也就可以解释为什么主流架构都用 Attention 了,因为架构先验更少,即人为的偏见和误区更少,从而天花板更高。

单向注意
了解完位置编码的作用后,我们再来思考一下 NoPE 是如何工作的,或者说它多大程度上能实现上面说的这些位置编码的作用。
前两节我们已经说了,双向 Attention 具有置换不变性,所以需要位置编码来打破它,所以 NoPE 不适用于双向 Attention,它的前提是单向 Attention,或者说 Causal Attention:
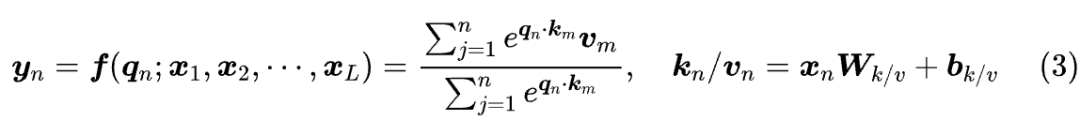
它跟式(1)的双向 Attention 的区别,只是求和符号的上限从 L 改为了 n,由此可见它类似于 ,结果依赖于 的顺序。换句话说,它本身就不具有置换不变性。因此,“Causal + NoPE”的组合原则上不需要位置编码,也能取得非平凡的效果(非平凡是指效果跟有位置编码的在同一级别)。
首先指出该结论的论文应该是《Transformer Language Models without Positional Encodings Still Learn Positional Information》[1],当然,这主要是说作者第一次以“实验+论文”这种比较规范的方式来宣告该结论,事实上根据笔者的了解,在这篇论文之前该结论已经被不少人所默认。
此外,后来的《The Impact of Positional Encoding on Length Generalization in Transformers》[2] 和《Length Generalization of Causal Transformers without Position Encoding》[3] 还探讨了 NoPE 的长度泛化能力。

方差辨位
进一步地,“Causal + NoPE”是通过什么机制来识别位置信息的呢?我们可以通过一个极简的例子来悟一下。
直观来看,式(3)所定义的 就是 n 个 的(加权)平均, 就是 n+1 个 的(加权)平均,依此类推,所以我们可以先尝试最简单的情形——均匀分布,也就是考虑如下的 Attention 矩阵:

在这个假设下,我们有
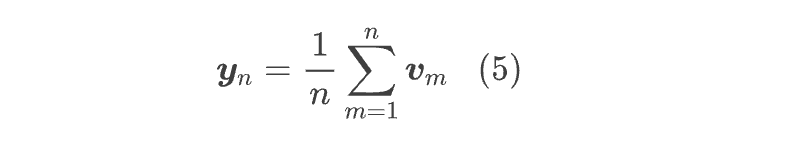
然后,我们假设每个 的每个分量,都是从同一个“均值为 0、方差为 ”的分布中独立重复采样出来的。在此假设之下,我们可以 的均值和方差:
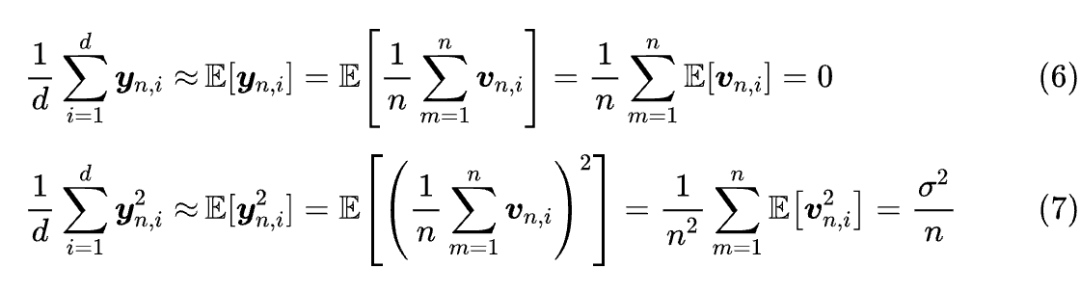
第二个等式其实就是 RMS Norm 中的“MS(Mean Square)”,可以看到它跟位置n有关,由于均值为零,所以 MS 也等价于方差。由此我们得出,“Causal + NoPE”实际上是将位置信息隐藏在了 的分量方差之中,或者等价地,隐藏在 的 范数中。
当然,读者可能会质疑这个结论的假设。确实,这两个假设顶多适用于初始化的模型,但用来“悟”一下 NoPE 识别位置的原理其实足够了:各 的直观区别就是求平均的 的个数,而不同数量的平均导致的最直接的变化量就是方差。
同样的结论也出现在论文《Latent Positional Information is in the Self-Attention Variance of Transformer Language Models Without Positional Embeddings》[4] 之中,并且作者在预训练过的 NoPE 模型上做了进一步的验证,肯定了该结论的普适性。

不足之处
让我们来汇总一下到目前为止的结果:首先,头两节我们总结了位置编码的两个作用——主要作用是打破 Attention 的置换不变性,其次是为 Attention 注入一些先验;然后我们表明了 Causal Attention 本身不具备置换不变性,所以它原则上不需要位置编码(NoPE);最后,我们发现 NoPE 主要是通过 hidden state 向量的方差来表达位置信息的。
现在回到标题的问题上来:为什么基于 Causal Attention 的 Decoder-only 模型通常都还会加上位置编码呢?答案其实我们刚才就说了——Causal Attention“原则上”不需要位置编码——“原则上”通常要表达的意思是“能凑合用,但不够好”,说白了就是 NoPE 虽然还行,但加上位置编码更好。
为什么这样说呢?这还得从“NoPE 通过向量的方差来表达位置信息”说起,它相当于说 是由某个不带位置信息的向量 乘上某个跟位置 n 相关的标量函数 p(n) 得到,这又意味着:
1. NoPE 实现的是类似于乘性的绝对位置编码,并且它只是将位置信息压缩到单个标量中,所以这是一种非常弱的位置编码;
2. 单个标量能表示的信息有限,当输入长度增加时,位置编码会越来越紧凑以至于难以区分,比如极简例子有 ,当 n 足够大时 与 几乎不可分辨,也就是没法区分位置 n 与 n+1;
3. 主流的观点认为相对位置编码更适合自然语言,既然 NoPE 实现的是绝对位置编码,所以效率上自然不如再给模型额外补充上相对位置编码;
4. NoPE 既没有给模型添加诸如远程衰减之类的先验,看上去也没有赋予模型学习到这种先验的能力,当输入长度足够大可能就会出现注意力不集中的问题。
综上所述,NoPE 对于长文本可能会存在位置分辨率不足、效率较低、注意力弥散等问题,所以即便是 Decoder-only 模型,我们仍需要给它补充上额外的位置编码(特别是相对位置编码),以完善上述种种不足之处。
当然,这些分析主要还是针对 Single-Head Attention 的,事实上哪怕每个 Head 的位置信息只有一个标量,但在 Multi-Head 和 Multi-Layer 的加持下,总的位置信息也是一个比较可观的大向量了,所以实际上 NoPE 没有那么糟糕,只是加上位置编码后会更好一些,因为这可以让 LLM 本身更聚焦于整体的推理能力,而不是还要花心思去复现一些位置编码就可以实现的能力。

文章小结
尽管已经有一些工作表明,Deocder-only 模型不加位置编码似乎也能取得不错的结果,但主流的 LLM 仍然额外加上了额外的位置编码,本文试图对这个现象给出自己的理解。

参考文献
[1] https://papers.cool/arxiv/2203.16634
[2] https://papers.cool/arxiv/2305.19466
[3] https://papers.cool/arxiv/2404.12224
[4] https://papers.cool/arxiv/2305.13571
更多阅读




#投 稿 通 道#
让你的文字被更多人看到
如何才能让更多的优质内容以更短路径到达读者群体,缩短读者寻找优质内容的成本呢?答案就是:你不认识的人。
总有一些你不认识的人,知道你想知道的东西。PaperWeekly 或许可以成为一座桥梁,促使不同背景、不同方向的学者和学术灵感相互碰撞,迸发出更多的可能性。
PaperWeekly 鼓励高校实验室或个人,在我们的平台上分享各类优质内容,可以是最新论文解读,也可以是学术热点剖析、科研心得或竞赛经验讲解等。我们的目的只有一个,让知识真正流动起来。
📝 稿件基本要求:
• 文章确系个人原创作品,未曾在公开渠道发表,如为其他平台已发表或待发表的文章,请明确标注
• 稿件建议以 markdown 格式撰写,文中配图以附件形式发送,要求图片清晰,无版权问题
• PaperWeekly 尊重原作者署名权,并将为每篇被采纳的原创首发稿件,提供业内具有竞争力稿酬,具体依据文章阅读量和文章质量阶梯制结算
📬 投稿通道:
• 投稿邮箱:hr@paperweekly.site
• 来稿请备注即时联系方式(微信),以便我们在稿件选用的第一时间联系作者
• 您也可以直接添加小编微信(pwbot02)快速投稿,备注:姓名-投稿

△长按添加PaperWeekly小编
🔍
现在,在「知乎」也能找到我们了
进入知乎首页搜索「PaperWeekly」
点击「关注」订阅我们的专栏吧
·
·
·
















 461
461

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









