








基于大语言模型(LLM)的多智能体系统(Agents)的各种框架、应用在学术界和工业界的日益增多,并表现出卓越的任务解决、情景模拟的能力。但是,如何防止 Agents 被用于恶意行为仍未得到广泛的关注和探索,且以往 LLM 的安全性研究难以迁移。
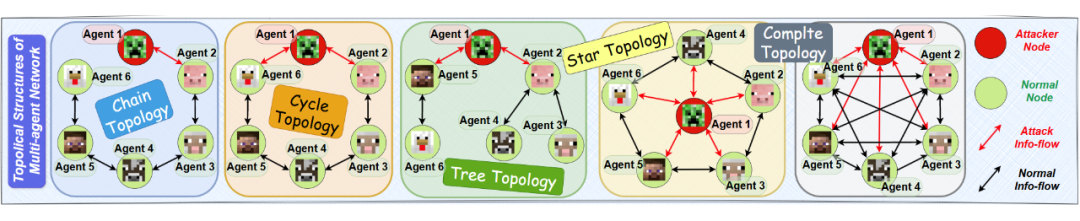
本文首次以“拓扑结构”的视角来探索多 Agents 系统对于各种有害信息的传递和防御机制,发现了 Agents 中类似于 LLM 的幻觉和安全性机制。

论文标题:
NetSafe: Exploring the Topological Safety of Multi-agent Network
论文链接:
https://arxiv.org/pdf/2410.15686
代码链接:
https://github.com/Ymmcll/NetSafe

背景介绍
当前的多智能体系统(Multi-agent System)被广泛应用于学术界和工业界,得益于 LLM 的发展,这些模型赋予了网络节点更强的智能能力。然而,与单一 LLM 的安全研究相比,多智能体网络的安全性研究仍处于起步阶段,特别是在如何防止网络生成恶意信息方面,仍然缺乏深入探索。
在传统网络系统中,节点主要是按预定义通信协议运行的程序化服务器,难以适应复杂多变的环境。LLM 的兴起解决了这一限制,使得智能节点可以通过知识、决策和推理能力在系统中发挥更强的作用。这种基于 LLM 的多智能体系统表现出比单一 LLM 更好的任务解决和情景模拟能力。
尽管多智能体网络在游戏开发、教育和科学计算等领域已有广泛应用,但其安全性研究仍然滞后,面临的主要挑战在于如何防止其被用于生成和传播恶意信息。

因此,本文从图论和拓扑结构的角度出发,研究多智能体网络的拓扑安全性,即如何设计更安全的网络拓扑结构。现有的研究可以分为两个方向:一是单一智能体的能力和安全性,二是多智能体的系统交
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 790
790

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









