







 本文介绍了腾讯 AI Lab 在 EMNLP 2018 上发表的两篇论文,涉及文本风格转化和对话生成。论文提出了一种量化指导下的序列编辑模型(QuaSE)解决数值匹配的句子生成问题,以及一种减少开放领域对话中通用回复的神经对话模型。实验结果显示,这些模型在内容保持和多样性方面表现优秀。
本文介绍了腾讯 AI Lab 在 EMNLP 2018 上发表的两篇论文,涉及文本风格转化和对话生成。论文提出了一种量化指导下的序列编辑模型(QuaSE)解决数值匹配的句子生成问题,以及一种减少开放领域对话中通用回复的神经对话模型。实验结果显示,这些模型在内容保持和多样性方面表现优秀。

本文将介绍腾讯 AI Lab 发表于 EMNLP 2018 的两篇论文,论文关注的是文本到文本生成研究领域中的文本风格转化及对话生成任务。其中,在文本风格的论文中,作者提出了一个新的序列编辑模型旨在解决如何生成与给定数值相匹配的句子的研究问题。而关于对话生成的论文中,作者提出了一个新的对话模型用于抑制对话生成模型中通用回复的生成。
引言
随着近年来端到端的深度神经网络的流行,文本生成逐渐成为自然语言处理中一个热点研究领域。文本生成技术具有广阔的应用前景,包括用于智能对话系统,实现更为智能的人机交互;我们还可以通过自动生成新闻、财报及其它类型的文本,提高撰文者的工作效率。
根据不同的输入类型,文本生成可以大致划分为三大类:文本到文本的生成,数据到文本的生成以及图像到文本的生成。每一类的文本生成技术都极具挑战性,在近年来的自然语言处理及人工智能领域的顶级会议中均有相当多的研究工作。
本次将介绍腾讯 AI Lab 在文本到文本生成研究领域中关于文本风格转化及对话生成的两篇论文。其中,文本风格的论文中,我们提出了一个新的序列编辑模型旨在解决如何生成与给定数值相匹配的句子的研究问题。而关于对话生成的论文中,我们提出了一个新的对话模型用于抑制对话生成模型中通用回复的生成。以下我们将分别介绍两篇论文。
QuaSE: 量化指导下的序列编辑


在这篇由腾讯 AI Lab 主导,与香港中文大学(The Chinese University of Hong Kong)合作完成的论文中,作者提出一种新的量化指标引导下的序列编辑模型,可以编辑生成与给定的量化指标相匹配的句子,未来可以扩展到诸如 CTR 引导下的新闻标题和摘要生成、广告描述生成等业务场景中。
研究问题
论文的主要任务是给定一个句子以及其对应的分数,例如 Yelp 平台上的用户评价“The food is terrible”以及其评分 1,然后我们设置一个目标分数,让模型能够生成与目标分数相匹配的句子,并且原句的主要内容在新的句子中必须得以保持。例如,给定数值 3,生成“The food is OK”。给定数值 5,生成“The food is extremely delicious”。
任务的挑战和特点主要有以下几方面:
1. 给定的数值可以是连续的,例如 2.5, 3.7, 4.1 等,意味着很难像机器翻译一样能够有人工标注的成对出现的训练样本;
2. 模型需要具有甄别句子中与数值相关的语义单元的能力;
3. 根据数值进行句子编写时,必须保持原句的主要内容。
模型框架
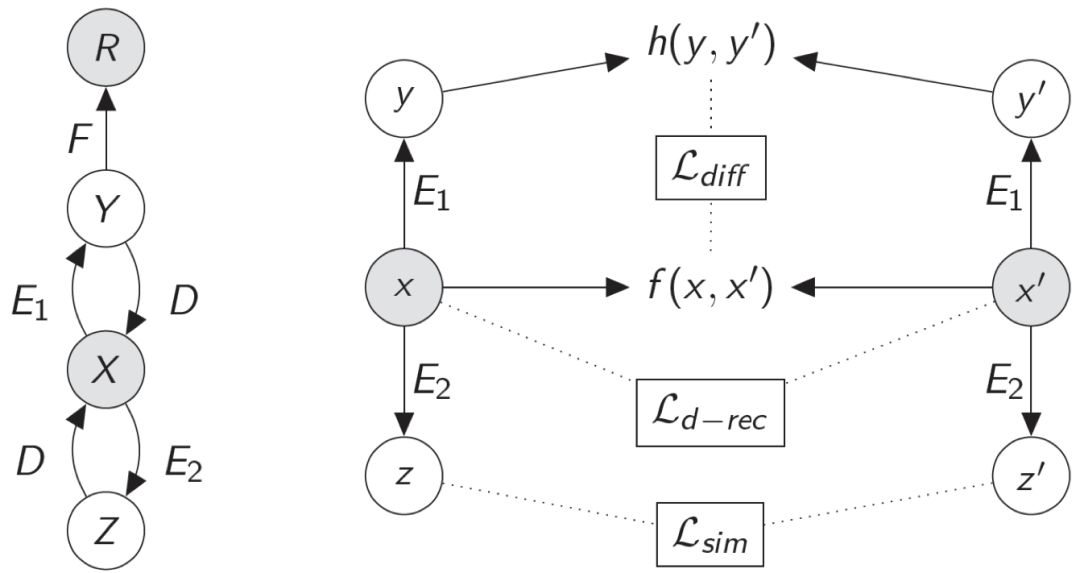
▲ 图1. QuaSE模型框架
图 1 为我们提出的模型 QuaSE 的框架,包含单句建模以及序列编辑两个部分的建模。左半部分为单句建模,其中 X 和 R 是观测值,分别表示句子(例如用户对餐厅的评价)以及其对应的数值(例如用户评分)。Z 和 Y 是隐变量,是对句子内容以及句子数值相关属性的建模表示。
受 Variational Auto-Encoders(VAE)模型的启发,对于隐变量 Z 和 Y 的建模是通过生成模型的方式实现。我们设计了两个 Encoder(E1 和 E2)和一个 Decoder (D),X 以 Z 和 Y 为条件进行生成。
模型的优化目标是使得生成的句子 X' 能够最大限度的重建输入句子 X。同时,由于优化目标积分计算困难等原因,我们采用变分的方法探寻优化目标的下界。单句建模的优化目标为:
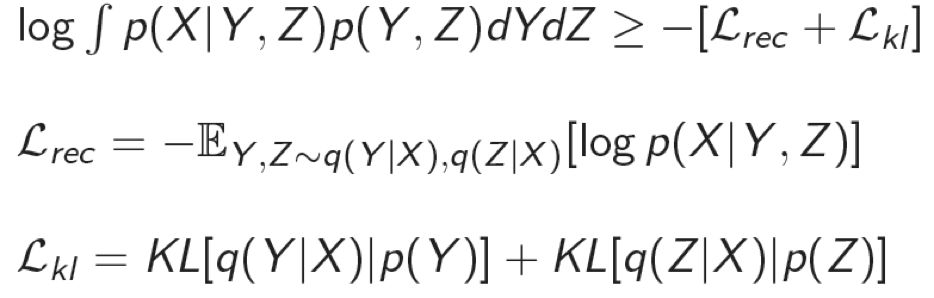
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1078
1078

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









