








作者丨文永亮
学校丨哈尔滨工业大学(深圳)
研究方向丨目标检测、GAN
推荐理由


这是一篇浙江大学和香港中文大学发表于 CVPR 2019 的论文,这篇文章十分有趣,网友戏称:“无痛涨点,实现简单,良心 paper”,在我看来确实是这样的,没有太大的改造结构,不需增加计算成本的条件下,居然能涨两个点 mAP。
除了本文解读的 Libra R-CNN(天秤座 RCNN)[1],我记得陈恺他们港中文的实验室今年还中了一篇 CVPR 2019,Region Proposal by Guided Anchoring [2],这篇也是不错的,看题目就知道是指导 anchor 的形状涨分的了。
这两篇改进的源码都会在 Github 上放出,作者表示还在完善中,地址是:
https://github.com/open-mmlab/mmdetection
三个不平衡
纵观目前主流的目标检测算法,无论 SSD、Faster R-CNN、Retinanet 这些的 detector 的设计其实都是三个步骤:
选择候选区域
提取特征
在 muti-task loss 下收敛
往往存在着三种层次的不平衡:
sample level
feature level
objective level
这就对应了三个问题:
采样的候选区域是否具有代表性?
提取出的不同 level 的特征是怎么才能真正地充分利用?
目前设计的损失函数能不能引导目标检测器更好地收敛?
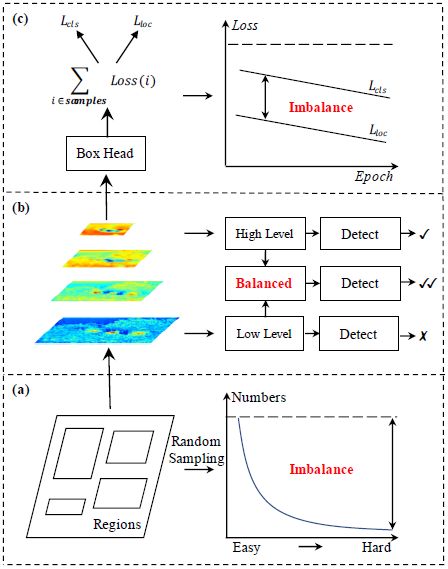
其实如果不对 detector 的结构做功夫的话,针对这些 imbalance 改进的其实就是为了把 detector 的真正功效给展现出来,就是如果把一个目标检测器 train 好的问题。
对应的三个改进
IoU-balanced Sampling
作者认为 sample level 的不平衡是因为随机采样造成的,Ross Girshick 后面提出了 OHEM(online hard example mining,在线困难样本挖掘)是一个 hard negative mining 的一种好方法,但是这种方法对噪音数据会比较敏感。随机采样造成的不平衡可以看下图:
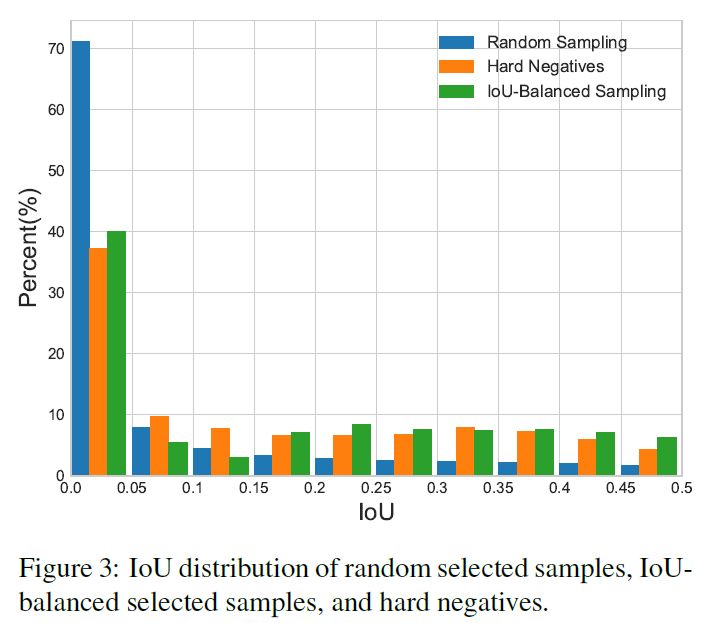
作者发现了如果是随机采样的话,随机采样到的样本超过 70% 都是在 IoU 在 0 到 0.05 之间的,有人会问不是随机吗?为什么大部分样本都落在了 IOU 较小的部分了呢?
因为样本的分布在 IoU 上并不是均匀分布的,生成候选框时随机采样会造成背景框远远大于框中 GT 的框,一张图这么大,是目标物体的区域只占很小一部分,背景占了绝大多数的位置,所以大部分样本都挤在了 IoU 在 0 到 0.05 的区间了。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章















 1283
1283











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









