







类别增量学习(CIL)或持续学习是智能系统在现实场景中亟需的关键能力,要求模型在持续学习新任务的同时保持原有知识的完整性。传统 CIL 方法主要依赖视觉信息进行特征提取,而近年来兴起的视觉-语言模型(VLM)通过融合文本模态数据,展现出更强的跨模态表征能力。
然而,当 VLM 在持续学习新类别时,往往会面临灾难性遗忘,因此将 VLM 应用于 CIL 面临两个主要挑战:1)如何在不遗忘的情况下微调模型;2)如何充分利用多模态信息。
为此,本文提出了 PROjectiOn Fusion(PROOF),使 VLM 能够在不遗忘的情况下学习。
为了应对第一个挑战,本文通过冻结图像/文本编码器,并学习轻量化投影模块,捕获任务信息。在面对新任务时,扩展新的投影,同时固定旧的投影,缓解了对旧概念的遗忘。
针对第二个挑战,本文提出了特征融合模块,以更好地利用跨模态信息。通过同时调整视觉和文本特征,模型能够更好地捕捉任务特定语义信息。在九个基准数据集上的广泛实验,涵盖了各种持续学习场景,验证了 PROOF 在性能上的领先优势。

论文标题:
Learning without Forgetting for Vision-Language Models
收录期刊:
TPAMI 2025
论文地址:
https://arxiv.org/pdf/2305.19270
代码链接:
https://github.com/zhoudw-zdw/PROOF

引言
在这个不断变化的世界中,训练数据通常以流的形式出现,其中新类别的数据不断涌现,这要求学习系统能够持续学习它们。然而,在 CIL 中,由于在训练过程中缺乏旧数据,持续学习新概念会覆盖旧知识,导致性能下降。在机器学习领域,人们已经做出了许多努力来应对灾难性遗忘。
近年来,CIL 研究从从头开始训练转向利用预训练模型(Pre-trained Models,PTM)。由于 PTM 本身已具备较强的泛化能力,能够捕捉视觉特征。因此,面对增量学习时的领域差距,它们只需要学习少量的额外参数。
当前基于预训练 ViT 的 CIL 方法侧重于学习视觉特征以识别新概念,但视觉语言模型(Vision-Language Models,VLM)的最新进展已经展示了文本信息在构建泛化特征表示方面的潜力。
作为一个具有代表性的 VLM,CLIP 将视觉和文本信息映射到共享的嵌入空间中,从而能够从不同模态稳健地学习和识别概念。这种视觉和文本模态的融合为开发能够有效适应现实世界场景的持续学习模型提供了新的方向。
将 VLM 扩展到 CIL 面临两个重大挑战。首先,顺序化地微调 VLM 会覆盖其固有的泛化能力和先前的概念,导致灾难性遗忘。其次,仅依靠文本信息进行分类会忽略多模态输入中存在的有价值的跨模态特征。因此,需要设计多模态融合机制,增强模型识别能力。
本文提出了投影融合(PROjectiOn Fusion,PROOF)方法,以解决 VLM 中的灾难性遗忘问题。为了使模型能保留过去的知识,本文冻结了预训练的图像/文本主干网络,并在输出结果上附加线性投影层。面对新任务时,在冻结旧投影层的基础上扩展新的投影层,从而保留先前的知识。
此外,本文通过跨模态融合整合不同模态的信息,从而使测试样本特征能够根据上下文信息进行调整。因此,PROOF 能够高效地学习新类别,同时防止遗忘旧类别,并在九个基准数据集上取得了最先进的性能。除了持续图片识别外,本文也在持续跨模态检索任务中验证了 PROOF 方法的有效性。本文的贡献可以总结如下:
本文提出了一个通用框架,使预训练的视觉-语言模型能够持续学习新类别而不会发生灾难性遗忘。
本文设计了一种新颖的投影融合机制,以增强模型的表征能力,并设计了一个跨模态融合模块来编码任务特定的信息。
PROOF 在九个基准数据集和一个非重叠数据集上达到了最先进的性能。得益于其通用性,PROOF 在持续跨模态检索任务中也展现了强劲的性能,超越了其他前沿方法。

PROOF
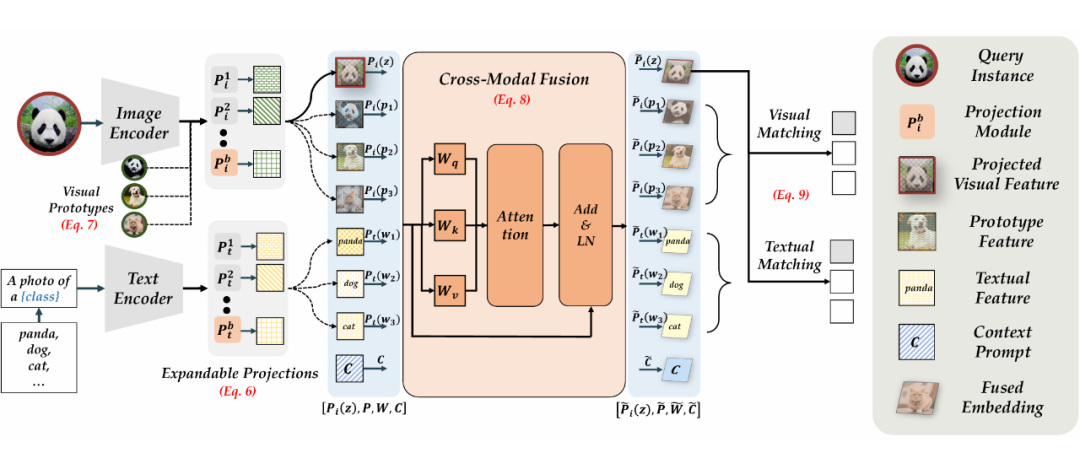
▲ 图1. PROOF 的模型架构
模型学习可扩展的投影并将它们相加以获得聚合特征。输入实例、原型特征、文本特征和上下文提示被输入到跨模态融合模块中。
该融合过程利用自注意力机制来融合多个输入,并输出融合后的特征。融合后的输入样本特征分别与视觉特征和文本特征中进行匹配,以获得最终预测。红色部分表示可训练,而灰色部分表示冻结。
2.1 可扩展特征投影
CLIP 以其强大的 zero-shot 性能而闻名,即使在没有对特定任务进行明确训练的情况下,也能获得具有竞争力的结果。
然而,鉴于预训练任务与下游任务之间的分布差异,需要一个适应过程来捕捉后者的特征。具体而言,本文引入了一个线性层(称为“投影”),它附加在冻结的图像和文本编码器之后,以促进成对投影特征的匹配。将视觉和文本端的投影层分别表示为
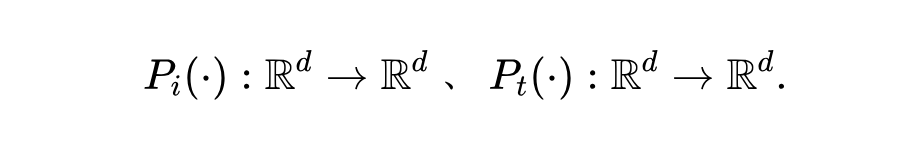
此时的 CLIP 预测结果表示为:
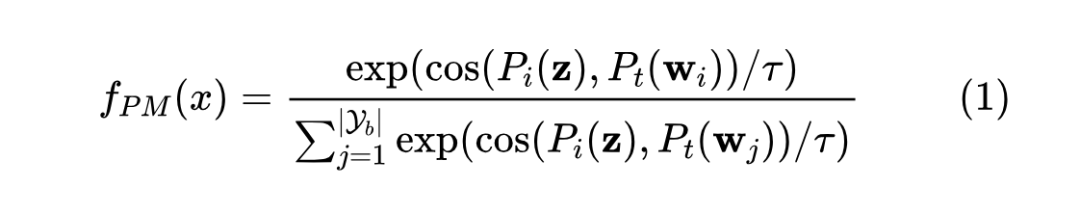
通过冻结图像和文本编码器,下游特征在投影空间中对齐,使得模型能够将相关的下游信息编码到投影层中。
由于预训练模型输出了可泛化的特征,投影层以数据驱动的方式学习重新组合这些特征。例如,在一个涉及“鸟类”的任务中,投影层会为“喙”和“翅膀”等特征分配更高的权重。这种适应使得投影后的特征能够更好地识别下游任务。
然而,顺序地训练单个投影层仍然会导致先前任务的遗忘,这在结合旧概念和新概念时会导致混淆。为此,本文为每个新任务扩展特定任务的投影。具体来说,当新任务到来时,添加一个新的投影层。从而构造出一系列投影层:
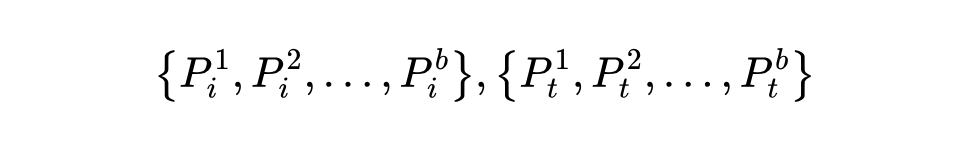
本文采用所有投影后的特征聚合作为对应模态的特征输出:
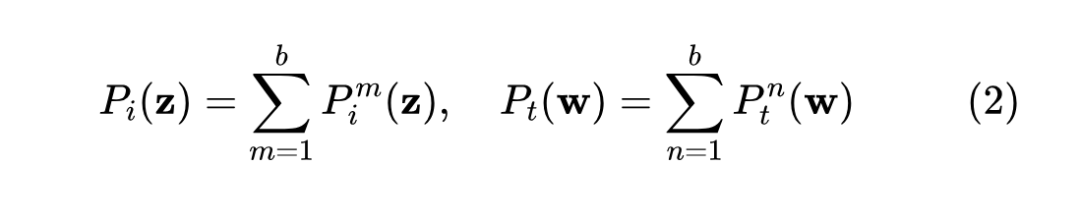
Eq.2 中来自不同阶段的投影特征被映射并聚合,以捕捉先前任务和后续任务的不同侧重点。例如,先前的任务可能强调用于鸟类识别的“喙”特征,而后续的任务可能专注于区分猫的“胡须”特征。
如何防止对先前投影的遗忘?
为了克服遗忘旧概念的问题,本文在学习新任务时冻结先前任务的投影,即:
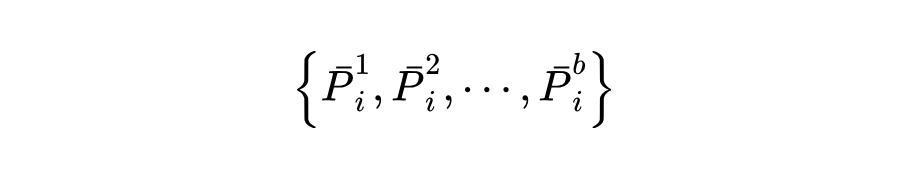
这允许新初始化的投影学习新任务的残差特征表示,在融入新概念的同时,保留先前任务的知识。
图 1(左)展示了投影的示意图。PROOF 基于预训练的编码器学习投影,能够在适应新模式的同时保持预训练模型的泛化能力。
每个投影层的参数数量是 d×d,与预训练模型的参数量相比是很小的。每个新任务学习任务特异化的投影,使模型能够有效捕捉新任务的特征。由于旧的投影被冻结,以前的知识得以保留,遗忘问题得以缓解。
2.2 投影融合机制
在 Eq.1 中,投影的视觉和文本特征直接在对齐后的空间中进行匹配。然而,进一步优化这些特征以捕捉图像和文本之间的上下文关系,将有助于提升模型性能。
例如,当输入实例是“熊猫”时,通过统一的方式调整视觉和文本特征,突出诸如黑色眼睛和耳朵等具有区分度的属性,能够显著提高模型的性能。同样,当输入实例是“猫”时,应该强调胡须和尾巴等特征。
因此,本文提出了一种集合到集合(set-to-set)的函数,用于样本特征和上下文信息。具体来说,本文将该函数表示为 T(⋅)。它接收样本特征和上下文信息作为输入集合,即
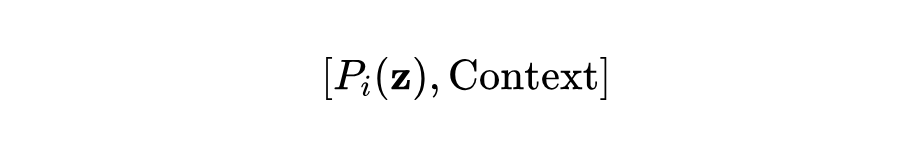
然后输出调整后的特征表示集合。接下来,本文将描述上下文信息 Context 的构建,并提供集合到集合函数的实现
如何定义上下文?
在 Eq.1 中,建立了测试样本特征和文本特征(即分类器)之间的映射。分类器是相应类别的文本特征。因此,一个简单的方法是利用文本特征作为上下文(Context):
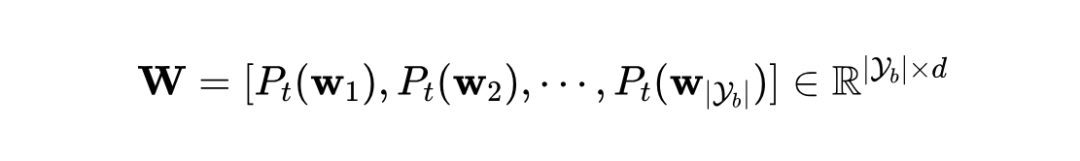
然而,最近的研究工作发现,在视觉语言模型(VLM)中,视觉特征和文本特征之间存在固有的分布差异。这种差异导致视觉和文本特征在特征空间中分布在两个不同的簇中,阻碍了有效的成对映射。因此,本文利用视觉原型特征作为捕捉每个类别共同特征的工具。本文将类别 k 的视觉原型定义为:
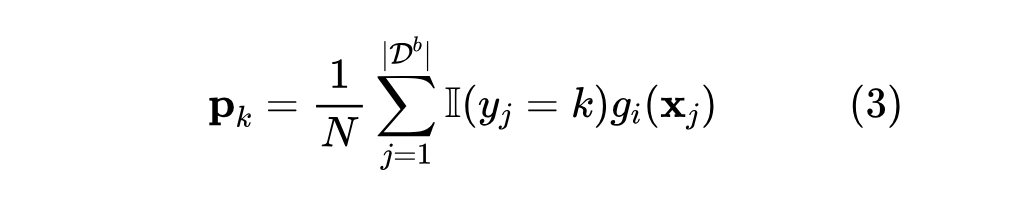
这些视觉原型在每个增量阶段开始时通过前向传播计算得到,并在后续任务中保持固定。视觉原型是相应类别的代表性特征,可以作为调整特征的上下文信息。因此,本文通过投影视觉信息来增强上下文,即 [P,W],其中 P 为:
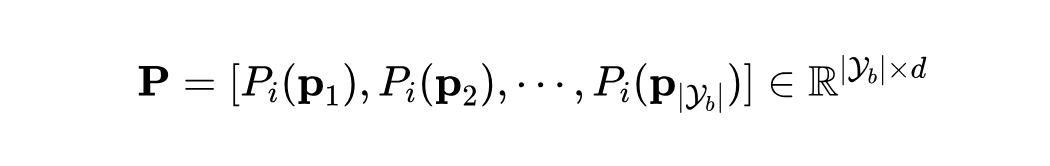
通过结合来自多种模态的特征,模型能够以跨模态的方式融合信息,从而超越了简单的视觉-文本匹配。
学习语境提示
除了视觉原型和文本分类器之外,本文还引入了一组可学习的上下文提示:
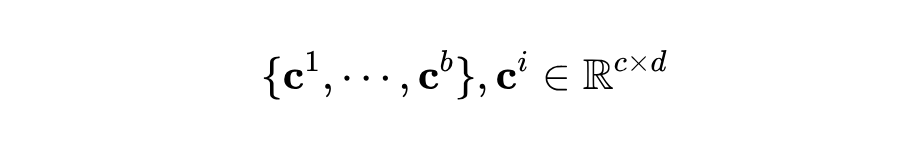
c 表示每个提示的长度。与投影层类似,本文使上下文提示具有可扩展性,以便捕捉新任务的新特征。在学习新任务时,本文会初始化一个新的上下文提示,并冻结之前的提示 。这些上下文提示作为上下文信息,增强了协同适应性。上下文信息被构建为 :
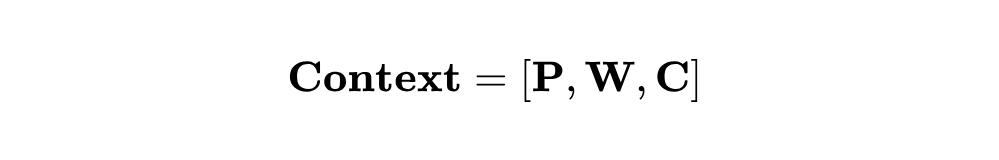
利用自注意力实现 T
在本文的实现中,使用自注意力机制作为跨模态融合函数 T。由于自注意力具有排列不变性,它擅长输出适应性特征表示,即使在存在长距离依赖的情况下也能很好地发挥作用。具体来说,自注意力机制中包含三元组权重(Q, K, V)。输入被投影到相同的空间中,即:
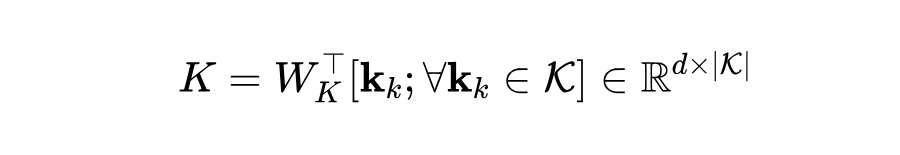
对于 Q 和 V 也进行类似的投影。查询 Q 与一系列 K 进行匹配,输出是所有值的总和,这些值根据键与查询点的接近程度进行加权:
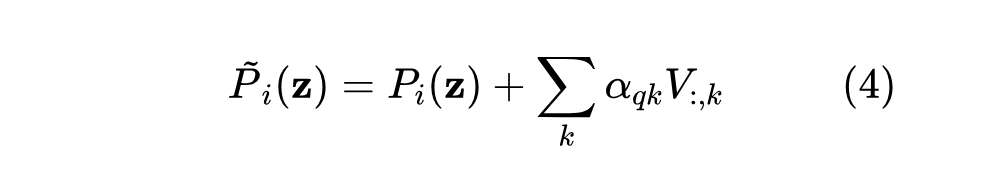
融合过程对于上下文中的其他组件也是相同的。具体来说,有:
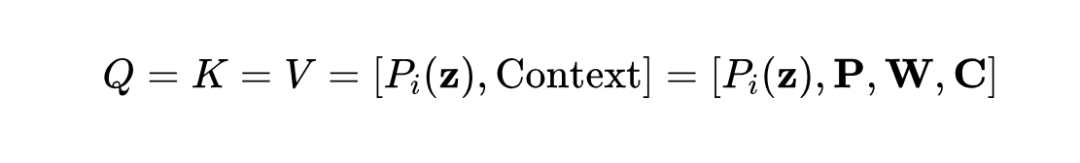
融合后的特征能反应上下文信息,记作:
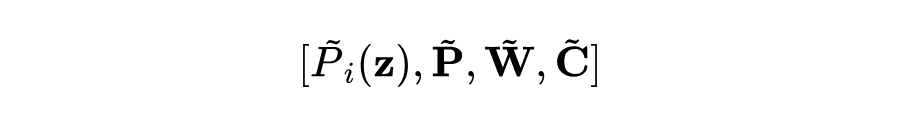
跨模态融合的效果
图1(右)展示了投影融合的示意图。本文利用已见类别的视觉和文本特征作为上下文信息,以帮助调整特定实例的特征表示。有了上下文化信息的特征表示,本文可以进行视觉匹配和文本匹配:
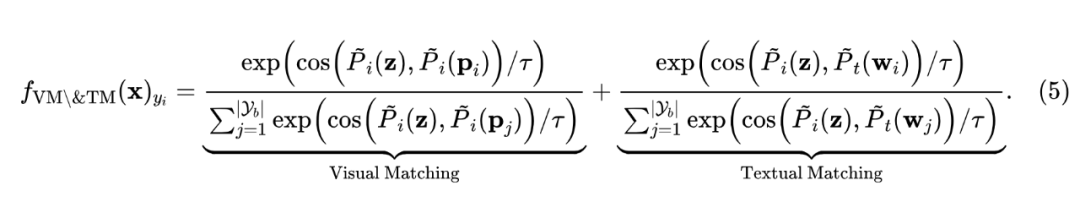
在 Eq.5 中,模型通过与融合后的视觉和文本原型的相似性为测试实例分配 logits。跨模态匹配的引入改善了预测性能。请注意,Context C 仅将任务特定信息编码到融合过程中,即它在 Eq.5 中不作为匹配目标。
2.3 总结
在 PROOF 中,首先通过投影映射学习新概念。为了在不遗忘先前概念的情况下学习新概念,为每个新任务初始化新的投影,并冻结之前的投影。
此外,本文利用自注意力融合的方式调整测试样本特征和上下文信息的表示。图 1 展示了三个匹配目标,即投影匹配(Eq.1)、视觉/文本匹配(Eq.5)。在训练过程中,本文优化交叉熵损失:
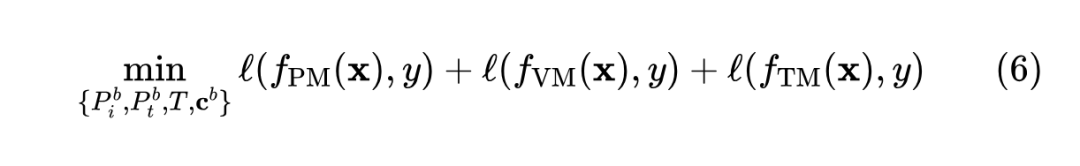
在 Eq.6 中,所有预训练的权重都被冻结,本文只优化这些额外的参数。在推理过程中,本文聚合这三个 logits 作为推理结果。

实验
3.1 数据集及其划分
数据集:本文参考 CLIP 提示学习的 Benchmark,定义了利用 CLIP 进行类别增量学习的 9 个基准数据集与数据划分,包含 CIFAR100、CUB200、ImageNet-R、ObjectNet、FGVCAircraft、Stanfordcars、Food101、SUN397、UCF101 共 9 个数据集。
数据集划分:数据集的划分表示为 Base-x, Inc-y,其中 x 代表第一阶段中的类别数量,y 代表每个后续任务中的新类别数量。x = 0 表示每个任务包含 y 个类别。
3.2 实验结果
在图 2 中,本文将 PROOF 的性能与 CoOp、iCaRL、MEMO、L2P、DualPrompt、CODA-Prompt、DAP、PLOT 等方法进行了对比。从实验结果中,本文得出以下三个主要结论:
1. 在第一阶段,PROOF 的性能优于典型的提示学习方法 CoOp,从而验证了学习投影对于下游任务的有效性。
2. PROOF 的性能曲线在所有方法中始终名列前茅,展示了其抵抗遗忘的能力。
3. 与仅依赖视觉的方法(即 L2P、DualPrompt、CODA-Prompt、DAP)相比,PROOF 表现出显著的改进,表明文本和视觉信息的协同适应能够有效促进增量学习。
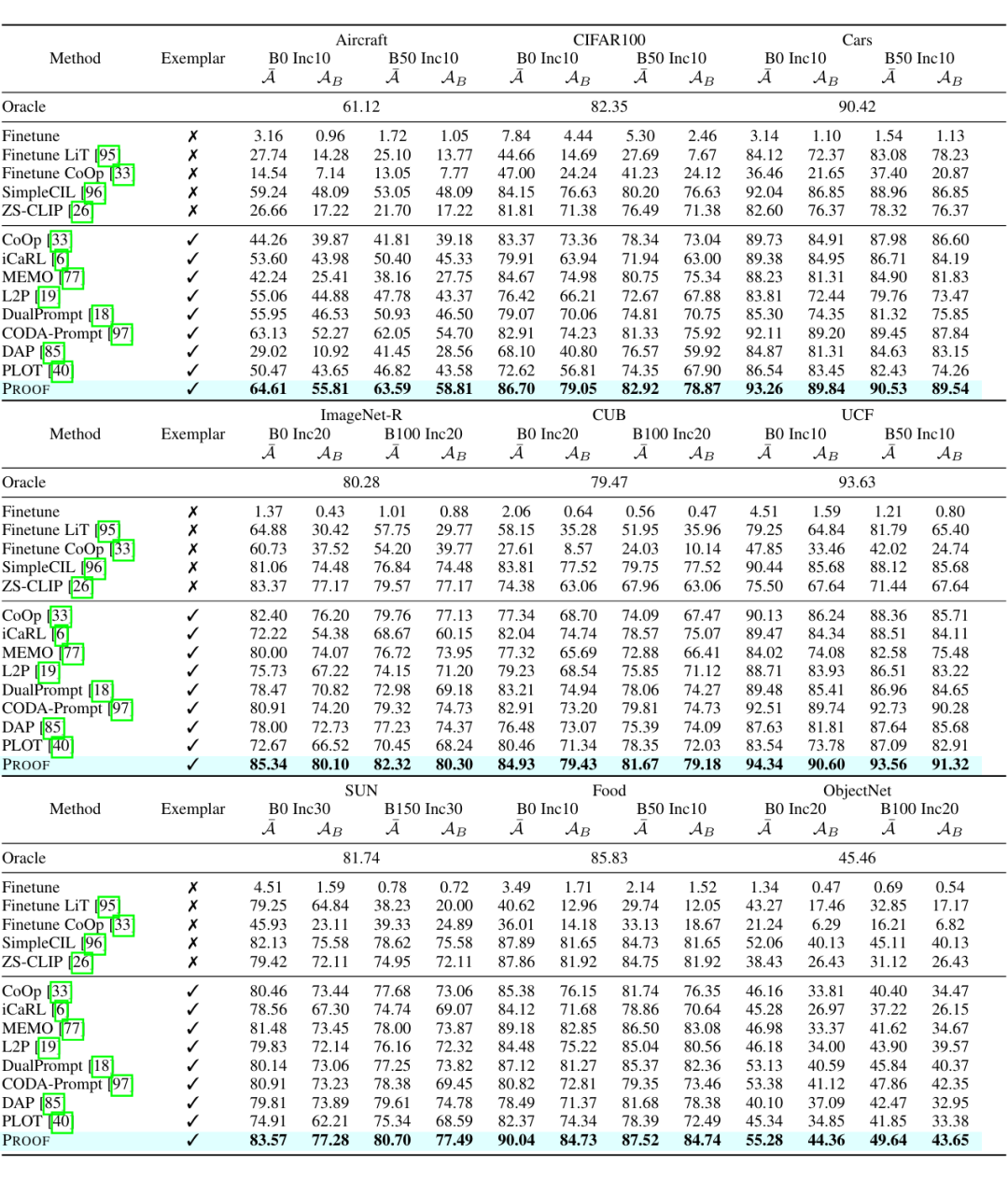
图2:不同方法的平均准确率和最终准确率
3.3 将 PROOF 扩展到其他视觉语言模型和其他应用
本文在前面的章节中使用 CLIP 作为视觉语言模型。然而,视觉语言模型(VLM)领域发展迅速,存在多种可用模型。
在本节中,本文将 PROOF 扩展到另一个广泛使用的 VLM——BEiT-3,并专注于跨模态检索任务。BEiT-3 是一个流行的 VLM,在多个视觉-语言任务中表现出色。由于检索任务与分类任务不同,本文通过仅采用投影扩展策略而不进行跨模态融合来简化 PROOF。
为了评估,本文使用 Flickr30K 数据集来评估增量跨模态检索的性能。Flickr30K 包含从 Flickr 图片共享平台收集的 31,783 张图片,涵盖日常生活、旅行、人物、食物和场景等多种主题。每张图片都附有五段手动注释的文本描述,提供了图片主要内容和上下文的描述性信息。
为了构建一个增量数据流,本文使用关键词匹配来识别包含不同动作(walk、stand、run、ride、play)的图片,并根据这些动作将训练实例划分为五个子集。为了创建平衡的测试集,本文在划分训练和测试对时保持 5:1 的训练-测试比例。
本文采用标准的跨模态检索指标进行评估,即 R@1、R@5 和 R@10。检索在两个方向上进行:图片→文本和文本→图片。与 CIL 评估类似,本文报告最后一个召回率 和跨增量阶段的平均召回率 。
为了进行比较分析,本文将 PROOF 与典型的微调方法作为基线进行比较,并修改 MEMO 和 DER 进行比较。这些方法代表了当前任务微调的最先进的持续学习方法。
实验结果如图 3 和图 4 所示。从图表中可以看出,直接对新概念进行微调会导致跨模态检索任务中的灾难性遗忘。
然而,为模型配备增量学习能力可以有效缓解遗忘。在所有比较方法中,PROOF 在不同的检索任务和指标上始终表现最佳,验证了其在减轻 VLM 遗忘方面的有效性。总之,即使在不同的 VLM 和持续学习环境中,PROOF 也表现出更强的竞争力。
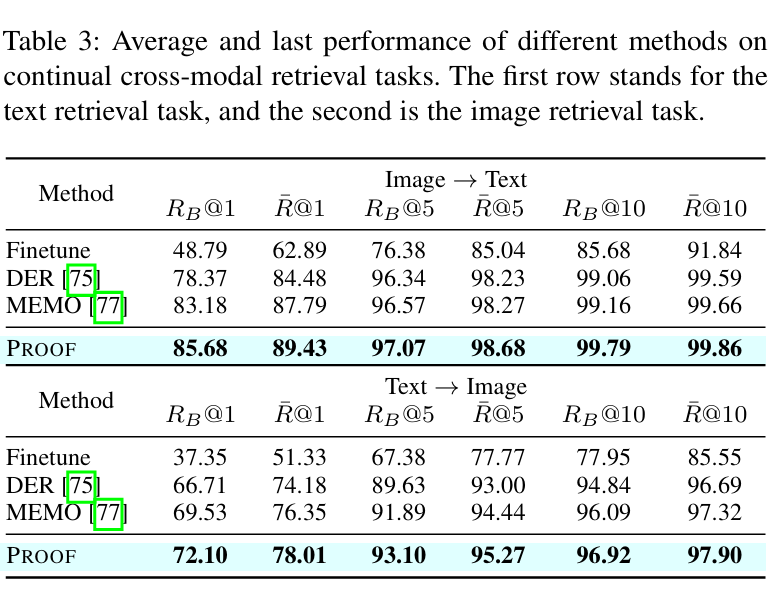
▲ 图3. 不同方法在持续跨模态检索任务中的平均性能和最终性能,上面的表格描述的是文本检索任务,下面的表格描述的是图像检索任务
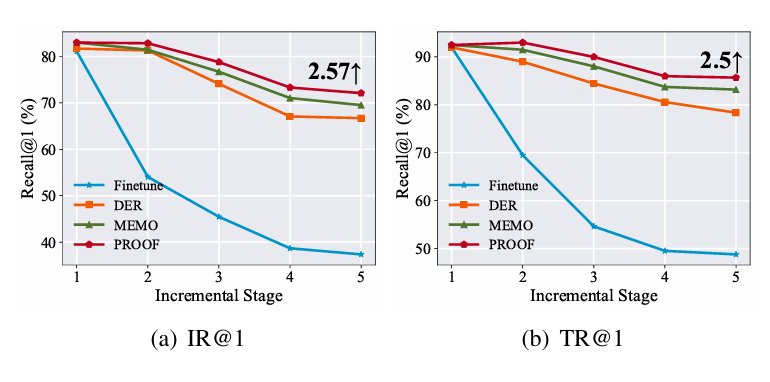
图4. 每种方法的性能趋势图。IR 表示图像检索的召回率,TR 表示文本检索的召回率。PROOF 在持续跨模态检索任务上始终优于其他对比方法,且优势显著。
3.4 在非重叠数据集上的类别增量学习
本文在前文中验证了 PROOF 在基准数据集上的性能。然而,由于 CLIP 在预训练阶段使用了海量数据,这些基准数据集可能与 CLIP 的预训练数据集存在重叠。因此,本文手动收集了一个新的数据集,用于评估 CLIP 发布后的电视节目分类任务,即 TV100。
数据集构建:CLIP 于 2021 年提出,其训练数据是从互联网收集的图像-文本对(2021 年之前)。因此,如果能够收集 2021 年之后的新数据集,可以确保 CLIP 未接触过这些新知识。为此,本文选择了一个每天都有新类别出现的领域——电视节目。
具体来说,本文从 IMDB 搜索 2021 年之后发布的电视节目,并通过 Google 搜索关键词 “[NAME] TVSeries”(其中 [NAME] 为电视节目名称)下载相关图片。
下载的图片经过手动处理,删除重复和无意义的图片,最终得到一个包含约 800 个类别的大型数据集,之后,通过评估每个类别的 CLIP 零样本性能,选择其中最难的 100 个类用于 CLIP 持续学习。
本文在新数据集上进行实验。与其他设置相同,本文选择了两种数据集划分(即 Base0 Inc10 和 Base50 Inc10),并在图 5 中报告结果。
从图中可以得出两个主要结论:首先,zero-CLIP 在该数据集上表现不佳,说明该数据集能够有效评估 CLIP 的持续学习能力;其次,PROOF 在该数据集上仍然显著优于其他对比方法,验证了其在持续学习任务中的强劲性能。
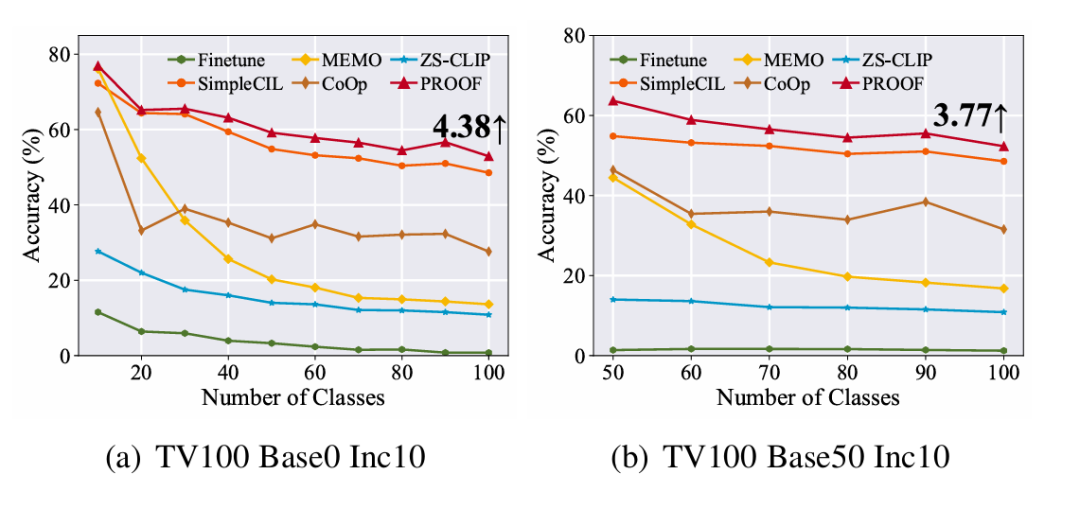
▲ 图5:TV 数据集实验结果
3.5 探索零样本性能
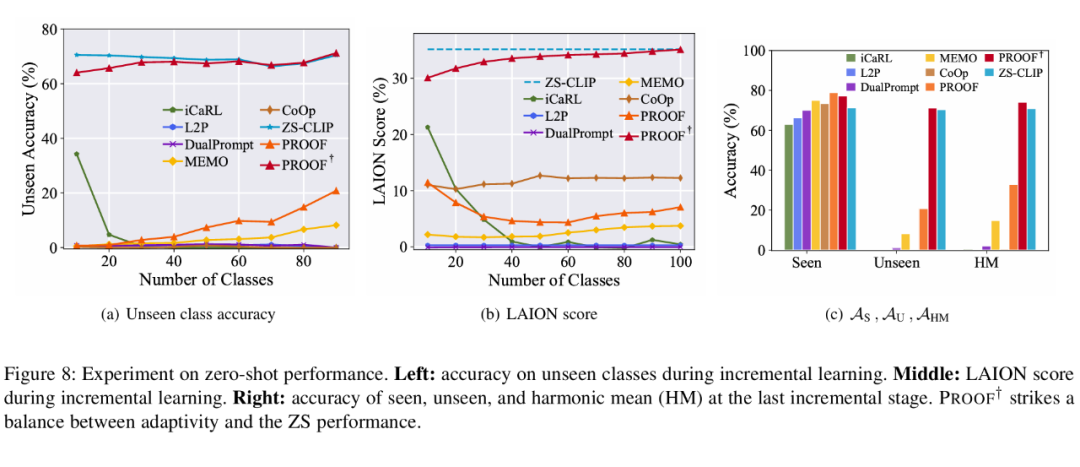
▲ 图6:零样本性能实验。左图:增量学习过程中未见类别的准确率。中图:增量学习过程中的 LAION 分数。右图:最后一个增量阶段中已见类别、未见类别以及调和平均值(HM)的准确率。PROOF† 在适应性和零样本性能之间取得了平衡。
CLIP 以其零样本(ZS)能力著称,即使模型未经过特定图像的训练,仍能通过匹配余弦相似度预测图像 x 属于类别 y 的可能性。CLIP 的强大泛化能力使其成为计算机视觉领域的流行模型。
然而,在持续学习(CIL)中,模型会随着下游任务的不断更新而削弱泛化能力,进而损害后续任务的零样本性能。在本节中,探讨了 CLIP 的零样本性能下降问题,并提出了 PROOF 的一个变体以保持零样本性能。
零样本性能的评估方式:当前的持续学习方法主要评估“已见”类别的性能。然而,由于 CLIP 具有零样本能力,本文也可以评估“未见”类别的性能,以研究零样本性能的变化。因此,本文在每个任务后计算性能指标 AS(已见类别)、AU(未见类别)和 AHM(AS 和 AU 的调和平均值)。
此外,本文还利用了来自 LAION-400M 的 10,000 对图像-文本数据集,计算它们的匹配分数。本文将平均匹配分数称为 LAION 分数,该分数反映了模型在上游任务上的匹配程度。鉴于泛化能力与上游任务之间的关系,LAION 分数是零样本性能的有效衡量标准。
除了前文提到的方法外,本文还报告了 PROOF 的一个变体,即 PROOF†。其唯一区别在于投影的设计,PROOF† 采用残差格式作为输出:
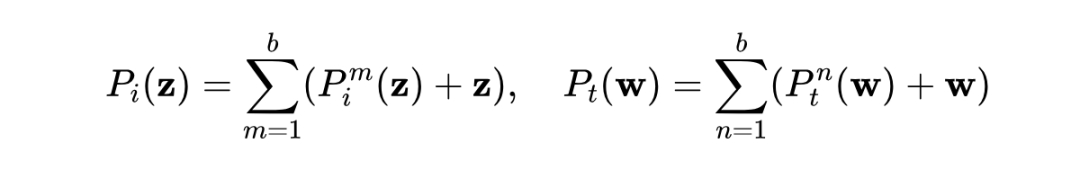
为了研究模型更新时的零样本性能,本文在图 6(a)中展示了增量阶段中未见类别 AU 的准确率,其中 ZS-CLIP 表现最佳。
相应地,由于将预训练信息 z 和 w 整合到投影特征中,PROOF† 保持了较好的零样本性能。这表明保留预训练信息有助于维持模型的泛化能力。相反,其他方法由于将重点转移到下游任务上,零样本性能显著下降。
本文在图 6(b)中观察到类似的趋势,其中 PROOF† 取得了与 ZS-CLIP 相近的 LAION 分数。最后,本文在图 6(c)中报告了最后一个增量阶段的 AS、AU、AHM。可以推断出,下游任务的适应性和零样本性能的泛化能力之间存在权衡。
与 PROOF 相比,PROOF† 牺牲了部分适应性以保持零样本性能,在已见类别和未见类别之间取得了平衡。因此,当零样本性能至关重要时,使用 PROOF† 是首选。

总结
现实世界的学习系统需要具备不断获取新知识的能力。本文旨在使流行的视觉语言模型(VLM)具备持续学习(CIL)的能力。具体来说,本文通过学习可扩展的投影,使视觉和文本信息能够逐步对齐。这种扩展技术使模型能够在学习新概念的同时不遗忘先前的知识。
此外,本文通过自注意力机制实现跨模态融合。大量的实验验证了本文提出的 PROOF 在各种 VLM 和持续学习场景中的有效性。

参考文献
[1] Zhou, et al. Class-incremental learning: A survey. IEEE Transactions on Pattern Analysis and Machine Intelligence 2024
[2] Zhou et al. Continual learning with pre-trained models: a survey. IJCAI 2024
[3] Zhou et al. TV100: a TV series dataset that pre-trained CLIP has not seen. Frontiers of Computer Science 2024
[4] Zhou et al. External Knowledge Injection for CLIP-Based Class-Incremental Learning. arXiv preprint arXiv:2503.08510
更多阅读




#投 稿 通 道#
让你的文字被更多人看到
如何才能让更多的优质内容以更短路径到达读者群体,缩短读者寻找优质内容的成本呢?答案就是:你不认识的人。
总有一些你不认识的人,知道你想知道的东西。PaperWeekly 或许可以成为一座桥梁,促使不同背景、不同方向的学者和学术灵感相互碰撞,迸发出更多的可能性。
PaperWeekly 鼓励高校实验室或个人,在我们的平台上分享各类优质内容,可以是最新论文解读,也可以是学术热点剖析、科研心得或竞赛经验讲解等。我们的目的只有一个,让知识真正流动起来。
📝 稿件基本要求:
• 文章确系个人原创作品,未曾在公开渠道发表,如为其他平台已发表或待发表的文章,请明确标注
• 稿件建议以 markdown 格式撰写,文中配图以附件形式发送,要求图片清晰,无版权问题
• PaperWeekly 尊重原作者署名权,并将为每篇被采纳的原创首发稿件,提供业内具有竞争力稿酬,具体依据文章阅读量和文章质量阶梯制结算
📬 投稿通道:
• 投稿邮箱:hr@paperweekly.site
• 来稿请备注即时联系方式(微信),以便我们在稿件选用的第一时间联系作者
• 您也可以直接添加小编微信(pwbot02)快速投稿,备注:姓名-投稿

△长按添加PaperWeekly小编
🔍
现在,在「知乎」也能找到我们了
进入知乎首页搜索「PaperWeekly」
点击「关注」订阅我们的专栏吧
·


















 79
79

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









