






2025深度学习发论文&模型涨点之——机器学习可解释性
机器学习可解释性(Explainable Machine Learning, XML)是指让人类能够理解机器学习模型在其决策过程中所做出的选择,包括“怎么决策”“为什么决策”以及“决策了什么”。其核心目标是提高机器学习系统的透明度和可信度,使模型的预测和决策过程对用户而言是可理解的。
-
确保公平性:通过分析特征的相互作用,了解哪些特征在模型决策中起主导作用,从而避免模型因某些特征而产生不公平的决策。
-
验证可靠性:能够解释模型为什么做出某个特定决策,帮助用户验证模型的决策逻辑是否合理。
小编整理了一些机器学习可解释性【论文】合集,以下放出部分,全部论文PDF版皆可领取。
需要的同学扫码添加我
回复“机器学习可解释性”即可全部领取

论文精选
论文1:
Further Insights: Balancing Privacy, Explainability, and Utility in Machine Learning-based Tabular Data Analysis
进一步洞察:在基于机器学习的表格数据分析中平衡隐私、可解释性和效用
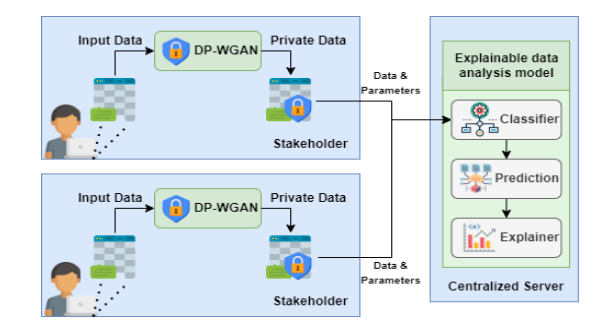
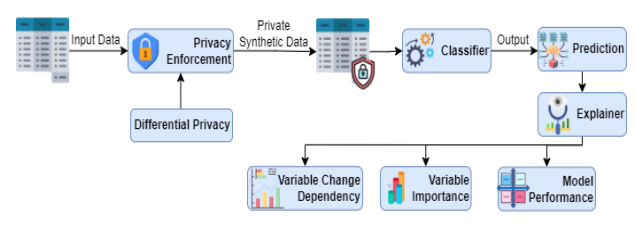
方法
-
隐私保护机制:采用(𝜋?,𝛿)-差分隐私与生成对抗网络(GAN)相结合的方法,通过向数据中添加噪声来保护隐私,同时利用GAN生成与原始数据分布相似的合成数据。
可解释性方法:运用多种模型解释方法,如模型性能评估、变量重要性分析、部分依赖(PD)曲线和累积局部(AL)依赖曲线,以提供模型决策的解释。
优化框架:提出一个综合优化标准,通过调整隐私参数和探索不同配置,找到在隐私保护、模型可解释性和数据效用之间达到最佳平衡的配置。
兼容性矩阵:构建一个三维兼容性矩阵,用于评估不同隐私程度、可解释性方法和数据集之间的兼容性,并确定最优配置。
创新点
-
隐私与效用的平衡:通过优化框架,成功地在隐私保护和数据效用之间找到了平衡,即使在严格的隐私约束下(如𝜋? = 1),某些分类器(如逻辑回归和多层感知器)仍能保持较高的数据效用和模型解释性,模型性能的准确率几乎不受隐私保护措施的影响。
隐私参数的灵活调节:研究结果表明,隐私参数与权衡分数之间存在正相关关系,通过调整隐私参数,可以灵活地在隐私保护和数据效用之间进行权衡,为实际应用中隐私保护程度的选择提供了理论依据。
模型解释性的提升:通过实验验证了不同可解释性方法对隐私保护和效用的影响,发现某些解释方法(如模型性能解释)在隐私保护下仍能提供高质量的解释,这对于提高模型的透明度和用户信任度具有重要意义。
兼容性矩阵的应用:利用兼容性矩阵全面评估了不同配置下的权衡结果,为不同利益相关者提供了根据自身需求选择最优配置的工具,提高了隐私保护和可解释性方法在实际应用中的灵活性和适用性。
论文2:
Investigating Adversarial Attacks in Software Analytics via Machine Learning Explainability
通过机器学习可解释性研究软件分析中的对抗攻击
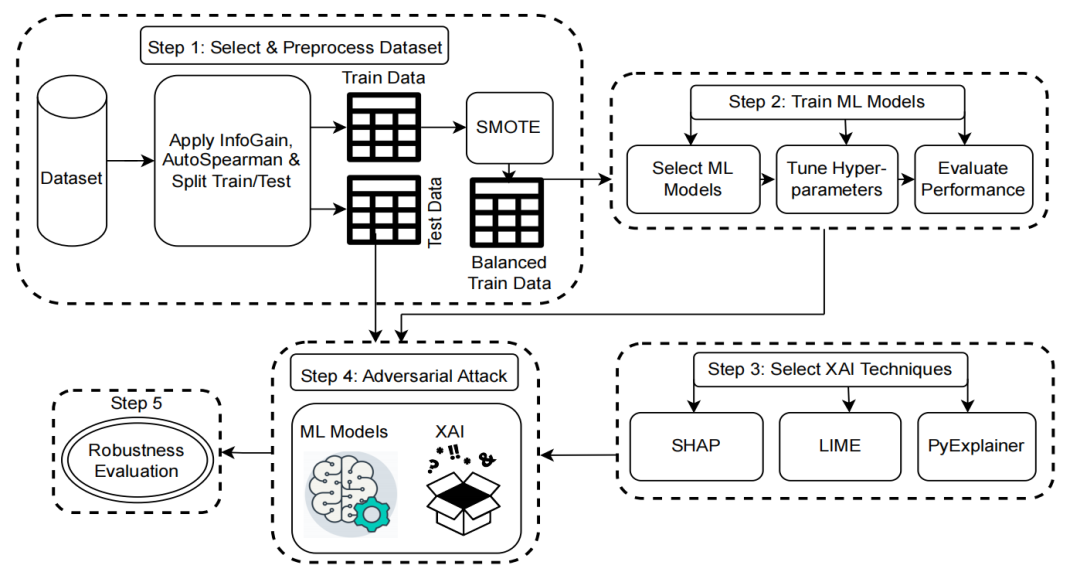
方法
-
对抗攻击方法:提出了一种基于机器学习可解释性的对抗攻击方法,通过修改由可解释性技术识别的最重要特征来生成对抗样本。
特征空间扰动:专注于在特征空间中进行扰动,而不是直接在输入空间中进行,通过修改顶部1-3个重要特征来成功欺骗机器学习模型。
多目标优化:采用多目标优化函数,同时最小化修改的特征数量(ℓ0扰动)和最大化攻击成功率(ASR),以生成在特征空间中难以察觉的对抗样本。
实验验证:在六个不同数据集上进行了广泛的实验,涵盖了代码缺陷预测、代码克隆检测和代码审查评论分类等任务,验证了所提出方法的有效性。
创新点
-
攻击成功率的显著提升:通过修改最多三个重要特征,成功地使机器学习模型在软件分析任务中的准确率下降高达86.6%,显著高于其他现有方法,如Zoo攻击、边界攻击和HopSkipJump攻击。
特征空间攻击的创新性:首次在软件分析任务中探索了基于特征空间的对抗攻击,与以往主要针对输入空间的攻击方法不同,这种方法更符合软件分析中数据的特性和应用场景。
可解释性技术的应用:利用机器学习可解释性技术(如SHAP、LIME和PyExplainer)来识别影响模型决策的重要特征,并基于这些特征生成对抗样本,为评估模型的鲁棒性提供了一种新的视角。
对抗样本的不可察觉性:通过最小化修改的特征数量,确保生成的对抗样本在特征空间中难以被察觉,从而在保持攻击有效性的同时,降低了攻击被发现的风险。
论文3:
Regulating Explainability in Machine Learning Applications – Observations from a Policy Design Experiment
监管机器学习应用中的可解释性——来自政策设计实验的观察
方法
-
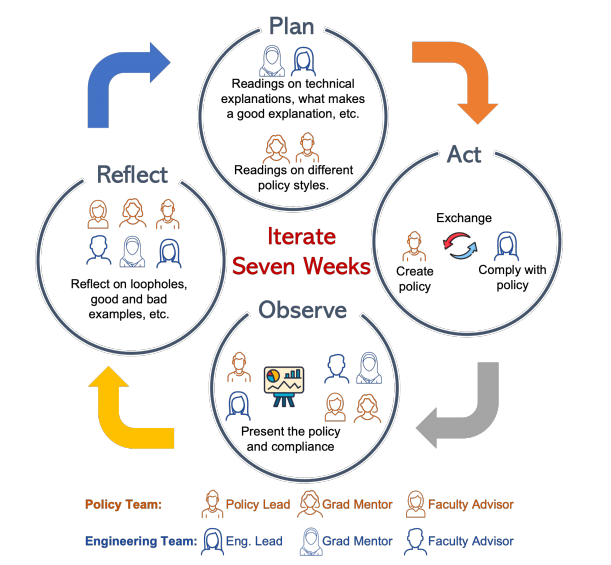
跨学科合作:通过跨学科团队(包括计算机科学、社会学和政策背景的研究人员)进行为期十周的实验性政策设计研究,共同制定和优化AI可解释性政策。
迭代政策设计:采用迭代和持续反馈的方法,每周进行政策草案的制定、尝试遵守或规避政策,并集体评估其有效性。
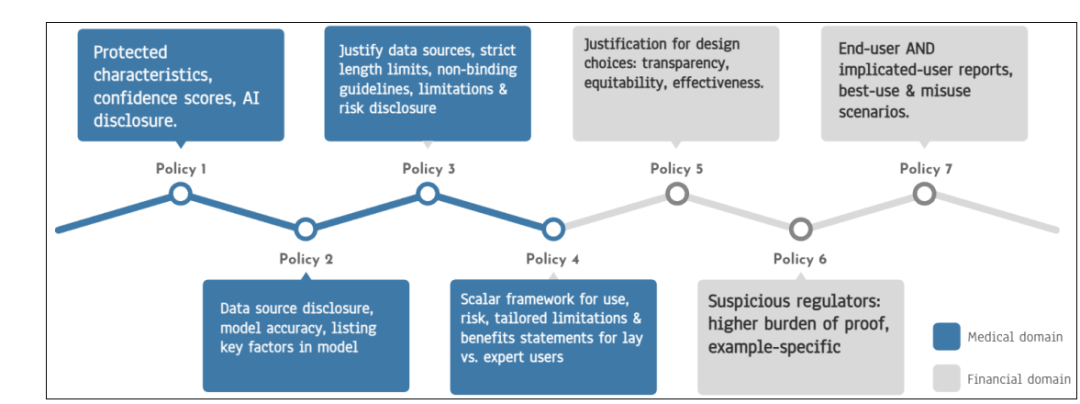
证据收集与评估:在政策设计过程中,讨论了如何通过技术证据(如SHAP值、模型卡)和人类主体研究来证明政策的合规性。
政策目标和受众的明确性:强调在政策设计中明确政策目标、受众以及所需证据的重要性,以确保政策的可执行性和有效性。
创新点
-
跨学科合作的成功:证明了在短时间内(约两个月)通过跨学科合作可以成功制定出具有可操作性和可执行性的AI可解释性政策,为政策制定者提供了新的合作模式。
政策草案的显著改进:通过迭代过程,政策草案从最初的模糊和不切实际,逐渐发展为更具体、更具操作性和可执行性的政策,显著提高了政策的质量。
人类主体研究的重要性:发现人类主体研究是评估解释有效性的重要证据形式,补充了技术方法的不足,为政策制定提供了更全面的视角。
政策目标和受众的明确化:明确了政策的目标和受众,使得政策更具针对性和有效性,为AI应用中的可解释性提供了更清晰的指导。
论文4:
The efficacy of machine learning models in lung cancer risk prediction with explainability
机器学习模型在肺癌风险预测中的效能与可解释性
方法
-
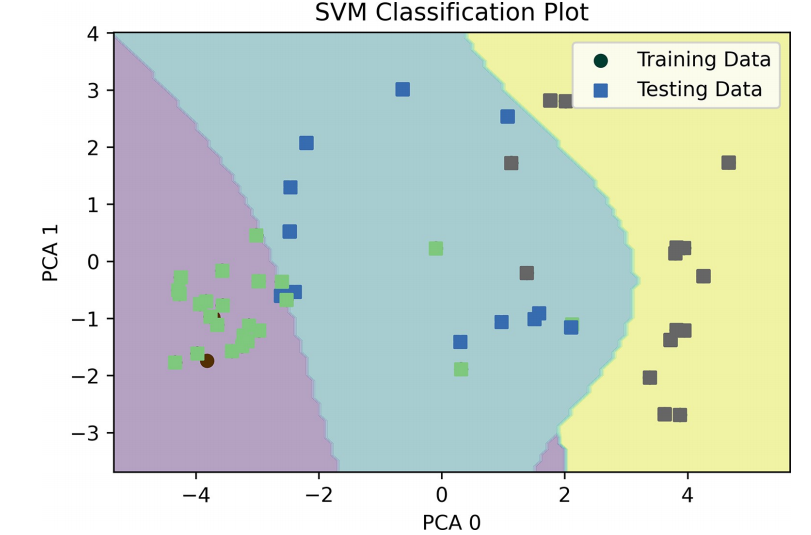
机器学习模型选择:选择了四种广为人知的机器学习模型(支持向量机(SVM)、K最近邻(KNN)、决策树(DT)和随机森林(RF))来训练和验证数据,以预测肺癌风险因素。
超参数调整:使用网格搜索算法对模型的超参数进行调整,以找到最佳参数组合,提高模型的预测性能。
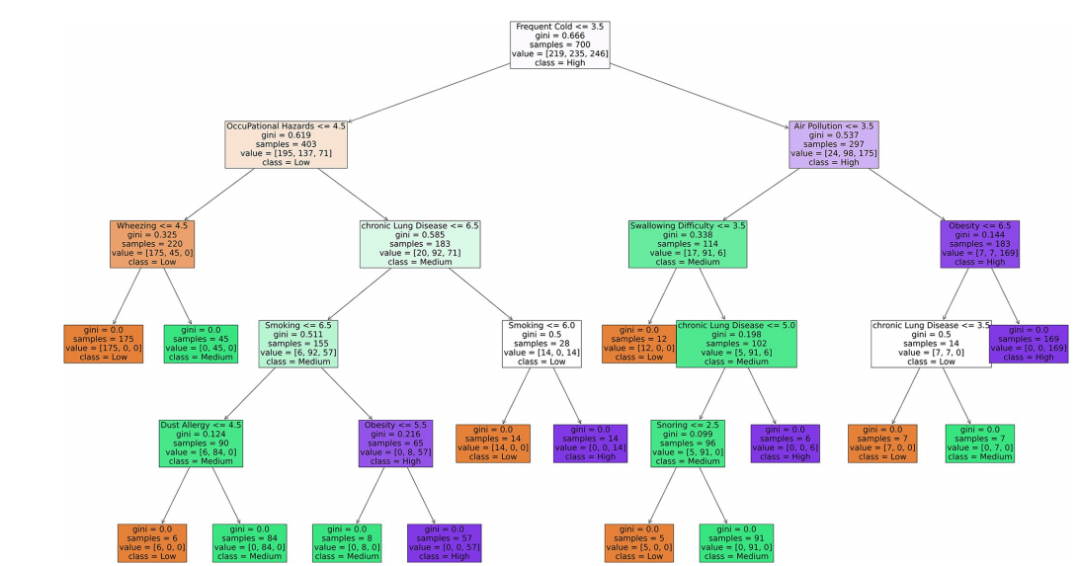
特征重要性评估:利用随机森林分类器计算特征重要性,识别对肺癌风险预测最具影响力的特征。
模型可解释性分析:采用决策边界、局部可解释模型无关解释(LIME)和树提取等方法,对模型的预测结果进行解释,增强模型的可解释性。
创新点
-
模型性能的显著提升:通过超参数调整,所有四种模型(SVM、KNN、DT、RF)的测试准确率均达到99%至100%,相较于之前的研究结果有了显著提升,例如在类似数据集上,SVM的准确率从99.2%提升至100%,KNN的准确率从92%提升至99%。
可解释性的增强:为每个模型提供了逻辑解释,通过决策边界、LIME和树提取等方法,解释了模型为何会做出特定的决策,这有助于提高患者和医疗工作者对模型的信任。
特征重要性的明确识别:通过随机森林分类器计算特征重要性,明确了哪些特征对肺癌风险预测最具影响力,为临床决策提供了更有力的支持。
数据集的深入分析:对肺癌相关参数的数据集进行了深入分析,揭示了不同特征之间的关系,为肺癌风险预测提供了更全面的理解。
小编整理了机器学习可解释性论文代码合集
需要的同学扫码添加我
回复“ 机器学习可解释性”即可全部领取


















 113
113

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









