







 超级会员免费看
超级会员免费看
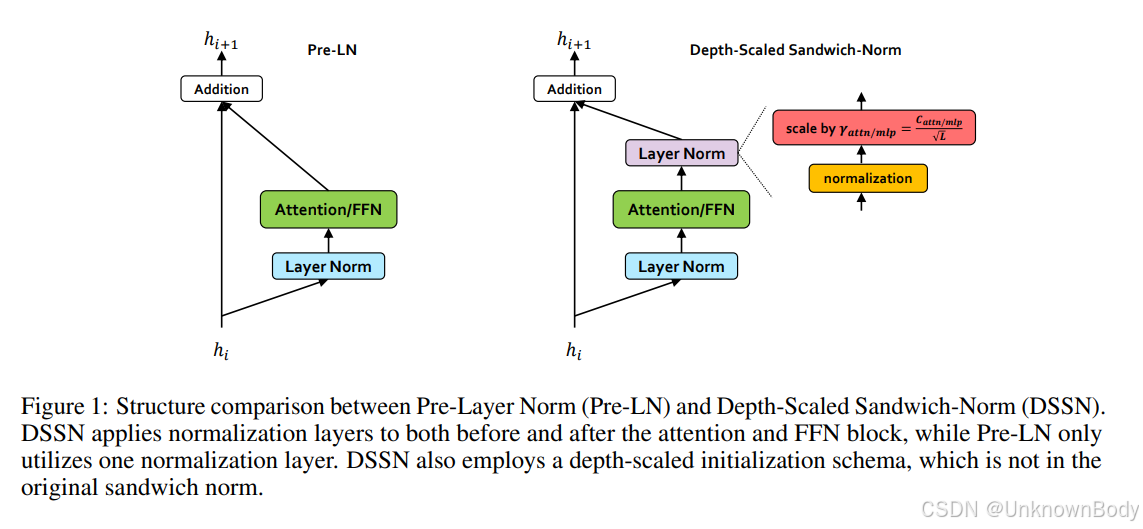
主要内容
- 模型架构:Pangu Ultra采用与Llama 3相似的基本架构,有1350亿参数、94层,隐藏层维度为12,288,SwiGLU前馈网络中间层大小为28,672 。通过提出深度缩放三明治归一化(Depth-Scaled Sandwich-Norm)和TinyInit参数初始化方法,解决大规模密集型语言模型训练稳定性和收敛性的根本挑战。同时,采用领域感知词汇表策略设计分词器。
- 模型训练:训练过程包括预训练、长上下文扩展和后训练三个主要阶段。预训练使用精心构建的13.2万亿高质量多样本数据集,分阶段提升模型能力;长上下文扩展通过增加RoPE的基础频率,将模型上下文窗口从4K扩展到128K;后训练通过监督微调(SFT)和强化学习(RL)使模型符合人类偏好。
- 训练系统:使用8192个Ascend NPU的计算集群训练Pangu Ultra,采用数据并行(DP)、张量并行(TP)、序列并行(SP)和流水线并行ÿ

 订阅专栏 解锁全文
订阅专栏 解锁全文



















 887
887

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











