



 研究系统性地探讨了基于静息态功能磁共振成像(REST-fMRI)的功能连接预测模型的选择,涉及多种脑区定义方法、连接参数化和分类器。实验发现,使用数据驱动的方法(如字典学习)定义节点,结合切线空间参数化和L2正则化的线性分类器,如逻辑回归,可以获得最佳预测性能。预计算的图谱和适当数量的节点(约150个)也有助于提高预测准确性。研究强调了选择合适建模方法的重要性,以降低计算成本并提高预测稳定性。
研究系统性地探讨了基于静息态功能磁共振成像(REST-fMRI)的功能连接预测模型的选择,涉及多种脑区定义方法、连接参数化和分类器。实验发现,使用数据驱动的方法(如字典学习)定义节点,结合切线空间参数化和L2正则化的线性分类器,如逻辑回归,可以获得最佳预测性能。预计算的图谱和适当数量的节点(约150个)也有助于提高预测准确性。研究强调了选择合适建模方法的重要性,以降低计算成本并提高预测稳定性。
研究表明,功能连接可揭示生物标志物的个体心理或临床特征。然而在静息态功能磁共振的典型分析中,不同研究者对其分析方法的选择并不固定且存在很多差异。为此,对静息态数据进行一种特定类型的研究将具有较强的现实意义,所以我们选择了一种预测模型(针对功能连接),接下来本文将对此选择做出合理的解释。本文发表在Neuroimage杂志。
研究方法:
本文系统地研究了6个不同队列的预测模型(被试2000人左右)。这些模型涉及的病症及考虑的因素为:神经退行性疾病(阿尔茨海默氏症、创伤后应激障碍)、精神障碍疾病(精神分裂症、自闭症)、药物影响(大麻使用)、临床环境和心理特征(流体智力)。人们对rest-fMRI的预测过程主要包括三个步骤:定义脑区、确定交互作用以及监督学习的最优方案。本文对于任何一步都会进行基准测试:在实验过程中,本文采用8种方法定义脑区(从REST-fMRI数据中预定义或直接生成),采取3种措施建立功能连接(从提取的时间序列中),构建10个分类模型(为比较受试者之间的交互作用)。尽管人口分布及地点存在差异性,但本文仍然对240多个不同的管道进行了总结,且对本文的模型进行了概括。研究发现,实验效果在根据功能数据所定义的区域上达到最好,且人们利用诸如线性回归这种线性预测模型,其预测效果最佳。
研究背景:
静息态功能磁共振成像(Rest-fMRI)是一种无特定任务的脑活动的分析,目前,它已成为探测人脑功能(针对健康人群及疾病人群)的首选工具。同时由于REST-fmri数据容易获得、前景广阔的特点,这就导致人们开始大规模地收集REST-fMRI数据(如2013年,Van Essen等人的人类连接组项目)。由于大样本的数据,其统计分析结果更准确,更更具有说服力,所以人们将较容易获得的rest-fmri脑影像数据与人体神经病理等临床症状联系起来,他们利用REST-fMRI数据,构建预测模型、建立生物标记物。
人们可以从REST-fMRI数据中提取出功能连接体(表征大脑的网络结构),而且人们可用大脑功能连接体的权重来表示个体的行为、认知、年龄、心理健康程度及和脑部病理程度。
功能连接能否转化为预测感兴趣表型的生物标记与机器学习管道(管道在本文中的意思是连续的数据处理形成的固定步骤)息息相关,换句话说,机器学习管道对此过程有着关键作用。就REST-fMRI数据而言,将功能连接转换为对分类对象的表型的处理管道通常包括3个,如图1所示:

图1:功能连接预测的三步流水线。
(1)根据REST-FMRI图像或已有的参考图谱定义大脑区域(ROI);
(2)从这些ROI中提取时间序列信号,以便量化其功能相互作用;
(3)通过监督学习方式,比较被试之间的功能交互作用。
研究过程:
尽管该领域的许多综述表明,人们可运用大脑功能连接边的权重对感兴趣的客体进行分类,但这个过程中能使用的管道种类实在太多,且不同的管道选择对研究的准确性有相当大的影响,此外,分析这种变化所耗费的成本是一般研究的两倍,所以很少有人讨论此问题。综上,人们之所以不讨论此问题可简单概括如下:首先,这种研究方法对实践者而言是一种负担,因为他们没有系统的指导,且他们需要在诸多选择中去做出合理的选择。其次,多变的方法会给研究人员带来特别大的自由度,所以这可能对生物标志物预测准确性的测量造成影响。考虑到上述因素,我们应该慎重地选择建模方法和处理管道。
因此,本文基于功能连接组的分类管道及分类管道的不同步骤,进行了系统的基准测试(基准测试是指通过设计科学的测试方法、测试工具和测试系统,实现对一类测试对象的某项性能指标进行定量的和可对比的测试)。除此之外,为制定出更好的策略,本文还分析了6个不同队列的预测精度,这其中包括不同的临床问题、不同的样本量、难度不一的预测问题及一个心理特征。虽然最优模型可能会因预测任务而产生差异,但本文所作的基准测试仍可概括出一些基本趋势。
具体来说,将从以下几个方面来展开研究:
1.我们应该如何选择节点:通过预定义的图谱还是采用数据驱动的方法?基于脑影像的诊断,我们需要多少节点?节点应该选择分布式大脑网络还是感兴趣区域(ROI)?
2.我们应该如何表示大脑功能连接组的权重:是通过相关性、部分相关性还是采用更复杂的模型来测量协方差矩阵的几何特征?
3.考虑到大脑功能连接组的权重,我们应选择哪些分类器来用于机器学习?我们应该首选线性模型还是非线性模型?应该使用稀疏模型还是非稀疏模型?我们是否还应该考虑特征选择呢?
本文除了探索以上这些主要问题,还对预处理策略和协变量控制进行了额外的实验(研究带通滤波和全脑均值回归的效果)。
本文的全局概括:
本文结构:首先回顾了迄今为止被大量使用的具体方法。接着,提出了基准测试的不同选择(针对分类管道步骤),并对这些方法进行了相应的描述;最后,根据本文的试验情况,对其实验结果进行报告并揭示了它们的趋势。
方法:功能连接组分类管道
当前实践的简要回顾:基于功能连接组的预测方法
在研究过程中,本文首次使用三篇综述里面有关预测研究的调查方法,这三篇综述的作者分别为Wolfers,Arbabshirani等人及Brown and Hamarneh。从这些综述中来看,这27项研究均运用了REST-fMRI数据,并获得了良好的分类分数。下面将对不同管道步骤中的选择进行简要概括(详情见表2)。
定义脑区ROI的不同方法:
参考文献坐标,以其为中心,制作半径为5毫米到10毫米的小球ROI;
参考一些脑图谱如AAL脑图谱、基于皮层接哦古的图谱以及基于功能连接的分区图谱;
基于k-均值、Ward聚类方法、独立成分分析方法(ICA)或字典学习的数据驱动方法,以往研究中使用的分区的脑区数量可设置成几十个到几百个,但人们通常将节点数(即脑区数量,为方便描述,后文统一为节点)控制在100个左右。
接下来描述大脑功能连接组的表示情况:
实验研究从二阶统计量的角度出发,来定义功能交互作用(基于单一协变量)。研究使用Pearson相关或偏相关的数理统计方法,其研究过程主要涉及最大似然估计或Ledoit-Wolf收缩协方差估计。我们知道节点之间的部分相关性有助于规避相关结构中的间接影响,但这一过程需要借助对协方差的收缩估计(收缩是一种正则化形式,用于在训练样本数量比特征数量少的情况下改善协方差矩阵的估计),我们对其中最简单的一个实验进行了基准测试。
关于预测分类器的描述
人们在之前的实验中已经使用过许多不同的分类器(其中包括线性分类器、非线性分类器以及稀疏分类器和非稀疏分类器),本文从中挑选出一些模型,并对其进行使用。详情见表A2。除了表上面所展示的原型管道之外,还有一些研究使用了如网络模块化或中心性等图论的网络建模方法,但值得一提的是,人们很少把这些方法与监督学习相结合使用。虽然图论指标可以很好地捕捉到大脑连通性全局方面的信息,但不能很好地捕获特定子网络中的连通性特征。所以本文只专注于机器学习方法(用于提取判别关系),不研究图论方法。
因为当前的做法非常多样且对建模方法没有标准的定义及选择。所以为了确保研究的准确性及合理性,本文探索了经典机器学习管道中比较流行的方法及其变体,以更好地满足我们的实验目标(对功能连接进行良好且有效的预测)。
接下来,将会对本文的研究进行详细的介绍。
定义感兴趣脑区(ROI)
实验假设:在本文定义的ROI范围内,能很好地捕捉到与功能连接相关的功能单元。虽然本文研究了解剖学上和功能上所定义的脑图谱,也学习了定义ROI的相关数据驱动方法,但因为使用条件以及不同病理的差异性,所以我们需要清楚:在实际的研究中,ROI的选择是一个极其困难的过程。
预定义图谱的选择:
本文选择了四个标准脑图谱,其中两个是结构图谱:
(1)AAL116脑图谱
(2)Harvard Oxford图谱,总共包含118个ROI
(3)Bootstrap Analysis of Stable Clusters (BASC)脑图谱,选择序号为36,64,122,197,325,444的感兴趣区
(4)Power图谱,制作半径为5mm的小球ROI
对于所有的基准测试,本文都只使用预先计算的区域。值得说明的一点是,在对静息态数据的研究过程中,如果有些功能图谱可运用字典学习的方法计算出,那么本文便参照Mensch等人计算的图谱,对数据进行合理的训练,以确保实验结果的准确性。
数据驱动方法的选择:
本文选择了四种当下流行的数据驱动方法(从fMRI数据中提取ROI,且用两种聚类方法来定义ROI)
(1)K均值聚类
(2)Wards聚类算法
(3)组ICA方法
(4)字典学习方法
数据驱动图谱的维度选择:
我们采取聚类的方法,提取出不同编号的ROI,具体为:40,60,80,100,120,150,200,300。同理,我们借助CanICA和DictLearn线性分解方法,提取出以下成分:40,60,80,100,120。
为避免实验模型出现过拟合的情况,对每一种数据驱动方法的分割都限制在训练集,并直接将分割结果应用于测试集。与此同时,在交叉验证循环的过程中,对于每个分割(定义大脑ROI),也将其限制在训练集上。
为了实现预测目标,本文使用图谱来学习连接模式。此外,为了让所提取的ROI区域增强,在提取大脑ROI之前,先对rest-fMRI数据上做了高斯平滑核为6mm的高斯平滑的操作。
本文还测试了节点是直接使用局部脑区还是分布式网络。目前,功能连接组学将大脑的局部区域或将包含多个区域的分布式网络都称之为节点。为了确保实验的准确性,本文在实验过程中,对这两种方法都进行了考虑。
在脑网络(借助Canica和DictLearn获得)中采用随机游走算法提取节点。对于K-Means和BASC方法,只需在它们的连通分量中划分集群即可,在此过程中,去除尺寸< 1500立方毫米的假阳性区域。图2展示了利用各种数据驱动方法从ADNI REST-fMRI数据中获得的大脑区域,具体情况如图所示:
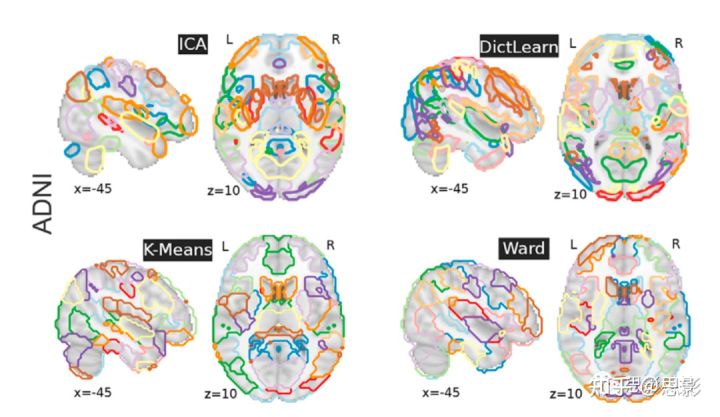
图2:使用ICA、DictLearn、KMeans和Ward方法提取的大脑区域。
使用 ICA 和字典学习方法,得到的静息态网络的维度分别是80和60,随之被分解为多个区域(150个)。通过KMeans和Ward聚类得到120个区域,其颜色随机分配。
多连通图的参数化
然后对每个节点都提取出其时间序列。在信号提取的过程中,本文探索了几种降噪方法来规避非神经伪影,降噪方法具体为:对数据做低通滤波的处理,对全脑均值均值进行回归。为了有效地估计功能连通性,使用了Ledoit-Wolf收缩估计,并给出了收缩参数的形式表达式。虽然REST-fMRI数据集的时间序列长度不同,但这种估计方法仍能产生良好效果,本研究还针对协方差,研究了它的的非正则化及稀疏估计方面的问题(见附录H.2)。本研究在这种协方差结构的背景下,对三种不同的功能交互的参数化过程进行了研究:全相关、偏相关及协方差矩阵。虽然协方差矩阵使用频率较低,但它具备良好的数学基础,且许多研究都报告出该框架具有良好的解码性能。本研究对两个变量进行了比较,使用欧几里得平均值或几何平均值作为参考点(在这两种情况下都参考了Nilearn所提出的方法)。值得注意的是,偏相关和切线空间的计算都需要求协方差逆矩阵,因此这些矩阵必须可逆。所以,这些参数化法不适用于非正则化协方差估计。
为了后面统计分析过程的良好进行,本研究对功能连接的每个参数都进行了矢量化的操作处理(数据的标准化),使用连通矩阵的下三角部分进行分类。
监督学习:分类器
最后,使用预测模型进行分类。在这个过程当中,本研究运用了几种不同的方法(线性方法、非线性方法、稀疏方法和非稀疏方法)。对于非线性方法,用K = 1和欧几里得距离的方法来度量最近邻方法(K-NN)、高斯朴素贝叶斯(GNB)和随机森林分类器(RF)。对于线性分类器,本研究使用了支持向量分类(SVC)和Logistic回归的方法,设定稀疏度值为ℓ1,并对其做了正则化的处理。对于非稀疏线性分类器,本研究使用了岭分类、SVC、Logistic回归的数学方法。此外,对于SVC,还使用了单因素方差分析方法对其进行10%阈值的特征筛选。对于正则化参数(例如SVC中的软边距参数),使用默认的值C =1或α= 1,因为研究发现这两个默认值具有很好的代表性。
实验研究
为了对不同的预测模型进行基准测试,本实验所用的数据为五个公开可用的REST-fMRI数据集,并在这些数据集上应用了不同的功能连接组分类管道。在实验过程中,对临床上不同的的功能连接预测结果都进行了研究,这其中包括:神经退行性、神经精神障碍、药物滥用的影响及流动智力。本文专注于二进制的分类问题。
具体情况如表1所示:
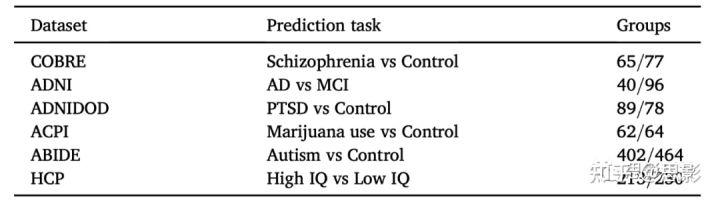
表1:数据集和预测任务。每组的被试数目:COBRE :142人ADNI :136 人ADNIDOD:167人ACPI :126 人ABIDE :866人HCP : 443人
IQ代表流动智力(788名受试者在HCP900版本中获得IQ分数)表A3总结了每个数据集的采集参数。
1.参照ADNI的restfMRI数据,以对患有轻度认知障碍(MCI)的被试与被患有阿尔茨海默病(AD)的被试进行区分。
2.参照ADNIDOD的restfMRI数据,将PTSD患者与健康对照组区分开来。
3.参照ACPI的restfMRI数据,判别被试是否有过吸食大麻史。
4.参照ABIDE的restfMRI数据,以此区分出患有自闭症障碍的患者实验组与健康对照组。
5.HCP 900人连接体项目包含健康受试者的成像和行为数据。使用来自HCP900释放的预处理的rest-fMRI数据来区分高智商和低智商个体.
6.参照COBRE(生物研究中心)的restfMRI数据,来研究精神分裂症和双相情感障碍这两种疾病。需要注意的是,本文主要利用精神分裂症患者的数据,将其与健康组进行对照,以便达到预测目标。
Rest-fMRI数据预处理:软件及相关过程
用SPM12软件对COBRE、ADNI和ADNIDOD数据进行预处理。预处理包括:头动校正、一步配准,平滑(高斯平滑核为5mm)。除此之外,在数据处理的过程中,剔除了有严重伪影(多人肉眼观察)或头动大于2毫米的被试。对于经过预处理的ABIDE数据和ACPI数据,本研究选用C-PAC pipeline来处理图像,但本研究在这个过程中,没有回归全脑均值。对于ACPI数据,本研究使用ANTS配准的方法对图像数据进行标准化处理,但没有删除数据,也没有对数据做全脑均值的回归处理。对经过预处理可用的数据者,继续进行下面的操作,而且,本研究没有对HCP数据做任何额外的预处理操作。
删除标准:
本研究通过目视检查(肉眼观察)的步骤剔除了一些被试,也借助其他办法排除了不符合要求的被试。例如,本研究从COBRE样本中剔除了既患有双相情感障碍疾病又患有分裂情感疾病的被试。对于HCP数据,本研究为了更容易预测二元分类设置,把低智商与高智商被试做了分组处理,根据分位数0.333(以下为低智商)和0.666(以上为高智商)来选择(详情见表1)。
交叉验证和误差测量:
本研究在进行交叉验证(CV)的过程中对所有被试进行随机处理,并对每个数据集做了超过100次的分割,最终将被试分成两组:75%的被试运用训练分类器和数据驱动模型的方法来分割脑区,剩余25%的被试则在不可见数据上进行测试。此外,本研究对数据进行分层处理,以保持组之间的样本比率。针对每次分割,本研究计算出曲线下面积(AUC),曲线下面积的值1代表完美预测,0.5代表随机水平概率。AUC的最终预测分数可用来衡量不同选择之下的预测管道结果情况。
计算和实施:
本研究的实验研究包含240多种类型的管道(8个图谱,3个连通性度量,10个分类器,以及其他变量,如3个filter选项和3个协方差回归选项),这些管道分别在5个数据集上运行。其运行结果是:在原始数据到模型计算期间的这个过程之中,本研究需要对50多万个管道进行拟合,所以计算量相当大。本研究使用Python2.7工具进行数据处理。这其中包括:定义脑图谱、提取具有代表性的时间序列以及构建连通性度量。
结果:管道选择的基准
接下来,本研究概述不同的模型选择对预测结果所产生的影响。
本研究在表2中报告了所有REST-fMRI数据集所获得的AUC分数,并且在表2中,本研究已将每步的最优选择进行呈现,以下本研究将对这些最优选择进行详细阐述。
不同的方法将产生不同的影响,为了更好衡量其影响,所以本研究对每个管道的预测分数计算出平均值。这种相对测量方法避免了因折叠或数据集不同而导致的分数差异的情况。本研究对这些相对预测分数进行了观察,并研究了不同的步骤选择(如分类器的选择、连接参数的选择和大脑图谱的选择)对预测管道的影响。在实验过程中,涉及很多步骤的选择,对于固定步骤而言,其影响有二:第一,当某些实验步骤是最优选择或接近最优选择时,本研究可以考虑其中一个步骤的影响;第二,对必选步骤来说,本研究可以考虑该步骤对其他步骤的影响。从经验上看,这两种情况得出了相似的结论,详情见附录C。
分类器的选择
图3总结了分类器对rest-fMRI数据集预测分数的情况。结果显示不同模型和数据集(即预测目标)之间存在一定的差异性,非稀疏(l2-regularized)线性分类器的表现情况更好,略领先于logistic-l2。
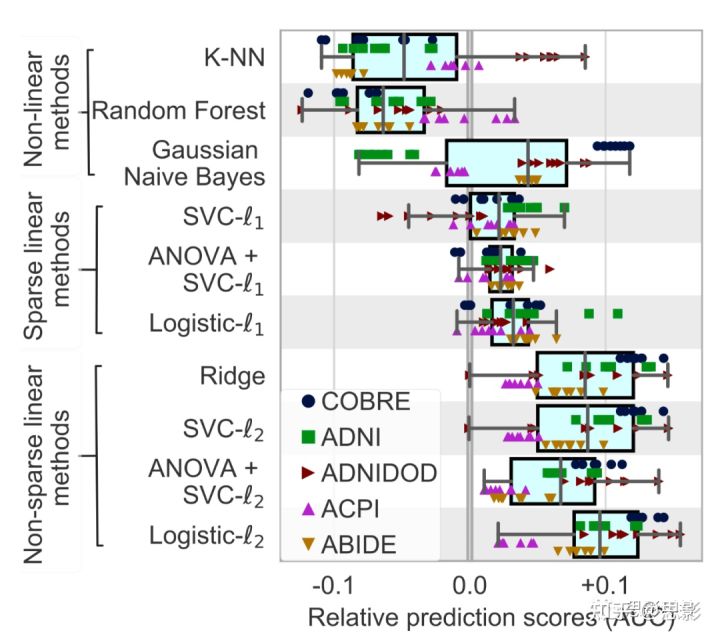
图3:分类器的选择对预测准确性的影响。
对于每个分类器,当改变其他步骤(正在进行)的建模选择时。总体而言,L2正则化的线性分类器的表现更好。
连接参数的选择
图4总结了REST-fMRI数据集的相对预测分数受协方差矩阵的参数化情况的影响。通常来说,切空间参数化(正切空间投影法被应用于功能连接的估计,具体方法可以看这篇文章:https://www.ncbi.nlm.nih.gov/pmc/articles/PMC7086233/)的性能优于完全相关或部分相关。
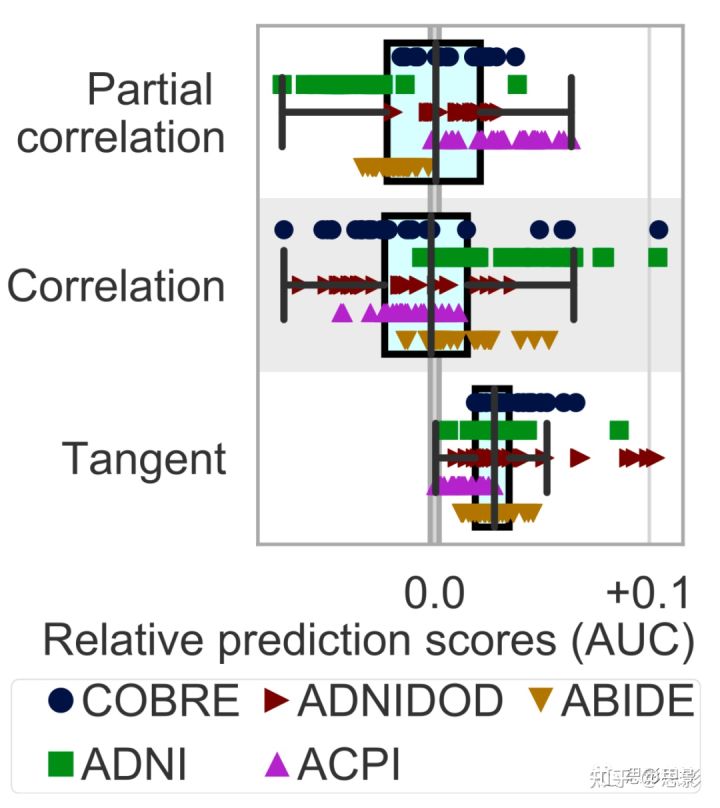
图4:连接参数对预测精度的影响。
实验过程中,本研究将完全相关性方法或部分相关性方法与基于切线空间的方法进行对比,发现使用基于切线空间的方法,其在预测时,其连通性参数显示出更高的准确度和相对较低的方差。图4方框显示中位数和四分位数,及五分位数和95分位数。
区域定义方法的选择:
为找到大脑区域定义的最佳方法,本研究在实验过程中,对实验方法做了两步处理。首先,本研究对每种方法都找出了最佳预测的维度,但这只适用于具有各种维度的BASC图谱及数据驱动的区域定义方法(如ICA)。其次,本研究在最佳维度的这个背景之下,研究了每种方法的预测精度。
最好的办法:
图5总结了不同的区域定义方法的相对预测性能。尽管这些方法的系统性影响很小(相比于褶皱和数据集的方差),但就预测效果而言:参照功能数据定义方法所定义的区域要比参照解剖学定义方法的预测效果更好。其中,本研究使用ℓ1字典学习方法定义区域(在REST-FMRI数据中),其实验效果似乎是最好的,其次是ICA方法(预测效果排名第二)。
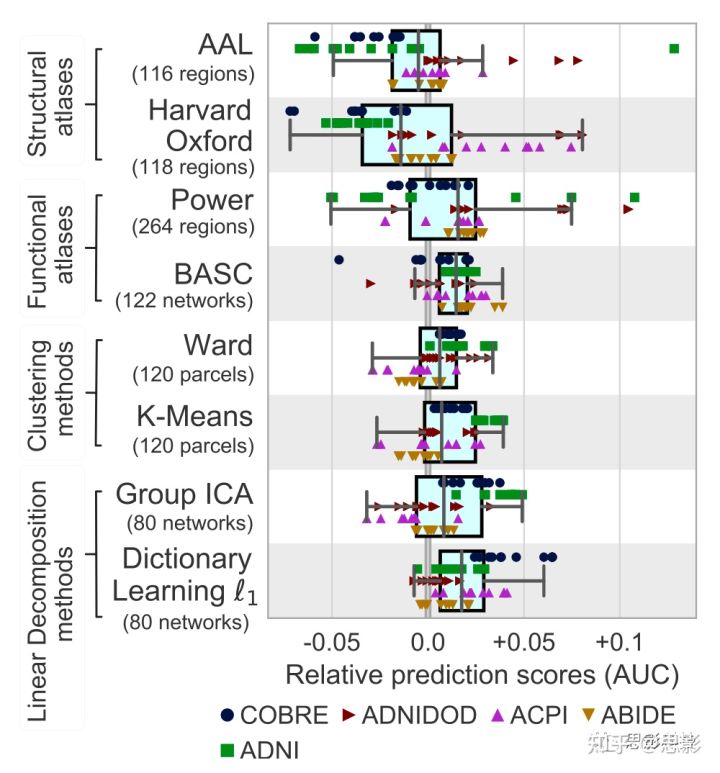
图5:不同的图谱定义的方法对预测精度的影响。
最优维度:
本研究对每种最佳维度方法的选择进行了图示,如图6所示。在实验过程中,本研究发现了一个在不同情况下会出现变化的最优值:这个值会随着提取节点数量的增加,使预测精度升高,然而对于其他方法,在相同情况下,这个值的预测精确性又会缓慢下降。详情见图6。除此之外,典型的最优区域数量约为150(见附录E)。
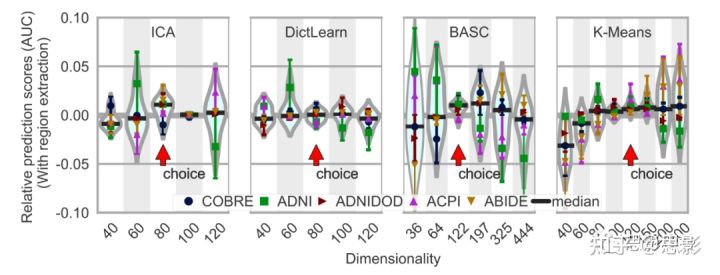
图6:脑区数量对预测准确性的影响。
该图显示了不同方法(对五个 rest-fMRI 数据集采用的方法)的 AUC 分数的分布情况。水平条(黑色)表示中位数,红色箭头表示维度。
更大的数据集和预先计算的图谱:
为了研究数据分析(限于更高质量数据集)的一致性对结果的影响,本研究对包括HCP数据在内的基准测试进行了相同的预处理。因这些数据时间序列更长且计算成本高,故为了降低计算成本及确保结果的严谨性,所以本部分将分析限制在预先计算的图谱上(对于字典学习和ICA方法下的脑区分割,是从对ADNI REST-fMRI数据的估计中来的)。图7总结了不同方法对六个群组预测精确性的影响。该实验得出了与其他实验类似的结论:使用字典学习、切线空间参数化和L2正则化分类器的方法来获取功能图谱作为特征,对分类性能的提升更大。详情见下图7。
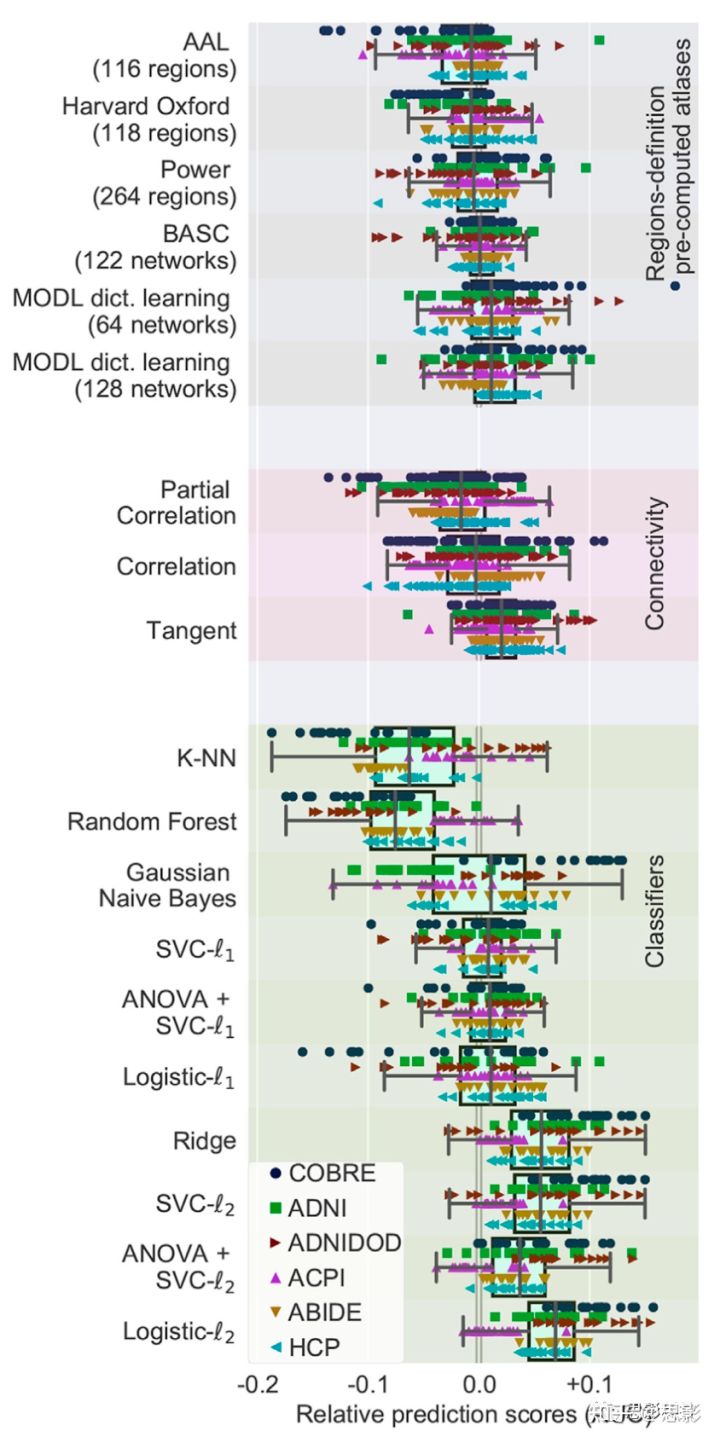
图7:预计算区域(限于六个数据集)的流水线选择
该图展示了相对预测分数的边际分布情况,最佳选择方法正向排序为:基于字典学习的分区方法(MOD1)、聚类法(BASC)、连通性的切数空间参数化方法以及L2正则化的逻辑回归方法。
滤波、全脑平均信号的影响
是否滤波以及是否回归全脑平均信号对结果影响不大。
总结:
本研究为使用功能磁共振数据作为特征的分类机器学习的实践提供了一些参考方向,具体总结在表3中:本研究发现带正则化参数的逻辑回归方法是一个在许多情况下都可以被使用的基本模型,并且使用ICA或者字典学习方法对功能数据进行软分区可以进一步提升模型的分类性能,除此以外,本文发现预处理过程中的滤波和全脑均值回归对分类结果的表现没有明显影响。
本文研究还有一个意义在于,使用良好的默认模型可以抑制分析管道的组合爆炸,从而降低研究的计算成本,以使其实验结论更稳定、更具有说服力、更具有统计意义。值得一提的是,就数据而言,其数据分析不可能有一个万能的解决方案,本文方法的最优选择以及本研究的研究虽然与前人研究的结果具有一致性,但不代表任何研究运用此方法都能达到和本文一样的效果,所以大家在实验过程中,可根据自己的数据以及实验目的,合理选择实验方法和模型来进行研究。

















 1872
1872




 到【灌水乐园】发言
到【灌水乐园】发言







