



功能性磁共振成像(fMRI)语言研究特有两种分析传统。一种依赖于跨个体平均激活水平。这种方法有其局限性:由于个体间语言区域位置的变异性,任何给定的体素/顶点在共同的大脑空间中可能是某些个体的语言网络的一部分,而在其他个体中,可能属于一个不同的网络。另一种方法依赖于使用功能性“定位器”识别每个个体的语言区域。由于其更高的灵敏度、功能分辨率和可解释性,功能定位正变得越来越受欢迎,但它并不总是可行的,并且不能对过去的研究进行追溯应用。为了桥接这些分离的方法,我们使用806个个体的fMRI数据创建了一个经过广泛验证的语言定位器的概率功能图谱。这个图谱能够估计任何给定位置在共同空间中属于语言网络的概率,因此可以帮助解释群体水平的激活峰值和病变位置,或者选择体素/电极进行分析。跨研究之间更有意义的比较应该会增加语言研究的稳健性和可复制性。本文发表在Scientific Data杂志。(可添加微信号19962074063或18983979082获取原文及补充材料,另思影提供免费文献下载服务,如需要也可添加此微信号入群,另思影脑影像分析业务,如感兴趣也可咨询)
背景与摘要
功能性磁共振成像(fMRI)是一种宝贵的非侵入性工具,特别是用于了解大脑的结构,尤其是对于人类独有的能力如语言。在fMRI语言研究中的一种常见分析方法是在一个共同的大脑空间中逐体素平均激活图,并在每个体素中跨个体进行统计推断。然而,由于在联合皮层中功能区域位置的个体间变异性已经得到了良好的证实,激活在个体间对齐得不好,导致敏感性和功能分辨率低。此外,群体平均分析的结果通常通过从解剖位置到功能的逆向推断来解释,但是由于上述的变异性,加上联合皮层的功能异质性,共同大脑空间中的位置不能有意义地与功能联系起来(关于这个问题的讨论,特别是对于“布洛卡区”的讨论,请参见文献6)。
一种替代的分析方法,它绕过了体素级的大脑平均,被称为“功能定位”。在这种方法中,通过在每个个体中使用功能对比识别支持感兴趣的心理过程的大脑区域或网络,然后检查其对一些新的关键条件的反应。这种方法提供了更高的敏感性、功能分辨率和可解释性,并且在感知和认知的许多领域都取得了成功,包括语言。因此,许多研究小组现在正从群体平均分析转向个体受试者分析。
然而,功能定位并不总是可行的。此外,尽管依赖功能定位的研究可以直接相互比较,但目前尚不清楚如何将这些研究的结果与群体平均fMRI研究或其他依赖大脑平均的研究(例如,在患者工作中使用基于体素的形态测量学(VBM)或基于体素的病变-症状映射(VLSM)的研究)相关联。为了帮助桥接语言研究中这两种分析传统之间的差距,我们通过叠加806个个体的激活图,为一个在个体受试者水平上稳健且经过广泛验证的语言“定位器”,创建了一个语言网络的概率功能图谱(“语言图谱”或LanA)。
语言定位器依赖于处理句子与语言学/声学上降级的控制条件之间的对比,对材料、呈现方式和任务的变化具有鲁棒性(见方法部分)。这个定位器识别出左侧化的额颞语言网络(例如文献12,13,14),该网络专门支持高级语言理解和产出(文献6,15,16,17,18),包括词义处理和组合句法/语义处理(文献19,20,21)。通过设计,这种对比排除了低级感知(文献22,23,24,25)和言语-发音过程(文献26,27,28),以及话语级理解(文献29,30,31,32)。此外,一个与这种功能对比密切对应的网络从无任务休息状态数据中浮现(文献33)。(许多研究者假设语言网络内不同大脑区域之间存在功能性分离(例如文献12,13,14,34,35,36)。然而,实证研究仍然复杂并充满争议,现在有压倒性的证据表明,即使网络内部存在分离,所有语言区域在活动中都强烈同步(文献33,37,38),表明它们形成了一个功能性整合的系统)。
LanA允许人们估计任何一个在共同大脑空间中的位置属于语言网络的概率。通过这种方式,这个图谱可以提供一个共同的参考框架,并帮助解释(a)过去和未来fMRI研究中的群体级激活峰值,或这些峰值的元分析结果(文献39),(b)个体大脑中的病变位置或VBM/VLSM分析中的病变重叠位点,以及(c)ECoG/SEEG调查中的电极位置或MEG研究中源定位活动的位置。此外,LanA(d)可以帮助在现有数据集中选择语言选择性单元(体素、电极、MEG通道,甚至单个细胞)进行分析,包括旨在将人类神经表征与人工神经网络语言模型的表征相关联的研究(文献41,42,43,44,45,46),(e)可以逐体素与任何全脑数据(文献47)相关联,包括结构数据、基因表达数据(文献48)或受体密度数据(文献49),以询问这些特征是否/如何与语言网络的地形学相关,以及(f)可以帮助选择尸检大脑中的片段进行细胞分析,以最大化检查语言皮层的机会。最后,LanA(g)可以在进行脑手术时指导/限制功能映射,当fMRI不可能时,尽管当然,不应仅基于LanA做出临床决策。我们为两种最常用的大脑模板提供了图谱(图1):一个基于体积(volume)的模板(MNI IXI549Space; SPM1250)和一个基于表面的模板(fsaverage; FreeSurfer51)。使用这些常见的数据格式将允许与现有的开放数据仓库(如NeuroVault52和ENIGMA53)轻松对接。我们强调,LanA不是定位器的替代品:如果可能,应执行语言定位器任务(文献54)。正如我们在SI-1中展示的,基于LanA的群体级兴趣区域(ROIs)或常用的Glasser分区(文献55)获得的效应大小相对于个体定义的语言功能ROIs被低估。
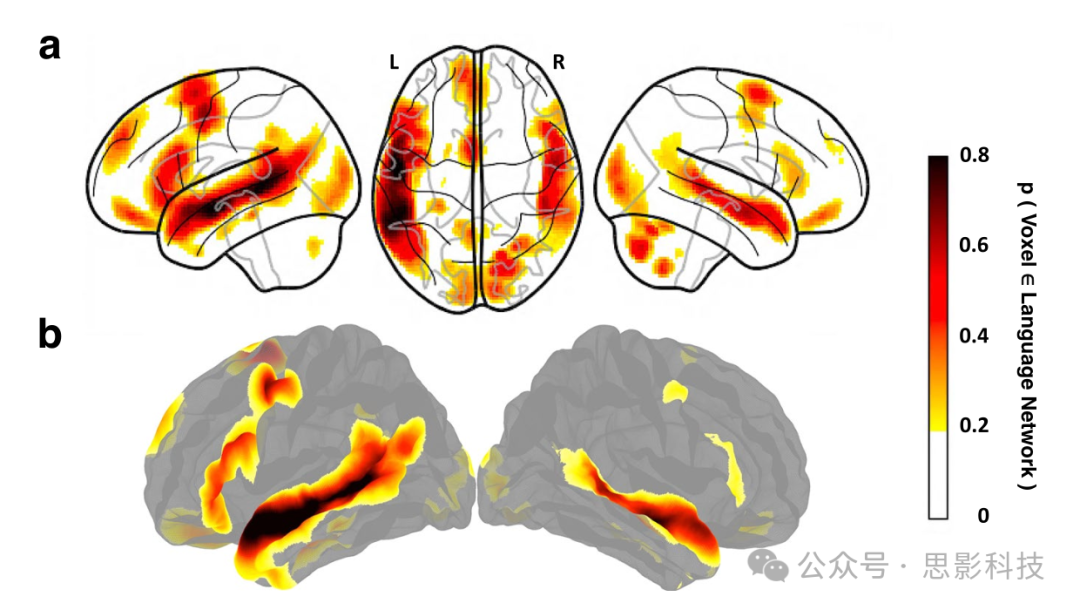
图1 语言图谱地形。
基于叠加的个体二值化激活图(在每张图中,选择前10%的体素,如文本中所述)的语言>控制对比的概率功能图谱。(a)在MNI模板空间中经SPM分析的体积数据(基于806个个体图)。(b)在FSaverage模板空间中经FreeSurfer分析的表面数据(基于804个个体图)。在两幅图中,颜色尺度反映了该体素/顶点属于语言>控制体素/顶点前10%的参与者比例(出于可视化目的,在p=0.2时进行阈值处理)。
我们还发布了:(i) 个体激活图(在MNI和FSaverage空间中),连同人口统计数据,以及(ii) 基于体积分析的个体级神经标记,包括效应大小、体素计数(激活范围)和跨次运行的激活稳定性。神经标记数据可以作为基于神经典型的相对年轻成人的规范分布,任何新的人群(例如,儿童或有发展性或获得性大脑障碍的个体)都可以根据此进行评估。
方法
参与者
共有806名神经典型成人参与,其中477名(约59%)为女性,年龄从19岁到75岁(441名,约55%,年龄在19-29岁之间;310名,约38%,年龄在30-39岁之间;55名,约7%,年龄在40岁以上),他们在2007年9月到2021年6月期间参与并获得报酬,如表1所总结。所有参与者都有正常或矫正到正常的视力,并且没有神经系统、发展性或语言障碍的历史。758名(约94%)的806名参与者收集了惯用手信息。其中,707名参与者(约93%)根据爱丁堡惯用手清单56或自我报告为右手惯用,38名(约5%)为左手惯用,13名(约2%)为双手惯用。(数据库中缺少惯用手信息的参与者很可能是右手惯用,因为他们中的大多数在数据收集的早期年份进行了测试,当时右手惯用是参与的要求之一。)在806名参与者中,629名(约78%)是英语的母语者,其余177名(约22%)是其他语言的母语者且精通英语(见文献38,证明个体精通的语言的语言反应地形学与其母语相似,见SI-2,对使用629名母语为英语的参与者与177名精通的非母语英语者生成的图谱进行了比较)。鉴于这种人口分布,这个图谱代表某些人群比其他人群更好,解释数据时应考虑这些偏见,包括与其他人群比较。
表1. 参与者人口统计学。包含在图谱中的806名参与者的人口统计学摘要。

每位参与者作为Fedorenko实验室某项研究的一部分完成了一项语言定位任务。每次扫描会话持续1到2小时,包括多种额外任务。所有参与者都按照麻省理工学院人类实验主题使用委员会(COUHES)的要求提供了知情书面同意。
参与者和会话选择
上述806次扫描会话(每位参与者一次会话)是从截至2021年6月Fedorenko实验室数据库中可用的1,065次会话和819位参与者中选择的。目标是尽可能包括更多的参与者,并且对于在多个会话中进行语言定位的163位参与者,选择一次具有高质量数据的会话。为了评估数据质量,我们检查了跨次运行语言定位对比(见语言定位范式)的激活地形学的稳定性。这一分析是在体积数据上进行的预处理和分析(即,基于SPM的分析;见SPM预处理和分析流程)。对于1,065次会话中的1,062次,我们计算了语言>控制对比(见语言定位范式)在奇数次和偶数次运行之间的体素级空间相关性(剩余的三次会话由单次运行组成,并通过对比图的视觉检查进行评估)。
相关性值是在语言“区块”内计算的——掩模标记了语言区域的典型位置。这些掩模(可在 http://evlab.mit.edu/funcloc 获取)是基于220名参与者(当前806名参与者集合的一个子集)的概率语言图谱派生的,并已在许多过去的工作中使用。从概率图谱中派生了六个掩模(三个位于额叶皮层,三个位于颞叶和顶叶皮层),并在左半球镜像投影到右半球。对于每次会话,将十二个区块的相关性值平均,得到每次会话的单一值。这个空间相关性度量量化了激活景观的稳定性,是数据质量的客观代理;它受到头部运动或困倦等因素的影响,但不需要对比图的主观视觉检查(见SI-4,证据表明当考虑所有体素与仅考虑对比感兴趣的正值体素时,这个度量工作相似,表明值不是由响应和非响应体素之间的差异驱动的)。空间相关性值为负的会话(n=23;约2%)被排除,留下1,042次会话跨806位参与者。对于有多于一次会话的163位参与者,我们选择了空间相关性值最高的会话纳入图谱(见文献11,证据表明跨会话的空间相关性值的稳定性:即,如果参与者在一次会话中显示出高空间相关性,他们可能在另一次会话中也显示出高空间相关性;未发表的数据在更大的人群和多个功能不同的网络中复制了这一结果)。根据这一数据选择程序,参与者语言>控制对比的Fisher转换空间相关性分别为左右半球r=0.98和r=0.57(见文献11,关于这些参与者的一个子集(n=150)的类似值)。
语言定位范式
在806位参与者中,使用了十个版本的语言定位器,如表2所总结。在每个版本中,句子理解条件与语言学上或声学上降级的控制条件形成对比。视觉(阅读)和听觉(听力)对比已被先前证实能够激活相同的额颞语言网络。这个网络的活动进一步被证明不依赖于任务或材料,并且在类型学上多样的语言中显示出稳健的效应。此外,这个网络可以基于时间内BOLD信号波动的模式从自然状态下的无任务(休息状态)数据中恢复,并且几乎完美地对应于基于句子>非词对比的网络。因此,我们在当前研究中汇总了不同定位器版本的数据(见SI-2,证据表明仅基于在大多数参与者中使用的定位器版本A定义的图谱与利用所有其他版本的数据定义的图谱几乎相同,以及SI-3,一个补充分析显示所有十个版本中稳健的语言>控制效应)。
表2. 语言定位器版本。每个版本的语言定位任务的时间参数。在任务类型下,选项定义如下:BP = 按钮按压,MP = 记忆探针,N = 无任务。(对于记忆探针任务,正确的探针大约同等可能来自字符串的早期、中期和晚期部分)。
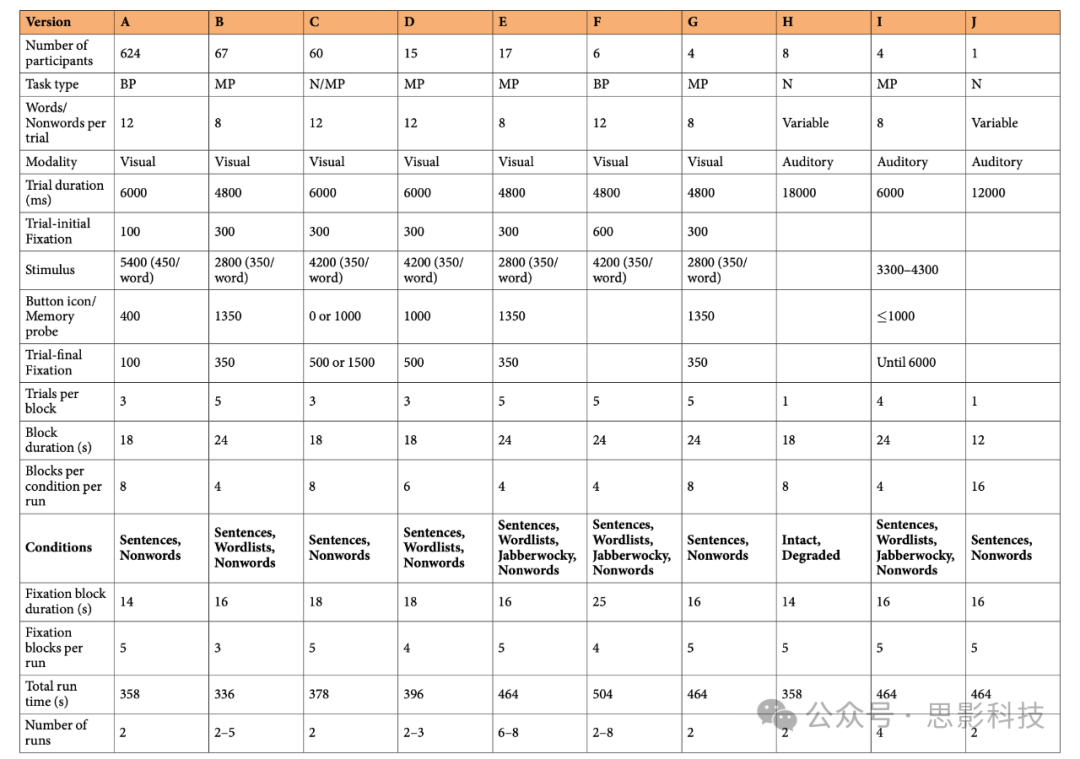
绝大多数参与者(624名,约77.4%)执行了定位器版本A——一个阅读版本,其中句子和非词字符串以每个词/非词450毫秒的速率逐个呈现,在一个block设计中(每个18秒的block包含3个句子/非词字符串)。参与者被指示认真阅读,并在每个试验结束时,当屏幕上出现一个手指按按钮的图片时按下按钮。实验包括两个约6分钟长的运行,每种条件共16个block。这个定位器版本的演示脚本和刺激可以在 http://evlab.mit.edu/funcloc/ 下载(关于其他定位器版本中使用的刺激,联系EF)。定位器版本B-G(由169名参与者执行,约21.0%)也使用了视觉呈现,而定位器版本H-J(由13名参与者执行,约1.6%)使用了听觉呈现。各版本之间在试验结构、时间安排和其他实验参数的相似性和差异的细节在表2中总结。
fMRI数据采集
结构和功能数据是在麻省理工学院麦戈文脑研究所的Athinoula A. Martinos成像中心使用全身3特斯拉Siemens Trio扫描仪采集的,使用12通道(G1;n=18)或32通道(G2;n=788)头线圈。T1加权结构图像在176个矢状切片中采集,具有1毫米等距体素(TR=2530毫秒,TE=3.48毫秒)。功能性、血氧水平依赖(BOLD)数据使用EPI序列采集(翻转角度90度,并使用GRAPPA加速因子为2),采集参数如下:33(G1)或31(G2)个4毫米厚的近轴向切片以交错顺序采集(带有10%的距离因子),3.0毫米×3.0毫米(G1)或2.1毫米×2.1毫米(G2)的平面分辨率,相位编码(A≫P)方向的视场(FoV)192毫米(G1)或200毫米(G2)和矩阵大小64毫米×64毫米(G1)或96毫米×96毫米(G2),TR=2000毫秒和TE=30毫秒。使用前瞻性采集校正技术根据参与者上一个TR的运动调整梯度的位置。每次运行的前10秒被排除,以允许稳态磁化。
SPM预处理和分析流程
预处理
对于SPM分析(图2 [体积]),fMRI数据使用SPM12(发布7487)、CONN EvLab模块(发布19b)和自定义MATLAB脚本进行分析。每位参与者的功能性和结构性数据从DICOM转换为NIfTI格式。所有功能扫描都使用B样条插值与第一次会话的第一次扫描进行了配准和重采样(Friston等人67)。潜在的异常扫描是根据结果中的主体运动估计以及使用CONN预处理流程中的默认阈值(全局BOLD信号变化中平均值以上5个标准差,或帧间位移值超过0.9毫米;Nieto-Castañón68)从BOLD信号指标中识别的。功能性和结构性数据独立地标准化到一个共同空间(蒙特利尔神经学院[MNI]模板;IXI549Space)使用SPM12统一分割和标准化程序(Ashburner & Friston69),参考功能图像计算为在排除异常扫描的所有时间点之后的平均功能数据。输出数据被重采样到MNI空间坐标(-90, -126, -72)和(90, 90, 108)之间的一个共同边界框,使用2毫米等距体素和4阶样条插值对功能数据进行,以及1毫米等距体素和三线性插值对结构数据进行。最后,功能数据通过与4毫米FWHM高斯核的空间卷积进行了空间平滑。
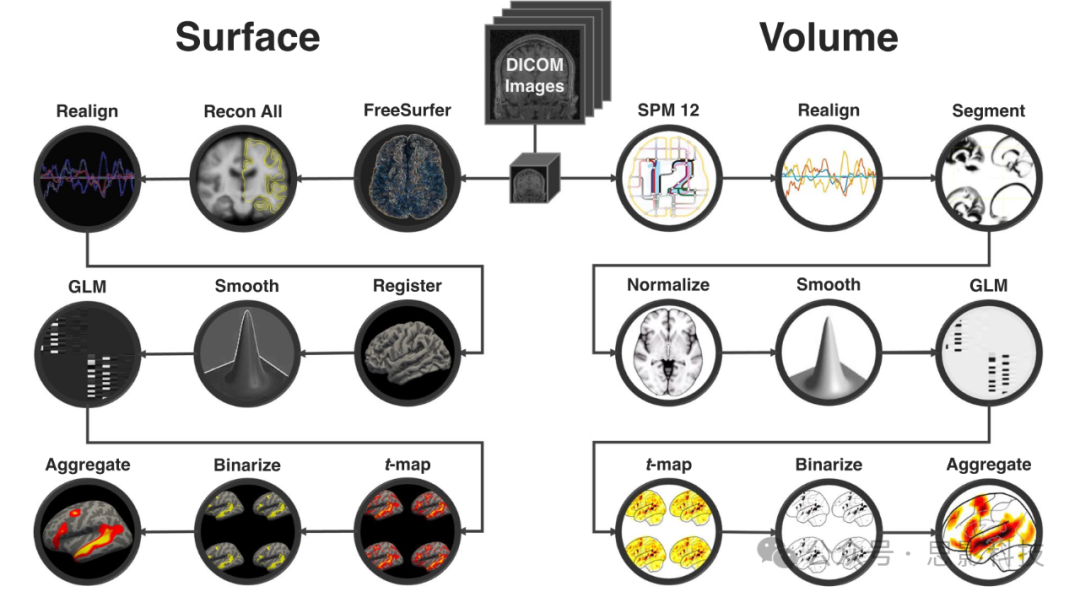
图2 数据处理流程图。SPM和FreeSurfer预处理及分析流程的概览。原始dicom图像被转换为NIfTI格式,在预处理过程中进行了运动校正、映射到公共空间并平滑处理。然后对每个会话进行建模,提取并阈值处理t图,所有会话被汇总以创建概率地图集。
一阶分析
效应是通过使用广义线性模型(GLM)估计的,在该模型中,每个实验条件都用一个方波函数建模,该函数与典型的血液动力学响应函数(HRF)卷积(固定视点被隐含地建模,这样所有不对应于某一条件的时间点都被假定为对应于固定期)。BOLD信号时间序列中的时间自相关通过结合高通滤波(截止频率为128秒)和使用AR(0.2)模型(围绕系数a=0.2线性化的一阶自回归模型)进行白化来考虑,以近似功能数据在受限最大似然估计(ReML)背景下观察到的协方差。除了实验条件效应外,GLM设计还包括了每个条件的一阶时间导数(包括以模拟HRF延迟的变异性),以及用于控制慢速线性漂移、受试者运动参数和潜在异常扫描对BOLD信号影响的干扰回归量。
FreeSurfer预处理和分析流程
对于FreeSurfer分析(图2 [表面]),fMRI数据使用FreeSurfer v6.0.0分析。每位参与者的功能性和结构性数据使用默认的unpacksdcmdir参数从DICOM转换为NIfTI格式。(806位参与者中有两位因为丢失了原始dicom文件而无法纳入此流程,留下804位参与者进行此分析。)然后将原始数据采样到FSaverage表面的两个半球上,使用每次运行的中间时间点进行运动校正和注册。然后数据通过4毫米FWHM高斯滤波器进行空间平滑。在一阶分析中,效应是通过使用GLM估计的,其中每个条件都用一个拟合典型HRF的一阶多项式回归量建模。GLM还包括了用于离线估计的受试者运动参数的干扰回归量。
地图集创建
SPM 使用自定义代码(可在OSF获取),我们计算了806名参与者(在SPM12流程中分析)的个体激活图与语言>控制对照组的重叠情况(请参阅SI-5,证明即使样本量远小于806,地图集也能达到稳定性,这表明当前的样本量足以具有普遍性)。特别地,我们使用了由一阶分析生成的全脑t图,其中每个体素包含了相关对照的t值(一项事后分析比较了全脑t图与其对应的未缩放对照图,并在806名参与者的集合中发现了强烈的体素级相关性:r = 0.93 ± 0.03;请参阅SI-2,证明从t图与对照图生成的地图集高度相似)。在每个个体图中,我们选取了全脑中t值最高的10%的体素,用于语言>控制对照(参与者的平均和中位数最小t值分别为1.73和1.62;平均和中位数最大t值分别为13.8和13.7)。然后,这些图被二值化,以便选定的体素被赋值为1,其余体素赋值为0。最后,这些值在每个体素中的参与者之间取平均。结果产生的地图集在每个体素中包含一个介于0到1之间的值,对应于806名参与者中有多少比例的人的该体素属于全脑中t值最高的10%的体素。在左半球,这些值的范围是0到0.82,在右半球(RH)是0到0.64(RH中的值较低,可能是因为大多数选定的体素位于左半球(LH):在参与者中,平均和中位数选定的体素落在LH的比例分别为58.3%和57.8%)。有关ROI级概率值的更多细节,请参阅SI-6。
FreeSurfer 使用自定义代码(可在OSF70获取),我们计算了804名参与者(在FreeSurfer流程中分析)的个体激活图与语言>控制对照组的重叠情况。该过程与SPM基础地图集的制作类似,除了最高t值的选择是在表面顶点上进行的。为了保持半球间的不对称性,与通常仅对每个半球分别进行FreeSurfer分析的做法不同,从LH和RH汇总的顶点中选择了顶部10%的顶点,如同SPM基础地图集一样。对于这个地图集,在左半球,比例值的范围是0到0.90,在RH是0到0.80(这些值预期高于SPM基础地图集中的值,鉴于基于表面的个体间对齐的优越性71)。
通用
我们选择了前10%的方法而不是每个个体图以固定t值(如在10中)进行阈值处理的方法,以考虑到因性状或状态因素72,73,74,–75导致的BOLD信号反应整体强度的个体间变异。然而,因为语言网络大小的差异可能对应于语言经验或能力的差异76,我们还提供了从以p<0.001、p<0.01或p<0.05为阈值的t图派生的地图集版本(https://doi.org/10.17605/OSF.IO/KZWBH70)。基于固定t值阈值方法的地图集产生的地形图与基于前10%方法的地形图非常相似(见SI-2)。这些地图集版本之间的关键区别在于重叠值的解释:如上所述,在前10%方法中,重叠值对应于806名参与者中有多少比例的人的该体素属于全脑中t值最高的10%的体素,而在基于固定阈值方法的地图集中,重叠值对应于806名参与者中有多少比例的人的该体素在相关阈值下对于语言>控制对照是显著的。
注意,除了经典的左前额和左颞区(及其右半球同源区)外,地图集中还出现了几个其他区域,包括在右小脑和视觉皮层。这些非典型区域在过去的语言研究中已被报告(例如77,78),但我们承认,通常这些区域并没有像核心前额和颞区那样被彻底功能性地描述,并且在未来的工作中可能被证明对于语言功能来说不是选择性的和/或关键的。
最后,人们可能会问:概率功能地图集的地形图与同一数据的随机效应组图的地形图有多相似。当然,鉴于在更大部分参与者群体中响应任务的体素(即,在地图集中具有更高概率重叠值的体素)可能在体素级t检验中产生更高的t值,这些预期是相关的(见SI-7对于LanA的这种比较)。概率功能地图集(如LanA)相对于随机效应图的关键优势在于它提供的体素值的直接解释,就是该体素属于相关功能区/网络(在本例中为语言网络)的概率。没有额外的假设/映射函数,这种信息无法从随机效应图的t值中推断出来。
神经标记
除了群体级地图集外,我们还为每位参与者的语言网络提供了一套个体级神经标记(基于体积(volume)SPM分析)。这些神经标记包括:效应大小、体素计数和空间相关性(下面提供这些标记的额外信息)。所有这些标记都已被证明在个体内随时间可靠,包括跨扫描会话11。我们为之前定义的语言“区块”(在54 http://evlab.mit.edu/funcloc可获取)限定的每个ROI提供了这些测量值,每个半球包括三个前额区块(下额前回[IFG]、其眶部分[IFGorb]和中额前回[MFG])和三个颞/顶区块(前颞[AntTemp]、后颞[PostTemp]和角回[AngG]),共计12个区块。在地图集中包含的806名参与者中,只有803名完成了2次或更多次运行,这是计算效应大小和空间相关性标记所需的;对于剩下的3名参与者,只提供了体素计数。
效应大小被定义为关键语言>控制对照的百分比BOLD信号变化的大小。在每个区块内,我们为每位参与者定义了一个功能性ROI(fROI),通过选择掩模总体素中t值最高的10%的体素,用于语言>控制对照,使用除了一次运行的所有数据。然后,我们从留出的运行中提取对语言和控制条件的响应,并计算语言>控制的差异。这个程序在所有运行的分区中重复。这种跨运行的交叉验证程序3确保了用于定义fROIs和估计其响应的数据之间的独立性79。在最后一步,估计值在交叉验证折叠中平均,以得出每位参与者每个fROI的单一值。体素计数(激活范围)被定义为关键语言>控制对照在固定统计阈值(p<0.001未校正阈值)下的显著体素数。空间相关性(激活景观的稳定性)被定义为—对于落在语言区块内的体素—奇数和偶数编号运行中语言>控制对照的体素响应之间的Fisher转换的皮尔逊相关系数。如上所述,对于所有三个测量,我们为每位参与者提供14个值:每个半球的12个ROIs(每个半球6个)中的每一个,以及每个半球的两个额外值(跨每个半球的6个ROIs平均)。参见表3,了解地图集人群中这些神经标记的总结。可以基于我们提供的测量计算额外的测量值(例如,可以从体素计数计算侧化80),并且可以从整个大脑激活图中提取其他测量值(见数据记录)。
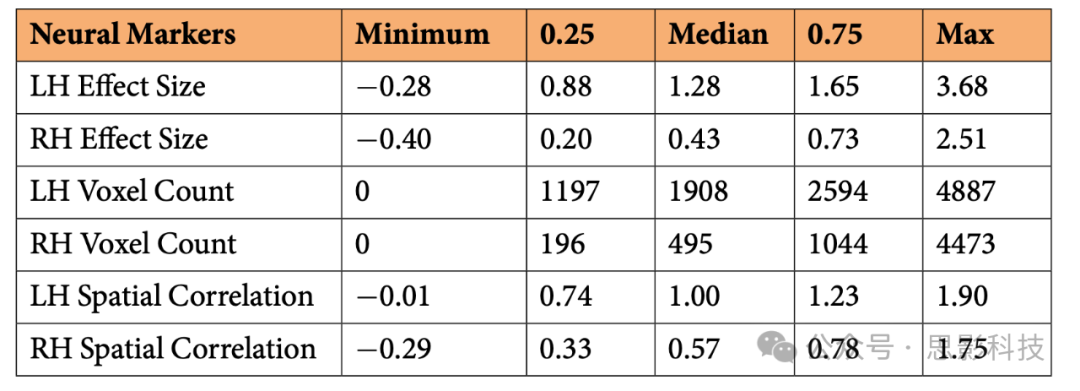
表3. 神经标记分布。总结了地图集中包含的803名参与者的语言>控制对照的神经标记,这些参与者我们有2次或更多次的运行数据。效应大小反映了语言fROIs中语言>控制对照的%BOLD信号变化(使用跨运行交叉验证估算,如文中所述)。体素计数反映了在固定统计阈值(p < 0.001未校正)下,语言区块边界内语言>控制对照的显著体素数量(见文本详情;神经标记)。空间相关性被定义为在语言区块边界内,奇数和偶数编号运行中语言>控制对照的体素响应之间的Fisher转换的皮尔逊相关系数。
LH = 左半球;RH = 右半球。列显示了对应于最小值、人群分布的第25百分位数的值、中位数、第75百分位数的值和最大值的值。
这些不同的测量可以相互探讨,或与人口统计变量探讨(但请参阅81,关于大脑-行为个体差异研究普遍存在的低功效问题的讨论)。这些测量也可以作为标准分布,用于评估任何新的人群,包括儿童或有发展性和获得性大脑障碍的个体,或其他非典型大脑82。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









