





自闭症谱系障碍(ASD)与社交行为能力的缺陷有关。在认知科学的广泛领域工作的科学家们已经进行了大量研究以发现ASD的根本原因,但其生物标志物仍然未知。神经科学领域的一些研究凸显了这样一个事实,即胼胝体和颅内脑容量为ASD的检测持有的重要信息。受此类发现的启发,在本文中,我们提出了一种基于机器学习的框架,利用从胼胝体和颅内脑容量中提取的特征自动检测ASD。我们提出的框架不仅实现了良好的识别准确性,而且通过选择在ASD分类判别能力方面最重要的特征,降低了训练机器学习模型的复杂性。其次,为了进行基准测试并验证深度学习在分析神经影像数据方面的潜力,在本文中,我们使用迁移学习方法展示了所取得的结果。为此,我们使用了预训练的VGG16模型进行ASD的分类。本文发表在Applied Artificial Intelligence杂志。(可添加微信号19962074063或18983979082获取原文及补充材料,另思影提供免费文献下载服务,如需要也可添加此微信号入群,思影提供脑影像数据分析及课程,如感兴趣也可添加微信咨询)
引言
计算机视觉和人工智能这一新兴领域已经主导了各个领域的研究和行业,现在旨在超越人类智能(Sebe et al. Citation2005)。借助计算机视觉和机器学习技术,在成像(Kak and Slaney Citation1988)、生物特征识别系统(Munir and Khan Citation2019)、计算生物学(Zhang Citation2002)、视频处理(Van Den Branden Lambrecht Citation2013)、情感分析(Khan et al. Citation2019b; Khan, et al., Citation2013a, Khan, et al., Citation2013b, Khan, Citation2013c)、医学诊断(Akram et al. Citation2013)、网络安全(Nazir and Khan Citation2021)、图像合成(Crenn et al. Citation2020)、电子健康记录(Shah and Khan Citation2020)等不同领域取得了不断进步。然而,尽管取得了所有这些进展,神经科学却是机器学习应用最少的领域之一,这是由于数据的复杂性。本文提出了一个框架,通过在称为ABIDE(自闭症脑成像数据交换)(Di Martino et al. Citation2014)的神经影像数据集上应用机器学习算法,自动识别自闭症谱系障碍(ASD)(Jaliaawala and Khan Citation2019)。
自闭症谱系障碍(ASD)是一种神经发育障碍,其特征是缺乏社会交往和情感智力,重复性的、令人憎恶的、被污名化的和固化的行为(Choi Citation2017; Jaliaawala and Khan Citation2019)。这种综合征不是一种罕见的疾病,而是一个具有众多残疾的谱系。ICD-10 WHO(世界卫生组织 Citation1993)(Organization Citation1993)和DSM-IV APA(美国精神病学协会)(Castillo et al. Citation2007)概述了根据社会和行为特征定义ASD的标准。根据他们的命名法,一个面临ASD的人在社交互动方面有异常趋势,缺乏语言和非语言交流技巧,对特定任务和活动的兴趣范围有限(Jaliaawala and Khan Citation2019)。基于这些行为特征,ASD进一步分为以下几组:
1. 高功能自闭症(HFA)(Baron-Cohen et al. Citation2001):HFA是一个术语,适用于患有自闭症障碍的人,他们被认为在认知上比其他自闭症患者"功能更高"(智商为70或更高)。
2. 阿斯伯格综合征(AS)(Klin, Volkmar, and Sparrow Citation2000):面临AS的个人在社交互动方面有质的损害,表现出局限、重复和刻板的行为、兴趣和活动模式。通常,这些人在语言或认知发展方面没有临床上显著的整体延迟。一般来说,面临AS(阿斯伯格综合征)的个人智商水平较高,但在面部动作和社交沟通技巧方面有所欠缺。
3. 注意力缺陷多动障碍(ADHD)(Barkley and Murphy Citation1998):患有ADHD的人表现出注意力不集中(注意力缺陷),他们有过度活跃的行为(多动)和有时冲动的行为(不假思索地行动)。
4. 精神病症状(Simonoff et al. Citation2008),如焦虑和抑郁。
最近基于人群的统计数据显示,自闭症是美国和英国增长最快的神经发育障碍(Rice Citation2009)。超过1%的儿童和成年人被诊断患有自闭症,根据美国疾病控制和预防中心(CDC)的报告,在美国和英国分别花费了2400万美元和2200万美元用于治疗(Buescher et al. Citation2014; Rice Citation2009)。众所周知,ASD检测的延迟与支持ASD个体的成本增加有关(Horlin et al. Citation2014)。因此,对于研究界来说,提出ASD早期检测的新方案是极其重要的,我们提出的框架可用于ASD的早期检测。
到目前为止,ASD的生物标志物尚不清楚(Del Valle Rubido et al. Citation2018; Jaliaawala and Khan Citation2019)。医生和临床医生正在练习标准化/常规方法进行ASD分析和诊断。智力特性和行为特征可用于ASD的诊断;然而,ASD的突触关联仍然未知,对认知神经科学和心理学研究人员来说是一项具有挑战性的任务(Kushki et al. Citation2013)。神经学中最近的一个假说表明,在面临ASD的个体中,大脑不同神经区域之间存在异常趋势(Bourgeron Citation2009)。这种变异趋势是由于神经模式的不规则性、认知功能在不同区域之间的解离和反相关性,影响了全球大脑网络(Schipul, Keller, and Just Citation2011)。
磁共振成像(MRI)是一种无创技术,已被广泛用于研究大脑区域网络。因此,MRI数据可用于揭示神经模式/网络中的细微变化,这有助于识别ASD的生物标志物。图1显示了不同横截面视图中MRI扫描的示例。根据所使用的扫描技术类型,MRI扫描进一步分为结构MRI(s-MRI)和功能MRI(f-MRI)(Bullmore and Sporns Citation2009)。结构MRI(s-MRI)扫描用于检查大脑的解剖结构和神经学。s-MRI扫描还用于测量大脑体积,即区域灰质(GM)、白质(WM)和脑脊液(CSF)(Giedd Citation2004),以及其亚区域的体积,并识别局部病变(Budman, Hoyt, and Friedman Citation1992)。功能MRI(f-MRI)扫描用于可视化与大脑功能相关的激活脑区。f-MRI通过检测不同认知区域的血流变化来计算同步神经活动。通过使用MRI扫描,许多研究人员已经报告了与ASD相关的独特脑区(Huettel, Song, and McCarthy et al. Huettel, et al., Citation2004)。
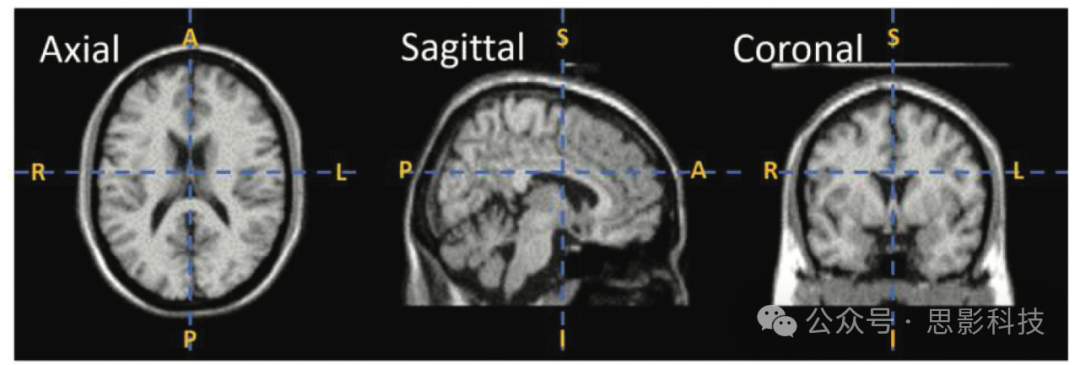
图1. 不同横截面视图中的MRI扫描,其中图中的A、P、S、I、R和L分别代表前、后、上、下、右、左。轴向/水平视图将MRI扫描分为头部和尾部/上部和下部,矢状面将扫描分为左右两部分,冠状面/垂直视图将MRI扫描分为前后两部分(Schnitzlein and Murtagh Citation1985)。
2012年,自闭症脑成像数据交换(ABIDE)为科学界提供了一个"开源"存储库,用于从脑成像数据即MRI数据中研究ASD(Di Martino et al. Citation2014)。ABIDE数据集包括1112名参与者(自闭症和健康对照)的rs-fMRI(静息状态功能磁共振成像)数据。rs-fMRI是一种在静息或任务负状态下捕获的f-MRI数据类型(Plitt, Barnes, and Martin Citation2015; Smith et al. Citation2009)。ABIDE还提供解剖扫描和表型Footnote1数据(Di Martino et al. Citation2014)。与ABIDE数据集相关的所有详细信息(数据收集和预处理)都在第3节中介绍。
在本研究中,我们提出了一个基于机器学习的框架,使用来自ABIDE数据集的T1加权MRI扫描自动检测ASD。使用T1加权MRI数据是因为有报告称T1加权MRI数据的结果具有高度可重复性(McGuire et al. Citation2017)。最初,为了自动检测ASD,我们利用了不同的传统机器学习方法(有关本研究中使用的机器学习算法的详细信息,请参阅第4.1.2节)。传统的机器学习方法是指除了最近流行的深度学习方法之外的方法。我们通过计算不同特征对给定任务的重要性/权重,进一步改进了传统机器学习方法取得的结果(第4.1.1节介绍了本研究中采用的特征选择方法)。特征是数据的可测量属性(Bishop Citation2006)。特征选择方法通过计算不同特征的判别能力来找到特征的权重/重要性,从而提高机器学习算法的预测性能、计算时间和泛化能力(Chandrashekar and Sahin Citation2014)。应用特征选择方法和传统机器学习方法获得的结果在第4.1.3节中讨论。最后,为了验证深度学习(LeCun, Bengio, and Hinton Citation2015)在分析神经影像数据方面的潜力,我们使用最先进的深度学习架构即VGG16(Simonyan and Zisserman Citation2014)进行了实验。我们使用迁移学习方法(Khan, et al., Citation2019a)来使用已经训练好的VGG16模型进行ASD检测。使用迁移学习方法获得的结果在第4.2节中介绍。第4.2节将帮助读者了解使用深度学习/CNN方法分析神经影像数据的好处和瓶颈,这些数据很难以足够大的数量记录用于深度学习。相关文献综述在下一节即第2节中介绍。
总之,我们在本研究中的贡献如下:
1. 我们展示了将机器学习算法应用于大脑解剖扫描以自动检测ASD的潜力。
2. 本研究表明,特征选择/加权方法有助于实现更好的ASD检测识别精度。
3. 我们还通过迁移学习方法提供了使用深度学习(LeCun, Bengio, and Hinton Citation2015)/卷积神经网络(CNN)的自动ASD检测结果。这将帮助读者了解使用深度学习/CNN方法分析神经影像数据的好处和瓶颈,这些数据很难以足够大的数量记录用于深度学习。
4. 我们还突出了改进此类框架自动检测ASD性能的未来方向。因此,这样的框架不仅可以在已发布的数据库上表现良好,而且可以在实际应用中表现良好,并帮助临床医生早期检测ASD。
现有技术:
在本节中,讨论了用于神经发育障碍分类的各种方法,但重点仍然是ASD的检测。人工智能技术(机器学习和深度学习)与脑成像数据的融合已经允许研究语义类别(Haxby et al. Citation2001)、名词意义(Buchweitz et al. Citation2012)、学习(Bauer and Just Citation2015)和情绪(Kassam et al. Citation2013)的表示。但是,由于问题的复杂性,机器学习算法在检测心理和神经发育疾病方面的一般应用,即精神分裂症(Bellak Citation1994)、自闭症(Just et al. Citation2014)和焦虑/抑郁(Craddock et al. Citation2009),仍然受到限制。
Craddock等人(Cameron Craddock and Holtzheimer Citation2009)使用多体素模式分析技术检测重度抑郁障碍(MDD)(Greicius et al. Citation2007)。他们展示了从四十名受试者收集的MRI数据的结果,即二十名健康对照组和二十名MDD个体。他们提出的框架达到了95%的准确率。Just等人(Just et al. Citation2014)提出了基于高斯朴素贝叶斯(GNB)分类器的方法,使用fMRI数据识别ASD和对照组参与者。他们在检测34名个体(17名对照组和17名自闭症个体)的自闭症时达到了97%的准确率。
Sabuncu等人(Sabuncu et al. Citation2015)进行的一项有前景的研究使用多元模式分析(MVPA)算法和结构MRI(s-MRI)数据来预测神经发育障碍链,即阿尔茨海默病、自闭症和精神分裂症。Sabuncu等人分析了来自六个公开网站(https://www.nmr.mgh.harvard.edu/lab/mripredict)的结构神经影像数据,共有2800名受试者。MVPA算法由三类分类器组成,包括支持向量机(SVM)(Vapnik Citation2013)、邻域近似森林(NAF)(Konukoglu et al. Citation2012)和相关向量机(RVM)(Tipping Citation2001)。Sabuncu等人使用5折验证方案(参见第4.1.3节中关于k折交叉验证方法的讨论),分别获得了70%、86%和59%的精神分裂症、阿尔茨海默病和自闭症检测准确率。
深度学习模型,即DNN(深度神经网络)(LeCun, Bengio, and Hinton Citation2015),在临床/神经科学/神经影像研究应用中具有巨大潜力。Plis等人(Plis et al. Citation2014)使用深度信念网络(DBN)自动检测精神分裂症(Bellak Citation1994)。Plis等人使用T1加权结构MRI(s-MRI)成像数据(关于s-MRI数据的讨论,请参见第1节)训练了具有三个隐藏层的模型:第一层、第二层和顶层分别有50-50-100个隐藏神经元。他们分析了约翰霍普金斯大学(JHU)、马里兰州精神病研究中心(MPRC)、伦敦精神病学研究所(IOP)和匹兹堡大学西部精神病学研究所(WPIC)进行的四项不同研究的数据集,其中包括198名精神分裂症患者和191名对照组,达到了90%的分类准确率。
Koyamada等人(Koyamada et al. Citation2015)表明,DNN在从神经影像数据中学习概念方面优于传统的监督学习方法,即支持向量机(SVM)122。Koyamada等人使用DNN研究了大脑活动中的大脑状态,以对具有七个任务类别的基于任务的fMRI数据进行分类:情绪反应、赌博、语言、运动、经验、人际关系和工作记忆。他们训练了一个具有两个隐藏层的深度神经网络,并实现了50.47%的平均准确率。
在另一项研究中,Heinsfeldl等人(Heinsfeld et al. Citation2018)通过从两个自动编码器(Vincent et al. Citation2008)迁移学习来训练神经网络(关于人工神经网络和多层感知器的讨论,请参见第4.1.2节)。迁移学习方法允许训练和测试中使用的分布不同,它还为神经网络在不同场景中使用学习到的神经元权重铺平了道路。Heinsfeldl等人研究的目的是检测ASD和健康对照组。自动编码器的主要目标是以无监督的方式学习数据,以提高模型的泛化能力(Vincent et al. Citation2010)。为了对这两个自动编码器进行无监督的预训练,Heinsfeldl等人利用了来自ABIDE-I数据集的rs-fMRI(静息状态-fMRI)图像数据。从这两个自动编码器中提取的权重形式的知识被映射到多层感知器(MLP)。Heinsfeldl等人实现了高达70%的分类准确率。
在最近发表的文章(Mazumdar, Arru, and Battisti Citation2021)中,Mazumdar等人提出了一种有趣的方法,通过利用儿童在分析视觉刺激(即图像)时的视觉行为,早期检测儿童的ASD。他们使用眼动追踪系统执行了心理视觉研究。将心理视觉研究中的特征与图像特征结合,并将机器学习算法应用于这些特征,以对受ASD影响的儿童进行分类。
Erkan和Thanh Erkan and Thanh(Citation2019)利用不同的机器学习算法,即KNN、RF和SVM,从UCI数据库的三个公开数据集中检测ASD。他们结合了"自闭症筛查成人数据集"、"儿童自闭症谱系障碍筛查数据集"和"青少年自闭症谱系障碍筛查数据集"的特征。本文提出的方法已经表明可以实现完美的分类评分。
另一种通过机器学习检测ASD的方法是分析交互行为。Xue等人(Yang et al. Citation2019)就做了这样的努力。他们提出了一个系统,用于分析儿童与NAO机器人之间的交互。基于NAO机器人呈现的图像书内容与对话主题之间的对应关系,系统可以检测儿童的ASD。
Wang等人(Citation2020)针对影响数据分布的数据集站点间异质性问题提出了一种解决方案。作者提出了一种基于多站点域适应的低秩表征分解方法。所提出的方法通过计算共同的低秩表示来减少多站点数据分布中的差异。一个站点被标记为目标域,而其余站点被标记为源域。这允许使用低秩表示将数据转换到公共空间。机器学习方法,即KNN和SVM,用于学习最优低秩表示的优化参数。作为测试案例,他们在(ABIDE)数据集上展示了他们的结果。ABIDE是一个在线共享联盟,提供ASD和对照组参与者的成像数据及其表型信息。ABIDE数据集由17个国际站点组成,共有1112名受试者。机器学习方法,即KNN和SVM,用于将自闭症受试者与对照组受试者区分开来。另一种针对多站点收集的数据异质性问题提出的算法是Wang等人提出的Wang et al.(Citation2021)。在这篇文章中,作者提出了一种使用所提出的多站点聚类和嵌套特征提取(MC-NFE)方法对fMRI数据进行ASD检测的方法。所提出的方法通过相似性驱动的多视图线性重构方法对站点间异质性进行建模。ABIDE数据集用于证明所提出方法的稳健性。
需要注意的是,将机器学习与多个站点(如ABIDE)收集的脑成像数据相结合以识别自闭症的研究表明,分类准确性往往会降低(Arbabshirani et al. Citation2017)。在本研究中,我们也观察到了相同的趋势。Nielsen等人(Nielsen et al. Citation2013)也从ABIDE数据集中发现了相同的模式/趋势,并得出结论,那些BOLD成像时间更长的站点的分类准确性明显更高。相比之下,血氧水平依赖(BOLD)是一种在fMRI中使用的成像方法,通过血流变化来观察活动区域。在这些区域中,血液浓度似乎比其他区域更活跃(Huettel, et al., Citation2004)。
上述研究主要集中在分析神经影像数据,即MRI和fMRI扫描数据,以检测不同的神经发育障碍。用于预测心理障碍的不同脑区并未得到关注。研究表明,大脑的不同区域突出显示了健康个体与面临神经发育障碍的个体之间的细微差异。使用ABIDE数据集的定量调查报告发现,ASD参与者的脑容量增加,胼胝体(Zaidel and Iacoboni Citation2003)区域减少。其中,胼胝体在整合信息和调节行为方面具有核心功能(Hinkley et al. Citation2012)。胼胝体由大约2亿根不同直径的纤维组成,是人脑最大的半球间连接(Tomasch Citation1954)。
Hiess等人(Hiess et al. Citation2015)也得出结论,尽管ASD和对照组参与者之间的胼胝体亚区没有显著差异,但面临ASD的个体颅内容积增加。颅内容积(ICV)用于估计大脑和脑区/容积分析的大小(Nordenskjöld et al. Citation2013)。Waiter等人(Waiter et al. Citation2005)报告了胼胝体压部(splenium)和峡部(isthmus)尺寸的减小,Chung等人(Chung, et al., Citation2004)也发现自闭症患者的胼胝体压部、膝部(genu)和喙部(rostrum)区域减小。其中,压部、峡部、膝部和喙部是根据Witelson等人(Witelson Citation1989)和Venkatasubramanian等人(Venkatasubramanian et al. Citation2007)的研究对胼胝体进行的区域细分。图2展示了胼胝体不同分割子区域的图示。在本研究中,将胼胝体的细分区域和颅内脑容量作为特征向量(特征向量的讨论请参考第4.1.1节)的动机来自于文献综述,这些区域通常被认为对自闭症的检测很重要。
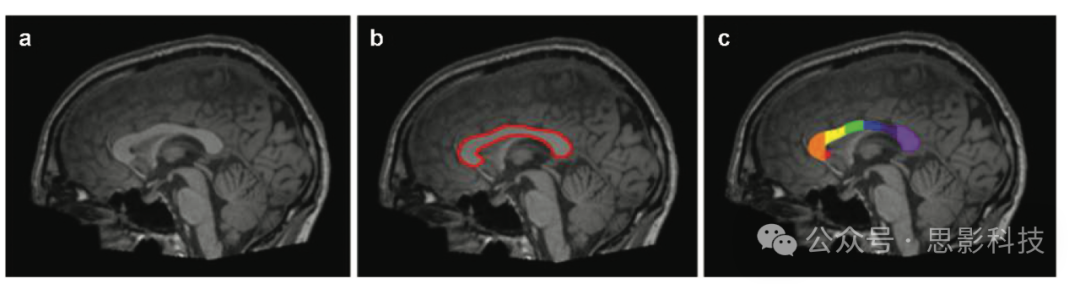
图2.胼胝体区域分割示例。该图显示了ABIDE研究中一个面临ASD的个体的示例数据。图A表示三维容积T1加权MRI扫描。图B表示红色的胼胝体分割。图C表示根据Witelson方案(Witelson Citation1989)对胼胝体进行进一步划分。W1(喙部)、W2(膝部)、W3(前体)、W4(中体)、W5(后体)、W6(峡部)和W7(压部)分别用红色、橙色、黄色、绿色、蓝色、紫色和浅紫色表示(Kucharsky Hiess et al. Citation2015)。
下一节将介绍与ABIDE数据库相关的所有详细信息,并解释预处理过程。
数据库
本研究使用了来自自闭症脑成像数据交换(ABIDE-I)数据集的结构MRI(s-MRI)扫描数据。ABIDE是一个在线共享联盟,提供ASD和对照组参与者的成像数据及其表型信息(Di Martino et al. Citation2014)。ABIDE-I数据集由17个国际站点组成,共有1112个受试者或样本,其中包括(539例自闭症病例和573例健康对照组参与者)。根据《健康保险便携性和责任法案》(HIPAA)(Act Citation1996)准则,未披露参与ABIDE数据库记录的个人身份。表1显示了ABIDE研究中每个站点的结构MRI(s-MRI)扫描的图像采集参数。
表1. ABIDE数据库中每个站点的结构MRI采集参数(Kucharsky Hiess et al. Citation2015)
我们使用了与Hiess等人的研究(Kucharsky Hiess et al. Citation2015)中相同的特征。接下来,我们将解释Hiess等人在ABIDE数据集的T1加权MRI扫描上进行的预处理,以计算胼胝体和脑容积的不同参数和区域。
预处理:
使用不同的软件计算了胼胝体区域、其亚区和颅内体积。这些软件如下:
1. yuki (Ardekani Citation2013)
2. fsl (https://fsl.fmrib.ox.ac.uk/fsl/fslwiki/)
3. itksnap (Yushkevich et al. Citation2006)
4. brainwash
胼胝体在整合信息和媒介行为方面具有中心功能(Hinkley et al. Citation2012)。胼胝体由大约2亿根不同直径的纤维组成,是人脑最大的半球间连接(Tomasch Citation1954)。而颅内体积(ICV)被用作估计大脑大小和脑区/体积分析的指标(Nordenskjöld et al. Citation2013)。
使用"yuki"软件(Ardekani Citation2013)对每个参与者的胼胝体区域进行了分割。使用Witelson方案(Witelson Citation1989)自动将胼胝体划分为其亚区。图2显示了胼胝体分割的示例。使用"ITK-SNAP"(Yushkevich et al. Citation2006)软件包对每个分割进行了目视检查和必要的校正。检查和校正过程由两名读者进行。由于某些MRI扫描的胼胝体分割中有轻微的手动校正,因此计算了两个读者测量的胼胝体区域的统计等效性分析和组内相关系数。
颅内总脑体积(Malone et al. Citation2015)是使用软件工具"brainwash"来测量的。"Automatic Registration Toolbox"(www.nitrc.org/projects/art)是brainwash中的一个功能,用于提取颅内脑体积。brainwash方法使用非线性变换,通过将共同配准的标签(预标记的颅内区域)映射到参与者的MRI扫描来估计颅内区域。体素投票方案(Manjón and Coupé Citation2016)用于将参与者MRI中的每个体素分类为颅内或非颅内。对每个大脑分割进行目视检查,以确保准确分割。在某些分割未正确执行的情况下,采取了以下额外步骤进行处理:
1. 在某些脑分割未正确实现的情况下,使用预处理的MRI扫描的同一部位再次执行brainwash方法,该部位的脑分割没有错误。
2. brainwash软件自动识别前后联合的坐标。在某些情况下,这些点没有被正确识别。在这种情况下,手动识别它们并输入软件。
3. “ITK-SNAP”软件包中实现的“基于区域的活动轮廓”特性被用于手动微调颅内体积分割错误。(Yushkevich等,2006年引用)
图3呈现了所提框架的示意概览。它展示了T1加权MRI扫描如何被转化为M x N维的特征向量,其中M表示样本总数,N表示特征向量中的特征总数。这里的特征是数据的可测量属性(Bishop,2006年引用)。然后,这些特征被用于训练检测ASD的模型。
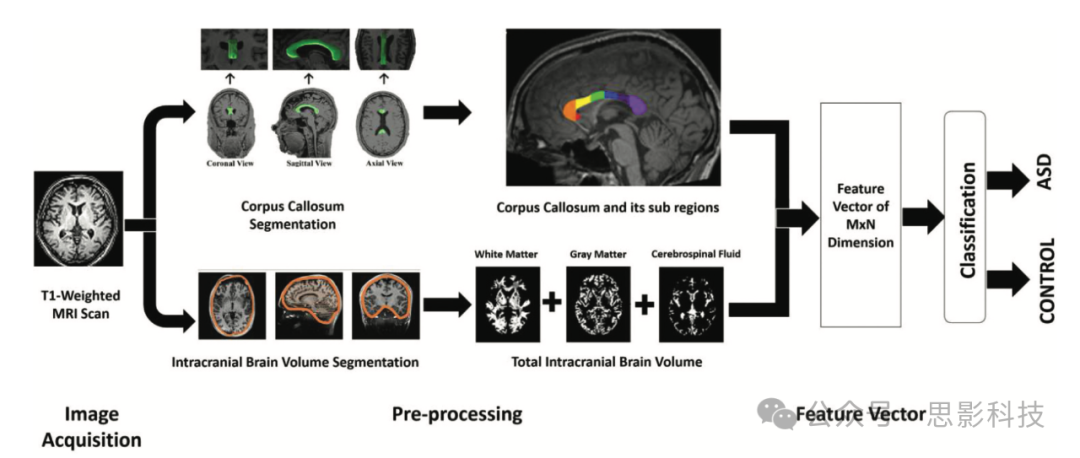
图3. 所提出框架的示意概览。
实验和结果
传统机器学习方法
在每个机器学习问题中,在应用任何机器学习方法之前,选择一组有用的特征或特征向量是一项重要任务。从数据集中提取的最佳特征可最小化类内变异(ASD vs对照个体),同时最大化类间变异(Khan Citation2013c)。特征选择技术用于通过删除给定任务的冗余或不相关特征来找到最佳特征。下一小节4.1.1将介绍评估的特征选择方法。第4.1.2节将讨论本研究中使用的传统机器学习方法,其中传统机器学习方法指除最近流行的深度学习方法以外的方法。第4.1.3节将讨论传统机器学习方法的结果。
特征选择
如上所述,我们使用了与 Hiess 等人研究(Kucharsky Hiess et al. Citation2015)相同的特征。通过使用相同的特征,我们可以稳健地验证所提出的基于机器学习的框架的相对优缺点,因为 Hiess 等人的研究没有采用机器学习。Hiess 等人已经将来自 ABIDE 的预处理 T1加权 MRI 扫描数据公开用于研究。预处理数据包括胼胝体、其亚区域和颅内脑体积的参数特征以及标签。总的来说,预处理数据由来自1100个样本的12个特征组成(12 x 1100)。表2概述了预处理数据的统计摘要。
表2. ABIDE预处理数据的统计摘要
CC =胼胝体
b,c,d,e,f,g,h Witelson (Witelson Citation1989)胼胝体的亚区域
选择有用的特征子集以通过消除冗余特征来提取有意义的结果是一项非常全面且递归的任务。为了增强计算简单性,降低复杂性并提高机器学习算法的性能,在预处理的 ABIDE 数据集上应用了不同的特征选择技术。在文献中,通常使用基于熵或相关性的方法进行特征选择。因此,我们也采用了基于熵和相关性的最新方法来选择能最小化类内变异(ASD vs 对照个体)同时最大化类间变异的特征。本研究中评估的方法解释如下:
信息增益
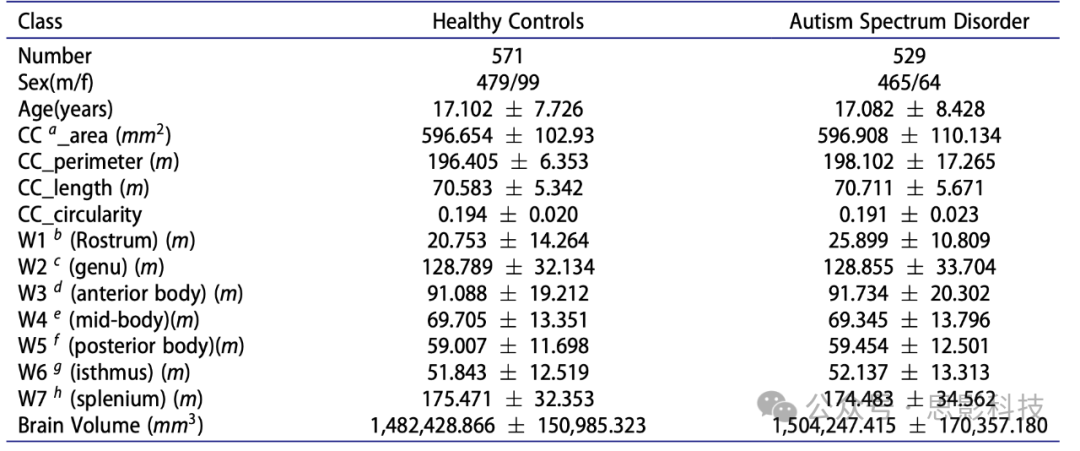
信息增益(IG)是一种特征选择技术,用于衡量一个特征为相应类别提供了多少信息。它以熵的形式度量信息。熵被定义为特征中不纯度、无序性或不确定性的概率度量(Quinlan Citation1986)。因此,具有较低熵值的特征倾向于提供更多信息,被认为更相关。对于给定的一组SN个训练样本,ni是该组中第
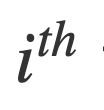
个特征的向量,
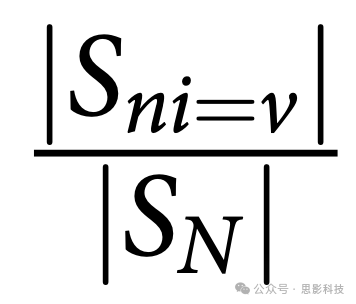
是第
个特征值为v的样本的比例。以下方程式用数学表示为:
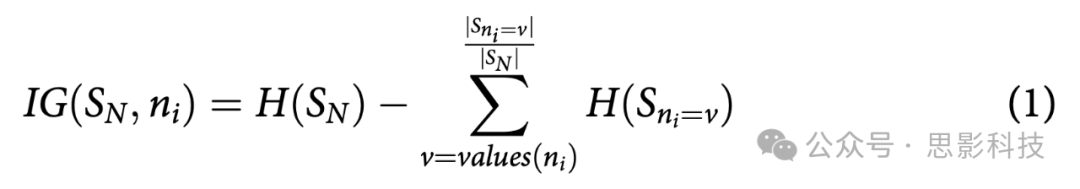
其中,熵定义为:
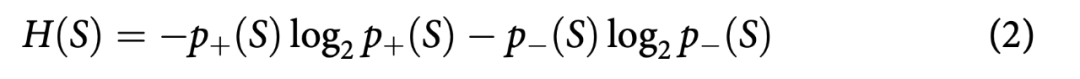
p±(S)分别是数据集S中训练样本属于相应正类和负类的概率。
信息增益率
信息增益(IG)在选择具有较大值的特征时存在偏差(Yu and Liu Citation2003)。信息增益率是信息增益的修正版本,可以减少其偏差。它计算为信息增益与固有值(intrinsic value)的比率(Kononenko and Hong Citation1997)。固有值(IV)是熵的附加计算。对于给定的特征集Feat,所有训练样本Ex,其中values(x,f)表示特定样本

具有特征值f∈Feat。values(f)函数表示特征f∈Feat的所有可能值的集合。特征f∈Feat的信息增益率IGR(Ex,f)数学表示为:
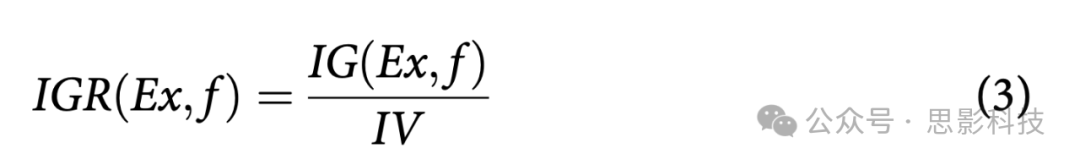
固有值(IV)为:
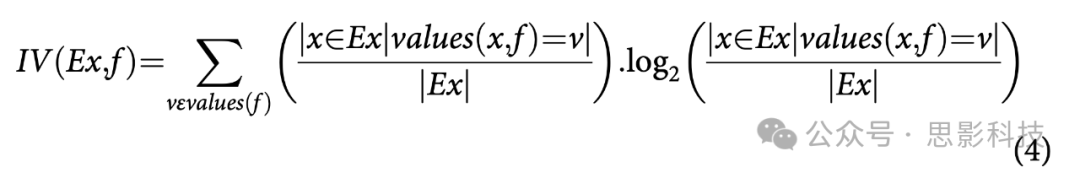
卡方方法
卡方(χ2)是一种基于相关性的特征选择方法(也称为皮尔逊卡方检验),用于计算两个独立变量之间的依赖关系,其中两个变量A和B被定义为独立的,如果P(AB)=P(A)P(B),或等价地,P(A|B)=P(A)和P(B|A)=P(B)。在机器学习中,两个变量是特征和类别标签的出现(Doshi Citation2014)。卡方方法通过计算以下表达式所表示的统计值来计算每个特征的相关强度:

其中,(χ2)是卡方统计量,O是第i个特征的实际值,E是第i个特征的期望值。
对称不确定性
对称不确定性(Symmetrical Uncertainty, SU)被称为相关性索引或评分(Brown et al. Citation2012)方法,用于寻找特征和类别标签之间的关系。它将特征的值归一化到[0, 1]的范围内,其中1表示特征和目标类别强烈相关,0表示它们之间没有关系(Peng, Long, and Ding Citation2005)。对于类别标签Y,特征集X的对称不确定性数学表示为:
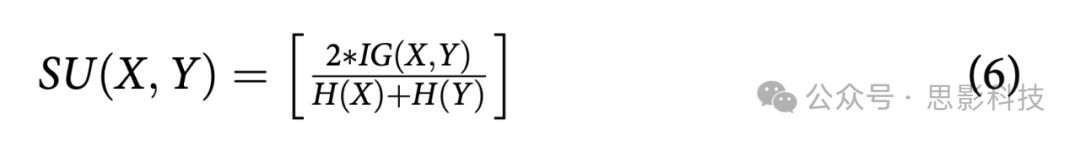
其中,IG(X,Y)表示信息增益,H分别表示熵。
所有四种方法(信息增益、信息增益率、卡方和对称不确定性)都计算每个特征对于给定任务的值/重要性/权重。每个特征的权重是根据类别标签和每种方法计算的特征值来计算的。特征的权重越高,就认为它越相关。每个特征的权重在[0, 1]范围内归一化。每种特征选择方法的结果如图4所示。
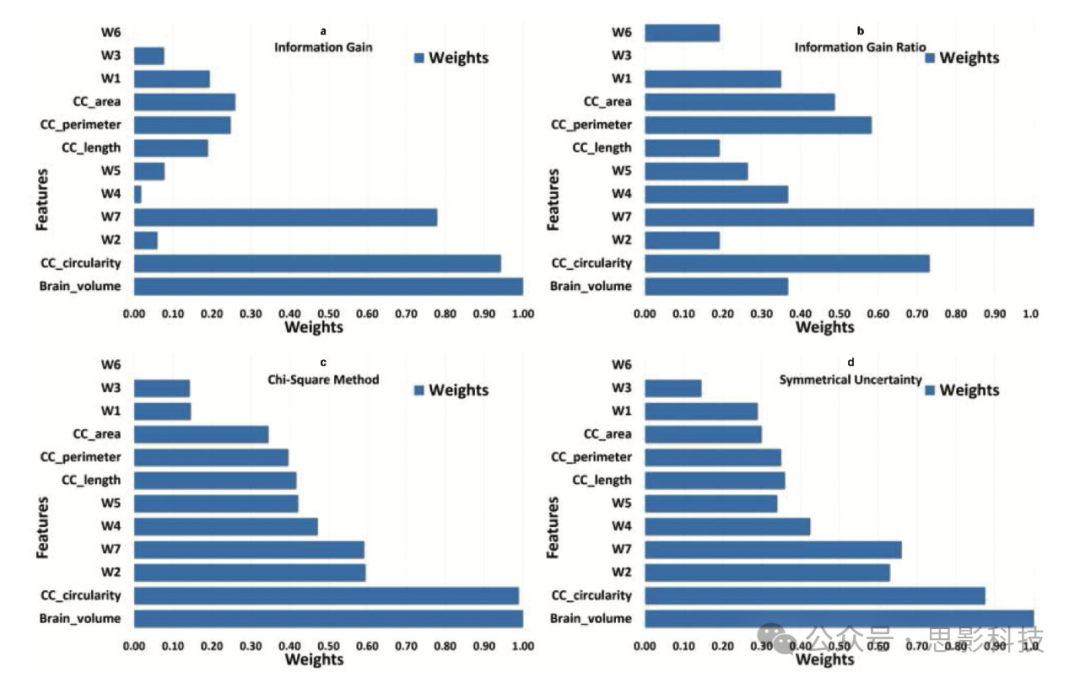
图4. 基于熵和相关性的特征选择方法的结果。所有特征都用其相应的权重表示。A表示信息增益的结果。B表示信息增益率的结果。C表示卡方法的结果。D表示对称不确定性的结果。
图4展示了特征选择研究的结果。前两个图显示了从基于熵的方法(即信息增益和信息增益率)计算出的不同特征的权重。最后两个图展示了从基于相关性的方法(即卡方和对称不确定性)获得的特征权重。信息增益率的结果与信息增益不同,但在这两种方法中,W7和CC_circularity都是最重要的特征。基于相关性的方法(即卡方和对称不确定性)的结果几乎相似,只有很小的差异。brain_volume、W7、W2和CC_circularity是最具区分性的特征。
值得强调的是,在我们的研究中提供更多区分信息的特征与Hiess等人(Kucharsky Hiess et al. Citation2015)的研究中确定的特征相当。Hiess等人(Kucharsky Hiess et al. Citation2015)得出结论,brain_volume和胼胝体面积是用于区分ABIDE数据集中ASD和对照组的两个重要特征。在我们的研究中,我们还得出结论,brain_volume和胼胝体的不同子区域,即膝部、中体和压部,标记为W2、W4和W7,是最具区分性的特征。事实上,基于相关性方法(即卡方和对称不确定性)的结果与Hiess等人(Kucharsky Hiess et al. Citation2015)提出的结果相当。
在我们提出的框架中,我们对特征选择方法获得的结果应用阈值,以选择一个特征子集,降低计算复杂性并提高机器学习算法的性能。我们使用不同的阈值进行了实验,并根据经验发现,在阈值p=0.4时,从卡方方法的特征子集获得的平均分类精度(ASD检测)最高。
本研究推导出的最终特征向量包括Brain_volume、CC_circularity、CC_length、W2(genu)、W4(mid-body)、W5(posterior-body)和W7(splenium),其中CC=胼胝体。表3展示了在应用传统机器学习方法后,有无特征选择方法的平均分类精度。从表中可以看出,在具有区分性的特征子集上训练分类器不仅在计算复杂性方面,而且在平均分类精度方面都能获得更好的结果。
下一小节4.1.2讨论了本研究中评估的传统机器学习方法。
使用的传统机器学习方法
分类是从给定的数据集或样本中搜索模式/学习模式/概念并预测其类别的过程(Bishop Citation2006)。为了从预处理的ABIDE数据集(由特征选择算法选择的特征,参见第4.1.1节)中自动检测ASD,我们评估了以下提到的最先进的传统机器学习分类器:
1. 线性判别分析(LDA)
2. 支持向量机(SVM)与径向基函数(rbf)核
3. 10棵树的随机森林(RF)
4. 多层感知器(MLP)
5. K最近邻(KNN),K=3
我们从不同类别中选择分类器。例如,K最近邻(KNN)是非参数的基于实例的学习器,支持向量机(SVM)是大边界分类器,理论上将数据映射到更高维度的空间以获得更好的分类,随机森林(RF)是基于树的分类器,将样本集分解为一组覆盖决策规则,而多层感知器(MLP)是受人脑解剖学的启发。以上提到的分类器简要说明如下。
线性判别分析(LDA)
LDA是一种统计方法,它找到特征的线性组合,将数据集分离到其对应的类别中。得到的组合用作线性分类器(Jain and Huang Citation2004)。LDA通过最大化类间方差与类内方差的比值来最大化线性可分性,以适用于任何特定数据集。设ω1,ω2,..,ωL和N1,N2,..,NL分别为各类别和每个类别中的样本数。设M1,M2…,ML和M分别为各类别的均值和总均值。然后,类内和类间散度矩阵Sw和Sb定义为:
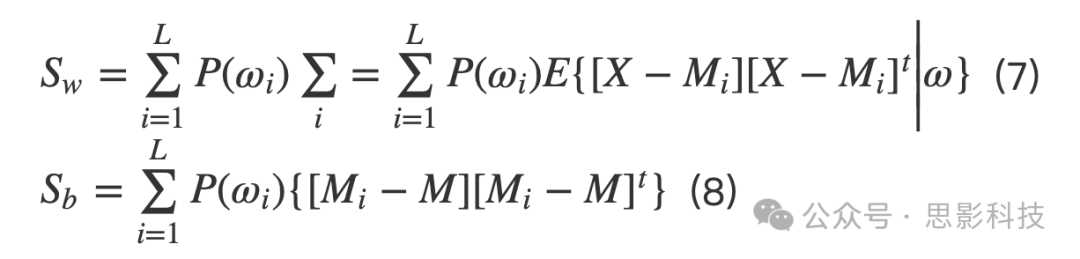
其中P(ωi)是先验概率,∑i表示类别ωi的协方差矩阵。
支持向量机(SVM)
SVM分类器通过构建称为超平面的决策边界将样本分为相应的类别(Vapnik Citation2013)。它隐式地将数据集映射到更高维度的特征空间,并在更高维度空间中构建一条与分离超平面具有最大边缘距离的线性可分线。对于一个训练样本集{(xi,yi),i=1…,l},其中xi∈ℜn,yi∈{−1,1},一个新的测试样本x通过以下函数进行分类:
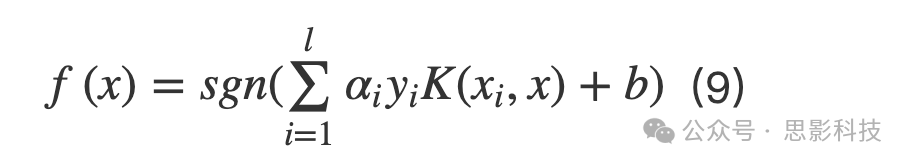
其中αi是分离两个超平面的对偶优化问题的拉格朗日乘子,K(.,.)是核函数,b是超平面的阈值参数。
随机森林(RF)
随机森林属于决策树家族,能够执行分类和回归任务。分类树由节点和分支组成,将样本集分解为一组覆盖决策规则(Mitchell Citation1997)。RF是由许多相关决策树组成的集成树分类器,其输出是各个决策树输出的类的众数。
多层感知器(MLP)
MLP属于神经网络家族,由相互连接的人工神经元组(称为节点)和用于处理信息的连接(称为边)组成(Jain, Mao, and Moidin Mohiuddin Citation1996)。神经网络由输入层、隐藏层和输出层组成。输入层以特征向量的形式传输带有权重值的输入到隐藏层。隐藏层由激活单元或传递函数组成(Gardner and Dorling Citation1998),携带来自第一层的带有权重值的特征向量并执行一些计算作为输出。输出层由单个激活单元组成,携带隐藏层的加权输出并预测相应的类别。图5显示了一个具有2个隐藏层的MLP示例。多层感知器被描述为完全连接,每个节点连接到下一层和上一层的每个节点。MLP在训练期间利用反向传播的功能(Hecht-Nielsen Citation1992)来减少错误函数。通过更新每一层的权重值来减少错误。对于一组训练样本{X=(x1,x2,x3,….,xm)}和输出y∈{0,1},一个新的测试样本x通过以下函数进行分类:
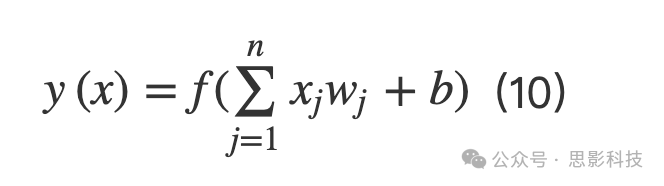
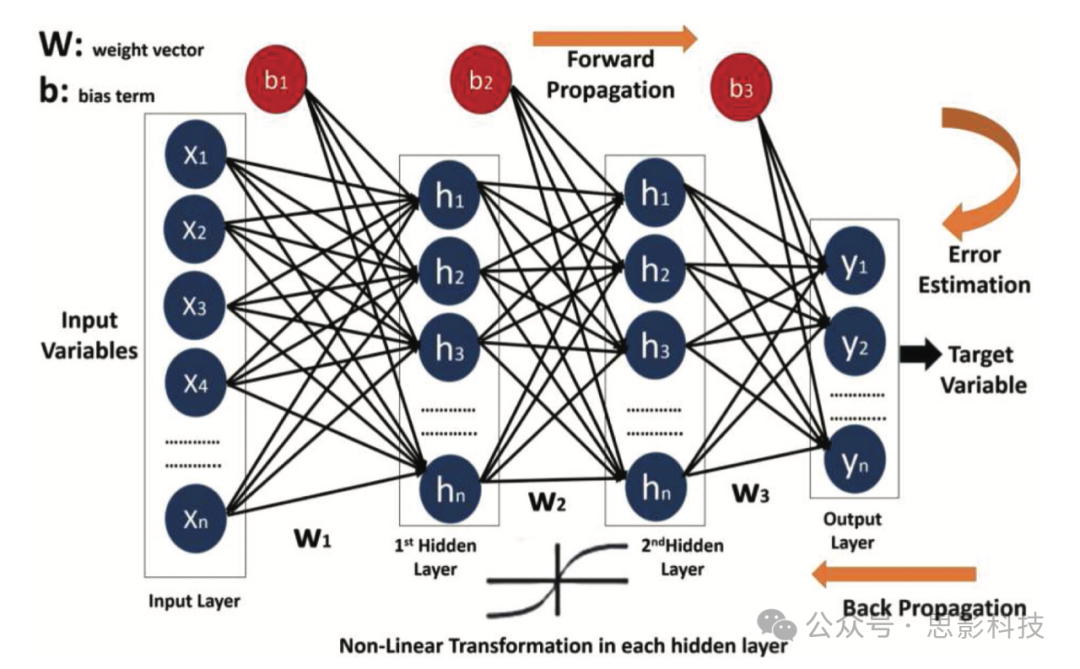
图5. 多层感知器(MLP)的架构。
其中f是非线性激活函数,wj是每一层j中与输入相乘的权重,b是偏置项。
K最近邻(KNN)
KNN是一种基于实例的非参数分类器,能够根据目标函数找到与新样本最接近的训练样本数量(Khan, Citation2013c; Acuna and Rodriguez Citation2004)。根据目标函数的值,它推断输出类的值。未知样本q属于类y的概率可以计算如下:
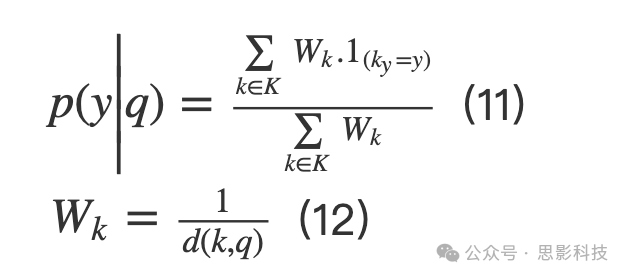
其中K是最近邻居的集合,ky是k的类别,d(k,q)是k到q的欧几里得距离。
结果与评估
我们选择以与Heinsfeldl等人提出的评估标准相同的方式来评估我们框架的性能(Heinsfeld et al. Citation2018)。Heinsfeldl等人根据k折交叉验证和留一个站点出分类方案来评估其框架的性能(Bishop Citation2006)。我们也根据这些方案评估了上述分类器的结果。
k折交叉验证方案
交叉验证是一种统计技术,通过将数据集分为两部分来评估和比较学习算法:一部分用于学习或训练模型,另一部分用于验证模型(Kohavi . Citation1995)。在k折交叉验证方案中,数据集被分成k个大小相等的部分、段或折。随后,执行k次学习和验证迭代,在每次迭代中,(k-1)折用于学习,一个不同的数据折用于验证(Bishop Citation2006)。在完成k折后,通过平均每一折的评估指标值(即准确率)来计算算法的性能。
所有研究的分类器都在5折交叉验证方案上进行评估。数据集被分为5个大小相等的部分。在5折交叉验证中,4个数据段用于训练,另一个部分用于测试。
图6展示了在预处理的ABIDE数据(由特征选择算法选择的特征,参见第4.1.1节)上,使用5折交叉验证方案研究的分类器实现的平均ASD识别准确率。结果表明,所有分类器的整体准确率随着折数的增加而提高。线性判别分析(LDA)、支持向量机(SVM)、随机森林(RF)、多层感知器(MLP)和K最近邻(KNN)分别实现了55.93%、52.20%、54.79%、54.98%和51.00%的平均准确率。结果也在表3中报告。
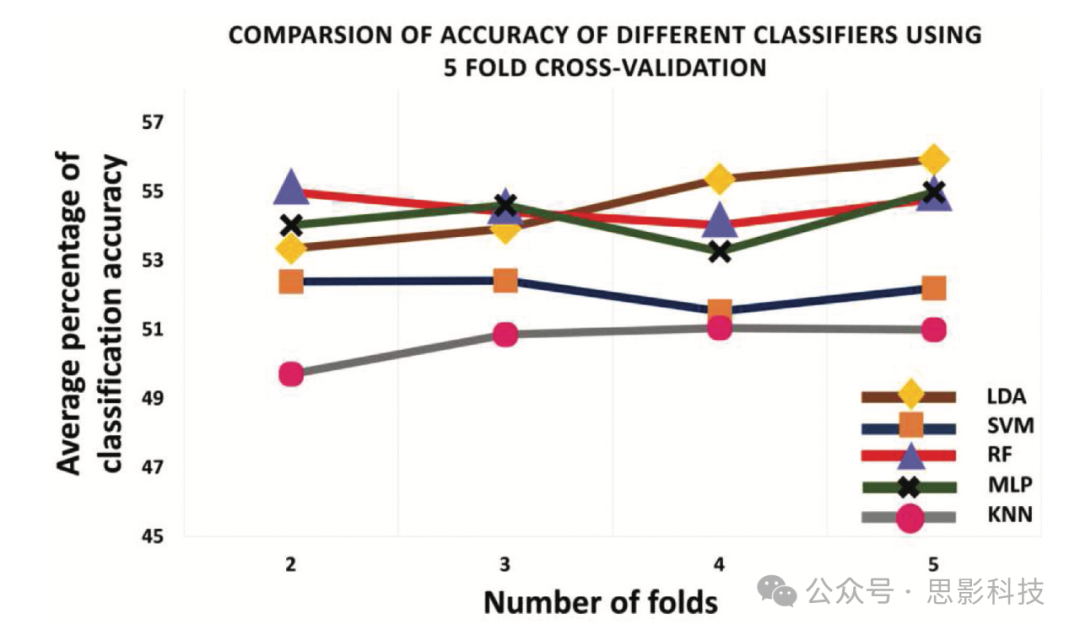
图6. 5折交叉验证方案的结果。
留一个站点出分类方案
在这个分类验证方案中,我们使用来自一个站点的数据进行测试,以评估模型的性能,而其余站点的数据则用于训练。图7展示了这一过程的示意图。
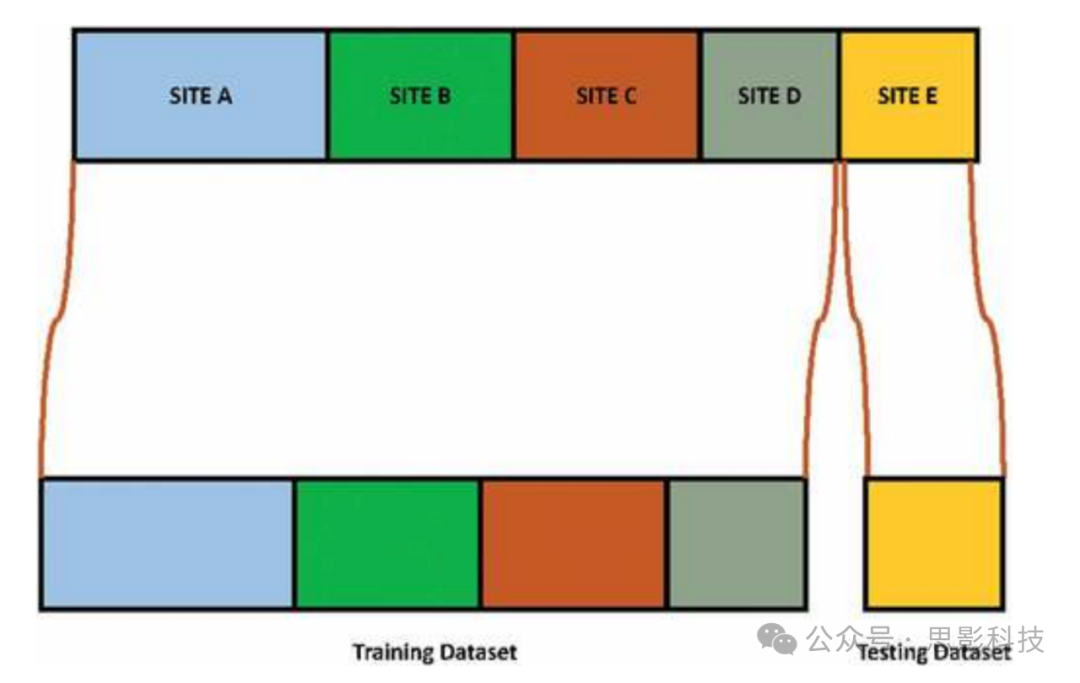
图7. 留一个站点出分类方案示意图。
使用留一个站点出分类方案进行ASD识别时,线性判别分析(LDA)、支持向量机(SVM)、随机森林(RF)、多层感知器(MLP)和K最近邻(KNN)的平均准确率分别达到56.21%、51.34%、54.61%、56.26%和52.16%。结果如表3所示。
图8展示了使用留一个站点出分类方法对每个站点的识别结果。有趣的是,对于所有站点,USM站点数据的ASD分类准确率最高,3-NN分类器达到79.21%的准确率。LDA在CALTECH站点数据上获得的准确率为76.32%,是第二高的。这一结果与Heinsfeldl等人的结果一致(Heinsfeld et al. Citation2018)。
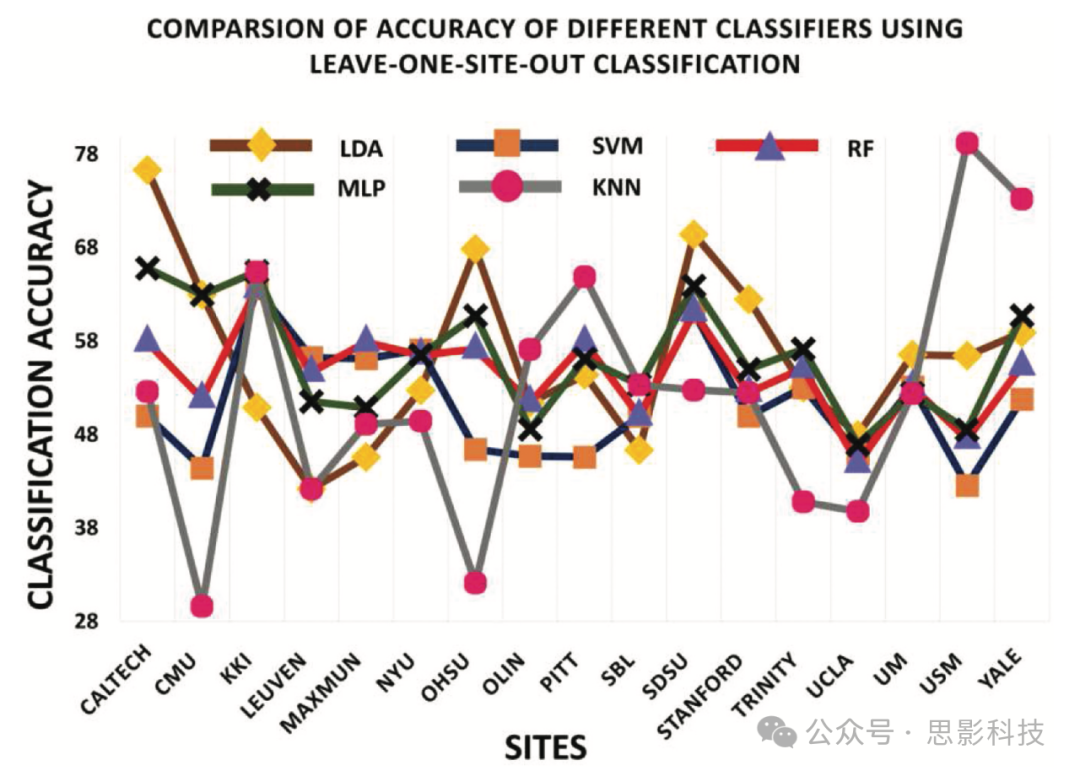
图8. 留一个站点出分类方案的结果。
所有分类器的留一个站点出分类结果显示,不同站点之间存在差异。结果表明,这种差异可能是由于训练阶段使用的样本数量变化所致。此外,不同站点之间的数据也存在差异。表1列出了ABIDE数据集中各个站点使用的结构MRI采集参数(Kucharsky Hiess et al. Citation2015)。
基于迁移学习的方法
使用传统机器学习算法(有无特征选择方法)获得的结果在第4.1.3节中给出。可以观察到,对于不同的传统机器学习算法,在ABIDE数据集上进行自闭症检测的平均识别准确率在52%到55%之间;参见表3。为了实现更好的识别准确率,并测试最新机器学习技术(即深度学习)的潜力(LeCun, Bengio, and Hinton Citation2015),我们采用了基于VGG16模型的迁移学习方法(Simonyan and Zisserman Citation2014)。
通常,在机器学习算法中,训练和测试数据来自相同的分布。相反,迁移学习允许训练和测试中使用的分布不同(Pan and Yang Citation2010)。采用迁移学习方法的动机来自以下事实:从头开始训练深度学习网络需要大量数据(LeCun, Bengio, and Hinton Citation2015),但在我们的案例中,ABIDE数据集(Di Martino et al. Citation2014)包含来自1112名受试者的标记样本(539例自闭症病例和573名健康对照组参与者)。迁移学习允许对已训练的模型进行部分再训练(通常是最后一层)(Pan and Yang Citation2010),同时保持模型中所有其他层(训练权重)不变,这些层在数百万个语义相似任务的样本上进行训练。我们在研究中使用迁移学习方法,因为我们希望从在视觉识别任务(即ImageNet大规模视觉识别挑战(ILSVRC))(Russakovsky et al. Citation2015)上实现高准确率且可用于研究目的的深度学习模型中获益。
ILSVRC中出现的一些著名深度学习架构包括来自Google的GoogleNet(又名Inception V1)(Szegedy et al. Citation2015)和Simonyan和Zisserman的VGGNet(Simonyan and Zisserman Citation2014)。这两种架构都属于卷积神经网络(CNN)家族,因为它们采用卷积运算来分析视觉输入(即图像)。我们选择使用VGGNet,它由16个卷积层(VGG16)组成(Simonyan and Zisserman Citation2014)。由于其统一的架构和在视觉识别任务中的稳健性,它是最具吸引力的框架之一,参见图9。其预训练模型可免费用于研究目的,因此是迁移学习的良好选择。
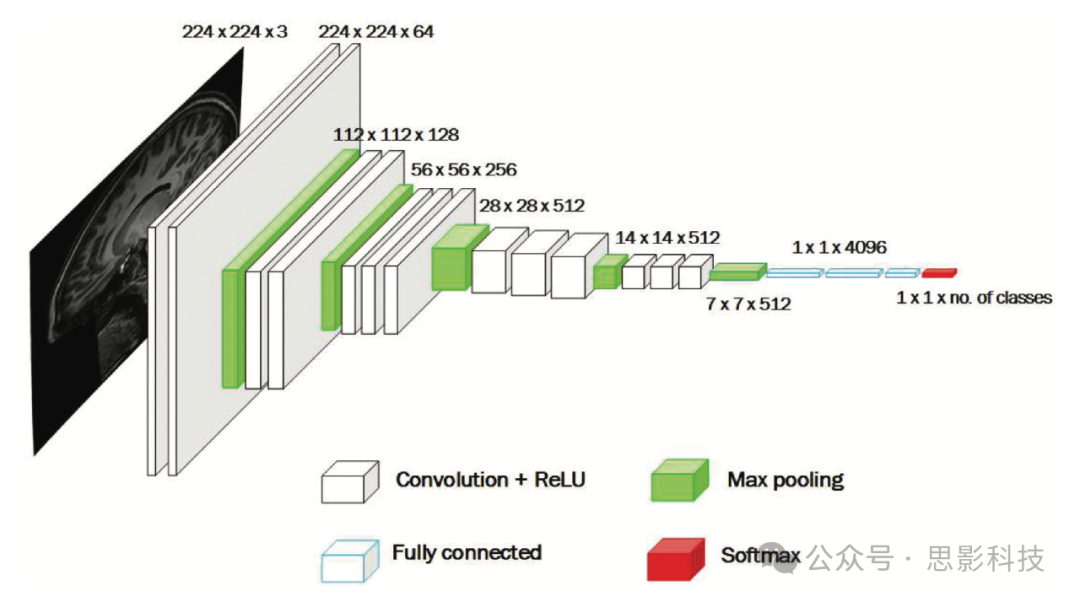
图9. VGG16架构示意图(Simonyan and Zisserman Citation2014)。
VGG16架构(参见图9)接受224×224的图像输入,感受野大小为3x3,卷积步幅为1个像素,填充为1(对于3×3的感受野)。它使用整流线性单元(ReLU)(Nair and Hinton Citation2010)作为激活函数。分类使用具有x个单元(表示x个类别/要识别的x个类别)的softmax分类层完成。其他层是卷积层和特征池化层。卷积层使用与输入图像卷积以生成激活或特征图的滤波器。架构中使用特征池化层来减小图像表示的大小,提高计算效率并控制过拟合。
结果
如前所述,本研究使用自闭症脑成像数据交换(ABIDE-I)数据集的结构MRI(s-MRI)扫描进行(Di Martino et al. Citation2014)。ABIDE-I数据集包括17个国际站点,共1112个受试者或样本,其中包括539例自闭症病例和573名健康对照组参与者。
ABIDE-I数据集中的MRI扫描以神经影像信息学技术倡议(nifti)文件格式提供(Cox et al. Citation2003),其中图像表示解剖体积到图像平面的投影。最初,所有解剖扫描都从nifti转换为标记图像文件格式,即TIFF或TIF,这是一种无压缩格式(Guarneri, Vaccaro, and Guarneri Citation2008),创建了一个约200k张tif图像的数据集。但我们没有使用所有tif图像进行迁移学习,因为从单个扫描中提取的图像的开始和结尾部分包含感兴趣区域(即胼胝体)的剪切/裁剪部分。因此,我们得到了约100k张tif图像,其中胼胝体的可见完整部分。
对于迁移学习,使用了由16个卷积层(VGG16)组成的VGGNet(Simonyan and Zisserman Citation2014)(VGG16架构的解释请参见第4.2节)。将VGG16预训练模型的最后一个全连接密集层替换为从ABIDE-I数据集中提取的图像并重新训练。我们使用softmax激活函数和ADAM优化器(Kingma and Ba Citation2014)以0.01的学习率对最后一个密集层进行图像训练。
从MRI扫描中提取的tif图像的80%用于训练,而20%的帧用于验证。使用上述参数,提出的迁移学习方法实现了66%的自闭症检测准确率。模型准确率和损失曲线如图10所示。与传统机器学习方法相比(使用不同传统机器学习方法获得的结果请参见表3),迁移学习方法在ASD检测方面提高了约10%。
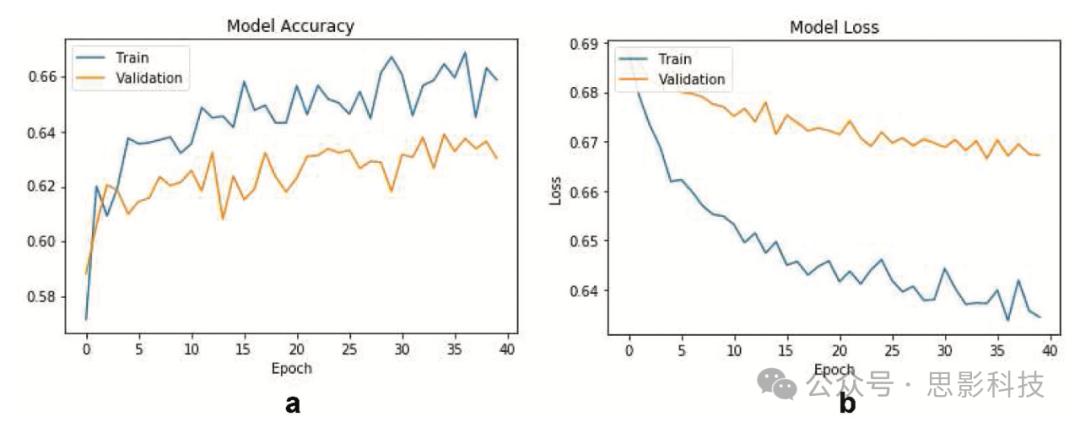
图10. 使用VGG16架构的迁移学习结果:(A)训练准确率与验证准确率和(B)训练损失与验证损失。
结论与未来工作
我们的研究表明,机器学习(传统和深度学习)算法在开发神经影像数据理解方面的潜力。我们展示了如何将机器学习算法应用于结构MRI数据,以自动检测患有自闭症谱系障碍(ASD)的个体。
虽然实现的识别率在55%-65%的范围内,但在缺乏生物标志物的情况下,这些算法仍然可以帮助临床医生早期检测ASD。其次,已知将机器学习与从多个站点(如ABIDE)收集的脑成像数据相结合以识别自闭症的研究表明,分类准确率往往会降低(Arbabshirani et al. Citation2017)。在这项研究中,我们也观察到了相同的趋势。
从这项研究中得出的主要结论如下:
- 应用于大脑解剖扫描的机器学习算法可以帮助自动检测ASD。从胼胝体和颅内脑区提取的特征呈现出显著的区分信息,可将面临ASD的个体与对照亚组区分开来。
- 特征选择/加权方法有助于构建用于自动检测ASD的稳健分类器。这些方法不仅在降低计算复杂性方面,而且在获得更好的平均分类准确率方面都有助于框架。
- 我们还通过迁移学习方法提供了使用卷积神经网络(CNN)进行自动ASD检测的结果。这将帮助读者了解使用深度学习/CNN方法分析神经影像数据的好处和瓶颈,这种数据很难以足够大的数量记录以用于深度学习。
- 为了提高提出的框架的识别结果,建议使用多模态系统。除了神经影像数据,其他模态(如EEG、语音或运动感觉)可以同时分析,以实现更好的ASD识别。
使用卷积神经网络(CNN)/深度学习获得的结果很有前景。充分利用CNN学习/数据建模能力的挑战之一是使用大型数据库来学习概念(LeCun, Bengio, and Hinton Citation2015; Zhou, Bin, and Zhenguo Citation2018),这使得在标记数据难以记录的应用中不切实际。对于获取数据(特别是神经影像数据)困难且深度学习算法的训练构成挑战的临床应用,解决此问题的一种方案是提出一种混合方法,将传统机器学习算法的数据建模能力(也可以在小数据上学习概念)与深度学习相结合。
为了缩小神经科学和计算机科学研究人员之间的差距,我们强调并鼓励科学界分享数据库和结果,以自动识别心理疾病。

















 1506
1506

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









