






http://developer.nvidia.com/sites/default/files/akamai/gamedev/files/gdc12/Efficient_Buffer_Management_McDonald.pptx
nvidia在gdc12上面的关于显卡上面buffer知识的介绍,针对dx11的比较多。
- 一般来说dx11要比dx9更加高效
- buffer的更新能batch就batch
- 16byte,alignment特别重要,性能可能相差30倍
- map/unmap要好于UpdateSubresource
- 尽量避免cpu-gpu sync points,这些行为会造成sync point
- 读你刚刚写入的framebuffer的信息
- cpu 循环等query结果
- gpu 显存在刚做了释放后,立刻又申请
- buffer在释放之后,又做改名字操作
- 更新正在使用的buffer
- dx9 使用flag=0来lock一个正在使用的buffer,会造成sync point
各种不同的buffer的update建议:

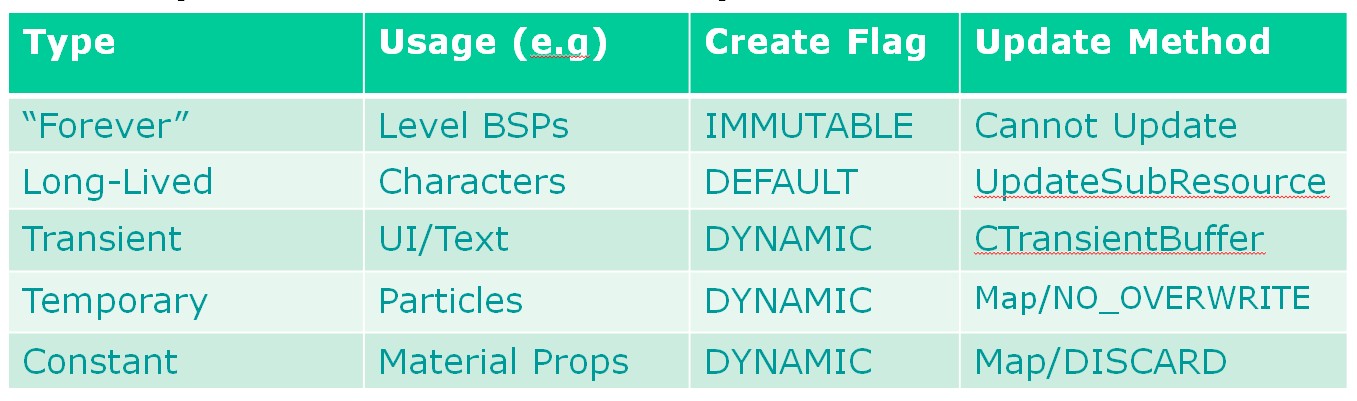
- forever:常驻的buffer,场景物件geometry类的,immutable flag,创建之后不再更新
- LongLived:会呆一会的buffer,用于streaming的这种,使用DEFAULT flag at creation time
- Temporary:particle类的,很快会被收掉的,DYNAMIC flag, Map/unmap来update
- Constants:constant buffer, DYNAMIC flag, Map/DISCARD to update
TemporaryBuffer
这里是需要额外注意一个pool的问题,cpu端release了之后,在gpu端实际是在使用结束了之后才release的。
所以需要使用一个query event,在确认使用结束了,然后再release会自己的pool里。
否则可能会出现,提前release了,马上又alloc出来,做内容填充,结果gpu还没释放,结果一个sync point,性能就悲剧了。
这种方式成为discard free temp buffer,效率最好
constant buffer
如果不是vertex shader bound,对于静态物体,可以使用把viewProjMatrix和worldMatrix分离的方式来尽可能减少constant buffer的update。
数据对比
- 115个vertex buffer update和一个大的vertexbuffer的map+115次memcpy,性能差4.1ms,绝对优势哦
- 如果discard free temp buffer : tripple buffer的map(MAP_NOOVERWRITE flag),可以再节省0.05ms,不过要付出额外两份memory















 1342
1342

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









