







目录
无线传感器网络(Wireless Sensor Networks, WSN)由大量低成本、低功耗的传感器节点组成,广泛应用于环境监测、智能医疗、工业物联网等领域。然而,WSN面临着节点能量有限、拓扑动态变化、信道资源稀缺等挑战,流量控制作为保障网络性能的核心技术,其有效性直接影响网络的吞吐量、延迟、能量效率和可靠性。传统流量控制算法(如TDMA、CSMA/CA)依赖固定规则或静态参数,难以适应复杂动态的网络环境。人工智能(Artificial Intelligence, AI)技术的发展为WSN流量控制提供了新的思路,通过引入人工智能代理(AI Agent),可实现对网络状态的智能感知、决策和优化,显著提升流量控制的自适应能力和全局性能。
1.基于人工智能代理的流量控制原理
1.1 核心架构
人工智能代理是一种具有感知、决策和行动能力的智能实体,其核心架构包括以下模块:
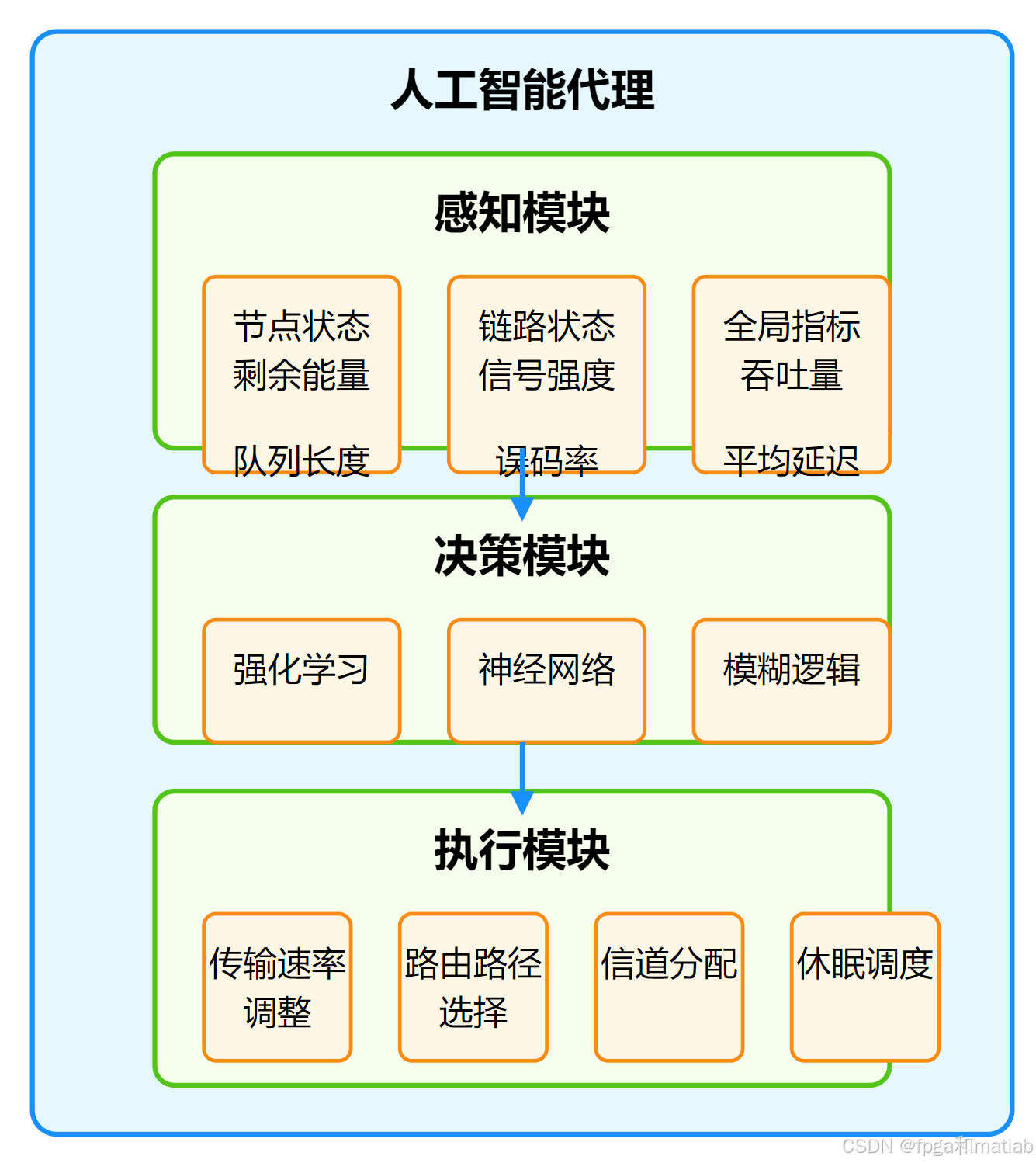
A.感知模块:实时采集网络状态信息,包括:
节点状态:剩余能量(Ei(t))、队列长度(Qi(t))、处理能力(Ci)
链路状态:信号强度(RSSIi,j)、误码率(BERi,j)、时延(Di,j)
网络全局指标:吞吐量(T)、平均延迟(Dˉ)、能量消耗(Etotal)
B.决策模块:基于感知数据生成控制动作,常见AI技术包括:
强化学习(Reinforcement Learning, RL):通过试错机制优化长期奖励
神经网络(Neural Network, NN):拟合复杂非线性映射关系
模糊逻辑(Fuzzy Logic):处理不确定性和不精确性问题
C.执行模块:将决策转化为具体的流量控制动作,例如:
传输速率调整(Ri∈{Rmin,Rmax})
路由路径选择(Paths,d={n1,n2,…,nk})
信道分配(Channeli∈{1,2,…,M})
休眠调度(Statusi∈{Active,Sleep})
1.2 基于强化学习代理的流量控制模型
马尔可夫决策过程(MDP)建模
将WSN流量控制问题抽象为离散时间MDP,定义五元组 (S,A,P,R,γ):

策略优化算法

2. 基于神经网络代理的流量预测与控制
2.1 流量预测模型
使用长短期记忆网络(LSTM)对节点流量进行时序预测:
输入层:历史流量数据xt=[qi(t−1),qi(t−2),…,qi(t−L)]
隐藏层:LSTM单元捕捉时间依赖关系,输出 ht=LSTM(ht−1,xt)
输出层:预测未来时刻队列长度q^i(t+1)=σ(Whht+bo),其中σ为激活函数,Wh,bo为网络参数。
2.2 闭环控制策略

3.基于Q-learning代理的流量控制算法实现
算法的伪代码如下:
初始化:
- 网络拓扑:N个节点,随机分布,构成无向图G(N, E)
- 智能体参数:Q表尺寸 |S|×|A|,α=0.1,γ=0.95,ε=0.1
- 环境参数:初始能量E_i=100J,队列容量Q_max=50 packets,传输速率R∈{10, 20, 30} kbps
for episode=1 to EPISODES:
初始化状态s:各节点E_i, Q_i,链路状态
for step=1 to MAX_STEPS:
根据ε-贪心策略选择动作a:
if random() < ε: 随机选择动作
else: 选择Q(s, a)最大的动作
执行动作a,观察新状态s'和奖励r
更新Q表:
Q(s, a) = Q(s, a) + α*(r + γ*max(Q(s', *)) - Q(s, a))
s = s'
if s为终止状态(如节点能量耗尽或队列溢出):
break
衰减ε:ε = max(ε_min, ε*decay_rate)主函数如下:
clc;
clear;
close all;
warning off;
rng('default');
% 参数设置
N = 5; % 节点数
R_set = [10,20, 30,40,50,60,70,80,90]; % 传输速率(kbps)
EPISODES = 5000;
MAX_STEPS = 500;
alpha = 0.05;
gamma = 0.95;
epsilon = 0.9;
epsilon_min = 0.1;
decay_rate = 0.995;
Q_max = 50; % 队列容量(packets)
E_init = 100; % 初始能量(J)
% 训练智能体
[Q, rewards] = q_learning_agent(N, R_set, EPISODES, MAX_STEPS, alpha, gamma, epsilon, epsilon_min, decay_rate);
% 绘制奖励曲线
figure;
plot(1:EPISODES, smooth(rewards,16));
xlabel('Episodes');
ylabel('Total Reward');
title('Q-learning Training Reward');
grid on;
% 测试阶段(任选一个状态)
% 初始状态:能量全满,队列为空
s_test = [ones(1, N)*E_init, zeros(1, N)];
state = [ceil(s_test(1:N)/10), ceil(s_test(N+1:end)/5)]; % 离散化
state_idx = 1;
for i=1:N
state_idx = state_idx + (state(1,i)-1) * (10^(i-1)) + (state(1,i)-1) * (10^(i-1))/100;
end
state_idx = floor(min(state_idx, size(Q,1)))+1;
[~, a_idx] = max(Q(state_idx, :));
optimal_action = R_set(a_idx);
fprintf('Optimal Action for Initial State: %d kbps\n', optimal_action);强化学习模块如下:
function [Q, rewards] = q_learning_agent(N, R_set, EPISODES, MAX_STEPS, alpha, gamma, epsilon, epsilon_min, decay_rate)
% N: 节点数
% R_set: 传输速率集合(动作空间)
% EPISODES: 训练轮数
% MAX_STEPS: 每轮最大步数
% alpha: 学习率
% gamma: 折扣因子
% epsilon: 探索率
% epsilon_min: 最小探索率
% decay_rate: 探索率衰减因子
Q_max = 50; % 队列容量(packets)
E_init = 100; % 初始能量(J)
% 状态空间:每个节点包含能量(离散化为10级)和队列长度(离散化为10级)
E_levels = 5; % 能量等级:0-100J分为10级
Q_levels = 5; % 队列等级:0-Q_max分为10级
state_dim = [E_levels, Q_levels]'; % 每个节点的状态维度
state_size = prod(state_dim)^N; % 总状态数(实际应用需降维或近似)
action_size = length(R_set); % 每个节点的动作数(速率选择)
% 初始化Q表:N个节点,每个节点独立决策(简化为集中式代理)
% 实际中需分布式实现,此处假设全局状态已知
Q = zeros(state_size, action_size); % 简化为一维状态索引
rewards = zeros(EPISODES, 1);
for episode=1:EPISODES
% 初始化状态:能量全满,队列为空
E = ones(1, N) * E_levels; % 能量等级初始为最高级
Q_len = zeros(1, N); % 队列等级初始为0
s = [E; Q_len]; % 状态向量
total_reward = 0;
for step=1:MAX_STEPS
% 将连续状态离散化为等级
e_levels = ceil(s(1,:) / (E_init / E_levels)); % E_init=100J,每级10J
q_levels = ceil(s(2,:) / (Q_max / Q_levels));
% 生成状态索引(简化为各节点状态的乘积,实际需唯一编码)
state_idx = 1;
for i=1:N
state_idx = state_idx + (e_levels(i)-1) * (Q_levels^(i-1)) + (q_levels(i)-1) * (Q_levels^(i-1))/E_levels;
end
state_idx = max(floor(min(state_idx, state_size)),1); % 防止越界
% ε-贪心策略选择动作
if rand < epsilon
a_idx = randi(action_size); % 随机动作
else
[~, a_idx] = max(Q(state_idx, :)); % 贪心选择
end
a = R_set(a_idx); % 动作值(传输速率)
% 执行动作,获取新状态和奖励
s_new = zeros(2, N);
s_new(1,:) = s(1,:) - 0.1*a; % 简化能量消耗模型
s_new(2,:) = max(s(2,:) + poissrnd(5, 1, N) - a/1000, 0); % 队列更新
s_new(2,:) = min(s_new(2,:), Q_max); % 队列容量限制
% 计算奖励(简化版本,与env函数一致)
throughput = a / 1000;
avg_queue = mean(s_new(2,:));
energy_consumption = 0.1*a;
r_throughput = throughput / max(R_set);
r_queue = 1 - avg_queue / Q_max;
r_energy = 1 - energy_consumption / (max(R_set)*0.1);
r = 0.4*r_throughput + 0.3*r_queue + 0.3*r_energy;
% 更新Q表
e_levels_new = ceil(s_new(1,:) / (E_init / E_levels));
q_levels_new = ceil(s_new(2,:) / (Q_max / Q_levels));
state_idx_new = 1;
for i=1:N
state_idx_new = state_idx_new + (e_levels_new(i)-1) * (Q_levels^(i-1)) + (q_levels_new(i)-1) * (Q_levels^(i-1))/E_levels;
end
state_idx_new = max(floor(min(state_idx_new, state_size)),1);
% 计算Q目标值
Q_target = r + gamma * max(Q(state_idx_new, :));
Q_delta = alpha * (Q_target - Q(state_idx, a_idx));
Q(state_idx, a_idx) = Q(state_idx, a_idx) + Q_delta;
total_reward = total_reward + r;
s = s_new;
% 检查终止条件
if any(s(2,:) >= Q_max) || any(s(1,:) <= 0)
break;
end
end
rewards(episode) = total_reward;
% 衰减探索率
epsilon = max(epsilon_min, epsilon * decay_rate);
if mod(episode, 100) == 0
fprintf('Episode %d, Reward: %.2f, Epsilon: %.3f\n', episode, total_reward, epsilon);
end
endWSN模块如下:
function [s_new, r] = wsn_env(s, a, N, Q_max, E_init, R_set)
% s: 当前状态 [E1, Q1, E2, Q2, ..., EN, QN]
% a: 动作向量 [R1, R2, ..., RN],Ri∈R_set
% N: 节点数
% Q_max: 队列容量
% E_init: 初始能量
% R_set: 传输速率集合
% 模拟流量到达(泊松过程)
lambda = 5; % 平均到达速率(packets/s)
arrival = poissrnd(lambda, 1, N); % 各节点到达数据包数
% 计算能量消耗
E_trans = zeros(1, N);
for i=1:N
if a(i) > 0 % 假设非零速率表示传输
% 简化能耗模型:传输能耗与速率成正比
E_trans(i) = 0.1 * a(i); % 单位:J/s
end
end
s_new(1:2:N) = s(1:2:N) - E_trans; % 更新能量
% 队列动态更新
for i=1:N
idx = 2*i;
q_current = s(idx);
q_out = a(i) / 1000; % 传输速率转换为packets/s(假设每个packet=1000 bits)
q_new = max(q_current + arrival(i) - q_out, 0);
s_new(idx) = min(q_new, Q_max); % 避免队列溢出
end
% 处理能量耗尽节点(能量≤0时设为0,队列清零)
for i=1:N
if s_new(2*i-1) <= 0
s_new(2*i-1) = 0;
s_new(2*i) = 0;
end
end
% 计算奖励
throughput = sum(a) / 1000; % kbps转Mbps
avg_queue = mean(s_new(2:2:end));
energy_consumption = sum(E_trans);
% 多目标奖励函数
r_throughput = throughput / max(R_set); % 归一化到[0,1]
r_queue = 1 - avg_queue / Q_max; % 队列越空奖励越高
r_energy = 1 - energy_consumption / (N * max(R_set) * 0.1); % 能耗越低奖励越高
r = 0.4*r_throughput + 0.3*r_queue + 0.3*r_energy;
% 终止条件:任意节点队列溢出或能量耗尽
if any(s_new(2:2:end) >= Q_max) || any(s_new(1:2:end) <= 0)
r = -1; % 惩罚性奖励
end上述程序训练过程如下:
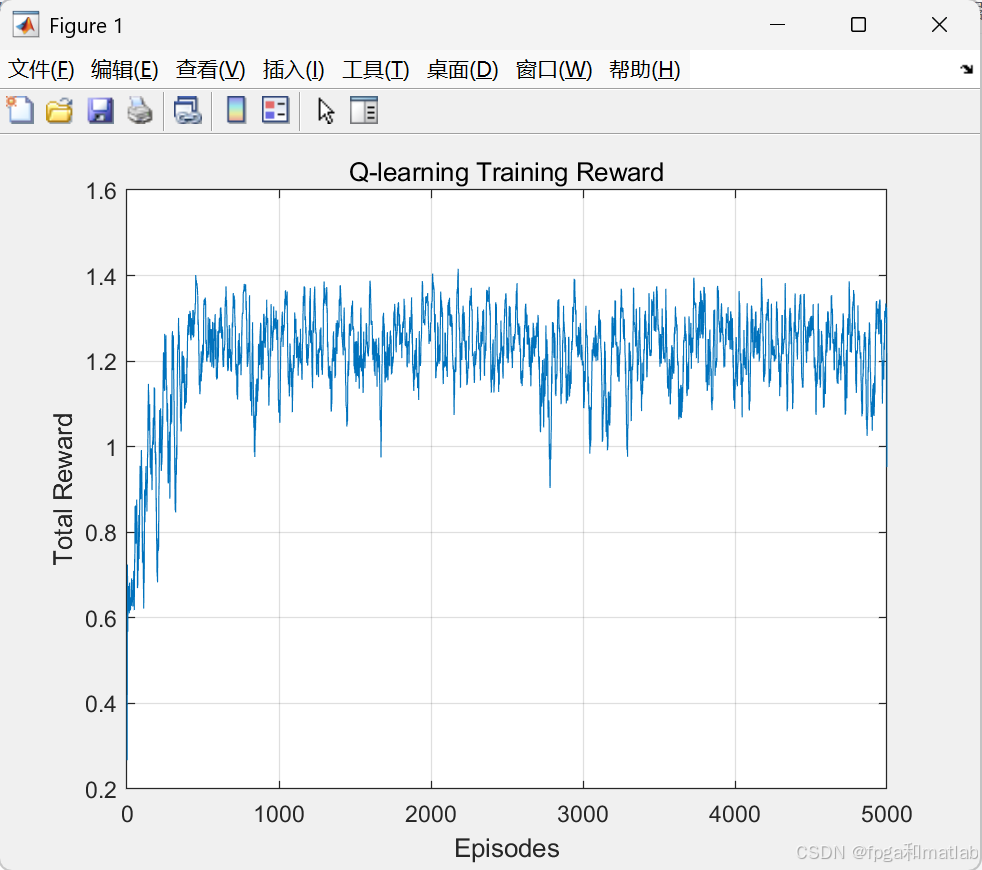
优化后的流量控制值为:

基于人工智能代理的WSN流量控制算法通过智能体对网络状态的动态感知和决策,显著提升了传统流量控制的自适应能力和多目标优化性能。强化学习和神经网络等技术的引入,为解决 WSN 的动态性、不确定性和资源约束问题提供了有效途径。未来研究需进一步探索分布式智能体协作、边缘计算与AI的结合,以及硬件 - 算法协同优化,推动该类算法在实际场景中的大规模应用。
欢迎订阅FPGA/MATLAB/Simulink系列教程



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











