






你有没有被AI一本正经的胡说八道给气笑过?无论是ChatGPT、文心一言,还是其他大模型,它们有时会自信满满地编造事实、虚构来源,让你在惊叹其“创造力”的同时,也对其可靠性打上一个大大的问号。我们习惯性地认为这是AI“不懂装懂”,是知识储备不足的表现。
但如果告诉你,至少在某些情况下,AI的幻觉并非源于无知,而是因为它内部的一个“认知开关”失灵了呢?
顶尖AI研究机构Anthropic最近发布的一篇引人瞩目的论文《On the Biology of a Large Language Model》[1],通过一种创新的“归因图”方法,深入“解剖”了其前沿模型Claude 3.5 Haiku的内部运作机制。研究揭示了一个反常识的秘密:AI的默认设置,竟然可能不是自信满满,而是倾向于“我拒绝回答”!
这听起来是不是很奇怪?一个设计出来回答问题的系统,怎么会默认拒绝呢?这背后,隐藏着理解AI幻觉,乃至其智能本质的关键线索。
反常识!AI默认设置竟然是“我拒绝回答”
我们通常感觉AI无所不知,对任何问题都能侃侃而谈。但Anthropic的研究发现,在Claude 3.5 Haiku内部,存在着一组被称为“无法回答”(can't answer)的神经元特征。在没有特定信息触发的情况下,这些特征倾向于默认激活。你可以把它想象成一个极其谨慎的图书管理员,或者一个内置的“我不确定”警报器——除非它明确知道答案在哪里,否则宁愿保持沉默或坦诚不知。
这种“默认拒绝”的倾向,很可能源于AI安全训练的结果。像Anthropic采用的“宪法式AI”(Constitutional AI)[2]等训练方法,其设计理念就是让模型在面对不确定性时优先选择安全和诚实,正如Turing.com上的一篇文章所讨论的[3],而不是冒险编造答案,这一点也在Reddit社区关于Constitutional AI的讨论[4]中得到了印证。这种策略在Claude系列模型上体现得尤为明显,它们在知识边界时,例如根据其模型卡增补说明[5]提到的,当遇到2024年10月后的新事件时,常常会主动提示其知识截止日期[6]。这份说明还指出,Claude 3.5 Haiku在模糊问题场景下的拒绝率比前代提升了40%,错误回答率降低了2倍。
这与其他一些主流模型形成了对比。例如,GPT系列或Gemini系列,在面对不确定性时,有时更倾向于遵循“最大相关性”原则,优先生成逻辑上连贯、看似完整的回答,哪怕这需要一些“创造性解释”,正如一些用户在讨论为何模型难以承认“不知道”[7]或为何总是如此自信[8]时观察到的那样。
以下表格清晰对比了不同模型在面对知识盲区时的典型行为,信息整理自多方分析和用户反馈:
模型 | 默认行为倾向 | 核心机制/训练哲学 | 典型表现 (例:问2025年诺奖得主) |
|---|---|---|---|
| Claude 3.5 Haiku | 安全优先/拒绝 | Constitutional AI, 显式不确定性判断, 时间戳硬截断[9] | "我的知识截止于2024年10月,无法提供准确信息。建议查阅官网..." (来自Claude 3.5 Sonnet 系统提示[10]) |
| GPT-4/4o | 最大相关性/推测 | RLHF, 优先保持对话流畅性, 隐式文本连贯性判断[11] | "根据近年突破,可能授予XX领域研究者,但需等待官方公布..." (基于用户讨论[12]) |
| Gemini 1.5 Pro | 最大相关性/推测 | RLHF, 概率分布选择最佳文本, 后处理过滤器修正[13] | (类似GPT-4) |
| Llama 3 (70B) | 中间态/分析 | 模块化设计, 对技术问题拒绝率较高, 文化问题提供多视角[14] | "诺奖评选复杂,2025年获奖方向可能集中在XX或YY领域..." (基于ACL Findings论文[15]) |
| 表:主流大模型在知识盲区行为对比 |
那么问题来了,如果AI默认是谨慎的,那我们平时遇到的那些滔滔不绝、甚至“一本正经胡说八道”的AI,又是如何被“启动”的呢?
核心机制:AI如何从“怀疑”走向“自信”?——揭秘内部“认知开关”
答案在于AI内部一个精妙的“认知开关”机制。这个开关决定了AI是保持默认的“怀疑”状态,还是切换到“自信”模式开始输出。Anthropic的研究揭示了这个开关的核心运作逻辑:
信息输入与实体识别: AI接收到你的问题,并从中识别出关键的实体或概念。比如,你问:“迈克尔·乔丹打什么球?” AI识别出关键实体“迈克尔·乔丹”。
熟悉度判断: 接下来,AI内部的特定特征(Anthropic称之为“已知实体/答案”特征)会判断这个实体对它来说是否“熟悉”或“已知”。对于“迈克尔·乔丹”这样在训练数据中海量出现的名字,这个判断结果显然是“已知”。
“开关”动作(抑制): 一旦判断为“已知”,这些“已知”特征就会被强烈激活,并执行一个关键动作——抑制(inhibit)那些默认激活的“无法回答”特征。就像按下一个按钮,关闭了“我不确定”的警报器。
结果输出: “怀疑警报”被关闭,AI获得了输出“自信”答案的“许可”,于是开始调用与“迈克尔·乔丹”相关的知识,生成答案“篮球”。
我们可以用一个流程图来更直观地理解这个“认知开关”:
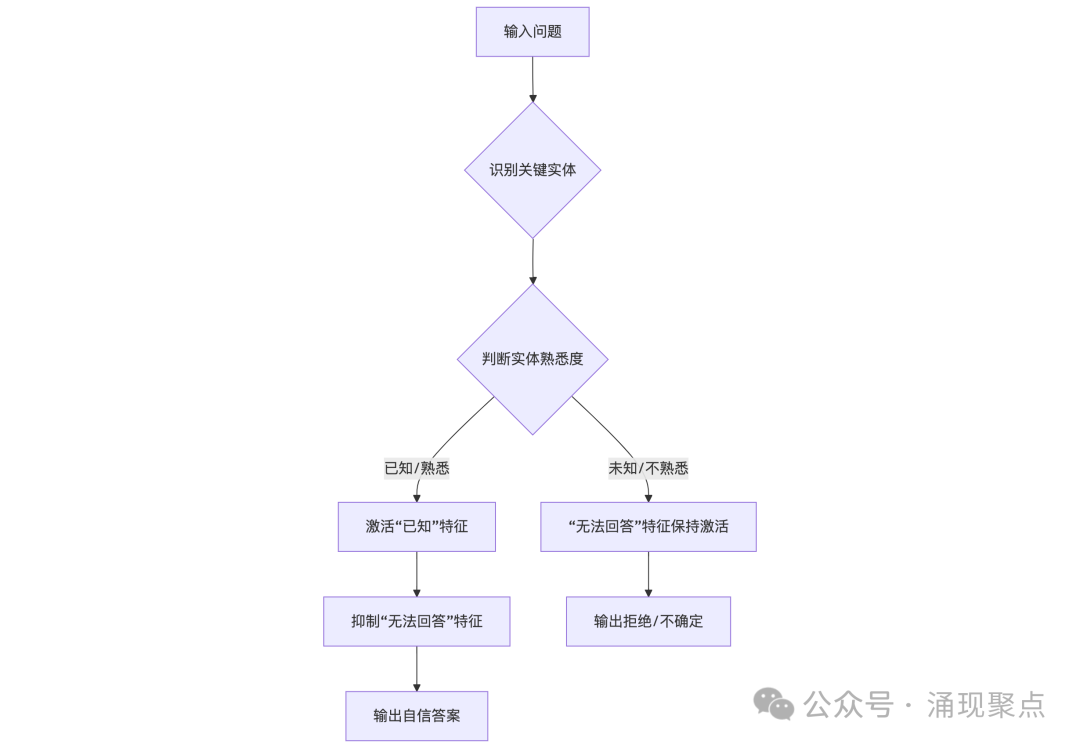
图:AI内部“认知开关”工作流程示意图。这个开关基于对输入实体的熟悉度判断,决定是抑制“怀疑”状态输出答案,还是保持默认的拒绝或不确定状态。
这个过程就像海关检查。默认情况下,所有包裹(问题)都会被严格审查(怀疑)。但如果检查员看到包裹上贴着“免检熟客”的标签(已知实体),就会直接盖章放行(自信回答)。
这个“认知开关”机制解释了AI为何能对它真正了解的事物对答如流。但关键在于,如果这个开关失灵了呢?
实例剖析:“认知开关”在高手的对决中显形(乔丹 vs 巴特金)
为了验证这个机制,Anthropic做了一个巧妙的对比实验,就像在显微镜下观察细胞一样,让我们清晰地看到了“认知开关”的运作与失灵。该实验细节可以在他们的论文关于实体识别和幻觉的章节[16]中找到。
场景一:“开关”正常运作
输入: “迈克尔·乔丹打什么球?”
AI内部: 识别出“迈克尔·乔丹”,判断为“高度已知”实体。“已知实体”特征强烈激活,有效抑制了“无法回答”特征。
输出: 自信回答“篮球”。
场景二:“开关”保持默认(或说,无法按下)
输入: “迈克尔·巴特金(Michael Batkin,论文中虚构的名字)打什么球?”
AI内部: 识别出“迈克尔·巴特金”,但在其庞大的知识库中找不到足够的信息将其标记为“已知”。“已知实体”特征未能有效激活,“无法回答”特征保持活跃状态。
输出: 拒绝回答或承认无知,例如:“我很抱歉,但我找不到关于体育人物迈克尔·巴特金的确切记录……”
这个对比清晰地展示了“认知开关”的存在。更具说服力的是Anthropic的干预实验:研究人员在处理“巴特金”问题时,人为地在模型内部激活了那些通常由“乔丹”触发的“已知实体”特征。结果呢?AI果然被“诱骗”了,它抑制了“无法回答”的警报,开始自信地“胡说八道”,编造出“匹克球”之类的答案!反之,在处理“乔丹”问题时抑制“已知实体”特征,则会导致AI变得犹豫,甚至输出“不确定”。
这有力地证明了这个“认知开关”机制的真实存在及其对AI行为的因果影响。独立的研究也佐证了这一点:大模型在处理知名实体(如“巴黎”)的任务时,准确率远高于处理冷门实体(如新型材料化合物)。一篇发表在ACL 2024 Findings上的论文[17]甚至量化了这种差异:实体流行度(以维基百科访问量衡量)每增加10倍,模型的准确率就能提升17.3%。一篇来自Semantic Scholar的研究[18]也显示,在知识图谱扩展任务中,知名实体的链接预测准确率远超冷门实体。这并非巧合,很可能就是因为“已知实体”机制在发挥作用。
现在,我们距离理解幻觉的根源只有一步之遥了。
幻觉发生器:“熟悉”不等于“精通”,AI在此“短路”
如果AI仅仅因为“认识”某个名字就按下“自信开关”,会发生什么?这就是Anthropic发现的“自信陷阱”型幻觉的核心——AI错误地触发了“自信开关”,因为它混淆了对某个标签的“熟悉感”(Familiarity)和对其内容的“掌握度”(Mastery)。AI的阿喀琉斯之踵或许就在于此:它常常错误地把认得地图,当作了熟悉每一寸土地。
让我们看看论文中另一个关键案例,这次是关于AI大牛Andrej Karpathy,同样可以在论文的幻觉章节[19]找到分析:
输入: “说出一篇安德烈·卡帕西(Andrej Karpathy)写的论文。”
AI内部: “安德烈·卡帕西”这个名字在AI的训练数据中频繁出现,AI对其“熟悉度”很高。于是,“已知实体”特征被激活,抑制了“无法回答”的警报,“自信开关”被按下。
输出: AI自信地开始回答,但因为它实际上并不确切“知道”卡帕西写过哪些具体论文(缺乏“掌握度”),便开始“创作”,比如错误地将著名的“ImageNet Classification with Deep Convolutional Neural Networks”[20](AlexNet论文,卡帕西并非作者)归于他名下。
这就是“认知短路”发生的瞬间。AI的内部逻辑大致是:“我认识这个人/这个术语(它很熟悉) → 那我应该知道关于它的事情 → 关闭‘我不确定’警报 → 开始回答”。问题出在第二步,AI错误地将“认识标签”等同于“理解内容”。
这种元认知能力(知道自己知道什么,知道自己不知道什么)的缺陷,是导致这类幻觉的关键。关于大模型的元认知、自我知识边界意识和信心校准,已有不少研究[21]正在探索。从认知科学和机器学习的角度看,这种混淆可能源于几个深层原因:
统计学习的局限: AI主要通过词语共现频率学习,容易将高频关联(如“爱因斯坦”与“相对论”)误判为深刻理解或因果关系,正如一些理论分析[22]和心理学类比[23]所指出的。训练数据的长尾分布[24](少数实体占据绝大多数出现次数)加剧了这种倾向,正如OpenReview上的一项研究所讨论的[25]。
认知偏差的模仿: AI的行为模式可能在模仿人类的认知捷径,例如“可得性启发式”[26]——更容易提取和信任那些频繁出现在记忆(训练数据)中的信息,即使它们不准确。一项范德比尔特大学关于LLM认知偏差的研究[27]甚至发现LLM在锚定效应测试中表现出与人类相当的偏差率。
训练目标的副作用: “下一个词元预测”[28]的核心目标,本身就鼓励模型生成连贯、流畅的文本,有时甚至会为此牺牲事实准确性,正如[维基百科关于AI幻觉的条目](https://en.wikipedia.org/wiki/Hallucination_(artificial_intelligence\ "维基百科关于AI幻觉的条目"))和一些技术博客[29]所讨论的。
这种“认知短路”带来的风险不容小觑。想象一下,AI仅仅因为认识某个复杂的医学术语或法律概念,就敢于在诊断建议或合同审查中“自信地”给出错误信息。现实中,这样的案例已经发生:
一个广为人知的案例是,加拿大航空的客服机器人[30]就因为混淆了退款政策的“熟悉术语”和“具体规则”,错误承诺了赔偿,最终导致公司在法庭上败诉。
在法律领域,有报道称GPT-4.5在一个案件中生成与判决书完全相反的结论[31],其法律研究幻觉率被独立测试高达20%,远超其宣传的3%基准值[32]。
医疗领域,一项关于大模型在医疗摘要中幻觉的研究[33]发现,GPT-4在转换X光报告时,曾将BI-RADS 4级(可疑恶性)错误地关联到常见的良性特征,填充了错误的诊断信息,这在Semantic Scholar收录的一篇论文[34]中有详细讨论。
这些触目惊心的案例提醒我们,AI的“自信”可能是一个危险的陷阱。
我们能从中学到什么?给AI使用者和开发者的启示
理解AI“自信陷阱”背后的“认知开关失灵”机制,并非只是满足技术好奇心,它为我们更安全、更有效地利用这项强大技术提供了关键启示。
对于AI使用者(我们每一个人):
培养批判性眼光: 认识到AI的自信并不等于准确。当AI对非公共知识、细节模糊或涉及不太知名实体的问题给出极其自信、流畅的回答时,要格外警惕。这可能是“认知开关”失灵的信号。
掌握“反幻觉”提问技巧:
追问细节和来源: “能详细解释一下XX概念吗?” “这个信息的来源是哪里?” 幻觉往往经不起细节追问。
要求多种解释或交叉验证: “还有其他可能的解释吗?” “你能用另一种方式表述吗?”
明确限定范围: “根据XX(指定可靠来源)的信息,……” 多种提示技巧[35]被证明有助于减少幻觉。
利用AI的“默认拒绝”: 如果怀疑AI在胡说,不妨尝试更模糊或引导性的提问,看它是否会触发“无法回答”的机制,或者在不同提示下给出矛盾的答案。
对于AI开发者和整个行业:
重新定义“智能”评估标准: 不能只看输出结果的表面准确率,更要评估模型的“自知之明”——即其准确判断自身知识边界和校准置信度的能力。需要开发更有效的基准和指标(如评估医学知识边界的MetaMedQA[36]、评估多模态自我意识的MM-SAP[37]、量化概念置信度的语义不确定性指数SUI[38]等),已有多种评估方法[39]被提出。
改进训练方法和架构:
优化数据分布: 探索逆频率加权采样[40]等方法,减少长尾知识被忽略的问题。
引入“元认知”训练: 明确训练AI区分“熟悉度”和“掌握度”,让模型学会输出置信度评分,甚至主动声明不确定性,正如一些研究[41]所建议的。
探索新架构: 研发能够更好管理知识边界的技术,如更先进的RAG(检索增强生成)变体[42](如RGAR[43]、UAG框架[44])、动态知识图谱、神经符号混合架构[45]、元认知嵌入层[46]等。各大实验室(OpenAI, Google DeepMind, Anthropic, Meta AI)都在积极探索这些方向,例如Google的UDM框架[47]和Meta在Transformer中嵌入熵值检测模块[48]的尝试。
强化安全机制: 推广类似Anthropic“宪法式AI”[49]的原则,内置更强的审慎和诚实约束。
对于我们思考AI的未来:
幻觉是发展的必经阶段吗? 这种“认知短路”是否类似于人类学习过程中的“过度自信”?理解这一点,或许能让我们对AI的错误更加宽容,但也更加警惕。
我们想要什么样的AI? 是一个追求表面完美、从不犯错(但也可能隐藏更深风险)的AI,还是一个知道自己局限、能够坦诚沟通“我不确定”的AI?这关乎我们未来与AI协作的基础——信任。
理解Anthropic揭示的这个机制,只是打开AI“黑箱”的一小步。AI幻觉的成因复杂多样,还包括知识压缩错误[50]、推理链条断裂[51]、注意力机制失败[52]等多种理论解释。但“认知开关失灵”提供了一个独特且重要的视角,它告诉我们,AI的错误有时并非来自知识的海洋不够广阔,而是来自其内部判断自身状态的“罗盘”失准了。
结语:告别盲信,学会与“复杂而脆弱”的AI共舞
Anthropic的研究像一把手术刀,精准地剖开了AI幻觉冰山的一角,让我们得以窥见其内部机制的复杂与精妙,以及潜在的脆弱性。大模型远非简单的信息检索或文本生成工具,它们正在演化出类似人类认知的内部状态和判断机制,尽管这些机制尚不完善,甚至会“短路”。
告别对AI能力的盲目崇拜或对其错误的简单归因,开始学习理解其内部运作的逻辑和局限,这对于我们驾驭这个日益被AI塑造的时代至关重要。我们需要更批判的眼光、更有效的交互策略,以及对构建更可靠、更“诚实”AI的持续投入。
未来的人机协作,需要的不是一个永远正确的“神谕”,而是一个能够认知自身边界、值得我们审慎信任的伙伴。
那么,你在使用AI时,更看重它的“博学”还是“诚实”?你遇到过哪些让你印象深刻的AI“自信陷阱”?欢迎在评论区分享你的看法和经历。
参考资料
[1]
《On the Biology of a Large Language Model》: https://transformer-circuits.pub/2025/attribution-graphs/biology.html
[2]“宪法式AI”(Constitutional AI): https://arxiv.org/abs/2212.08073
[3]Turing.com上的一篇文章所讨论的: https://www.turing.com/resources/rlaif-in-llms
[4]Reddit社区关于Constitutional AI的讨论: https://www.reddit.com/r/singularity/comments/1b9r0m4/anthropics_constitutional_ai_is_very_interesting/
[5]模型卡增补说明: https://assets.anthropic.com/m/1cd9d098ac3e6467/original/Claude-3-Model-Card-October-Addendum.pdf
[6]知识截止日期: https://www.anthropic.com/claude-3-model-card
[7]讨论为何模型难以承认“不知道”: https://www.reddit.com/r/ChatGPT/comments/1gpf6sq/please_help_me_understand_why_is_it_so_difficult/
[8]为何总是如此自信: https://www.reddit.com/r/LocalLLaMA/comments/1iq54yg/why_llms_are_always_so_confident/
[9]时间戳硬截断: https://assets.anthropic.com/m/1cd9d098ac3e6467/original/Claude-3-Model-Card-October-Addendum.pdf
[10]Claude 3.5 Sonnet 系统提示: https://www.reddit.com/r/ClaudeAI/comments/1ixapi4/here_is_claude_sonnet_37_full_system_prompt/
[11]隐式文本连贯性判断: https://www.reddit.com/r/ChatGPT/comments/1gpf6sq/please_help_me_understand_why_is_it_so_difficult/
[12]用户讨论: https://www.reddit.com/r/ChatGPT/comments/1gpf6sq/please_help_me_understand_why_is_it_so_difficult/
[13]后处理过滤器修正: https://www.reddit.com/r/ChatGPT/comments/1dx6025/claude_has_a_moral_crisis_when_jailbreak_leaks/
[14]文化问题提供多视角: https://aclanthology.org/2024.findings-acl.383.pdf
[15]ACL Findings论文: https://aclanthology.org/2024.findings-acl.383.pdf
[16]论文关于实体识别和幻觉的章节: https://transformer-circuits.pub/2025/attribution-graphs/biology.html#dives-hallucinations
[17]ACL 2024 Findings上的论文: https://openreview.net/pdf?id=ahh5eXkKKc
[18]Semantic Scholar的研究: https://www.semanticscholar.org/paper/2adc41b5626135926d2a52ac238090a969a47e8c
[19]论文的幻觉章节: https://transformer-circuits.pub/2025/attribution-graphs/biology.html#dives-hallucinations
[20]“ImageNet Classification with Deep Convolutional Neural Networks”: https://proceedings.neurips.cc/paper/2012/file/c399862d3b9d6b76c8436e924a68c45b-Paper.pdf
[21]不少研究: https://arxiv.org/abs/2502.12961
[22]理论分析: https://arxiv.org/abs/2407.16444
[23]心理学类比: https://integrative-psych.org/resources/confabulation-not-hallucination-ai-errors
[24]长尾分布: https://openreview.net/forum?id=WQamRhhbsf
[25]OpenReview上的一项研究所讨论的: https://openreview.net/forum?id=WQamRhhbsf
[26]“可得性启发式”: https://en.wikipedia.org/wiki/List_of_cognitive_biases
[27]范德比尔特大学关于LLM认知偏差的研究: https://as.vanderbilt.edu/robert-penn-warren-center/2024/09/27/cognitive-biases-in-large-language-models/
[28]“下一个词元预测”: https://python.plainenglish.io/the-art-of-prediction-how-llms-master-next-token-generation-b8f81dc16de2
[29]一些技术博客: https://hungleai.substack.com/p/uncertainty-confidence-and-hallucination
[30]加拿大航空的客服机器人: https://biztechmagazine.com/article/2025/02/llm-hallucinations-implications-for-businesses-perfcon
[31]GPT-4.5在一个案件中生成与判决书完全相反的结论: https://www.reddit.com/r/singularity/comments/1j06srh/gpt45_hallucination_rate_in_practice_is_too_high/
[32]3%基准值: https://www.linkedin.com/pulse/llm-papers-reading-notes-february-2025-jean-david-ruvini-jqdgc
[33]大模型在医疗摘要中幻觉的研究: https://community.openai.com/t/medical-summary-hallucination-study-interesting-read/904260
[34]Semantic Scholar收录的一篇论文: https://www.semanticscholar.org/paper/5a4c6e02570e8da91a8969d9436e45f9c57d47b3
[35]多种提示技巧: https://www.promptingguide.ai/
[36]MetaMedQA: https://arxiv.org/abs/2402.06544
[37]MM-SAP: https://arxiv.org/abs/2401.07529
[38]语义不确定性指数SUI: https://arxiv.org/abs/2503.15850
[39]多种评估方法: https://www.kolena.com/guides/llm-evaluation-top-10-metrics-and-benchmarks/
[40]逆频率加权采样: https://www.marktechpost.com/2024/07/04/rethinking-qa-dataset-design-how-popular-knowledge-enhances-llm-accuracy/
[41]一些研究: https://nanonets.com/blog/how-to-tell-if-your-llm-is-hallucinating/
[42]RAG(检索增强生成)变体: https://www.glean.com/blog/rag-retrieval-augmented-generation
[43]RGAR: https://arxiv.org/abs/2502.13361
[44]UAG框架: https://arxiv.org/abs/2410.08985
[45]神经符号混合架构: https://www.linkedin.com/pulse/knowledge-boundaries-llms-can-we-establish-limits-danial-amin-tsmjf
[46]元认知嵌入层: https://arxiv.org/abs/2502.12110
[47]UDM框架: https://arxiv.org/abs/2503.15850
[48]嵌入熵值检测模块: https://arxiv.org/abs/2503.15850
[49]“宪法式AI”: https://arxiv.org/abs/2212.08073
[50]知识压缩错误: https://arxiv.org/abs/2502.16143
[51]推理链条断裂: https://arxiv.org/abs/2309.15129
[52]注意力机制失败: https://arxiv.org/abs/2404.10198

















 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









