






来源:CreateAMind
https://direct.mit.edu/books/oa-monograph/5299/Active-InferenceThe-Free-Energy-Principle-in-Mind
10章: Active Inference as a Unified Theory of Sentient Behavior
In general we are least aware of what our minds do best.
—Marvin Minsky
本章是主动推理的深入总结及对大量不同理论进行了深入比较。(2万字)
10.1 简介
10.2 各章总结
10.3 连接点:主动推理的综合视角
10.4 预测大脑、预测心智和预测处理(次优)
10.4.1 预测处理
10.5 感知
10.5.1 贝叶斯大脑假设(次优)
10.6 动作控制
10.6.1 意念运动理论
10.6.3 最优控制理论
10.7 效用和决策
10.7.1 贝叶斯决策理论(次优)
10.7.2 强化学习(次优)
10.7.3 Planning as Inference
10.8 行为和有限理性
10.8.1 有限理性自由能理论
10.9 Valence, Emotion, and Motivation
10.10 稳态 动态平衡和内感受处理 Homeostasis, Allostasis, and Interoceptive Processing
10.11 注意力、显着性和认知动态 Attention, Salience, and Epistemic Dynamics
10.12 规则学习、因果推理和快速泛化 Rule Learning, Causal Inference, and Fast Generalization
10.13 主动推理和其他领域:开放方向
10.13.1 社会和文化动态
10.13.2 机器学习和机器人技术
10.14 总结
10.1 简介
在本章中,我们总结了主动推理的主要理论要点(来自本书的第一部分)及其实际实现(来自第二部分)。然后,我们将这些点联系起来:我们从前面章节中讨论的特定主动推理模型中抽象出来,专注于框架的集成方面。主动推理的好处之一是它为有感知力的生物体必须解决的适应性问题提供了完整的解决方案。因此,它为感知、行动选择、注意力和情绪调节等问题提供了统一的视角,这些问题通常在心理学和神经科学中被单独处理,并在人工智能中使用不同的计算方法来解决。我们将在控制论、行动思想运动理论、强化学习和最优控制等既定理论的背景下讨论这些问题(以及更多问题)。最后,我们简要讨论如何将主动推理的范围扩展到涵盖本书未深入讨论的其他生物、社会和技术主题。
10.2 总结
本书系统地介绍了主动推理的理论基础和实际实现。在这里,我们简单总结一下前九章的讨论。这提供了一个机会演练主动推理的关键结构,这将在本章的其余部分中发挥作用。
在第1章中,我们介绍了主动推理作为理解有感知力的生物的规范方法,这些生物其环境构成了的动作感知循环的一部分(Fuster 2004)。我们解释说,规范性方法从第一原理开始,得出并测试有关感兴趣现象的经验预测 在这里,生物体在与生物体进行适应性(行动‑感知的环境互动循环)时持续存在在他们的环境。
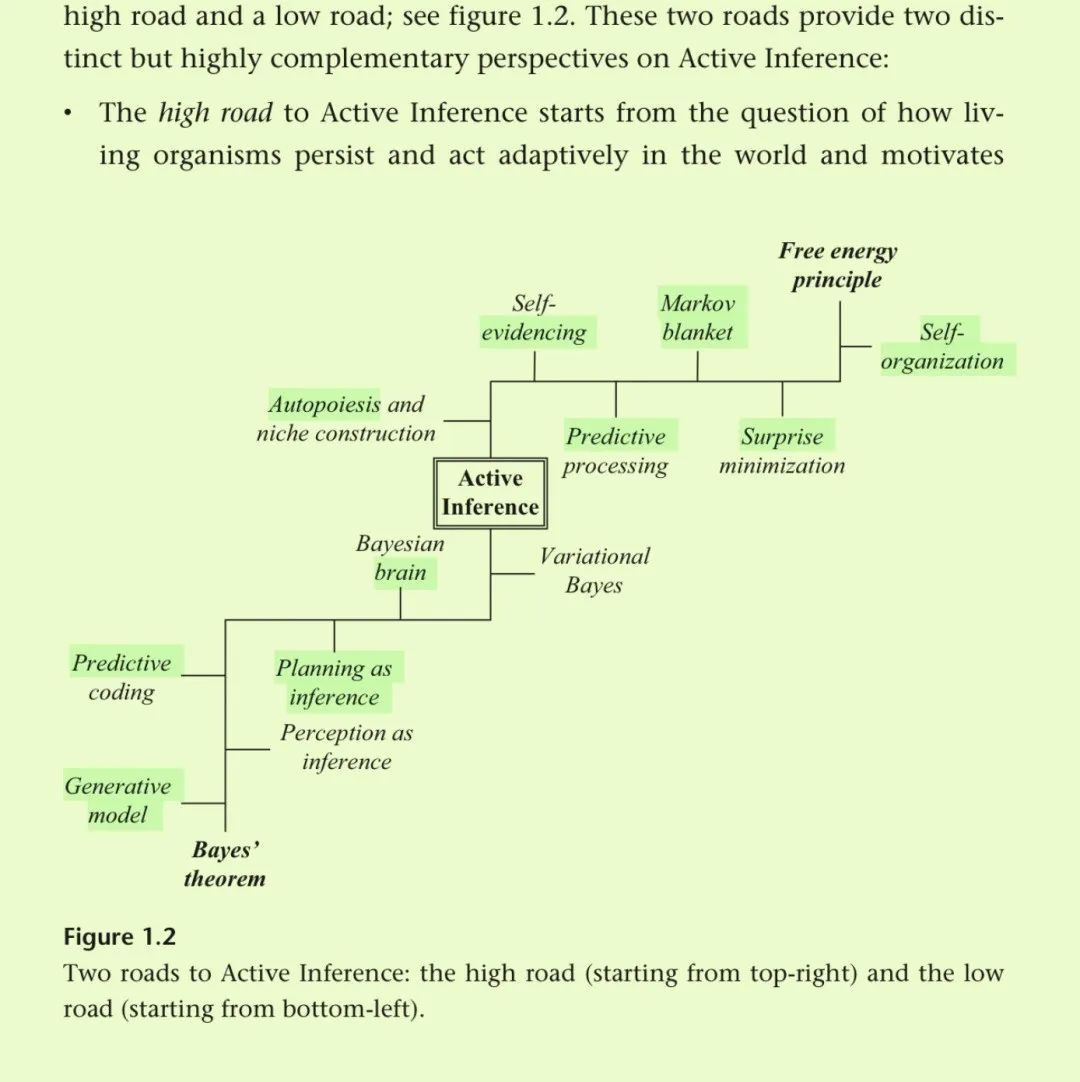
在第2章中,我们阐述了主动推理的低级之路。这条道路始于这样的想法:大脑是一台预测机器,具有生成模型:世界上隐藏的原因如何产生感觉的概率表示(例如,从苹果反射的光如何刺激视网膜)。通过反转这个模型,它可以推断出其感觉的原因(例如,考虑到我的视网膜以某种方式受到刺激,我是否看到了一个苹果)。这种感知观点(又名感知即推理)的历史根源在于亥姆霍兹的无意识推理概念,以及最近的贝叶斯大脑假说。主动推理通过将动作控制和规划纳入推理范围内(也称为控制即推理、规划即推理)扩展了这一观点。最重要的是,它表明感知和行动并不是典型的可分离过程,而是实现相同的目标。我们首先更非正式地描述这个目标,作为模型与世界之间差异的最小化(通常减少到意外或预测误差最小化)。简而言之,人们可以通过两种方式最小化模型与世界之间的差异:改变自己的想法以适应世界(感知)或改变世界以适应模型(行动)。这些可以用贝叶斯推理来描述。然而,精确推理通常很棘手,因此主动推理使用(变分)近似(请注意,精确推理可能被视为近似推理的特殊情况)。这导致了对感知和行动的共同目标的第二个更正式的描述,即变分自由能最小化。这是主动推理中使用的核心量,并且可以根据其组成部分(例如,能量和熵、复杂性和准确性、或意外和发散)进行分解。最后,我们引入了第二种自由能:预期自由能。这在规划时尤其重要,因为它提供了一种通过考虑替代政策预期产生的未来结果来对替代政策进行评分的方法。这也可以根据其组成部分(例如,信息增益和实用价值、预期的模糊性和风险)来分解。
在第 3 章中,我们阐述了主动推理的大道。这条替代道路始于生物有机体保持完整性和避免消散的的必要性,这可以被描述为避免令人惊奇的状态。然后我们引入了马尔可夫毯子的概念:有机体内部状态和世界外部状态之间统计分离的形式化。至关重要的是,内部和外部状态只能通过中间(主动和感觉)变量(称为毯子状态)相互影响。这种统计上的分离由马尔可夫毯介导的 对于赋予有机体一定程度的独立于外部世界的自主权至关重要。要理解为什么这是一个有用的观点,请考虑以下三个后果。
首先,具有马尔可夫毯的有机体似乎在贝叶斯意义上模拟外部环境:其内部状态平均对应于关于世界外部状态的近似后验信念approximate posterior belief。其次,自主性是由以下事实保证的:有机体的模型(其内部状态)不是无偏的,而是规定了一些必须维持的存在先决条件(或先验偏好),例如,对于鱼来说,处于水中。第三,有了这种形式主义,就可以将最优行为(相对于先验偏好)描述为感知和行动的(贝叶斯)模型证据的最大化。通过最大化模型证据(即不证自明),生物体确保它实现其先前的偏好(例如,鱼留在水中)并避免令人惊讶的状态。反过来,模型证据的最大化在数学上(大约)等价于变分自由能的最小化 因此我们再次(以另一种方式)达到第 2 章中讨论的主动推理的相同中心结构。最后,我们详细介绍了最小化意外与汉密尔顿最少行动原则之间的关系。这证明了主动推理与统计物理学第一原理之间的正式关系。
在第4章中,我们概述了主动推理的形式方面。我们关注从贝叶斯推理到易于处理的近似的转变变分推理 以及有机体通过感知和行动最小化变分自由能的最终目标。由此得到生物用来理解其世界的生成(世界)模型的重要性。我们引入了两种生成(世界)模型,使用离散变量或连续变量来表达我们对数据如何生成的信念。我们解释说,两者都提供相同的主动推理,但它们分别适用于在离散时间(如部分观察的马尔可夫决策问题)或连续时间(如随机微分方程)中表述事态的情况。
在第五章中,我们评论了自由能最小化的规范原理与大脑如何实现该原理的过程理论之间的差异,并解释说后者会产生可测试的预测。然后,我们概述了伴随主动推理的过程理论的各个方面,其中包括神经元消息传递等领域,包括神经解剖电路(例如,皮质‑皮质下环路)和神经调节。例如,在解剖层面,消息传递很好地映射到典型的皮质微电路,其预测源于某一层的深层皮质层,并以下面一个层面的表层皮层为目标((Bastos et al. 2012)。在更系统的层面上,我们讨论了贝叶斯推理、学习和精确加权如何分别对应于神经元动力学、突触可塑性和神经调节,以及预测编码的自上而下和自下而上的神经消息传递如何映射到较慢的(例如,α或β)和更快(例如,γ)的脑节律 At a more systemic level, we discussed how Bayesian inference, learning, and precision weighting correspond to neuronal dynamics, synaptic plasticity, and neuromodulation, respectively, and how the top- down and bottom-up neural message passing of predictive coding maps to slower (e.g., alpha or beta) and faster (e.g., gamma) brain rhythms。这些和其他示例表明,在设计特定的主动推理模型后,人们可以从其生成世界模型的形式中得出神经生物学含义。
在第6章中,我们提供了设计主动推理模型的秘诀。我们看到,虽然所有生物都会最大限度地减少其变分自由能,但它们的行为方式不同,有时甚至相反,因为它们被赋予了不同的生成模型。因此,区分不同(例如,更简单和更复杂)生物的只是它们的生成模型不同。有丰富的可能的生成模型,它们对应于不同的生物(例如神经元)实现,并在不同的环境和生态位中产生不同的适应性或适应不良行为。这使得主动推理同样适用于表征简单的生物,如感知和寻求营养梯度的细菌,像我们这样追求复杂目标并参与丰富文化实践的复杂生物,甚至不同的个体 在某种程度上,人们适当地表征了各自的特征生成模型。进化似乎已经发现了越来越复杂的大脑和身体设计结构,使生物体能够处理(和塑造)丰富的生态位。建模者可以对这一过程进行逆向工程,并根据感兴趣的生物所占据的利基类型,以生成模型的形式指定其大脑和身体的设计。这对应于一系列的设计选择(例如,使用离散或分类变量的模型、浅层或分层模型) 我们在本章中对其进行了解包。
在第7章和第8章中,我们提供了离散和连续时间的主动推理模型的大量示例,这些示例解决了感知推理、目标导向导航、模型学习、动作控制等问题。这些示例旨在展示这些模型下的各种紧急行为,并详细说明如何在实际中指定它们的原则。
在第9章中,我们讨论了如何使用主动推理进行基于模型的数据分析,并恢复个体生成模型的参数,从而更好地解释任务中主体的行为。这种计算表型分析使用了本书其余部分讨论的相同形式的贝叶斯推理,但以不同的方式:它有助于设计和评估其他人(主观)模型的(客观)模型。
10.3连接点:主动推理的综合视角
几十年前,哲学家丹尼特感叹认知科学家投入了太多精力来建模孤立的子系统(例如感知、语言理解),而这些子系统的边界往往是任意的。他建议尝试对“整个鬣蜥”进行建模:一种完整的认知生物(也许是一个简单的生物)和它需要应对的环境生态位(Dennett 1978)。
主动推理的一个好处是,它提供了生物体解决其适应性问题的方式的首要原则。本书所追求的规范方法假设可以从变分自由能最小化原理出发,并得出有关特定认知过程的含义,例如感知、行动选择、注意力和情绪调节及其神经元基础。
想象一个简单的生物,它必须解决诸如寻找食物或住所之类的问题。当施展为主动推理时,该生物的问题可以是用积极的术语描述,即采取行动来征求偏好的感觉(例如,与食物相关的感觉)。在某种程度上,这些偏好的感觉被包含在其生成模型中(作为先验信念),有机体正在有效地收集其模型的证据,或者更寓言性地,为其存在收集证据(即最大化模型证据或不证自明的证据)。这个简单的原理对传统上孤立地考虑的心理功能产生了影响,例如感知、行动控制、记忆、注意力、意图、情感等等。例如,感知和行动都是自我证明的,从某种意义上说,生物可以通过改变其信念(关于食物的存在)或通过改变世界,将其期望(给定其生成模型)与其感知的东西结合起来。(追求与食物相关的感觉)。记忆和注意力也可以被认为是优化同一目标。长期记忆是通过学习生成模型的参数来发展的。当信念是关于过去和未来的外部状态时,工作记忆就是信念更新。注意力是对感官输入精确度的信念的优化。规划(和意图)的形式可以通过吸引(某些)生物在替代未来中进行选择的能力来概念化,这反过来又需要时间深度的生成模型。这些预测了一系列行动将产生的结果,并对这些结果持乐观态度。这种乐观主义表现为相信未来的结果将导致首选的结果。深度时间模型还可以帮助我们理解复杂形式的展望(其中对当前的信念用于推导对未来的信念)和回顾(其中对当前的信念用于更新对过去的信念)。内感受调节和情绪的形式可以通过诉诸内部生理学的生成模型来概念化,该模型预测未来事件的 allostatic后果。
正如上面的例子所示,从情感行为规范理论的角度研究认知和行为有一个重要的结果。这种理论并不是从组装单独的认知功能开始的,例如感知、决策和计划。相反,它首先为生物体必须解决的问题提供完整的解决方案,然后分析该解决方案以得出有关认知功能的含义。例如,哪些机制允许生物体或人造生物(例如机器人)感知世界、记住世界或计划(Verschure 等人,2003 年、2014 年;Verschure 2012 年;Pezzulo、Barsalou 等人,2013 年;Krakauer 等人)等2017)?这是一个重要的随着心理学和神经科学教科书中使用的认知功能分类法在很大程度上继承自早期哲学和心理学理论(有时称为詹姆斯主义范畴),这一趋势正在发生变化。尽管它们具有巨大的启发价值,但它们可能相当任意,或者它们可能不对应于单独的认知和神经过程(Pezzulo 和 Cisek 2016,Buzsaki 2019,Cisek 2019)。事实上,这些詹姆斯式的范畴可能是我们的生成模型如何解释我们与感觉中枢的接触的候选者 而不是解释这种接触。candidates for how our generative models explain our engagement with the sensorium—as opposed to explaining that engagement例如,“我正在感知”的唯我论假设只是我对当前事态的解释,包括我的信念更新。
采用规范视角也可能有助于识别不同领域研究的认知现象之间的形式类比。
一个例子是勘探和开发exploration and exploitation之间的权衡,它以各种形式出现(Hills et al. 2015)。这种权衡经常在觅食过程中进行研究,此时生物必须在利用以前的成功计划和探索新的(可能更好)的计划之间做出选择。然而,当生物可以在利用当前最佳计划与投入更多时间和认知努力来探索其他可能性之间做出选择时,在利用有限资源(例如,时间限制或搜索努力)进行记忆搜索和深思熟虑期间,也会发生同样的权衡。用自由能来表征这些明显不相关的现象可能会揭示深层的相似性(Friston, Rigoli et al. 2015;Pezzulo, Cartoni et al. 2016;Gottwald and Braun 2020)。最后,除了对心理现象的统一视角之外,主动推理还提供了一种理解相应神经计算的原则方法。换句话说,它提供了一种将认知处理与(预期的)神经元动力学联系起来的过程理论。主动推理假设与大脑、思想和行为有关的一切行为可以用最小化自由变分来描述活力。反过来,这种最小化具有可以凭经验验证的特定神经特征(例如,在消息传递或大脑解剖学方面)。在本章的其余部分中,我们将探讨主动推理对心理功能的一些影响 就像我们在绘制一本心理学教科书一样。对于每个函数,我们还强调了主动推理与文献中其他流行理论之间的一些联系(或分歧)。
10.4 预测大脑、预测心智和预测处理(次优)
I have this picture of pure joy
it’s of a child with a gun
he’s aiming straight in front of himself,
shooting at something that isn’t there.
—Afterhours, “Quello che non c’è” (Something that isn’t there)
传统的大脑和认知理论强调从外部刺激到内部表征,然后是运动动作的前馈转换。这被称为“三明治模型”,因为刺激和反应之间的一切都被贴上“认知”标签(Hurley 2008)。从这个角度来看,大脑的主要功能是将传入的刺激转化为适合情境的反应。主动推理与这种观点有很大不同,它强调大脑和认知的预测和目标导向方面。用心理学术语来说,主动推理生物(或其大脑)是概率推理机器,它根据其生成模型不断生成预测。不证自明的生物以两种基本方式使用它们的预测。首先,他们将预测与传入数据进行比较,以验证他们的假设(预测编码),并在较慢的时间尺度上修改他们的模型(学习)。其次,他们制定预测来指导他们收集数据的方式(主动推理)。通过这样做,主动推理生物满足了两个必要条件:认知(例如,视觉探索存在显着信息的地方,可以解决假设或模型的不确定性)和实用(例如,移动到可以进行首选观察(例如奖励)的位置。安全)。认知命令使感知和学习过程变得活跃,而实用命令使行为目标导向。
10.4.1 预测处理
这种以预测和目标为中心的大脑和认知观点与预测处理(PP)密切相关(并为其提供了灵感) :这是心灵哲学和认识论中的一个新兴框架,它将预测视为预测的核心。大脑和认知,并诉诸“预测性大脑”或“预测性思维”的概念(Clark 2013,2015;Hohwy 2013)。有时,PP 理论会吸引主动推理的特定功能及其一些结构,例如生成模型、预测编码、自由能、精确控制和马尔可夫毯子,但有时它们会吸引其他结构,例如耦合逆和耦合逆向推理。前向模型,不属于主动推理的一部分。因此,与主动推理相比,术语“预测处理”的含义更广泛(且限制更少)。
预测处理理论在哲学引起了人们的广泛关注,因为它们在许多意义上具有统一的潜力:跨越多个认知领域,包括感知、行动、学习和心理病理学;从较低水平(例如,感觉运动)到较高水平的认知处理(例如,心理结构);从简单的生物有机体到大脑、个体以及社会和文化结构。 PP 理论的另一个吸引力是它们使用概念术语,例如信念和惊讶,这涉及哲学家熟悉的心理分析水平(需要注意的是,有时这些术语可能具有与常见用法不同的技术含义)。然而,随着对 PP 兴趣的增长,哲学家们对其理论和认识论含义有不同的看法,这一点变得越来越明显。例如,它被解释为内在主义(Hohwy 2013)、体现或基于行动(Clark 2015)以及行动主义和非表征术语(Bruineberg et al. 2016,Ramstead et al. 2019)。围绕这些概念解释的争论超出了本书的范围。
10.5 感知
You can’t depend on your eyes when your imagination is out of focus.
—Mark Twain
主动推理将感知视为基于如何生成感官观察的生成模型的推理过程。贝叶斯规则本质上是反转模型,根据观察结果来计算有关环境隐藏状态的信念。这种“感知即推理”的想法可以追溯到亥姆霍兹(Helmholtz,1866),并且经常在心理学、计算神经科学和机器学习(例如综合分析)中被重新提出。面临具有挑战性的感知问题,例如破坏基于文本的 CAPT‑CHA (George et al. 2017)。
10.5.1 贝叶斯大脑假设(次优)
这一想法最突出的当代表达是贝叶斯大脑假说,该假说已应用于决策、感觉处理和学习等多个领域(Doya 2007)。主动推理通过将变分自由能最小化的要求推导出来,为这些推理思想提供了规范基础。正如同样的命令延伸到动作动力学,主动推理自然地模拟了主动感知以及有机体主动采样观察结果来测试其假设的方式(Gregory 1980)。相反,在贝叶斯大脑议程下,感知和行动根据不同的命令进行建模(其中行动需要贝叶斯决策理论;参见第 10.7.1 节)。更广泛地说,贝叶斯大脑假说指的是一系列不一定是整合的方法,并且经常做出不同的经验预测。例如,这些包括大脑执行贝叶斯最佳感觉运动和多感觉整合的计算级建议(Kording and Wolpert 2006),大脑实现贝叶斯推理的特定近似的算法级建议,例如决策‑通过采样(Stewart 等人,2006 年),以及关于神经群体执行概率计算或编码概率分布的具体方式的神经级提案例如,作为样本或概率群体代码(Fiser 等人,2006 年)。 2010,Pouget 等人。2013)。在每个解释层面上,该领域都有相互竞争的理论。例如,通常诉诸精确贝叶斯推理的近似值来解释与最佳行为的偏差,但不同的工作考虑不同的(且并不总是兼容的)近似值,例如不同的采样方法。更广泛地说,不同级别的提案之间的关系并不总是直接的。这是因为贝叶斯计算可以通过多种算法方式实现(或近似),即使没有明确表示概率分布(Aitchison 和 Lengyel 2017)。
主动推理提供了一个更综合的视角,将规范原则和过程理论联系起来。在规范层面,其核心假设所有过程都最小化变分自由能。相应的推理过程理论使用自由能梯度下降,这具有明确的神经生理学含义,在第 5 章中进行了探讨(Friston、FitzGerald 等人,2016 年)。更广泛地说,我们可以从自由能最小化原理出发,推导出对大脑的影响架构例如,感知推理的规范过程模型(在连续时间)是预测编码。预测编码最初由 Rao 和 Ballard (1999) 提出作为分层感知处理理论,用于解释一系列记录在案的自上而下效应,这些效应很难与前馈架构以及已知的生理事实相一致(例如,感觉层次中存在前向或自下而上和后向或自上而下的连接)。然而,在某些假设下,例如拉普拉斯近似(Friston 2005),预测编码可以从自由能最小化原理导出。此外,连续时间内的主动推理可以被构建为预测编码到动作领域的定向延伸 通过赋予预测编码代理运动反射(Shipp et al. 2013)。这将我们引向下一点。
10.6 动作控制
If you can’t fly then run, if you can’t run then walk, if you can’t walk then crawl, but whatever you do you have to keep moving forward.
—Martin Luther King
在主动推理中,动作处理类似于感知处理,因为两者都受到前向预测(分别是外感受和本体感受)的指导。正是“我的手抓住杯子”的(本体感受)预测引发了抓握动作。动作和知觉之间的等价性也存在于神经生物学层面:运动皮层的结构与感觉皮层的组织方式相同 作为预测编码结构,不同之处在于它可以影响脑干和大脑中的运动反射。脊柱(Shipp et al. 2013)并且它接收到的上升输入相对较少。电机Motor反射允许通过沿着所需的方向设置“平衡点”来控制运动轨迹 对应于平衡点假设的想法(费尔德曼,2009)。重要的是,启动一个动作(例如抓起一个杯子)需要适当调节先前信念和感觉流的精度(逆方差)。这是因为这些精度的相对值决定了生物处理其先前信念(它拿着杯子)和它的感官输入(表明它没有拿着杯子)之间的冲突的方式。根据相互矛盾的感官证据,先前关于抓杯子的不精确信念可以很容易地被修正 导致改变想法而不采取任何行动。相反,当先验信念占主导地位(即具有更高的精确度)时,即使面对相互冲突的感官证据,它也会被维持,并且会引发解决冲突的抓住行动。为了确保这种情况,动作启动会引起短暂的感觉衰减(或降低感觉预测错误的权重)。这种感觉衰减的失败可能会产生适应不良的后果,例如无法启动或控制运动(Brown et al. 2013)。
10.6.1 意念运动理论
在主动推理中,行动源于(本体感受)预测,而不是运动命令(Adams、Shipp 和 Friston 2013)。这个想法将主动推理与行动的意念ideomotor运动理论联系起来:一个理解行动控制的框架,可以追溯到威廉·詹姆斯(1890)和后来的“事件编码”和“预期行为控制”理论(Hommel et al. 2001,霍夫曼 2003)。意念运动理论表明,动作‑效果联系(类似于前向模型)是认知架构中的关键机制。重要的是,这些链接可以双向使用。当它们用于作用‑效果方向时,它们允许生成感官预测;当它们用于效果‑动作方向时,它们允许选择实现所需感知结果的动作 这意味着动作是根据其预测的结果来选择和控制的(因此称为“ideo + motor”)。这种行动控制的预期观点得到了大量文献的支持,这些文献记录了(预期的)行动后果对行动选择和执行的影响(Kunde et al. 2004)。主动推理提供了这一想法的数学特征,其中还包括其他机制,例如精确控制和感觉衰减的重要性,这些机制在意念运动理论中尚未得到充分研究(但与意念运动理论兼容)。
10.6.2 控制论
主动推理与控制论思想密切相关,这些思想涉及行为的有目的的、目标导向的性质以及(基于反馈的)主体与环境交互的重要性,如 TOTE(测试、操作、测试、退出)和相关的例子所示。模型(Miller 等人,1960 年;Pezzulo、Baldassarre 等人,2006 年)。在 TOTE 和主动推理中,动作的选择是由首选(目标)状态和当前状态之间的差异决定的。这些方法不同于简单的刺激‑反应关系,正如行为主义理论和强化学习等计算框架中更常见的假设(Sutton 和 Barto 1998)。
主动推理中的动作控制概念特别类似于感知控制理论(Powers 1973)。感知控制理论的核心概念是受控制的是感知状态,而不是运动输出或动作。在驾驶时,我们所控制的——并且在面对干扰时保持稳定——是我们的参考或期望速度(例如,90 英里/小时),如速度计所指示的,而我们为此选择的动作(例如,加速或减速)更易变并且依赖于上下文。例如,根据干扰(例如,风、陡峭的道路或其他汽车),我们需要加速或减速来保持参考速度。这一观点实现了威廉·詹姆斯(1890)的建议,即“人类通过灵活的手段实现稳定的目标
虽然在主动推理和感知控制理论中,控制动作的是感知(特别是本体感受)预测,但这两种理论在控制的操作方式上有所不同。在主动推理(而不是感知控制理论)中,动作控制具有基于生成模型的预期或前馈方面。相反,感知控制理论假设反馈机制在很大程度上足以控制行为,而尝试预测干扰或施加前馈(或开环)控制是毫无价值的。不过,这种反对意见主要是指在解决使用逆控制理论的局限性正向模型(参见下一节)。在主动推理下,生成或前向模型不用于预测干扰,而是用于预测未来(期望的)状态和通过行动实现的轨迹,并推断感知事件的潜在原因。
最后,主动推理和感知控制理论之间的另一个重要联系点是它们概念化控制层次结构的方式。感知控制理论提出,更高层次的控制低层次是通过设置参考点或设定点(即他们必须实现的目标),让他们自由选择实现目标的手段,而不是通过设置或偏向较低级别必须执行的行动(即,如何操作)。这与大多数分层和自上而下控制理论形成鲜明对比,在这些理论中,较高级别要么直接选择计划(Botvinick 2008),要么偏向较低级别的行动或运动命令的选择(Miller 和 Cohen 2001)。与感知控制理论类似,在主动推理中,人们可以根据目标和子目标的(自上而下)级联分解层次控制,这些目标和子目标可以在适当的(较低)级别自主实现。此外,在主动推理中,控制层次的不同级别所表示的目标的贡献可以通过激励过程进行调节(精确加权),从而优先考虑更显着或更紧急的目标(Pezzulo,Rigoli) ,和弗里斯顿 2015,2018)。
10.6.3 最优控制理论
主动推理解释动作控制的方式与神经科学中的其他控制模型显著不同,例如最优控制理论(Todorov 2004,Shadmehr et al. 2010)。该框架假设大脑的运动皮层使用将刺激映射到反应的(反应性)控制策略来选择动作。相反,主动推理假设运动皮层传达预测,而不是命令。此外,虽然最优控制理论和主动推理都吸引内部模型,但它们以不同的方式描述内部模型(Friston 2011)。在最优控制中,两种内部模型之间存在区别:逆模型对刺激响应偶然事件进行编码并选择运动命令(根据某些成本函数),而正向模型对行动结果偶然事件进行编码并为逆模型提供模拟结果。输入来代替噪声或延迟反馈,从而超越了纯粹的反馈控制方案。逆向和正向模型还可以在与外部动作感知分离的循环中运行(即,当输入和输出被抑制时),以支持动作序列的内部“假设”模拟。这种对动作的内部模拟与各种认知功能有关,例如社会领域的计划、动作感知和模仿(Jeannerod 2001,Wolpert 等人 2003)以及各种运动障碍和精神病理学(Frith 等人) .2000)。
与正向‑逆向建模方案相反,在主动推理中,正向(生成)模型负责动作控制的繁重工作,而逆向模型则非常简单,并且通常简化为在外周水平(即在脑干或大脑中)解决的简单反射。当预期状态和观察到的状态(例如,期望的、当前的手臂位置)之间存在差异时,即感官预测误差,就会开始采取行动。这意味着电机命令相当于正向模型做出的预测,而不是最优控制中逆向模型计算的结果。感觉(更准确地说,本体感受)预测误差通过动作(即手臂运动)来解决。通过行动填补的空白被认为非常小,以至于不需要复杂的逆模型,但需要简单得多的运动反射(Adams、Shipp 和 Friston 20131).运动反射比逆模型更简单的原因在于,它不编码从推断的世界状态到动作的映射,而是编码动作和感觉结果之间更简单的映射。参见 Friston、Daunizeau 等人。 (2010)进一步讨论。最佳电机控制和主动控制之间的另一个关键区别推论是,前者使用成本或价值函数的概念来激励行动,而后者则用贝叶斯先验概念(或先验偏好,隐含在预期自由能中)取代它 正如我们在下一节。
10.7 效用和决策
Action expresses priorities.
—Mahatma Gandhi
状态成本或价值函数的概念是许多领域的核心,例如最优运动控制、效用最大化的经济理论和强化学习。例如,在最优控制理论中,到达任务的最优控制策略通常被定义为最小化特定成本函数的策略(例如,更平滑或具有最小的加加速度)。在强化学习问题中,例如在包含一种或多种奖励的迷宫中导航,最优策略是允许最大化(折扣)奖励同时最小化移动成本的策略。这些问题通常使用贝尔曼方程(或连续时间的哈密尔顿‑雅可比‑贝尔曼方程)来求解,其一般思想是决策的问题可以分解为两部分:立即奖励和决策问题剩余部分的价值。这种分解提供了动态规划的迭代过程,这是控制理论和强化学习(RL)的核心(Bellman 1954)。
主动推理与上述方法有两个主要不同之处。首先,主动推理不仅仅考虑效用最大化,而是考虑(预期)自由能最小化的更广泛目标,其中还包括其他(认知)命令,例如消除当前状态的歧义和寻求新颖性(见图2.5)。这些额外的目标有时会添加到经典奖励中,例如作为“新奇奖励”(Kakade 和 Dayan 2002)或“内在奖励”(Schmidhuber 1991,Oudeyer 等人 2007,Baldassarre 和 Mirolli 2013,Gottlieb 等人 2013) 但它们在主动推理中自动出现,使其能够解决探索‑利用平衡。原因是自由能是信念的函数,这意味着我们处于信念优化领域,而不是外部奖励函数。这对于探索性问题至关重要,其中的成功取决于解决尽可能多的不确定性。
其次,在主动推理中,成本的概念被吸收到先验中。先验(或先验偏好)指定了控制目标,例如要遵循的轨迹或要到达的终点。使用先验来编码首选观察结果(或序列)可能比使用实用程序更具表现力(Friston、Daunizeau 和 Kiebel 2009)。使用这种方法,寻找最优策略被重新定义为一个推理问题(实现首选轨迹的一系列控制状态),并且不需要价值函数或贝尔曼方程 尽管可以诉诸类似的方法如递归逻辑(Friston、Da Costa 等人,2020)。主动推理和强化学习中通常使用先验函数和值函数的方式之间至少存在两个根本区别。首先,强化学习方法使用状态或状态‑动作对的值函数,而主动推理则使用观测值的先验。其次,价值函数是根据遵循特定策略的状态(或在状态中执行操作)的预期回报来定义的,即从该状态开始然后获得的未来(贴现)奖励的总和执行政策。相比之下,在主动推理中,先验通常不会对未来的奖励进行求和,也不会对其进行折扣。相反,当预期自由能达到时,类似于预期回报的东西才会出现在主动推理中。这意味着预期自由能是最接近价值函数的模拟。然而,即使如此,预期自由能是关于state的信念的函数,而不是state的函数 a functional of beliefs about states, not a function of states,这一点也有所不同。话虽如此,构建类似于 RL 中状态的价值函数的先验是可能的,例如,通过缓存这些状态中的预期自由能计算(Friston、FitzGerald 等人,2017)。2016年;迈斯托、弗里斯顿和佩祖洛 (2019)。
此外,将效用utility的概念吸收到先验中有一个重要的理论结果:先验扮演目标的角色,并使生成模型有偏见——或乐观,在某种意义上,生物相信它会遇到更好的结果。正是这种乐观使推断的计划在积极的推理中达到预期的结果;这种乐观的失败可能对应于冷漠(Hezemans et al. 2020)。这与其他正式的决策方法形成了鲜明的对比,例如贝叶斯决策理论,它将事件的概率与其效用分开。话虽如此,这种区分有些肤浅,因为效用函数总是可以被重写为编码先验信念,这与最大化效用函数的行为是先验的(通过设计)更有可能的事实是一致的。从通货紧缩的角度来看(稍微有点偏离逻辑),这就是效用的定义。
10.7.1 贝叶斯决策理论(次优)
贝叶斯决策理论是一个数学框架,它将贝叶斯大脑的思想(如上所述)扩展到决策、感觉运动控制和学习领域(Kording and Wolpert 2006,Shadmehr et al. 2010,Wolpert and Landy 2012)。贝叶斯决策理论根据两个不同的过程来描述决策。第一个过程使用贝叶斯计算来预测未来(行动或政策相关)结果的概率,第二个过程使用(固定或学习的)效用或成本函数定义对计划的偏好。最终决策(或行动选择)过程整合了两个流,从而选择(以更高的概率)具有更高概率产生更高奖励的行动计划。这与主动推理形成鲜明对比,在主动推理中,先验分布直接表明什么对有机体有价值(或者在进化历史中什么是有价值的)。然而,贝叶斯决策理论的两个流派与变分自由能和预期自由能的优化之间可以分别进行相似之处。在下面主动推理,变分自由能的最小化提供了关于世界状态及其可能演化的准确(且简单)的信念。先前的信念是,通过政策选择,预期的自由能将被最小化,这包含了偏好的概念。
在一些圈子里,人们对贝叶斯决策理论的地位感到担忧。这是从完整的类定理(Wald 1947,Brown 1981)得出的,该定理说,对于任何给定的决策和成本函数对,存在一些使贝叶斯决策最优的先验信念。这意味着在单独处理先验信念和成本函数时存在隐含的二元性或简并性。从某种意义上说,主动推理通过将效用或成本函数吸收到偏好形式的先验信念中来解决这种退化问题。
10.7.2 强化学习(次优)
强化学习(RL)是一种解决马尔可夫决策问题的方法,在人工智能和认知科学中都很流行(Sutton 和 Barto 1998)。它侧重于智能体如何通过反复试验来学习策略(例如,杆平衡策略):通过尝试行动(例如,向左移动)并根据行动成功(例如,杆平衡)或接收积极或消极的强化失败(例如,杆子掉落)。
主动推理和强化学习解决了一系列重叠的问题,但在数学和概念上在许多方面有所不同。如上所述,主动推理省去了奖励、价值函数和贝尔曼最优性的概念,而这些概念是强化学习方法的关键。此外,政策概念在两个框架中的使用方式也不同。在强化学习中,策略表示一组需要学习的刺激‑响应映射。在主动推理中,策略是生成模型的一部分:它表示需要推断的一系列控制状态。
强化学习方法有很多,但它们可以分为三个主要类别。前两种方法尝试学习良好的(状态或状态动作)价值函数,尽管以两种不同的方式。
RL 的无模型方法直接从经验中学习价值函数:它们执行操作、收集奖励、更新其价值函数,并使用它们来更新其策略。它们被称为无模型的原因是因为它们不使用允许预测未来状态的(转换)模型 类似于主动推理中使用的那种。相反,它们隐含地诉诸于更简单的模型(例如,状态‑动作映射)。无模型强化学习中的学习价值函数通常涉及计算奖励预测错误,如流行的时间差异规则。虽然主动推理经常引起预测错误,但这些都是状态预测错误(因为主动推理中没有奖励的概念)。
基于模型的强化学习方法不会直接从经验中学习价值函数或策略。相反,他们从经验中学习任务模型,使用该模型进行计划(模拟可能的经验),并根据这些模拟经验更新价值函数和策略。虽然主动推理和强化学习都适合基于模型的规划,但它们的使用方式有所不同。在主动推理中,规划是计算每个策略的预期自由能,而不是更新价值函数的手段。可以说,如果预期自由能被视为价值函数,则可以说使用生成模型得出的推论用于更新该函数,从而在这些方法之间提供了一个类比点。
强化学习方法的第三个系列是策略梯度方法,它试图直接优化策略,而不需要中间值函数,而中间值函数是基于模型和无模型强化学习的核心。这些方法从参数化策略开始,能够生成(例如)运动轨迹,然后通过更改参数来优化它们,以在轨迹导致高(低)正奖励时增加(减少)策略的可能性。这种方法将策略梯度方法与主动推理联系起来,这也省去了价值函数(Millidge 2019)。然而,政策梯度的总体目标(最大化长期累积奖励)不同来自主动推理。
除了主动推理和强化学习之间的形式差异之外,还存在一些重要的概念差异。一个区别在于这两种方法如何解释目标导向行为和习惯行为。在动物学习文献中,目标导向的选择是通过对行动与其结果之间的偶然性的(前瞻性)知识来调节的(Dickinson and Balleine 1990),而习惯性选择不是前瞻性的,而是依赖于更简单的选择(例如,刺激‑反应)机制。强化学习中的一个流行观点是,目标导向和习惯性选择分别对应于基于模型和无模型的强化学习,并且这些选择是并行获得的,并不断竞争以控制行为(Daw et al. 2005)。
相反,主动推理将目标导向和习惯性选择映射到不同的机制。在主动推理(离散时间)中,策略选择本质上是基于模型的,因此符合目标导向的深思熟虑选择的定义。这与基于模型的强化学习中发生的情况类似,但有所不同。在基于模型的强化学习中,行动是在预期中选择的方式(使用模型)但以反应方式进行控制(使用刺激‑反应政策);在主动推理中,可以通过实现本体感受预测以主动的方式控制动作(关于动作控制,请参阅第 10.6 节)。
在主动推理中,可以通过执行目标导向的策略,然后缓存有关哪些策略在哪些上下文中成功的信息来获得习惯。缓存的信息可以合并为策略的先验值(Friston、FitzGerald 等人,2016 年;Maisto、Friston 和 Pezzulo,2019 年)。该机制允许无需深思熟虑地执行具有较高先验价值(在给定上下文中)的策略。这可以简单地被认为是通过多次参与一项任务来观察“我做了什么”并了解到“我是那种倾向于这样做的生物”。与无模型强化学习不同,在无模型强化学习中,习惯是独立于目标导向的策略选择而获得的,而在主动推理中,习惯是通过反复追求目标导向的策略(例如,通过缓存其结果)来获得的。
在主动推理中,目标导向和习惯机制可以合作而不仅仅是竞争。这是因为对政策的先验信念取决于习惯项(政策的先验值)和深思熟虑的项(预期自由能)。主动推理的分层阐述表明,反应性和目标导向的机制可以按层次结构排列,而不是并行路径(Pezzulo、Rigoli 和 Friston 2015)。
最后,值得注意的是主动推理和强化学习在以下方面有细微的区别:2012)。在这些方法中,规划是通过推断后验进行的他们如何看待行为及其原因。强化学习源自行为主义理论,认为行为是由强化介导的试错学习的结果。相反,主动推理假设行为是推理的结果。这将我们引向下一点。
10.7.3 Planning as Inference
就像可以将感知问题转化为推理问题一样,也可以将控制问题转化为(近似)贝叶斯推理(Todorov 2008)。与此相一致,在主动推理中,规划被视为推理过程:对生成模型的一系列控制状态进行推理。这个想法与其他方法密切相关,包括控制即推理(Rawlik et al. 2013,Levine 2018)、规划即推理(Attias 2003,Botvinick 和 Toussaint 2012)以及风险敏感和KL 控制(卡彭等人。2012)。规划通过使用动态生成模型推断动作或动作序列的后验分布来进行,该动态生成模型编码状态、动作和未来(预期)状态之间的概率偶然性。最佳行动或计划可以通过观察未来回报(佩祖洛和里戈利2011年,索尔维和伯特温尼克2012年)或最佳未来轨迹(莱文2018年)的条件生成模型来推断。例如,可以将模型中的未来期望状态固定(即,固定其值),然后推断出更有可能填补从当前状态到未来期望状态的差距的动作序列
主动推理、推理规划和其他相关方案使用前瞻性控制形式,该控制形式从未来待观察状态的明确表示开始,而不是从一组刺激响应规则或政策开始。更常见的是最优控制理论和强化学习。然而,控制和规划作为推理的具体实现至少在三个维度上有所不同 即,它们使用什么形式的推理(例如,采样或变分推理),它们推理什么(例如,后验分布)动作或动作序列),以及推理的目标(例如,最大化最优条件的边际可能性或获得奖励的概率)。
主动推理对每个维度都采取独特的视角。
首先,它使用可扩展的近似方案(变分推理)来解决规划即推理过程中出现的具有挑战性的计算问题2。其次,它提供基于模型的规划,或对控制状态的后验推断 对应于行动序列或策略,而不是单个行动。第三,为了推断行动序列,主动推理考虑了预期的自由能泛函,它在数学上包含了其他广泛使用的规划即推理方案(例如 KL 控制),并且可以处理不明确的情况(Friston、Rigoli 等人,2015 年)。
10.8 行为和有限理性
The wise are instructed by reason, average minds by experience, the stupid by necessity and the brute by instinct.
—Marcus Tullius Cicero
主动推理中的行为自动结合了多个组成部分:深思熟虑的、坚持不懈的和习惯性的(Parr 2020)。想象一下一个人正走向她家附近的一家商店。如果她预见到后果根据她的行为(例如,左转或右转),她可以制定一个到达商店的好计划。这种深思熟虑的行为是由预期的自由能提供的,当一个人以某种方式采取行动以实现首选观察时(例如,在商店里),预期的自由能会最小化。请注意,预期的自由能还包括减少不确定性的动力,这可以在深思熟虑中体现出来。例如,如果该人不确定最佳方向,她可以移动到适当的有利位置,从那里她可以轻松找到通往商店的路,即使这意味着更长的路线。简而言之,她的计划获得了认知affordance可供性。
如果该人不太能够进行思考(例如,因为她分心),她可能会在到达商店后继续行走。行为的这种持久性是由变分自由能提供的,当人们收集与当前信念(包括关于当前行为过程的信念)相一致的观察结果时,变分自由能就会最小化。人收集的感官和前本体感受观察为“行走”提供了证据,因此可以在没有深思熟虑的情况下决定坚持不懈。
最后,当这个人不太能够深思熟虑时,他可以做的另一件事是选择通常的回家计划,而不需要考虑它。这种习惯成分是由策略的先验值提供的。这可能会为回家的计划分配很高的概率 她观察到自己过去多次制定了这个计划如果不经过深思熟虑的话,它可能会成为主导。
请注意,行为的深思熟虑、坚持不懈和习惯性方面是共存的,并且可以在主动推理中结合起来。换句话说,我们可以推断,在这种情况下,一种习惯是最有可能的行动方案。这与“双重理论”不同,“双重理论”假设我们是由两个独立的系统驱动的,一个是理性的,一个是直觉的(Kahneman 2017)。行为的深思熟虑、坚持不懈和习惯性方面的混合似乎取决于情境条件,例如人们可以在可能具有高复杂性成本的深思熟虑过程中投入的经验量和认知资源量3。
认知资源对决策的影响已在有限理性的框架下得到了广泛的研究(Simon 1990)。其核心思想是,虽然理想的理性主体应该始终充分考虑其行为的结果,但有限理性主体必须平衡计算的成本、努力和及时性,例如,审议最佳计划的信息处理成本(Todorov 2009,Gershman 等人 2015)。
10.8.1 有限理性自由能理论
有限理性是根据亥姆霍兹自由能最小化来表达的:一种与主动推理中使用的变分自由能概念严格相关的热力学结构;有关详细信息,请参阅 Gottwald 和 Braun (2020)。 “有限理性的自由能理论”根据自由能的两个组成部分:能量和熵,阐述了行动选择与有限信息处理能力的权衡(见第二章)。前者代表选择的预期价值(准确度术语),后者代表深思熟虑的成本(复杂性术语)。在深思熟虑过程中,代价高昂的是在选择使信念更加精确之前降低信念的熵(或复杂性)(Ortega and Braun 2013,Zénon et al. 2019)。直观上,具有更精确的后验信念的选择会更准确(并且可能需要更高的效用),但由于提高信念的精确度是有成本的,因此有界决策者必须找到折衷方案 通过最小化自由能。同样的权衡也出现在主动推理中,从而产生了有限理性的形式。有限理性的概念也与证据变分界限(或边际可能性)的使用产生共鸣,这是主动推理的一个确定方面。总之,主动推理提供了(有限)理性和最优性的模型,其中给定问题的最佳解决方案来自互补目标之间的折衷:准确性和复杂性。这些目标源于规范(自由能最小化)的要求,它比经济理论中通常考虑的经典目标(例如效用最大化)更丰富。
10.9 Valence, Emotion, and Motivation
Consider your origins: you were not made to live as brutes, but to follow virtue and knowledge.
—Dante Alighieri
主动推理侧重于(负)自由能作为适应性和有机体实现其目标的能力的衡量标准。虽然主动推理提出生物会采取行动来最小化它们的自由能,但这并不意味着它们必须计算它。一般来说,处理自由能的梯度就足够了。以此类推,我们不需要知道我们的海拔高度即可找到山顶,但只需沿着斜坡向上即可。然而,一些人建议生物可以模拟它们的自由能如何随时间变化。这一假设的支持者认为,它可能允许对 valence, emotion, and motivation.等现象进行表征。
根据这种观点,有人提出 emotional valence, or the positive or negative character of emotions,可以被视为自由能随时间的变化率(一阶导数)(Joffily 和 Coricelli 2013)。
具体来说,当一个生物的自由能随着时间的推移而增加时,它可能会为这种情况分配一个负价;而当它的自由能随着时间的推移而减少时,它可能会赋予它正价。将这一思路延伸到自由能(和二阶导数)的长期动态,也许可以描述复杂的情绪状态;例如,从低价态过渡到高价态的欣慰,或者从高价态过渡到低价态的失望。监测自由能动态(以及它们引发的情绪状态)可能允许根据长期环境统计数据调整行为策略或学习率。
假设第二个生成模型的作用是监控第一个生成模型的自由能,这似乎有点跳跃。然而,这些想法还可以通过另一种方式来解释。这些观点的一个有趣的形式化在于思考是什么导致了自由能的快速变化。由于它是信念的函数,自由能的快速变化必定是由于信念的快速更新。该速度的关键决定因素是精度precision,它在预测编码的动态中充当时间常数。有趣的是,这与自由能高阶导数的概念相关,因为精度是二阶导数的负数(即自由能的曲率curvature of a free energy landscape)。然而,这引出了一个问题:为什么我们应该将精度与效价联系起来。答案来自于注意到精确性与模糊性成反比。事物越精确,其解释就越不模糊。选择最小化预期自由能的行动方案也意味着最小化模糊性,从而最大化精度。在这里,我们看到自由能的高阶导数、其变化率和动机行为之间的直接关联。
对自由能(增加或减少)的期望也可能发挥激励作用并激励行为。在主动推理中,代理对自由能变化(增加或减少)的预期是对政策信念的精确性。这再次凸显了二阶统计量的重要性。例如,高度精确的信念表明人们已经找到了一项好的政策,即一项可以自信地预期能够最大限度地减少自由能的政策。有趣的是,政策(信念)的精确性与多巴胺信号传导有关(FitzGerald、Dolan 和 Friston 2015)。从这个角度来看,提高政策信念精确度的刺激会引发多巴胺爆发 这可能表明它们的激励显着性(Berridge 2007)。这种观点可能有助于阐明将目标或奖励实现的期望与注意力的增加(Anderson et al. 2011)和动机(Berridge and Kringelbach 2011)联系起来的神经生理学机制。
10.10 稳态、动态平衡和内感受处理 Homeostasis, Allostasis, and Interoceptive Pro cessing
There is more wisdom in your body than in your deepest philosophy.
—Friedrich Nietzsche
生物的生成模型不仅与外部世界有关,而且还也许更重要的是 关于内部环境。身体内部(或内感受图式interoceptive schema)的生成模型具有双重作用:解释内感受(身体)感觉是如何产生的,并确保生理参数的正确调节(Iodice et al. 2019),例如体温或血液中的糖含量。控制论理论(在第 10.6.2 节中提到)假设生物体的中心目标是维持体内平衡(Cannon 1929) 确保生理参数保持在可行的范围内(例如,体温永远不会变得太高) 并且体内平衡只能通过对环境的成功控制来实现(Ashby 1952)。这种形式的稳态调节可以在主动推理中通过指定生理参数的可行范围作为内感受观察的先验来实现。有趣的是,体内平衡调节可以通过多种嵌套方式实现。最简单的调节回路是当某些参数(预计)超出范围时(例如,当体温过高时),自主反射(例如,血管舒张)的参与。这种自主控制可以构建为内感受推理:在内感受 interoceptive流上运行的主动推理过程而不是本体感受 proprioceptive流,如外部定向动作的情况(Seth et al. 2012、Seth and Friston 2016、Allen et al. 2019)。为此,大脑可以使用生成模型来预测内感受和生理流并触发自主反射来纠正内感受预测错误(例如,令人惊讶的高体温)。这类似于激活运动反射以纠正本体感觉预测错误和引导外部指导行动的方式。
主动推理超越了简单的自主循环:它可以纠正以越来越复杂的方式产生相同的内感受预测错误(高体温)(Pezzulo、Rigoli 和 Friston 2015)。它可以使用预测性的变稳态策略(Sterling 2012,Barrett and Simmons 2015,Corcoran et al. 2020),超越稳态,在触发内感受预测错误之前以变稳态的方式先发制人地控制生理学 ,例如,在过热之前寻找阴凉处。另一种预测策略需要在预期偏离生理设定点之前调动资源,例如,在长跑之前增加心输出量,以预期氧气需求增加。这需要动态地修改内感受观察的先验,超越稳态(Tschantz et al. 2021)。最终,预测大脑可以制定复杂的目标导向策略,例如确保将冷水带到海滩,以更丰富、更有效的方式满足同样的要求(控制体温)。
生物和内感受调节可能对于情感和情绪affect and emotional处理至关重要(Barrett 2017)。在情境交互过程中,大脑的生成模型不仅不断预测接下来会发生什么,而且还预测内感受和动态平衡的后果。内感受流 在感知外部物体和事件期间引发给它们注入情感维度,这表明它们对于生物的动态平衡和生存有多好或多坏,从而使它们“有意义”。如果这种观点是正确的,那么这种内感受和变稳态处理的障碍可能会导致情失调和各种精神病理状况(Pezzulo 2013;Barrett et al. 2016;Barca et al. 2019;Pezzulo, Maisto et al. 2019)
内感受推理有一个新兴的伙伴 即情感推理。在主动推理的这种应用中,情绪被认为是生成模型的一部分:它们只是大脑用来在深度生成中部署精度的另一种构造或假设。从信念更新的角度来看,这意味着焦虑只是对贝叶斯信念“我很焦虑”的承诺,它最好地解释了普遍的感觉和内感受队列。从行动的角度来看,随后的(内感受)预测增强或减弱了各种精确度(即隐蔽行动)或奴役自主反应(即公开行动)From the perspective of acting, the ensuing (interoceptive) predictions augment or attenuate vari ous precisions (i.e., covert action) or enslave autonomic responses (i.e., overt action)。
这可能看起来很像觉醒,证实了“我很焦虑”的假设。通常,情绪推理需要领域通用的信念更新,吸收来自内感受和外感受感觉流的信息,因此情绪、内感受和健康注意力之间存在密切关系(Seth 和 Friston 2016;Smith,Lane 等,2016) intimate relationship between emotion, interoception, and attention in health and disease
10.11 注意力、显着性和认知动态 Attention, Salience, and Epistemic Dynamics
True ignorance is not the absence of knowledge, but the refusal to acquire it.
—Karl Popper
鉴于我们仅在本章中就多次提到精度和预期自由能,如果不花一点空间来关注和突出,那就太疏忽了。这些概念在整个心理学中反复出现,并经过多次重新定义和分类。有时,这些术语用于指代突触增益控制机制 synaptic gain control mechanisms(Hillyard et al. 1998),该机制优先选择某种感觉模态或模态内的通道子集。有时它们指的是我们如何通过公开或秘密的行动来定位自己,以获得更多关于世界的信息(Rizzolatti et al. 1987; Sheliga et al. 1994, 1995)。
尽管注意力的多种含义带来了不确定性证明了该研究领域的一些认知吸引力,但解决随之而来的歧义也具有价值。心理学的正式观点提供的一件事是我们不需要担心这种歧义。我们可以在操作上将注意力定义为与某些感官输入相关的精确度。这巧妙地映射到增益控制的概念,因为我们推断为更精确的感觉将比那些推断为不精确的感觉对信念更新产生更大的影响。这种关联的结构有效性已经通过心理学范式得到了证明,包括著名的波斯纳范式(费尔德曼和弗里斯顿2010)。具体来说,对视觉空间中具有更高精度 afforded a higher precision的位置处的刺激做出响应比对其他位置的刺激做出响应要快。
这使得术语“显着性”需要类似的正式定义。通常,在主动推理中,我们将显着性与预期信息增益(或认知值)相关联:预期自由能的组成部分。直觉上,当我们期望某件事能产生更多信息时,它就更显着。然而,这定义了行动或政策的显着性,而注意力是关于感官输入的信念的一个属性。这符合显着性作为显性或隐性定向的概念。我们在第七章中看到,我们可以将预期信息增益进一步细分为显着性和新颖性。前者是推理的潜力,后者是学习的潜力。表达注意力和显着性(或新颖性)之间差异的类比是科学实验的设计和分析。注意力是从我们已经测量的数据中选择最高质量的数据并使用这些数据为我们的假设检验提供信息的过程。显着性是下一个实验的设计,以确保最高质量的数据。

我们并不是为了简单地在文献中添加对注意力现象的另一种重新分类而详细讨论这个问题,而是为了强调致力于形式心理学的重要优势。在主动推理下,其他人是否以不同的方式定义注意力(或任何其他构造)并不重要,因为我们可以简单地引用所讨论的数学构造并排除任何混淆。最后要考虑的一点是,这些定义为为什么注意力和显着性经常被混为一谈提供了简单的解释。高度精确的数据很少有歧义。这意味着他们应该受到关注,并且获取这些数据的行动非常重要(Parr 和 Friston 2019a)。
10.12 规则学习、因果推理和快速泛化 Rule Learning, Causal Inference, and Fast Generalization
Yesterday I was clever, so I wanted to change the world. Today I am wise, so I am changing myself.
—Rumi
与当前的机器相比,人类和其他动物擅长做出复杂的因果推论,学习抽象概念和物体之间的因果关系,并从有限的经验中进行概括学习范式,需要大量的例子才能获得相似的性能。这种差异表明,当前的机器学习方法主要基于复杂的模式识别,可能无法完全捕捉人类学习和思考的方式(Lake et al. 2017)。
主动推理的学习范式基于生成模型的开发,该模型捕获动作、事件和观察之间的因果关系。在本书中,我们考虑了相对简单的任务(例如,第 7 章的 T 迷宫示例),这些任务需要不复杂的生成模型。相比之下,对复杂情况的理解和推理需要深度生成模型来捕获环境的潜在结构,例如允许在许多明显不同的情况下进行泛化的隐藏规律(Tervo 等,2016年;弗里斯顿,林等人。 2017)。
管理复杂社交互动的隐藏规则的一个简单例子是交通路口。想象一下,一个天真的人观察了一个繁忙的十字路口,并且必须预测(或解释)行人或汽车何时过马路。人们可以积累有关同时发生的事件的统计数据(例如,一辆红色汽车停下来,一个高个子男人过马路;一个老妇人停下来,一辆大车经过),但大多数最终都是无用的。人们最终可以发现一些重复出现的统计模式,例如在所有汽车停在道路上的某个点后不久,行人就会过马路。如果任务只是预测行人何时即将行走,那么在机器学习环境中,这种确定就足够了,但不需要对情况有任何了解。事实上,这甚至可能导致错误的结论:汽车的停止解释了行人的移动。这种错误在机器学习应用程序中很常见,这些应用程序不吸引(因果)模型,并且无法区分是下雨解释了湿草还是湿草解释了下雨(Pearl 和 Mackenzie 2018)。
另一方面,推断正确的隐藏(例如,交通灯)规则可以更深入地理解情况的因果结构(例如,交通灯导致汽车停车和行人行走)。隐藏规则不仅提供了更好的预测能力,而且还使推理更加简洁,因为它可以抽象出大多数感官细节(例如,汽车的颜色)。反过来,这允许推广到其他情况,例如不同的十字路口或城市,其中大多数感官细节都存在显着差异 ‑ 但需要注意的是,在某些情况下面临十字路口像罗马这样的城市可能需要的不仅仅是看交通信号灯。最后,了解交通灯规则还可以在新情况下实现更有效的学习,或者发展心理学中所谓的“学习集”或机器学习中的学习能力(Harlow 1949)。当面对红绿灯关闭的十字路口时,人们无法使用学到的规则,但可能会期望有另一个类似的隐藏规则在起作用,这可以帮助理解交警在做什么。
正如这个简单的例子所示,学习丰富的环境潜在结构的生成模型(又名结构学习)可以提供复杂形式的因果推理和概括。扩大生成模型以解决这些复杂的情况是计算建模和认知科学的一个持续目标(Tenenbaum et al. 2006,Kemp and Tenenbaum 2008)。有趣的是,当前的机器学习趋势(一般思想是“越大越好”)与主动推理的统计方法之间存在着紧张关系,这表明平衡模型的准确性与其复杂性和准确性的重要性。倾向于更简单的模型。模型缩减(以及修剪不必要的参数)不仅仅是避免资源浪费的一种方法,它也是学习隐藏规则的有效方法,包括在睡眠等离线时段(Friston,Lin 等人,2017 年),也许表现在静息状态活动中(Pezzulo、Zorzi 和 Corbetta 2020)。
10.13 主动推理和其他领域:开放方向
It has to start somewhere, it has to start sometime,what better place than here? What better time than now?
—Rage Against the Machine, “Guerrilla Radio”
在本书中,我们主要关注解决生存和适应生物学问题的主动推理模型。然而主动推理可以应用于许多其他领域。在最后一节中,我们简要讨论两个这样的领域:社会和文化动态以及机器学习和机器人技术。
解决前者需要考虑多个主动推理代理交互的方式以及这种交互的新兴影响。解决更复杂的问题 但以与理论的基本假设兼容的方式。两者都是有趣的开放研究方向。
10.13.1 社会和文化动态
我们(人类)认知的许多有趣的方面都与社会和文化有关文化动态,而不是个人主义的看法,决定,和行动(Veissière等人,2020年)。根据定义,社会动力学需要multiple主动推理生物参与物理互动(例如,联合行动,例如玩团队运动)或更抽象的交互(例如,选举或社交网络)。互动的简单演示相同生物之间的推论已经产生了有趣的emergent现象,例如简单生命形式的自我组织抵制分散,参与形态发生过程的可能性获取和恢复身体形态,以及相互协调的预测和话轮转换(弗里斯顿2013;弗里斯顿和弗里斯2015a弗里斯顿,莱文等人。2015).其他模拟研究了生物可以将他们的认知扩展到物质人工制品,并塑造他们的认知生态位(Bruineberg等人2018年)。
这些模拟只捕捉到了我们社会复杂性的一小部分和文化动态,但它们说明了主动推理的潜力从个人科学扩展到社会科学——以及如何扩展认知超越了我们的头脑(Nave et al. 2020)。
10.13.2 机器学习和机器人技术
本书讨论的生成建模和变分推理方法广泛应用于机器学习和机器人技术。在这些领域,重点通常是如何学习(联结主义)生成模型而不是如何将它们用于主动推理,这是本书的重点。这很有趣,因为机器学习方法可能有助于扩大生成模型和本书中考虑的问题的复杂性,但需要注意的是,它们可能需要非常不同的主动推理过程理论。
虽然在这里不可能回顾有关机器学习生成模型的大量文献,但我们简要提及一些最流行的模型,并从中开发了许多变体。两种早期的联结主义生成模型,亥姆霍兹机和玻尔兹曼机(Ackley et al. 1985,Dayan et al. 1995)提供了范例如何以无监督方式学习神经网络内部表示的示例。亥姆霍兹机与主动推理的变分方法尤其相关,因为它使用单独的识别和生成网络来推断隐藏变量的分布,并从中采样以获得虚构数据。这些方法早期的实际成功是有限的。但之后,堆叠多个的可能性(受限)玻尔兹曼机能够学习多层内部表示,是无监督深度神经网络的早期成功之一(Hinton 2007)。
连接主义生成模型的两个最新例子,变分自动编码器或 VAE(Kingma 和 Welling,2014 年)和生成对抗网络或 GAN(Goodfellow 等人,2014 年),广泛用于机器学习应用,例如识别或生成图片和视频。 VAE 体现了变分方法在生成网络学习中的优雅应用。他们的学习目标,即证据下界 (ELBO),在数学上等同于变分自由能。该目标使得能够学习数据的准确描述(即,最大化准确性),但也有利于与先验没有太大差异的内部表示(即,最小化复杂性)。后一个目标充当所谓的正则化器,有助于泛化并避免过度拟合。
GAN 遵循不同的方法:它们结合了两个网络,一个生成网络和一个判别网络,这两个网络在学习过程中不断竞争。判别网络学习区分生成网络生成的示例数据是真实的还是虚构的。生成网络试图生成欺骗判别网络(即被错误分类)的虚构数据。这两个网络之间的竞争迫使生成网络提高其生成能力并生成高保真度的虚构数据 这种能力已被广泛用于生成逼真的图像等。
上述生成模型(和其他模型)可用于控制任务。例如,Ha 和 Eck(2017)使用(序列到序列)VAE 来学习预测铅笔笔画。通过从 VAE 的内部表示中采样,该模型可以构建新颖的基于笔划的绘图。玻尔兹曼机能够学习多层内部表示,是无监督深度神经网络的早期成功之一(Hinton 2007)。生成建模方法也已用于控制机器人运动。其中一些方法使用主动推理(Pio‑Lopez 等人,2016,桑卡塔尔等人 2020,西里亚等人 2021)或密切相关的想法,但在联结主义背景下(Ahmadi 和 Tani 2019,Tani 和 White 2020)。
该领域的主要挑战之一是机器人运动是高维的并且需要(学习)复杂的生成模型。主动推理和相关方法的一个有趣的方面是,要学习的最重要的事情是下一时间步骤的动作和感觉(例如,视觉和本体感觉)反馈之间的前向映射。这种前向映射可以通过多种方式学习:通过自主探索、通过演示,甚至通过与人类的直接交互例如,老师(实验者)引导机器人的手沿着轨迹到达目标,从而构建有效的目标导向行动的获取(Yamashita 和 Tani 2008)。以各种方式学习生成模型的可能性极大地扩展了机器人最终可以实现的技能范围。反过来,使用主动推理开发更先进(神经)机器人的可能性不仅在技术上而且在理论上都很重要。事实上,主动推理的一些关键方面,例如自适应代理与环境交互、认知功能的集成以及体现的重要性,在机器人设置中自然得到解决。
10.14 总结
Home is behind, the world ahead,
and there are many paths to tread
through shadows to the edge of night,
until the stars are all alight.
—J. R. R. Tolkien, The Lord of the Rings
我们在本书的开头就提出了一个问题:是否有可能从第一原理来理解大脑和行为。然后,我们引入主动推理作为应对这一挑战的候选理论。我们希望读者相信我们最初问题的答案是肯定的。在本章中,我们考虑了主动推理为感知行为提供的统一视角,以及该理论对熟悉的心理结构(例如感知、行动选择和情感)的影响。这使我们有机会重新审视整本书中介绍的概念,并提醒自己仍有待未来研究的有趣问题。我们希望本书为主动推理的相关著作提供有用的补充,一方面包括哲学(Hohwy 2013,Clark 2015),另一方面包括物理学(Friston 2019a)。
我们现在已经到了旅程的终点。我们的目标是提供向那些对使用这些方法感兴趣的人进行介绍 无论是概念层面还是形式层面。然而,需要强调的是,主动推理并不是纯粹在理论上可以学习的东西。我们鼓励任何喜欢这本书的人考虑在实践中追求它。理论神经生物学的重要阶段是尝试写下生成模型,体验模拟行为不当时的挫败感,并在意外发生时从违反先前信念的行为中学习。无论您是否选择在计算层面进行这种实践,我们希望您在日常生活中进行主动推理时能够进行反思。这可能表现为强迫你的眼睛去解决你周边视觉中某些事物的不确定性。它可能是选择在最喜欢的餐厅吃饭以满足先前的(味觉)偏好。它可能是在淋浴太热时减少热量,以确保温度符合您的世界应该如何的模型。最终,我们相信您将继续以某种形式追求主动推理。
未来智能实验室的主要工作包括:建立AI智能系统智商评测体系,开展世界人工智能智商评测;开展互联网(城市)大脑研究计划,构建互联网(城市)大脑技术和企业图谱,为提升企业,行业与城市的智能水平服务。每日推荐范围未来科技发展趋势的学习型文章。目前线上平台已收藏上千篇精华前沿科技文章和报告。
如果您对实验室的研究感兴趣,欢迎加入未来智能实验室线上平台。扫描以下二维码或点击本文左下角“阅读原文”


















 82
82

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









