






QWQ-32B:阿里重磅推出与deepseek媲美的推理模型QWQ,全球第一个内化agent工具使用能力的开源推理模型,可大大降低本地化部署成本,只需要48G显存即可具备deepseek-r1的效果。
QwQ 与传统的指令调优模型相比,能够思考和推理的 QwQ 可以在下游任务中实现显着增强的性能,尤其是难题。QwQ-32B 是中型推理模型,能够实现与最先进的推理模型(如 DeepSeek-R1、o1-mini)相比的竞争性能。
QwQ 32B 模型 具有以下特点:
1、类型: 因果语言模型
2、训练阶段:预训练和后训练(监督微调和强化学习)
3、架构:具有 RoPE、SwiGLU、RMSNorm 和 Attention QKV 偏置的变压器
4、参数数量:32.5B
5、参数数(非嵌入):31.0B
6、层数: 64
7、注意头数 (GQA):Q 为 40 个,KV 为 8 个
8、上下文长度:完整 131,072 个令牌
用法:
from transformers import AutoModelForCausalLM, AutoTokenizer
model_name = "Qwen/QwQ-32B"
model = AutoModelForCausalLM.from_pretrained(
model_name,
torch_dtype="auto",
device_map="auto"
)
tokenizer = AutoTokenizer.from_pretrained(model_name)
prompt = "How many r's are in the word \"strawberry\""
messages = [
{"role": "user", "content": prompt}
]
text = tokenizer.apply_chat_template(
messages,
tokenize=False,
add_generation_prompt=True
)
model_inputs = tokenizer([text], return_tensors="pt").to(model.device)
generated_ids = model.generate(
**model_inputs,
max_new_tokens=32768
)
generated_ids = [
output_ids[len(input_ids):] for input_ids, output_ids in zip(model_inputs.input_ids, generated_ids)
]
response = tokenizer.batch_decode(generated_ids, skip_special_tokens=True)[0]
print(response)
为了实现最佳性能,我们建议使用以下设置:
1、强制执行深思熟虑的输出:
确保模型以 “\n” 开头,以防止生成空洞的思考内容,这可能会降低输出质量。如果使用 apply_chat_template 并设置 add_generation_prompt=True,则这已经自动实现,但可能会导致响应在开始时缺少标记。这是正常行为。
2、采样参数:
使用 Temperature=0.6 和 TopP=0.95 而不是贪婪解码,以避免无休止的重复。
使用 20 到 40 之间的 TopK 来过滤掉罕见的Token出现,同时保持生成输出的多样性。
3、历史中没有思考内容:
在多轮对话中,历史模型输出应该只包含最终的输出部分,不需要包含思考内容。此功能已在 apply_chat_template 中实现。
4、标准化输出格式:
建议在基准测试时使用提示来标准化模型输出。
数学问题:在提示中包含“请逐步推理,并将您的最终答案放在 \boxed{}. 中。
多项选择题:将以下 JSON 结构添加到提示中以标准化响应:“请在答案字段中显示您的选择,在提示中仅包含选择字母,例如,\”answer\“: \”C\“..”
5、处理长输入:
对于超过 32,768 个令牌的输入,启用 YaRN 以提高模型有效捕获长序列信息的能力。
对于部署,建议使用 vLLM。 目前,vLLM 仅支持静态 YARN,这意味着无论输入长度如何,缩放因子都保持不变,这可能会影响较短文本的性能。
仅在需要处理长上下文时才添加 rope_scaling 配置。
deepseek R1 与 QWQ-32B 的对比分析:
模型概述
deepseek R1:这是 DeepSeek 的第一代推理模型,总参数量为 671B,其中 37B 为激活参数,采用 Mixture of Experts(MoE)架构。其性能被认为与 OpenAI 的 o1 模型相当,特别在数学、编码和推理任务上表现出色。
QWQ-32B:Qwen 系列的推理模型,参数量为 32B,是一个密集模型,基于 Qwen2.5-32B 构建,通过强化学习(RL)优化,旨在与 deepseek R1 和 o1-mini 等顶尖模型竞争
性能对比
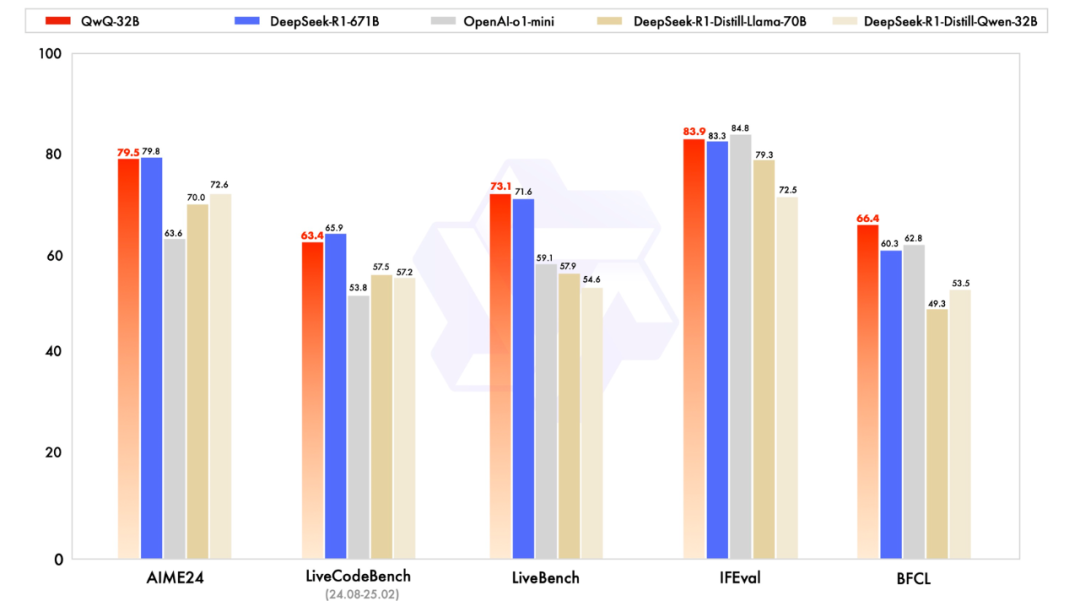
通过多个基准测试,我们可以观察两者的表现:
| 基准测试 | deepseek R1 得分 | QWQ-32B 得分 |
|---|---|---|
| AIME24(数学推理) | 79.8% | 79.5% |
| LiveCodeBench(编码能力) | 65.9% | 63.4% |
| LiveBench(通用问题解决) | 71.6% | 73.1% |
| IFEval(功能性推理) | 未明确提供 | 83.9% |
数学推理:在 AIME24 上,deepseek R1 以 79.8% 略胜 QWQ-32B 的 79.5%,显示出微弱优势。
编码能力:LiveCodeBench 测试中,deepseek R1 的 65.9% 高于 QWQ-32B 的 63.4%,表明在编码生成和优化上稍强。
通用问题解决:LiveBench 上,QWQ-32B 以 73.1% 超过 deepseek R1 的 71.6%,显示出在广义问题解决上的优势。
功能性推理:IFEval 测试中,QWQ-32B 得分 83.9%,但 deepseek R1 的具体数据未明确提供,需进一步确认。
这些结果表明,两者在不同任务上的表现各有优劣,但整体性能非常接近,QWQ-32B 尽管参数量小,却能与 deepseek R1 匹敌,这一点令人意外。
效率与计算资源
deepseek R1:由于其 671B 总参数量(37B 激活),运行时可能需要更多计算资源,例如需要 1500GB vRAM(约 16 个 Nvidia A100 GPU)。这使其更适合高性能计算环境。
QWQ-32B:仅需 24GB vRAM,可在单张 Nvidia H100 GPU 上运行,计算效率更高,适合消费者级硬件或资源受限的场景。
这种效率差异使得 QWQ-32B 在实际部署中更具吸引力,尤其对于中小型团队或个人研究者。
灵活性与开源特性
deepseek R1:采用 MIT 许可,开放源代码,并提供从 1.5B 到 70B 的多种蒸馏版本(如 DeepSeek-R1-Distill-Qwen-32B),用户可根据需求选择适合的参数规模。这为不同计算预算的用户提供了灵活性。
QWQ-32B:采用 Apache 2.0 许可,同样开源,可在 Hugging Face 和 ModelScope 上访问,并通过 Qwen Chat 提供交互体验。其许可允许商业和研究用途,扩展性强。
deepseek R1 的多版本策略为其增添了额外的实用性,而 QWQ-32B 的开源特性则使其更易于集成和定制。
潜在问题与局限性
deepseek R1:其零样本版本(DeepSeek-R1-Zero)可能存在语言混合、重复输出和可读性差的问题。尽管最终版本(DeepSeek-R1)通过引入冷启动数据和多阶段训练有所改善,但这些问题可能仍对某些应用场景造成影响。
QWQ-32B:实验版本(QwQ-32B-Preview)曾报告语言混合、递归推理循环和安全考虑等问题,但最终版本可能已优化这些缺陷。具体细节未完全公开,需用户在部署时谨慎测试。
优缺点总结
以下是两者的详细优缺点对比:
| 方面 | deepseek R1 优势 | deepseek R1 劣势 | QWQ-32B 优势 | QWQ-32B 劣势 |
|---|---|---|---|---|
| 性能 | 在 AIME24 和 LiveCodeBench 上略优 | 在 LiveBench 上稍逊于 QWQ-32B | 在 LiveBench 上表现更好 | 在 AIME24 和 LiveCodeBench 上略逊 |
| 计算效率 | - | 计算资源需求高(671B 参数) | 参数量小(32B),高效运行 | - |
| 灵活性 | 提供多种蒸馏版本,适合不同计算预算 | - | - | 版本选择较少 |
| 开源与许可 | MIT 许可,开放性强 | - | Apache 2.0 许可,商业友好 | - |
| 潜在问题 | - | 可能存在语言混合等问题 | 最终版本可能已优化问题 | 可能存在类似语言混合或推理循环问题 |
适用场景建议
如果用户需要最高性能,尤其在数学和编码任务上,且计算资源充足,deepseek R1 是更好的选择。
如果用户计算资源有限,或希望在消费者级硬件上运行高效模型,QWQ-32B 是更实用的选项。
结论
deepseek R1 和 QWQ-32B 均是优秀的推理模型,两者在性能上非常接近,但 QWQ-32B 的高效性和资源节约性使其在实际应用中更具吸引力。用户应根据具体需求(如计算资源、任务类型)选择适合的模型。


















 622
622

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











