









知识蒸馏(Distilling the Knowledge in a Neural Network)
三大作者
深度学习教父 Geoffery Hinton

谷歌灵魂人物 oriol Vinyals

谷歌核心人物 Jeff Dean

Abstract
多模型集成能提升机器学习性能是指多个性能较差的模型集合在一起可以提升整体的性能。同样集成模型也会出现部署笨重、算力高昂的问题,无法适用多数用户进行安装,训练这些模型也需要进行大量的计算。在一号文献中提到知识蒸馏,将一个集成模型学习到的知识,进行“知识蒸馏”压缩到单个模型上,即可部署在边缘设备上。我们使用这种方法在MNIST数据集和语音识别领域进行测试并取得了不错的效果。另外我们还提出了新的模型集成范式,混合全(全才)模型和专家(专才)模型,其中专家模型负责某个领域的细粒度类别,对于细粒度类别可以很快并且准确的并行学习和训练
1、Introduction
许多昆虫的幼虫形态是为了从环境中提取能量和营养而优化的,而成虫形态则是为了满足不同的旅行和繁殖需求而优化的。昆虫如此,国家如此,个人如此,神经网络也应该是这样
在大规模的机器学习中,我们训练和部署大都使用同一个模型进行,这是不符合上面所诉原则的。尽管训练和部署的目标是不同的,训练的目标是为了提取特征和学习,可以设计成尽可能的大而冗余,需要耗费大量的算力,不必考虑部署在试试设备上。然而部署的目标是实时性高和计算资源少。从上可知,大自然的进化法则是正确的,人类训练和部署机器学习的方法是错误的。
因此训练时我们可以训练出笨重而大模型,也可以是多个模型的集成,目的是做到识别效果好,部署时可以试用本文提到的“知识蒸馏”进行压缩,尽可能的将大模型的知识迁移到小模型中,使用小模型进行部署。
有一个问题(概念上的障碍),我们怎么定义大模型向小模型迁移的“知识”?
通常认为,模型学习到的参数代表了“知识”,无法直接迁移,但教师网络预测结果中各类别概率的相对大小也隐式包含知识,可以看做大模型输出到小模型输入的映射。
对于“大模型”,它去学习区分大量类别,常规的目标函数(损失函数)是对预测和正确答案做平均对数似然概率,最后会给吃正确类别的概率,同样非正确类别的概率也会给出,虽然这些概率会很低。非正确类别识别出的相对概率中隐藏了重要信息,其中就有怎样让模型泛化性能的答案。例如一张宝马车的图片,垃圾车与宝马车的相似度比胡萝卜与宝马车相似度高,这就是费正确类别中隐含的信息,垃圾车比胡萝卜更像宝马车
人们认为训练的目标应该尽可能的接近实际应用,尽管模型常常是在训练集上训练,在测试集上测试,我们想让模型在测试集和实际任务上泛化性能好。因此就需要知道真正学到的知识如何定义和量化,然后让学生网络学习拟合相同的知识。
那么怎样实现教师网络引导学生网络呢?
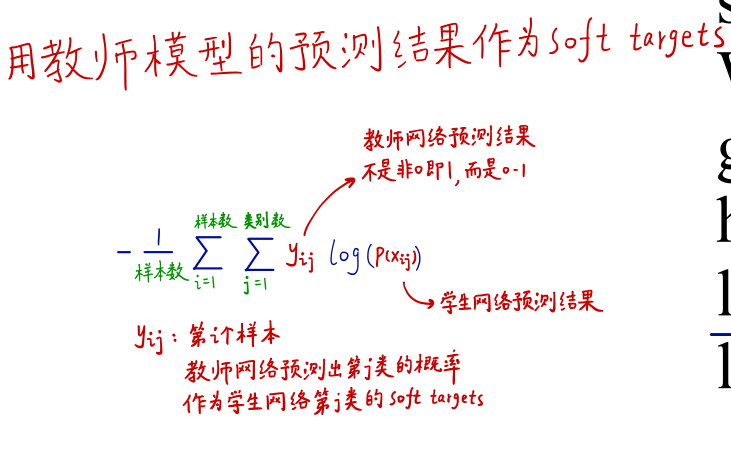
简单直接的方法就是将教师网络的预测结果作为soft targets喂给学生网络训练,对于学生网络可以使用想用训练集或者是部分训练集作为“transfer set”。当大模型是多个模型的集合时,可以使用他们各自的输出的算术平均数或几何平均数作为soft targets。当soft targets具有很高的熵时,即各个类别之间的差别都存在,不会出现一种类别概率很大,另一种很小(为0),可以从中获得大量信息,梯度变化区域平缓。因此可以得出学生网络可以冲教师网络学到很多“知识”,并使用更大的学习率。变化后的交叉熵:
熵低信息量小,确定性大,熵高信息量大,确定性小

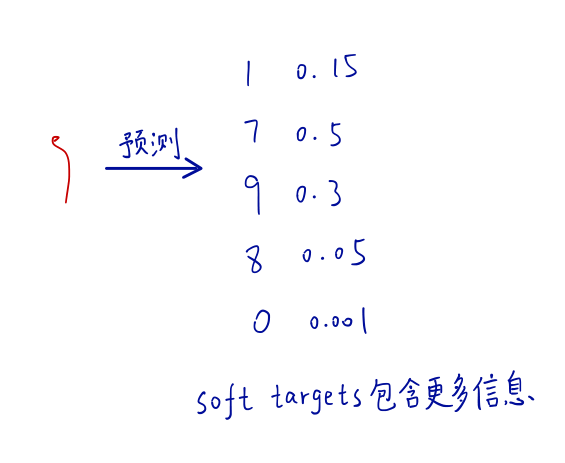
对于MNIST手写数据集,现在已经有了很多优秀的模型,我们使用这些优秀的模型进行训练,并使用他们的输出作为soft targets,从soft targets中可以看到不同数字之间包含更多信息。例如图中预测数字更像7和9,更不像0和8,因此我们可以得出一张2的图片多像3多像7
soft targets相对大小很重要,但在交叉熵中无法体现,因为很小的logit在softmax之后接近0,在一号文献中,直接使用了线性分类器输出的分数(softmax之前的分数),回避了上诉logit在softmax之后接近0的问题,使用大模型生成的logit和小模型生成的logit进行均方误差。我们提供了更普遍的解决方法,称之为“distillation”,提高softmax的“温度”,使其能够产生一组相对合适的“soft targets”。然后我们再使用相同的“温度”训练学生网络,让学生网络输出的soft target 和教师网络输出的soft target更相似。
知识蒸馏的另一个好处是对于transfer set可以使用未标注的数据,使用大量未标注或随机获取的图片进行教师网络的训练得到其“soft targets”,并训练学生网络。最后的loss使用soft-loss 和hard-loss加权求和,其中soft-loss相当于蒸馏loss,Yij在0-1区间且经过蒸馏,可以看作老师的言传身教,hart-loss(Ground Truth Loss),Yij非0既1,相当于课本和习题的学习。
2、Distillation
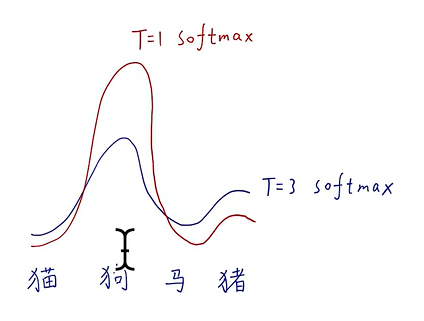
添加蒸馏温度T在原始softmax函数中:

温度T为1时,该式子等于原softmax函数,T越大每个类别之间的差别就越小:
添加温度T后的教师网络和学生网络训练、测试过程,其中使用温度T训练的时候,教师网络和学生网络的温度T相同,预测时不需要添加温度,使用原始softmax
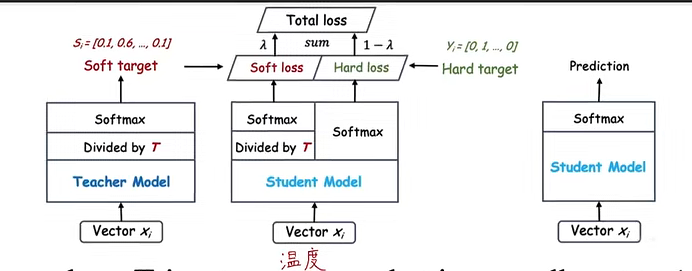
最后的总loss由soft-loss和hard-loss两部分组成,soft-loss是学生网络和教师网络使用相同的温度T蒸馏之后得到的soft targets求loss所得,hard-loss是有学生网络不进行蒸馏得到的结果和训练之前的hard targets求loss所得。
2.1 Matching logits is a special case of distillation
(一号文献中提到的直接让学生网络拟合教师网络输出的logit是知识蒸馏的特例)
计算交叉熵梯度:
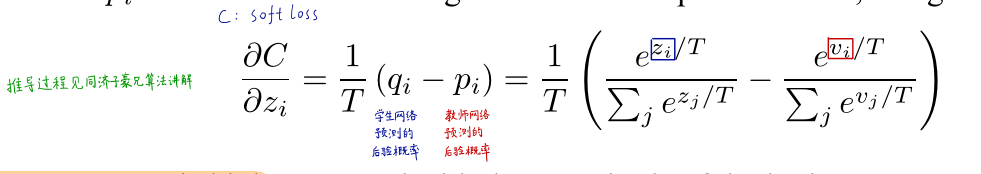
假设一、当温度T足够大时:
从Ex的泰勒展开式可以看出,当展开项足够大时,可以使用1+x代替Ex,因此式子可以转化为下面的式子
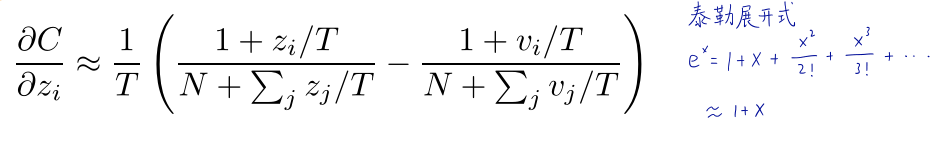
假设二、温度足够大,且不同样本logit的均值为0:
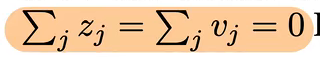
此时可以再将式子进行化简,去除期望值,
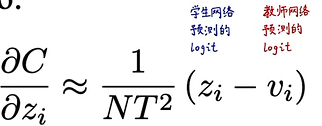
可以从假设2中看出,当温度足够大,不同样本logit均值为0时,知识蒸馏的式子就等价与均方误差,因此一号文献中提出的方法就是知识蒸馏的一种特例
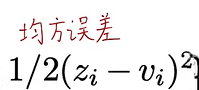
但是现实生活中的温度T并没有计算中这么理想,我们需要合适的温度T,
1)当蒸馏温度较高时,很小的logit也能被蒸馏出很高的softmax(泡沫来时猪也能飞),虽然传递有用信息,但是也带来噪声(泥沙俱下)。
2)当蒸馏温度较低时,很小的logit对应的softmax梯度再次变为0,传递不了有用信息。
因此温度T的大小选定需要根据实验和经验来定,中等合适的温度T才能使网络达到最好的效果。
3、Preliminary experiments on MNIST(小数据集预实验)
MNIST数据集被称为人工智能界的“果蝇”(果蝇在遗传学的很大著名理论中作为实验对象)
我们使用的教师网络具有两个隐藏层,每个隐藏层具有1200个ReLu函数的神经元,使用dropout防止过拟合,最后结果表现很好,只有67个识别出错。学生网络是具有两个隐藏层,每个隐藏层具有800个ReLu函数的神经元,不使用正则化,最后表现不太好,测试集中有146个出错。如果使用温度T为20,并使用教师网络的soft targets训练学生网络,该模型在测试集上只有74个出错。从该实验中可以看出,知识蒸馏会传递很多“知识”,甚至可以传递“平移不变性”(即图像进行平移后不影响卷积进行特征提取),学生网络未进行平移不变性相关训练就可以从教师网络哪里学习到这些“知识”,说明知识蒸馏具有“零样本学习”的作用
当蒸馏网络(学生网络)每层有300个神经元或不止两个隐藏层,蒸馏温度T大于8表现更好,如果网络变小,每个隐藏层只有30个神经元,蒸馏温度需要调整到2.5-4或者更低。
如果我们将训练学生网络的transfer set中的3的分类全部去掉,从学生网络的角度看,3这个类别是传说中的数字,它从来没有见到过,但是教师网络训练集中具有3这个分类。尽管如此,在最后的测试集中学生模型预测结果出错206个,其中3这个分类有133个,全部的3分类一共有1010个,表现效果比较好。之所以3分类的出错角度,是因为学生网络未学习过3,主要是通过偏置项修正学习,之前的偏置项相对于3太小,所以我们手动将3分类的偏置项调整为3.5,实验结果表示最后预测出现109个错误,其中3分类的错误占了14个。如果在transfer set中只保留7和8个分类,预测精度为47.3%,如果我们调整7和8的偏置项为7.6,最后的预测精度降低到了13.2%。
总结:transfer set中不包含哪一类,学生网络中该类偏置项低(需要手动调高),如果只包含哪些类,学生网络中这些类别的偏置项高(需要手动调低)
4、Experiments on speech recognition(语音识别)
本章节对表现好的语音模型Deep Neural Networl(DNN)进行知识蒸馏,发现可以非常好的将集成模型压缩为单个模型,比相同数据训练单独网络的效果好。
语音识别相关知识:
现在比较流行的方法是,使用深度神经网络(DNN)将一段语音中导出的时序上下文映射到隐马尔科夫模型上,更具体的讲,深度学习试讲tri-phone state转成了隐马尔科夫的状态链,语音识别(语音转文字)应尽可能即符合声音元素、也符合语言模型。
主要是优化该公式,其中Ht是输入标签,St是输出标签,让二者尽可能相似,并进行优化,该模型采用分布式梯度下降。
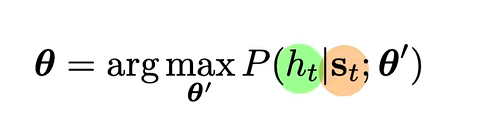
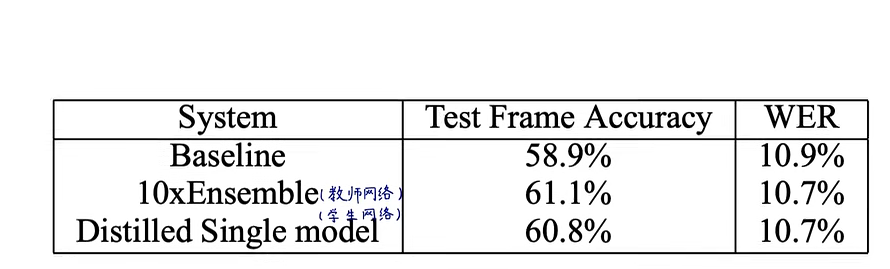
我们使用了一个包含8个隐藏层的架构,每个隐藏层包含2560个校正线性单元,最后一个softmax层包含14000个标签(HMM)。输入是40个Mel缩放滤波器组系数的26帧,每帧提前10毫秒,我们预测第21帧的HMM状态。参数总数约为85M。这是Android voice search使用的声学模型的一个稍微过时的版本,应该被视为一个非常强大的基线。为了训练DNN声学模型,我们使用了大约2000小时的英语口语数据,其中包括700M训练数据。该系统实现了58.9%的 frame accuracy 和10.9%的World Error Rate。
4.1 Results
我们训练了十个模型,都使用相同的结构和数据集,模型初始时进行随机初始化,并作为baseline,可以看出十个模型的结果要比单个模型效果好。蒸馏温度选择【1,2,5,10】,权重使用0.5,其中当蒸馏温度为2时,模型表现效果最好。
表一中展示的了蒸馏的方法能够将大模型的知识迁移给小模型,而且集成模型得到的提升几乎都可以被学生模型学习到,和MNIST数据集的实验结果相似。
八号文献也致力于将大的语音模型迁移到小模型上,但是他们使用的是T为1,且效果不好。
5、Trainingensembles of specialists on very big datasets(“专才”模型)(选修)
(soft targets用于训练冀衡学习的基学习器)
略
6、Soft Targets as Regularizers(选修)
略
7、Relationship to Mixtures of Experts(选修)
略
8、Discussion(总结)
我们已经表明知识蒸馏可以将一个很大的模型结构所包含的知识迁移到小模型上,在MNIST数据集上的实验可以看到在零样本学习上有较好的表现。在安卓语音识别模型上的训练,同样使用大模型训练小模型,最后小模型的表现效果也不错,蒸馏之后的小模型更方便部署。
对于真正的大型神经网络,即使训练一个完整的集合也是不可行的,但我们已经证明,通过学习大量的专家网络,每个专家网络都可以学习在高度易混淆的集群中区分不同的类,可以显著提高经过长期训练的单个真正大型网络的性能。我们还没有证明我们可以将专家们的知识提取回单一的大网络中。

















 1908
1908

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









