







 本文探讨了基于深度强化学习的移动机器人路径规划,提出改进的DDQN和IDDQN算法,以及ARPER经验池采样和迁移学习策略,以提升自主导航效率。
本文探讨了基于深度强化学习的移动机器人路径规划,提出改进的DDQN和IDDQN算法,以及ARPER经验池采样和迁移学习策略,以提升自主导航效率。
一、主要内容
移动机器人的关键技术是路径规划。路径规划技术要求移动机器人在存在障碍物的环境中,能够感知周围事物,并收集信息作为信源,从起始点到目标点,规划出一条不发生碰撞且线路最优的路径。因此。如何使移动机器人在不同的环境下,自主避开障碍物的同时,能够省时高效的到达目标点,是目前机器人自主导航路径规划的研究热点和重要问题。 基于深度强化学习 DRL 的机器人决策控制是人工智能时代下的产物,是机器人自主移动研究中的前沿方向,在研究中取得的成果对于智能机器人的自主导航具有重要的研究意义。本文利用深度强化学习技术对移动机器人路径规划算法问题展开研究,所做内容为未来机器人领域的发展提供了一定的理论意义和应用价值。
重点内容:基于 DRL 的路径规划算法设计与改进。主要对基于深度强化学习的深度Q 网络进行设计与改进,针对深度 Q 网络过估计问题,选取 DDQN 网络,经过解耦动作选择与动作评估后,为了进一步减缓过估计的问题,提出了 IDDQN 算法,采用优化目标的动作选取策略,改善目标选取 max 的激进操作。接着对于经验池的采样机制做出优化改进,提出了 ARPER 经验池采样机制,设置经验样本进入经验池的基准线,对经验样本进行重新排序,提高优秀样本的采集频率。最后提出了将迁移学习策略引入到所改进的算法训练中,将相同任务在不同环境进行迁移训练,降低数据收集复杂度,来减少训练所需要的时间。
二、仿真与核心优化过程
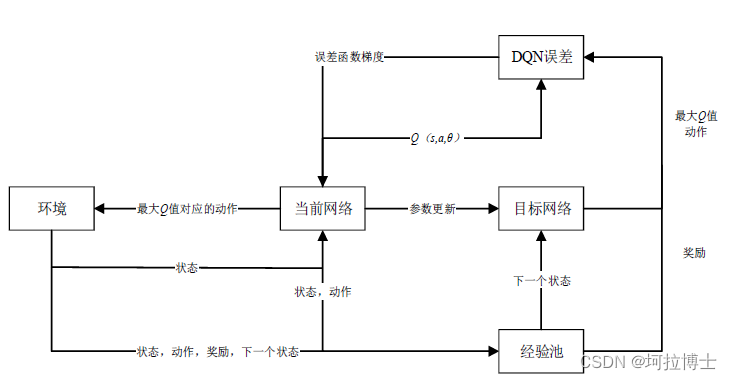
网络设计
超参数设置:初始化缓存容量𝑁,折扣因子𝛾,步长为𝐶
输入:初始化 𝐷, 𝑄
for 每一个回合do
初始化环境并获取观测数据𝑆0,对序列预处理𝜙0 = 𝜙(𝑆0)
for 每一个在现有的回合do
通过概率 𝜀选择动作𝐴𝑡
𝐴𝑡 = 𝑚𝑎𝑥
𝑎
𝑄(𝛷(𝑆𝑡 ), 𝑎; 𝜃) 最大 𝑄 值对应的动作
执行𝐴𝑡获得数据、奖励数据𝑅𝑡
if 回合结束, 𝐷𝑡 = 1𝑒𝑙𝑠𝑒𝐷𝑡 = 0
𝑆𝑡+1 = {𝑆𝑡 , 𝐴𝑡 } 并进行预处理 𝜙𝑡+1 = 𝜙(𝑆𝑡+1)
存储状态转移数据(𝜙𝑡 , 𝐴𝑡 , 𝑅𝑡 , 𝐷𝑡 , 𝜙𝑡+1)进𝐷
在 (𝑌𝑖 − 𝑄(𝜙𝑖, 𝐴𝑖 ; 𝜃))
2
上对 𝜃 执行梯度下降步骤。
每𝐶步对目标网络𝑄−进行同步
If epsiod 溢出 break
end for
end for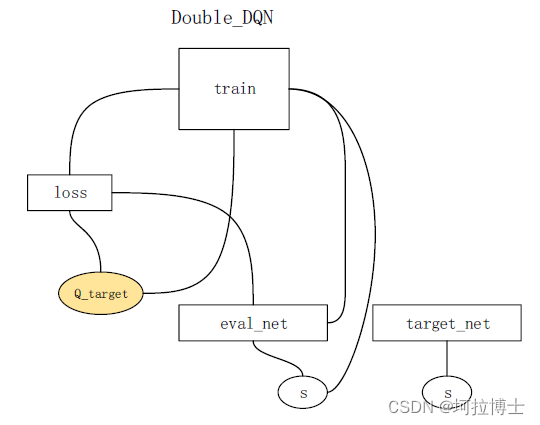
算法总体流程
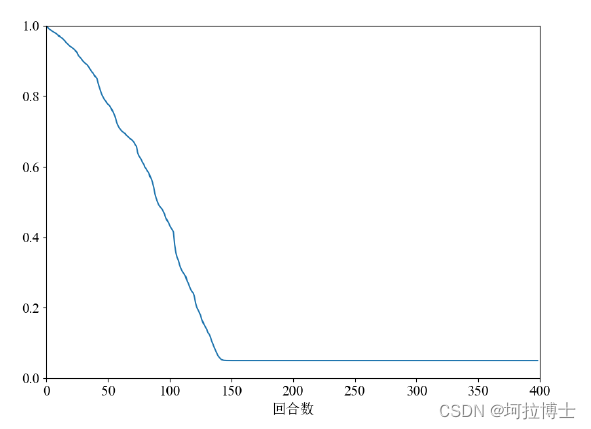
初步参数的确认
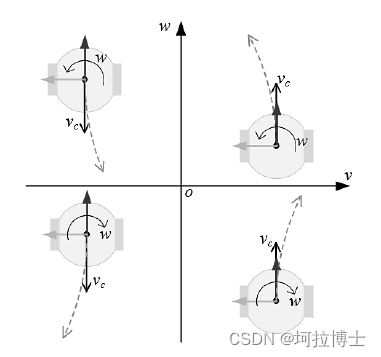
机器人坐标
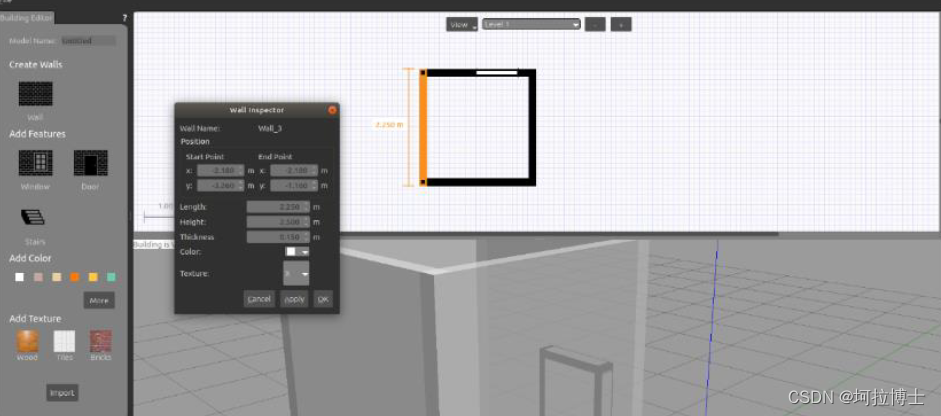
仿真过程

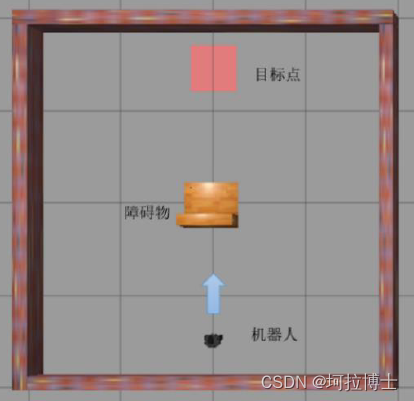
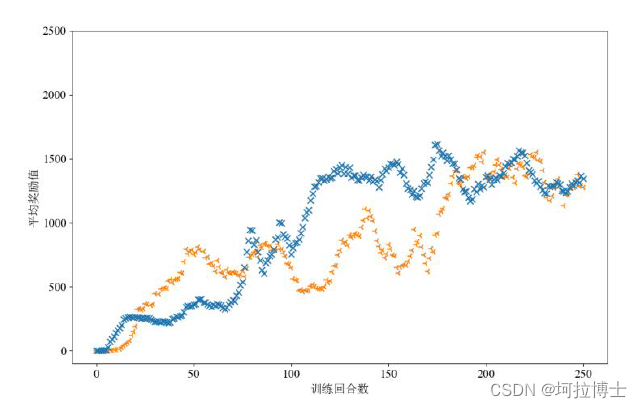
优化前后算法对比


















 1706
1706

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











