







深入探索深度学习:RNN, LSTM, 和 GRU 的魔力
引言
随着深度学习技术的不断进步,它已成为当今人工智能领域最激动人心的进展之一。尤其在处理复杂的序列数据时,循环神经网络(RNN)及其衍生模型长短期记忆网络(LSTM)和门控循环单位(GRU)展现出了其独特的能力。这些模型能够捕捉时间序列数据中的长距离依赖关系,被广泛应用于语音识别、自然语言处理、时间序列预测等多个领域。本文将深入探讨RNN, LSTM, 和GRU的工作原理、它们之间的区别以及在实际应用中的表现。
循环神经网络(RNN)
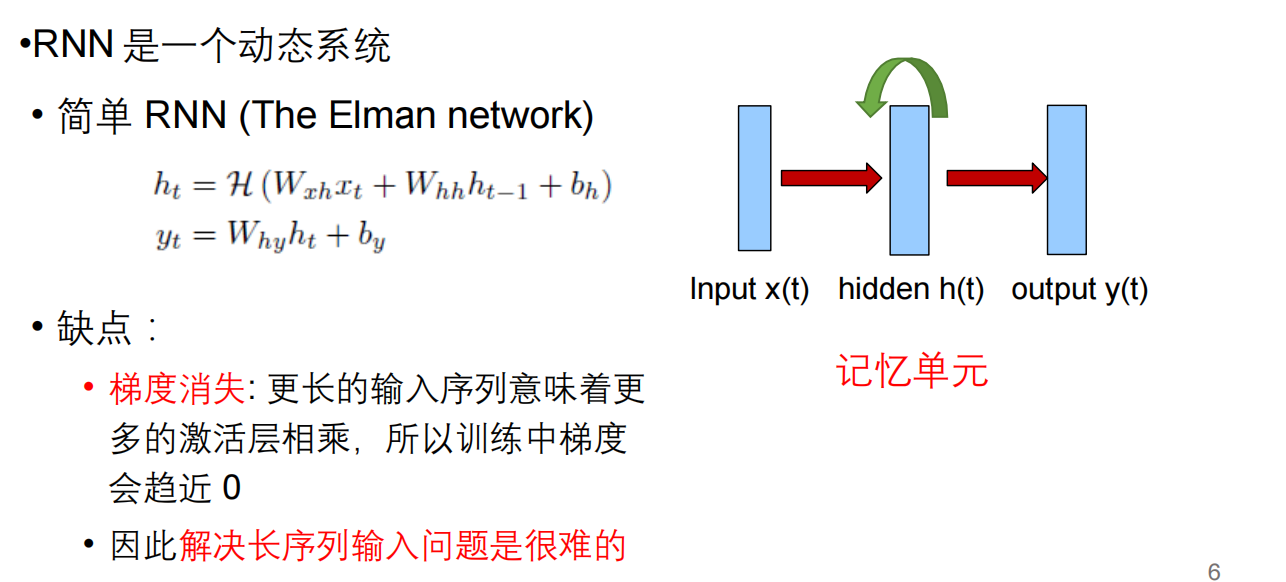
循环神经网络(RNN)是深度学习中的一种重要网络结构,专为处理序列数据设计。它通过在神经网络的隐藏层引入循环来使得信息能够在序列的不同时间步之间传递。这种结构使RNN能够在每个时间步考虑到之前的信息,理论上能够捕捉序列中的长期依赖关系。然而,标准RNN在实际应用中面临梯度消失和爆炸的问题,限制了其捕捉长距离依赖的能力。
长短期记忆网络(LSTM)
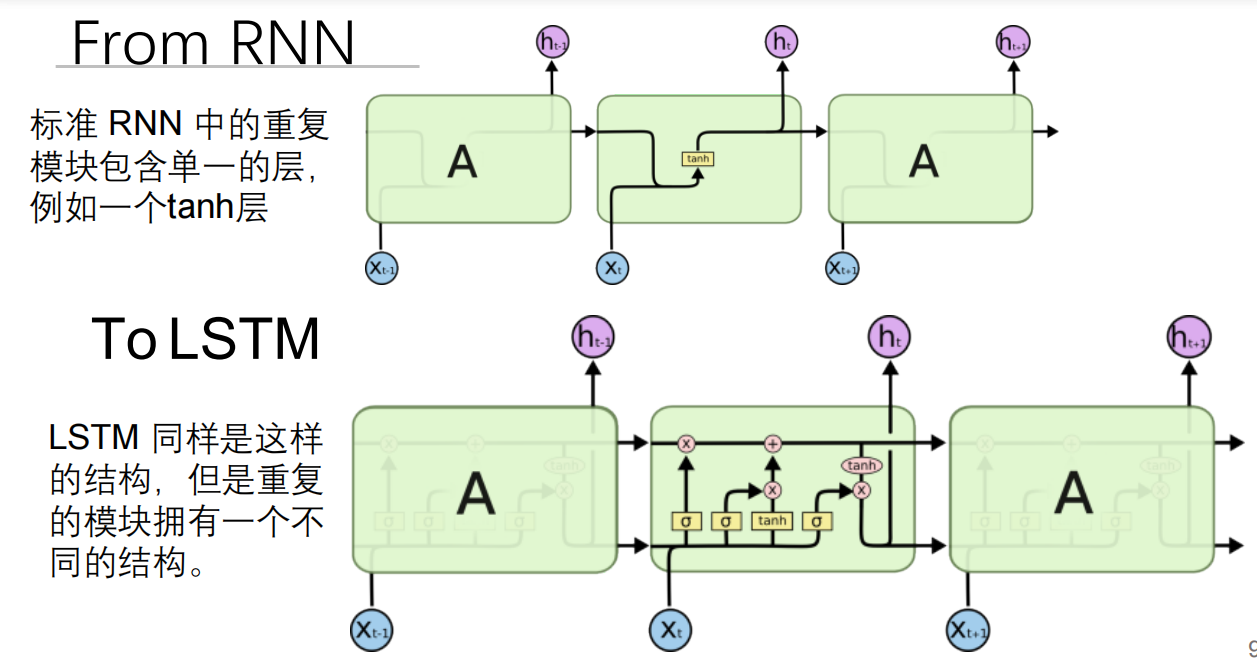
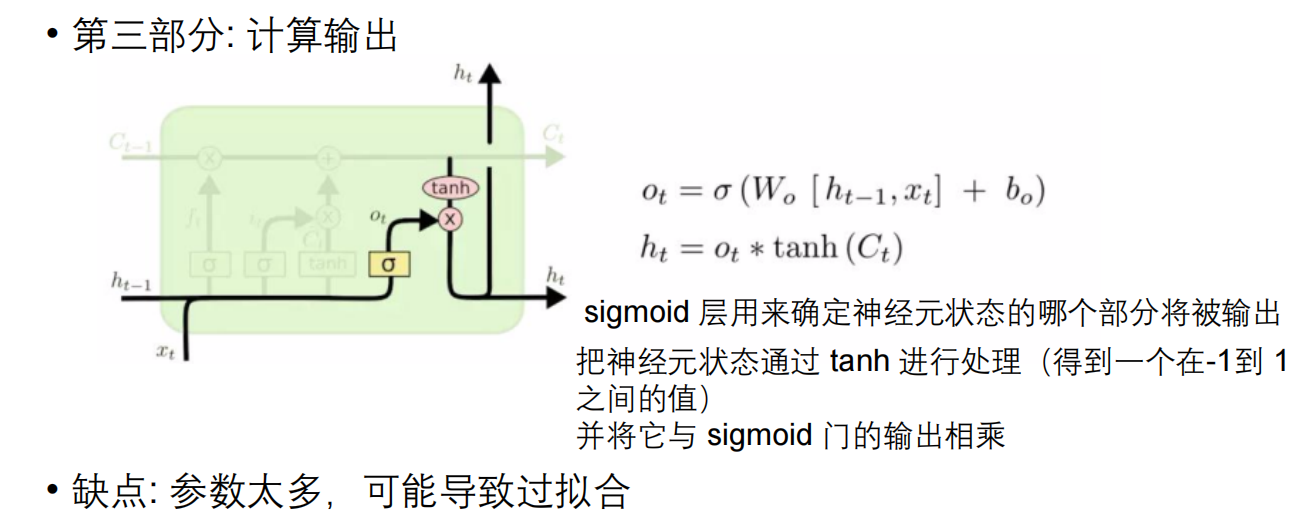
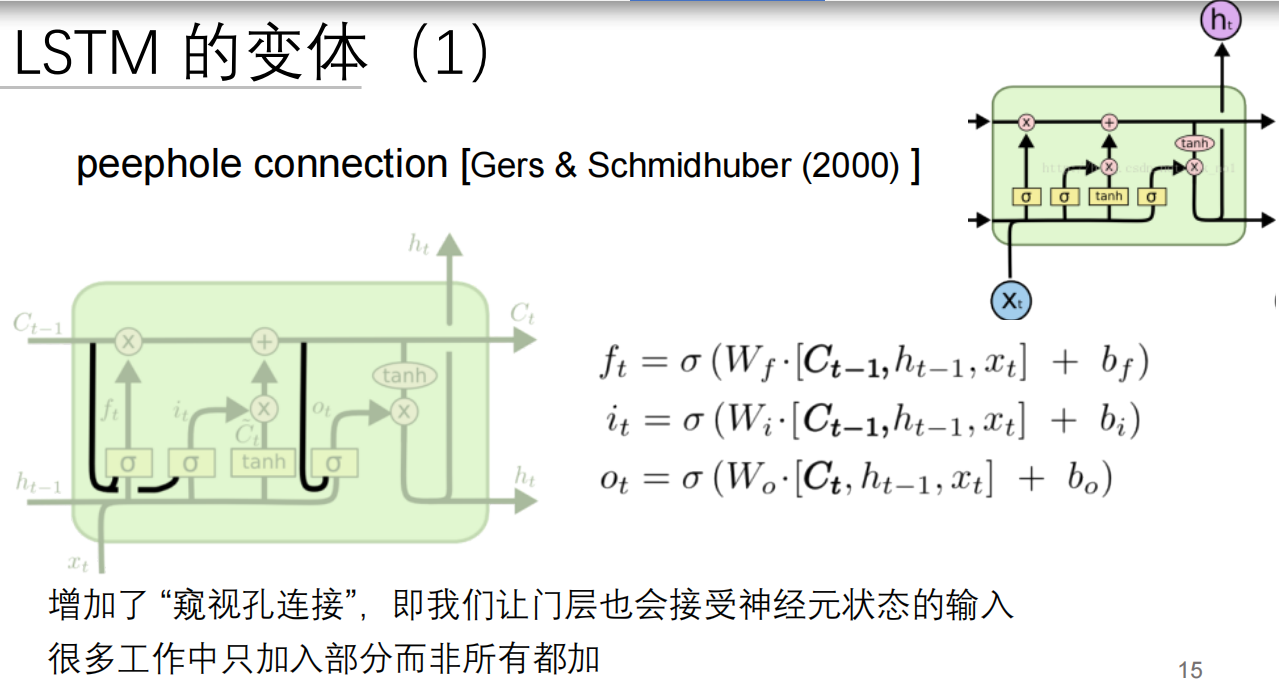
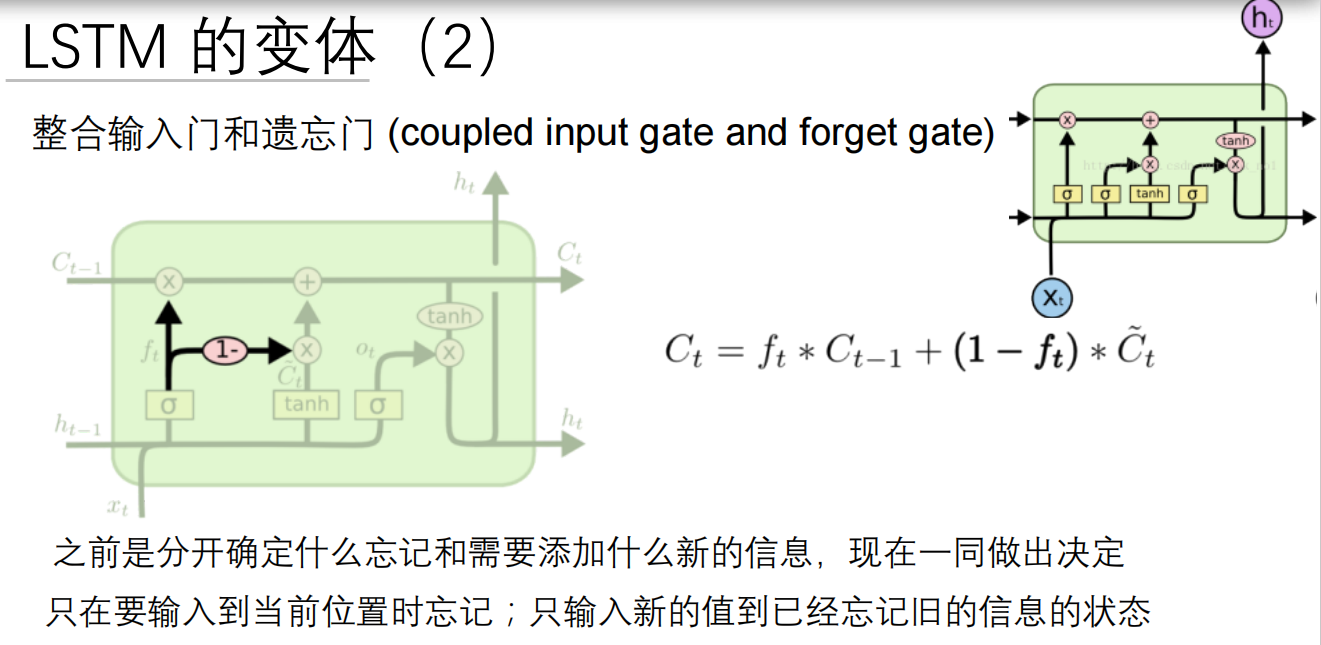
LSTM通过引入三个门(遗忘门、输入门和输出门)和一个细胞状态来解决RNN面临的梯度消失问题,从而有效地保持和传递长期信息。这些门的结构允许模型学习在处理输入序列时保留什么信息、丢弃什么信息以及在每个时间步输出什么信息,使得LSTM能够在更长的序列中有效地学习到长期依赖关系。
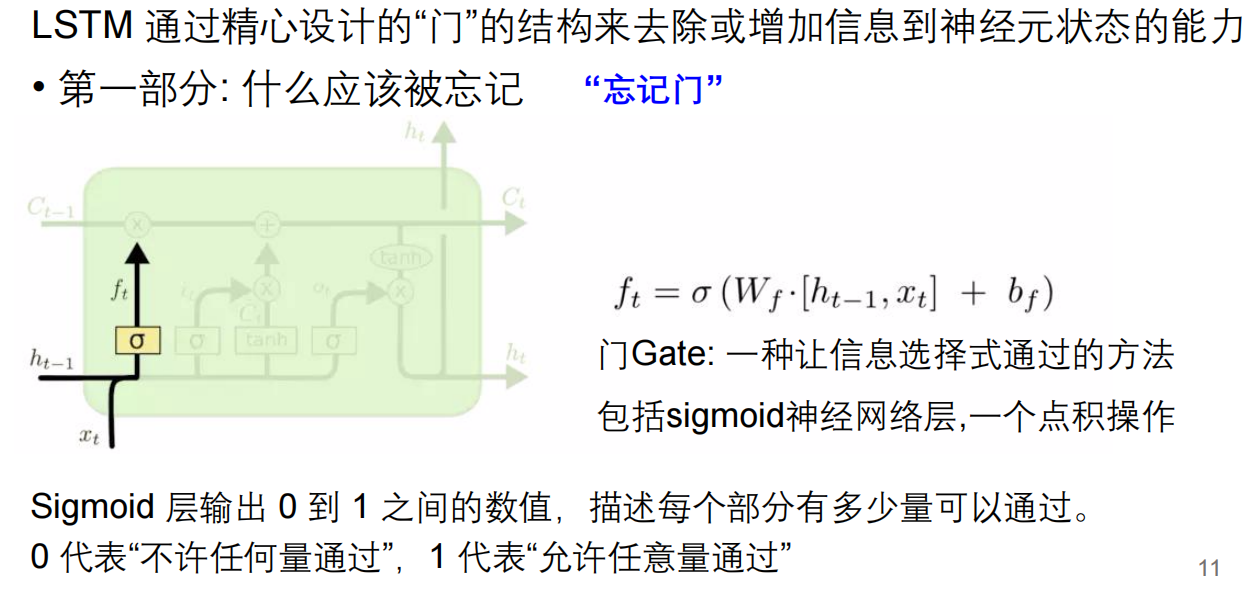
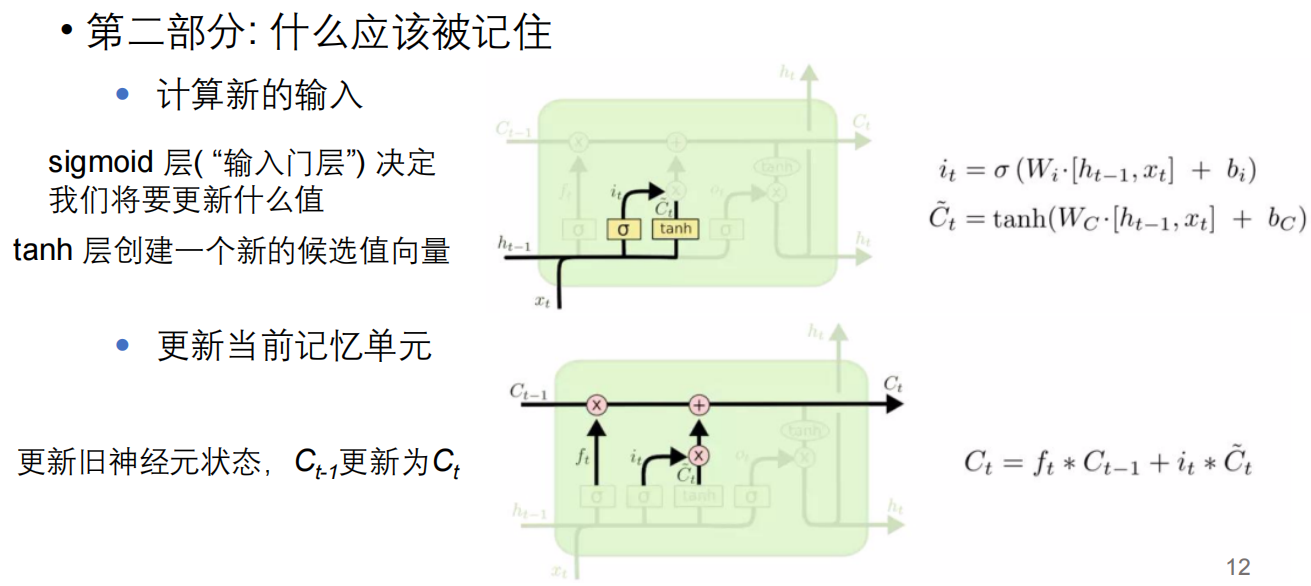
门控循环单位(GRU)
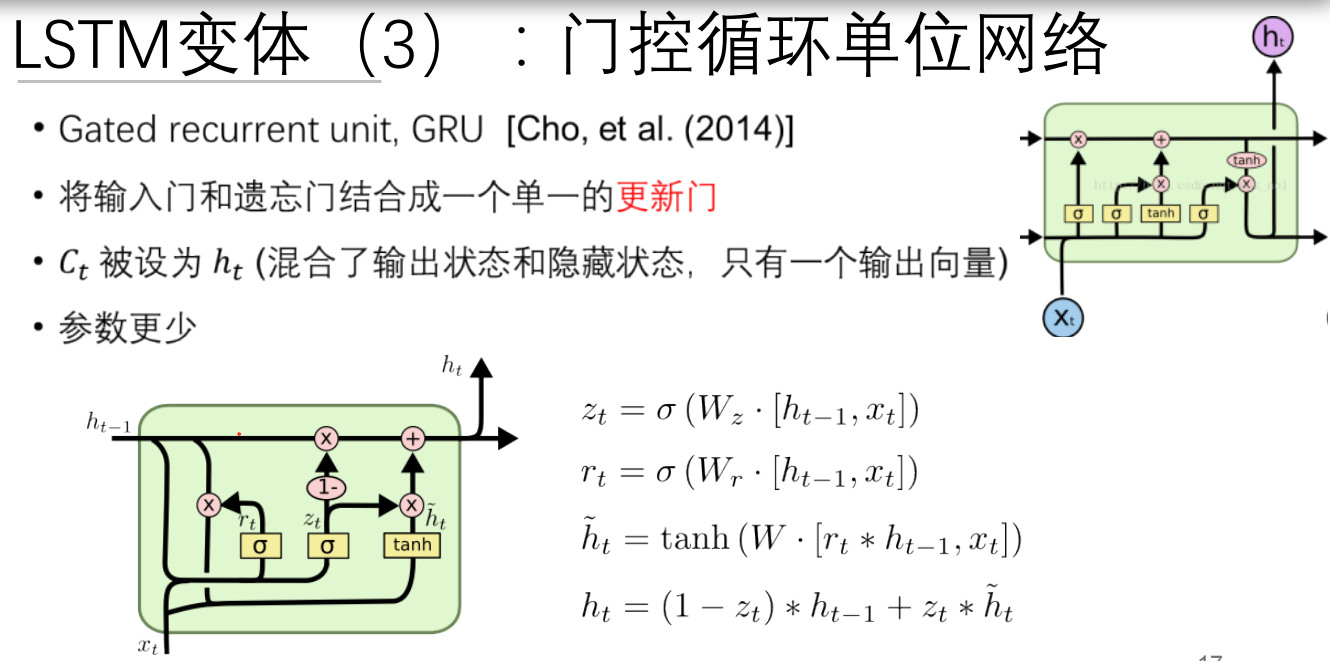
GRU是对LSTM的简化,它将LSTM中的遗忘门和输入门合并为一个单一的更新门,并合并了细胞状态和隐藏状态,简化了模型的复杂度。这种简化虽然减少了模型的灵活性,但在很多任务中GRU和LSTM展现出了相似的性能,同时由于其结构更为简单,训练速度往往更快,参数更少。
应用举例
- 语音识别:LSTM和GRU被广泛用于语音识别系统中,它们能够处理音频信号的序列性质,识别语音中的长期依赖模式。
-
- 自然语言处理:在自然语言处理(NLP)领域,如机器翻译、文本摘要、情感分析等任务中,LSTM和GRU能够捕捉文本数据中的语义流和上下文信息。
- 时间序列预测:在金融市场分析、气象预测等领域,RNN及其变体因其能够处理时间序列数据的特点而被广泛应用。
总结
RNN及其变体LSTM和GRU在处理序列数据方面的强大能力,使得它们在许多实际应用中成为不可或缺的工具。尽管存在计算成本高和模型解释性差等挑战,但随着研究的深入和技术的进步,深度学习社区正在不断探索优化这些网络的新方法。未来,我们可以期待这些模型在更多领域内的应用,以及在性能和效率上的进一步提升.
在线资源
深入学习深度学习技术不仅需要理论知识,也需要实践经验。以下是一些优秀的在线资源,可以帮助你开始或加深你对深度学习的了解。
-
网站: Deep Learning - 提供深度学习相关的最新研究、教程和案例研究。
-
阅读材料: 提供关于深度学习基础和高级主题的综合阅读列表,适合初学者和进阶学习者。
-
软件工具:
- Theano @ University of Montreal: 一个强大的Python库,允许你以高效的方式定义、优化和评估数学表达式,特别是有大量的多维数组。
- Caffe @ UC Berkley: 一个清晰和高效的深度学习框架,特别适合图像处理和计算机视觉任务。
- Tensorflow by Google: 一个开源软件库,用于高性能数值计算,广泛应用于构建机器学习模型。
- Torch by Facebook: 提供了一个丰富的库集合,用于机器学习、计算机视觉、信号处理、并行处理、图像、视频、音频和网络处理。
- Deeplearning4j: 一款适用于Java和JVM的商业级开源、分布式深度学习库。



















 263
263

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











