









欢迎关注更多精彩
关注我,学习常用算法与数据结构,一题多解,降维打击。
问题描述
给定1个数组,利用gpu求和并返回结果。
cpu 算法
#include <math.h>
#include<vector>
#include<time.h>
#include <stdio.h>
using namespace std;
#define BLOCK_SIZE 1024
#define N (102300 * 1024)
int arr[N];
void cpu_sum(int *in, int&out) {
out = 0;
for (int i = 0; i < N; ++i) {
out += in[i];
}
}
int main()
{
float time_cpu, time_gpu;
for (int y = 0; y < N; ++y) {
arr[y] = y;
}
int cpu_result = 0;
auto b = clock();
cpu_sum(arr, cpu_result);
time_cpu = clock() - b;
printf("CPU result: %d, CPU time: %.3f\n", cpu_result, time_cpu);
return 0;
}
cpu耗时
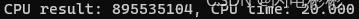
耗时20毫秒
gpu 算法
算法过程
- 先对数据分成1024*1024组,每组用1个线程进行汇总。
- 再把线程分成1024组,每组1024个,组内用共享内存进行快速求和。
- 将每组结果汇总。
共享内存求和过程:
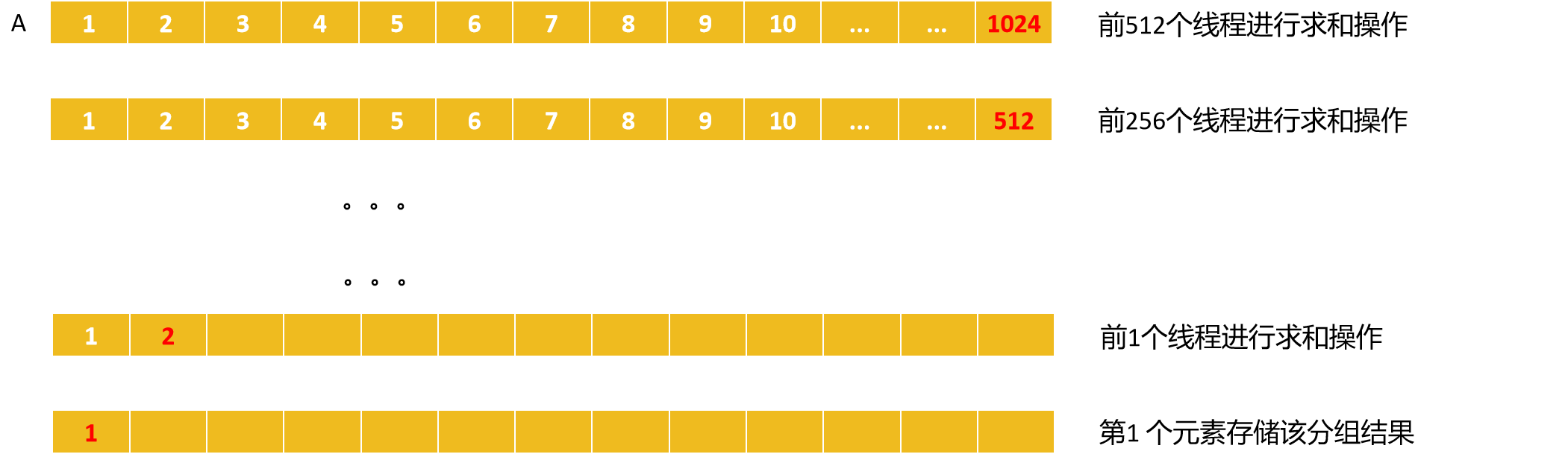
设数组A为共享内存,共享内存有大小限制,一共1024个元素。
每次由前一半的线程进行操作。
第1次由前512个线程进行求和,结果放入前512个元素中。
第2次再缩减一半,直到剩下1个元素。
for(int s = 1024/2;s;s>>=1) { // s代表当前多个线程有计算作用
if(tid<s)// tid代表当前线程号
A[tid]+=A[tid+s];
}
代码
#include "cuda_runtime.h"
#include<vector>
#include "device_launch_parameters.h"
#include <stdio.h>
using namespace std;
cudaError_t addWithCuda(vector<int> &a, vector<int> &sum);
__global__ void addKernel(int *dev_a, int *dev_out)
{
int myId = threadIdx.x + blockDim.x*blockIdx.x;
atomicAdd(dev_out, dev_a[myId]);
}
__global__ void addKernel_sheard(int *dev_a, int *dev_out, int len)
{
extern __shared__ int sdata[];
int myId = threadIdx.x + blockDim.x*blockIdx.x;
int tid = threadIdx.x;
sdata[tid] = 0;
for (myId; myId < len; myId += blockDim.x*gridDim.x) sdata[tid] += dev_a[myId];
__syncthreads();
for (unsigned int s = blockDim.x / 2; s > 0; s >>= 1) {
if (tid < s) {
sdata[tid] += sdata[tid + s];
}
__syncthreads();
}
if (tid == 0) {
atomicAdd(dev_out, sdata[0]);
}
}
int main()
{
vector<int> a(102300 * 1024);
vector<int> sum(1024, 0);
int s = 0;
for (int i = 0; i < 102300 * 1024; ++i)
{
s += i;
a[i] = i;
}
fprintf(stderr, "%d\n", s);
// Add vectors in parallel.
cudaError_t cudaStatus = addWithCuda(a, sum);
if (cudaStatus != cudaSuccess) {
fprintf(stderr, "addWithCuda failed!");
return 1;
}
cudaStatus = cudaDeviceReset();
if (cudaStatus != cudaSuccess) {
fprintf(stderr, "cudaDeviceReset failed!");
return 1;
}
s = 0;
for (auto n : sum)s += n;
fprintf(stderr, "%d\n", s);
return 0;
}
// Helper function for using CUDA to add vectors in parallel.
cudaError_t addWithCuda(vector<int> &a, vector<int> &sum)
{
int *dev_a = 0;
int *dev_out = 0;
cudaError_t cudaStatus;
// Choose which GPU to run on, change this on a multi-GPU system.
cudaStatus = cudaSetDevice(0);
if (cudaStatus != cudaSuccess) {
fprintf(stderr, "cudaSetDevice failed! Do you have a CUDA-capable GPU installed?");
goto Error;
}
// Allocate GPU buffers for three vectors (two input, one output) .
cudaStatus = cudaMalloc((void**)&dev_a, a.size() * sizeof(int));
if (cudaStatus != cudaSuccess) {
fprintf(stderr, "cudaMalloc failed!");
goto Error;
}
cudaStatus = cudaMalloc((void**)&dev_out, sum.size() * sizeof(int));
if (cudaStatus != cudaSuccess) {
fprintf(stderr, "cudaMalloc failed!");
goto Error;
}
// Copy input vectors from host memory to GPU buffers.
cudaStatus = cudaMemcpy(dev_a, a.data(), a.size() * sizeof(int), cudaMemcpyHostToDevice);
if (cudaStatus != cudaSuccess) {
fprintf(stderr, "cudaMemcpy failed!");
goto Error;
}
cudaStatus = cudaMemcpy(dev_out, sum.data(), sum.size() * sizeof(int), cudaMemcpyHostToDevice);
if (cudaStatus != cudaSuccess) {
fprintf(stderr, "cudaMemcpy failed!");
goto Error;
}
// Launch a kernel on the GPU with one thread for each element.
for (int i = 0; i < 1; ++i)addKernel_sheard << <1024, 1024, 1024 * sizeof(int) >> > (dev_a, dev_out, a.size());
// Check for any errors launching the kernel
cudaStatus = cudaGetLastError();
if (cudaStatus != cudaSuccess) {
fprintf(stderr, "addKernel launch failed: %s\n", cudaGetErrorString(cudaStatus));
goto Error;
}
// cudaDeviceSynchronize waits for the kernel to finish, and returns
// any errors encountered during the launch.
cudaStatus = cudaDeviceSynchronize();
if (cudaStatus != cudaSuccess) {
fprintf(stderr, "cudaDeviceSynchronize returned error code %d after launching addKernel!\n", cudaStatus);
goto Error;
}
// Copy output vector from GPU buffer to host memory.
cudaStatus = cudaMemcpy(sum.data(), dev_out, sum.size() * sizeof(int), cudaMemcpyDeviceToHost);
if (cudaStatus != cudaSuccess) {
fprintf(stderr, "cudaMemcpy failed!");
goto Error;
}
Error:
cudaFree(dev_a);
cudaFree(dev_out);
return cudaStatus;
}
耗时分析
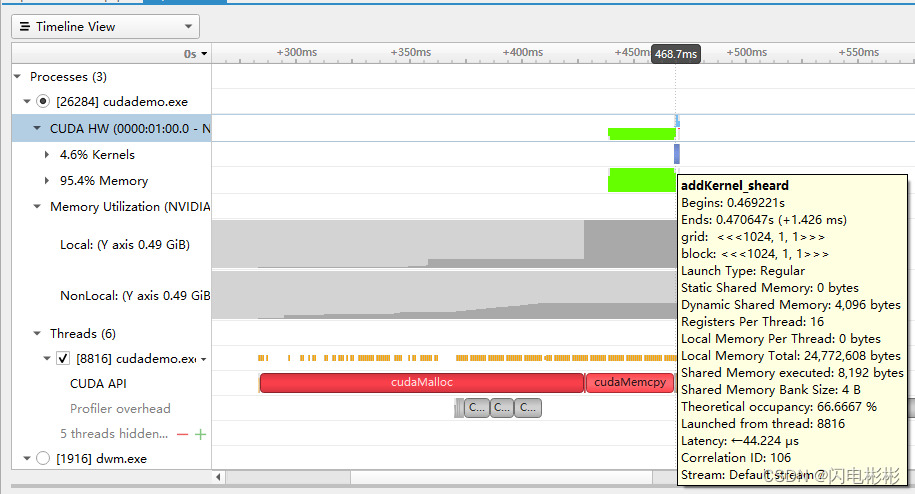
耗时1.4毫秒,提升了10多倍。
本人码农,希望通过自己的分享,让大家更容易学懂计算机知识。创作不易,帮忙点击公众号的链接。
















 2170
2170











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









