







1、主要参考
(1)大佬写的很好
https://www.jianshu.com/p/24376b18e5c7
(2)二分类和多分类大佬写的很好
交叉熵损失函数_沙子是沙子的博客-CSDN博客_交叉熵损失函数
二分类交叉熵,多分类交叉熵,focal loss_jzdl的博客-CSDN博客_二分类交叉熵
(3)二分类的定义和实现
(4)softmax和sigmod的关系见下面,写得很好
Softmax和Sigmoid函数的区别_ciki_tang的博客-CSDN博客_softmax和sigmoid
(5)其它概念参考
2、什么是熵
参考某度
https://baike.baidu.com/item/%E7%86%B5/19190273?fr=aladdin
(1)熵 [shāng],(英语:entropy)。泛指某些物质系统状态的一种量度,某些物质系统状态可能出现的程度。熵的概念是由德国物理学家克劳修斯于1865年提出。1923年,德国科学家普朗克(Planck)来中国讲学用到"entropy"这个词,胡刚复教授翻译时灵机一动,把“商”字加火旁来意译“entropy”这个字,创造了“熵”字(拼音:shāng)。
(2)1948年,香农将统计物理中熵的概念,引申到信道通信的过程中,从而开创了”信息论“这门学科。香农定义的“熵”又被称为“香农熵”或“信息熵”,即
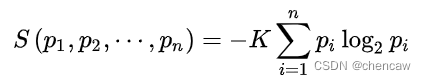
其中 i 标记概率空间中所有可能的样本,pi 表示该样本的出现几率,K是和单位选取相关的任意常数。
(3)上述公式中,如果i有32个取值范围,假设其中,p1,p2 , ...,p32 分别是这 32 个球队夺冠的概率。
S = -(p1*log(2,p1) + p2 * log(2,p2) + ... +p32 *log(2,p32))
注意:当所有样本等几率出现的情况下,熵达到最大值。
3、Sigmoid函数和二分类交叉熵
3.1 sigmoid函数
(1)sigmoid的函数如下图所示
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 2573
2573











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









