






前言:
本篇主要讲两个WGAN的两个例子:
1 高斯混合模型 WGAN实现

2 MNIST 手写数字识别 -WGAN 实现

WGAN 训练起来蛮麻烦的,如果要获得好的效果很多超参数需要手动设置
1: 噪声的维度
2: 学习率
3: 生成器,鉴别器网络模型
4: batchsz,num_epochs
目录:
- Google Colab
- 损失函数
- 高斯混合模型(WGAN 实现)
- MNIST 手写数字识别(WGAN 实现)
一 Google Colab
1.1 : 打开google 云盘
https://drive.google.com/drive/my-drive
1.2: 新建 wgan.ipynb 文件
把对应的python 脚本拖在该目录下面
1.3:打开colab
https://colab.research.google.com/drive/
新建笔记
1.4: 在colab 中运行 main.py
from google.colab import drive
import os
drive.mount('/content/drive')
os.chdir('/content/drive/My Drive/wgan.ipynb/')
%run main.py

二 WGAN 损失函数

2.1 Wasserstein 约束和 WGAN 的约束条件转换原理
我们知道WGAN 是根据Wasserstein Distance 推导出来的。
Wasserstein Distance 原始约束关系为
只要满足k-Lipschitz 约束条件,肯定可以满足原始的约束条件。
证明如下:

这种约束关系很难求解,一般采用Weight Clipping 或者 Gradient penalty 两种方案
来约束.
2.2 Weight Clipping
这是一种工程经验,无理论基础
1-Lipschitz 约束条件为:
一张1024*1024的灰度图,其状态变量为,要让所有的状态组合满足该约束条件
没有办法求解。早期的解决方案是做weight Clipping
在利用 gradient descent 进行参数更新后,在对所有参数进行如下操作:
通过约束w 范围,来约束 输出范围,效果比较好。

2.3 Gradient penalty
这是一种工程经验,无严格理论基础


问题:
weight clipping会导致很容易一不小心就梯度消失或者梯度爆炸。原因是判别器是一个多层网络,如果我们把clipping threshold设得稍微小了一点,每经过一层网络,梯度就变小一点点,多层之后就会指数衰减;反之,如果设得稍微大了一点,每经过一层网络,梯度变大一点点,多层之后就会指数爆炸。只有设得不大不小,才能让生成器获得恰到好处的回传梯度,然而在实际应用中这个平衡区域可能很狭窄,就会给调参工作带来麻烦

三 高斯混合模型(WGAN 实现)
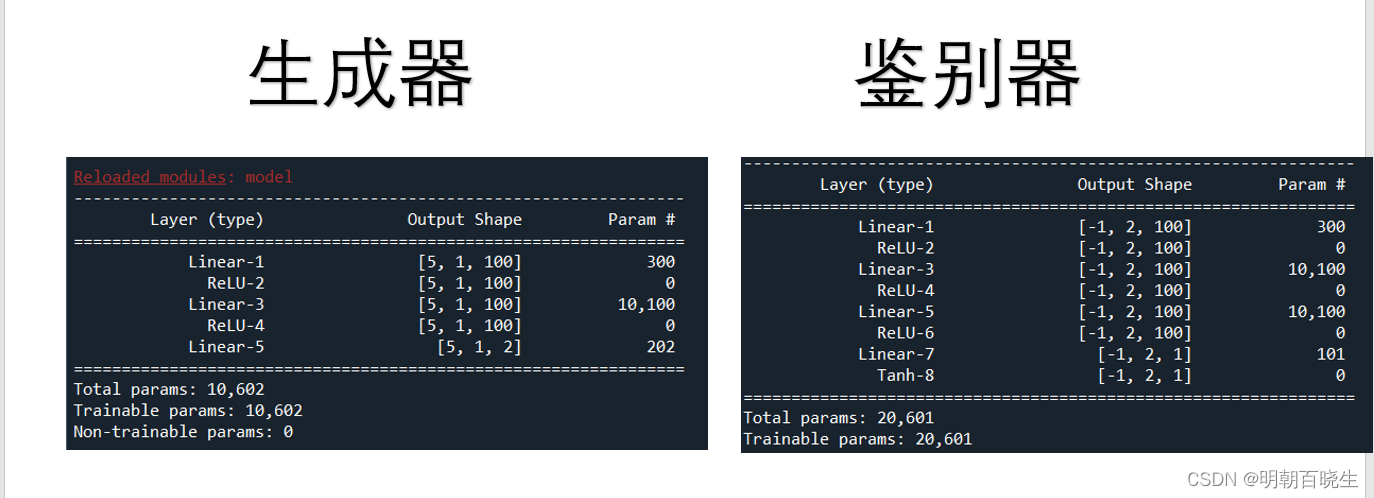
3.1 模型部分代码
model.py
# -*- coding: utf-8 -*-
"""
Created on Tue Mar 19 10:50:31 2024
@author: chengxf2
"""
import torch
from torch import nn
import random #numpy 里面的库
from torchsummary import summary
class Generator(nn.Module):
def __init__(self,z_dim=2,h_dim=400):
super(Generator, self).__init__()
#z:[batch, z_dim]
self.net = nn.Sequential(
nn.Linear(z_dim, h_dim),
nn.ReLU(True),
nn.Linear(h_dim, h_dim),
nn.ReLU(True),
nn.Linear(h_dim, 2)
)
def forward(self, z):
#print("\n input.shape",z.shape)
output = self.net(z)
return output
class Discriminator(nn.Module):
def __init__(self,input_dim,h_dim):
super(Discriminator,self).__init__()
self.net = nn.Sequential(
nn.Linear(input_dim, h_dim),
nn.ReLU(True),
nn.Linear(h_dim, h_dim),
nn.ReLU(True),
nn.Linear(h_dim, h_dim),
nn.ReLU(True),
nn.Linear(h_dim, 1),
nn.Tanh()
)
def forward(self, x):
out = self.net(x)
return out.view(-1)
def model_summary():
device = torch.device('cuda:0' if torch.cuda.is_available() else 'cpu')
#[channel, w,h]
#summary(model=net, input_size=(3,32,32),batch_size=2, device="cpu")
summary(Generator(2,100).to(device), (1,2,),batch_size=5)
print(Generator(100))
print("\n 鉴别器")
summary(Discriminator(2,100).to(device) , (2,2))
3.2 训练部分代码
main.py
# -*- coding: utf-8 -*-
"""
Created on Tue Mar 19 11:06:37 2024
@author: chengxf2
"""
import torch
from torch import autograd,optim,autograd
import numpy as np
import visdom
import random
from model import Generator,Discriminator
import visdom
import matplotlib.pyplot as plt
batchsz = 512
H_dim = 400
viz = visdom.Visdom()
device = torch.device('cuda:0' if torch.cuda.is_available() else 'cpu')
def data_generator():
#8个高斯分布的中心点
scale = 2
centers = [
(1, 0),
(-1, 0),
(0, 1),
(0, -1),
(1. / np.sqrt(2), 1. / np.sqrt(2)),
(1. / np.sqrt(2), -1. / np.sqrt(2)),
(-1. / np.sqrt(2), 1. / np.sqrt(2)),
(-1. / np.sqrt(2), -1. / np.sqrt(2))
]
# 放大一下
centers = [(scale * x, scale * y) for x, y in centers]
while True:
dataset = []
for i in range(batchsz):
#随机生成一个点
point = np.random.randn(2) * 0.02
#随机选择一个高斯分布
center = random.choice(centers)
#N(0,1)+center (x,y)
point[0] += center[0]
point[1] += center[1]
dataset.append(point)
dataset = np.array(dataset).astype(np.float32)
dataset /= 1.414
yield dataset
def generate_image(D, G, xr, epoch):
"""
Generates and saves a plot of the true distribution, the generator, and the
critic.
"""
N_POINTS = 128
RANGE = 3
plt.clf()
points = np.zeros((N_POINTS, N_POINTS, 2), dtype='float32')
points[:, :, 0] = np.linspace(-RANGE, RANGE, N_POINTS)[:, None]
points[:, :, 1] = np.linspace(-RANGE, RANGE, N_POINTS)[None, :]
points = points.reshape((-1, 2))
# (16384, 2)
# print('p:', points.shape)
# draw contour
with torch.no_grad():
points = torch.Tensor(points).to(device) # [16384, 2]
disc_map = D(points).to(device).numpy() # [16384]
x = y = np.linspace(-RANGE, RANGE, N_POINTS)
cs = plt.contour(x, y, disc_map.reshape((len(x), len(y))).transpose())
plt.clabel(cs, inline=1, fontsize=10)
plt.colorbar()
# draw samples
with torch.no_grad():
z = torch.randn(batchsz, 2).to(device) # [b, 2]
samples = G(z).to(device).numpy() # [b, 2]
plt.scatter(xr[:, 0], xr[:, 1], c='green', marker='.')
plt.scatter(samples[:, 0], samples[:, 1], c='red', marker='+')
viz.matplot(plt, win='contour', opts=dict(title='p(x):%d'%epoch))
def gradient_penalty(D,xr,xf):
LAMBDA = 0.2
t = torch.rand(batchsz,1).to(device)
#[b,1]=>[b,2]
t = t.expand_as(xf)
#interpolation
mid = t*xr+(1-t)*xf
#需要对 mid 求导
mid.requires_grad_()
pred = D(mid)
grad = autograd.grad(outputs=pred,
inputs= mid,
grad_outputs= torch.ones_like(pred) ,
create_graph= True,
retain_graph = True,
only_inputs=True)[0]
gp = torch.pow((grad.norm(2, dim=1)-1),2).mean()
return gp*LAMBDA
def gen():
## 读取模型
z_dim=2
h_dim=400
model = Generator(z_dim,h_dim ).to(device)
state_dict = torch.load('Generator.pt')
model.load_state_dict(state_dict)
model.eval()
z = torch.randn(batchsz, 2).to(device)
#tf.stop_graident()
xf = model(z)
print(xf)
def main():
z_dim=2
h_dim=400
input_dim =2
np.random.seed(23)
num_epochs = 2
data_iter = data_generator()
torch.manual_seed(23)
G = Generator(z_dim,h_dim ).to(device)
D = Discriminator(input_dim, h_dim).to(device)
#print(G)
#print(D)
optim_G = optim.Adam(G.parameters(), lr = 5e-4, betas =(0.5,0.9))
optim_D = optim.Adam(D.parameters(), lr = 5e-4, betas =(0.5,0.9))
viz.line([[0,0]], [0], win='loss', opts=dict(title='loss',
legend=['D', 'G']))
for epoch in range(num_epochs):
#1. train Discrimator firstly
for _ in range(5):
# 1.1 train on real data
x = next(data_iter)
xr = torch.from_numpy(x).to(device)
#[batch_size, 2]=>[batch, 1]
predr = D(xr)
#max predr , min lossr
lossr = -predr.mean()
#1.2 train on fake data
z = torch.randn(batchsz, 2).to(device)
#tf.stop_graident()
xf = G(z).detach()
predf = D(xf)
lossf = predf.mean()
#1.3 gradient penalty
gp = gradient_penalty(D,xr,xf.detach())
#1.4 aggregate all
loss_D = lossr+lossf+gp
#1.5 optimize
optim_D.zero_grad()
loss_D.backward()
optim_D.step()
#2 train Generator secondly
z = torch.randn(batchsz, 2).to(device)
#tf.stop_graident()
xf = G(z)
predf = D(xf)
loss_G = - predf.mean()
#optimize
optim_G.zero_grad()
loss_G.backward()
optim_G.step()
if epoch%100 ==0:
viz.line([[loss_D.item(), loss_G.item()]],[epoch],win='loss',update='append')
print(f"loss_D {loss_D.item()} \t ,loss_G {loss_G.item()}")
generate_image(D,G,x, epoch)
print("\n train end")
#二、只保存模型中的参数并读取
torch.save(G.state_dict(), 'Generator.pt')
torch.save(G.state_dict(), 'Discriminator.pt')
#2 train Generator
#http://www.manongjc.com/detail/42-hvxyfyduytmpwzz.html
gen()
四 MNIST 手写数字识别
4.1 模型部分
model.py
# -*- coding: utf-8 -*-
"""
Created on Mon Mar 18 10:19:26 2024
@author: chengxf2
"""
import torch.nn as nn
from torchsummary import summary
import torch
class Generator(nn.Module):
def __init__(self, z_dim=10, im_chan=1, hidden_dim=64):
super(Generator, self).__init__()
self.z_dim = z_dim
self.gen = nn.Sequential(
self.layer1(z_dim, hidden_dim * 4,kernel_size=3, stride=2),
self.layer1(hidden_dim * 4, hidden_dim * 2,kernel_size=4,stride = 1),
self.layer1(hidden_dim * 2,hidden_dim ,kernel_size=3,stride = 2, ),
self.layer2(hidden_dim,im_chan,kernel_size=4,stride=2))
def layer1(self, input_channel, output_channel, kernel_size, stride = 1, padding = 0):
#inplace = true, 就相当于在原内存计算
return nn.Sequential(
nn.ConvTranspose2d(input_channel, output_channel, kernel_size, stride, padding),
nn.BatchNorm2d(output_channel),
nn.ReLU(inplace=True),
)
def layer2(self, input_channel, output_channel, kernel_size, stride = 1, padding = 0):
#双曲正切函数的输出范围为(-1,1)
return nn.Sequential(
nn.ConvTranspose2d(input_channel, output_channel, kernel_size, stride, padding),
nn.Tanh()
)
def forward(self, noise):
'''
Parameters
----------
noise : [batch, z_dim]
Returns
-------
输出的是图片[batch, channel, width, height]
'''
x = noise.view(len(noise), self.z_dim, 1, 1)
return self.gen(x)
class Discriminator(nn.Module):
def __init__(self, im_chan=1, hidden_dim=16):
super(Discriminator, self).__init__()
self.disc = nn.Sequential(
self.block1(im_chan,hidden_dim * 4,kernel_size=4,stride=2),
self.block1(hidden_dim * 4,hidden_dim * 8,kernel_size=4,stride=2,),
self.block2(hidden_dim * 8,1,kernel_size=4,stride=2,),
)
def block1(self, input_channel, output_channel, kernel_size, stride = 1, padding = 0):
return nn.Sequential(
nn.Conv2d(input_channel, output_channel, kernel_size, stride, padding),
nn.BatchNorm2d(output_channel),
nn.LeakyReLU(0.2, inplace=True)
)
def block2(self, input_channel, output_channel, kernel_size, stride = 1, padding = 0):
return nn.Sequential(
nn.Conv2d(input_channel, output_channel, kernel_size, stride, padding),
)
def forward(self, image):
return self.disc(image)
def model_summary():
device = torch.device('cuda:0' if torch.cuda.is_available() else 'cpu')
summary(Generator(100).to(device), (100,))
print(Generator(100))
print("\n 鉴别器")
summary(Discriminator().to(device) , (1,28,28))
model_summary()
4.2 训练部分
main.py
# -*- coding: utf-8 -*-
"""
Created on Mon Mar 18 10:37:21 2024
@author: chengxf2
"""
import torch
from model import Generator
from model import Discriminator
import torchvision.transforms as transforms
from torch.utils.data import Dataset, DataLoader, ConcatDataset, TensorDataset
from torchvision.datasets import MNIST
import time
import matplotlib.pyplot as plt
import numpy as np
from torchvision.utils import make_grid
import torch.nn as nn
def get_noise(n_samples, z_dim, device='cpu'):
return torch.randn(n_samples,z_dim,device=device)
def weights_init(m):
if isinstance(m, nn.Conv2d) or isinstance(m, nn.ConvTranspose2d):
torch.nn.init.normal_(m.weight, 0.0, 0.02)
if isinstance(m, nn.BatchNorm2d):
torch.nn.init.normal_(m.weight, 0.0, 0.02)
torch.nn.init.constant_(m.bias, 0)
def gradient_penalty(gradient):
#Gradient Penalty
gradient = gradient.view(len(gradient), -1)
gradient_norm = gradient.norm(2, dim=1)
penalty = torch.mean((gradient_norm - 1)**2)
return penalty
def get_gen_loss(crit_fake_pred):
#生成器的loss
gen_loss = -1. * torch.mean(crit_fake_pred)
return gen_loss
def get_crit_loss(crit_fake_pred, crit_real_pred, gp, c_lambda):
#鉴别器的loss, 原公式加符号,转换为极小值求梯度
crit_loss = torch.mean(crit_fake_pred) - torch.mean(crit_real_pred) + c_lambda * gp
return crit_loss
def get_gradient(crit, real, fake, epsilon):
#随机采样
mixed_images = real * epsilon + fake * (1 - epsilon)
mixed_scores = crit(mixed_images)
gradient = torch.autograd.grad(
inputs=mixed_images,
outputs=mixed_scores,
grad_outputs=torch.ones_like(mixed_scores),
create_graph=True,
retain_graph=True,
)[0]
return gradient
def show_new_gen_images(tensor_img, num_img=25):
tensor_img = (tensor_img + 1) / 2
unflat_img = tensor_img.detach().cpu()
img_grid = make_grid(unflat_img[:num_img], nrow=5)
plt.imshow(img_grid.permute(1, 2, 0).squeeze(),cmap='gray')
plt.title("gen image")
plt.show()
def show_tensor_images(image_tensor, num_images=25, size=(1, 28, 28), show_fig=False, epoch=0):
#生成器输出的范围[-1,1]
#image_tensor = (image_tensor + 1) / 2
image_unflat = image_tensor.detach().cpu().view(-1, *size)
image_grid = make_grid(image_unflat[:num_images], nrow=5)
plt.axis('off')
label =f"Epoch: {epoch}"
plt.title(label)
plt.imshow(image_grid.permute(1, 2, 0).squeeze())
#if show_fig:
#plt.savefig('image_at_epoch_{:04d}.png'.format(epoch))
plt.show()
def show_loss(G_mean_losses,C_mean_losses ):
plt.figure(figsize=(10,5))
plt.title("Generator and Discriminator Loss During Training")
plt.plot(G_mean_losses,label="G-Loss")
plt.plot(C_mean_losses,label="C-Loss")
plt.xlabel("iterations")
plt.ylabel("Loss")
plt.legend()
plt.show()
def train():
z_dim = 32
batch_size = 128
device = torch.device('cuda:0' if torch.cuda.is_available() else 'cpu')
lr = 1e-4
beta_1 = 0.0
beta_2 = 0.9
#MNIST Dataset Load
print("\n init 1: MNIST Dataset Load ")
fixed_noise = get_noise(batch_size, z_dim, device=device)
train_transform = transforms.Compose([transforms.ToTensor(),])
dataloader = DataLoader( MNIST('.', download=True, transform=train_transform),
batch_size=batch_size,
shuffle=True)
print("\n init2: Loaded Data Visualization")
start = time.time()
dataiter = iter(dataloader)
images,labels = next(dataiter)
print ('Time is {} sec'.format(time.time()-start))
plt.figure(figsize=(8,8))
plt.axis("off")
plt.title("Training Images")
plt.imshow(np.transpose(make_grid(images.to(device), padding=2, normalize=True).cpu(),(1,2,0)))
print('Shape of loading one batch:', images.shape)
print('Total no. of batches present in trainloader:', len(dataloader))
#Optimizer
gen = Generator(z_dim).to(device)
gen_opt = torch.optim.Adam(gen.parameters(), lr=lr, betas=(beta_1, beta_2))
crit = Discriminator().to(device)
crit_opt = torch.optim.Adam(crit.parameters(), lr=lr, betas=(beta_1, beta_2))
gen = gen.apply(weights_init)
crit = crit.apply(weights_init)
print("\n -------- train ------------")
n_epochs = 10
cur_step = 0
total_steps = 0
start_time = time.time()
cur_step = 0
generator_losses = []
Discriminator_losses = []
C_mean_losses = []
G_mean_losses = []
c_lambda = 10
crit_repeats = 5
for epoch in range(n_epochs):
cur_step = 0
start = time.time()
for real, _ in dataloader:
cur_batch_size = len(real)
real = real.to(device)
mean_iteration_Discriminator_loss = 0
for _ in range(crit_repeats):
### Update Discriminator ###
crit_opt.zero_grad()
fake_noise = get_noise(cur_batch_size, z_dim, device=device)
fake = gen(fake_noise)
crit_fake_pred = crit(fake.detach())
crit_real_pred = crit(real)
epsilon = torch.rand(len(real), 1, 1, 1, device=device, requires_grad=True)
gradient = get_gradient(crit, real, fake.detach(), epsilon)
gp = gradient_penalty(gradient)
crit_loss = get_crit_loss(crit_fake_pred, crit_real_pred, gp, c_lambda)
# Keep track of the average Discriminator loss in this batch
mean_iteration_Discriminator_loss += crit_loss.item() / crit_repeats
# Update gradients
crit_loss.backward(retain_graph=True)
# Update optimizer
crit_opt.step()
Discriminator_losses += [mean_iteration_Discriminator_loss]
### Update generator ###
gen_opt.zero_grad()
fake_noise_2 = get_noise(cur_batch_size, z_dim, device=device)
fake_2 = gen(fake_noise_2)
crit_fake_pred = crit(fake_2)
gen_loss = get_gen_loss(crit_fake_pred)
gen_loss.backward()
# Update the weights
gen_opt.step()
# Keep track of the average generator loss
generator_losses += [gen_loss.item()]
cur_step += 1
total_steps += 1
print_val = f"Epoch: {epoch}/{n_epochs} Steps:{cur_step}/{len(dataloader)}\t"
print_val += f"Epoch_Run_Time: {(time.time()-start):.6f}\t"
print_val += f"Loss_C : {mean_iteration_Discriminator_loss:.6f}\t"
print_val += f"Loss_G : {gen_loss:.6f}\t"
print(print_val, end='\r',flush = True)
gen_mean = sum(generator_losses[-cur_step:]) / cur_step
crit_mean = sum(Discriminator_losses[-cur_step:]) / cur_step
C_mean_losses.append(crit_mean)
G_mean_losses.append(gen_mean)
print_val = f"Epoch: {epoch}/{n_epochs} Total Steps:{total_steps}\t"
print_val += f"Total_Time : {(time.time() - start_time):.6f}\t"
print_val += f"Loss_C : {mean_iteration_Discriminator_loss:.6f}\t"
print_val += f"Loss_G : {gen_loss:.6f}\t"
print_val += f"Loss_C_Mean : {crit_mean:.6f}\t"
print_val += f"Loss_G_Mean : {gen_mean:.6f}\t"
print(print_val)
fake_noise = fixed_noise
fake = gen(fake_noise)
show_tensor_images(fake, show_fig=True,epoch=epoch)
cur_step = 0
print("\n-----训练结束--------------")
num_image = 25
noise = get_noise(num_image, z_dim, device=device)
#Batch Normalization,Dropout不使用
gen.eval()
crit.eval()
with torch.no_grad():
fake_img = gen(noise)
show_new_gen_images(fake_img.reshape(num_image,1,28,28))
train()PyTorch-Wasserstein GAN(WGAN) | Kaggle
WGAN模型——pytorch实现_python实现wgn函数-CSDN博客
WGAN_哔哩哔哩_bilibili
15 李宏毅【機器學習2021】生成式對抗網路 (Generative Adversarial Network, GAN) (中) – 理論介紹與WGAN_哔哩哔哩_bilibili















 733
733

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









