







@创建于:20220105
@修改于:20220106
文章目录
1、Splitter Classes概述
Splitter Classes是scikit-learn 1.0.2中model_selection模块的一个对数据进行切分类的集合,包含的切分方式如下图所示。model_selection模块还包括Splitter Functions(数据切分方法)。

本博客,基于scikit-learn 1.0.2介绍其中的几种切分类。
2、KFold
2.1 方法介绍
class sklearn.model_selection.KFold(n_splits=5, *, shuffle=False, random_state=None)
- (1)输出划分后的训练集、测试集的索引,将数据集拆分为 k 个连续的折叠(默认情况下不进行随机划分,即进行顺序划分,shuffle=True时,进行伪随机划分)。
- (2)将每折叠用作一次验证,而剩余的 k - 1 个折形成训练集。
- (3)每一折的数据是相互独立的,没有重复,合并在一起组成完整的数据集。
2.2 参数介绍
n_splits:int, default=5
表示,要分割为多少个K子集
shuffle:bool, default=False
是否要洗牌(打乱数据)
random_state:int or RandomState instance, default=None
随机状态,需要配合shuffle参数使用,建议设定为特定值,便于复现。
2.3 图形化解说
下图是可视化的交叉验证行为,可以看出,KFold 不受类别或组的影响。具体请点击此链接。
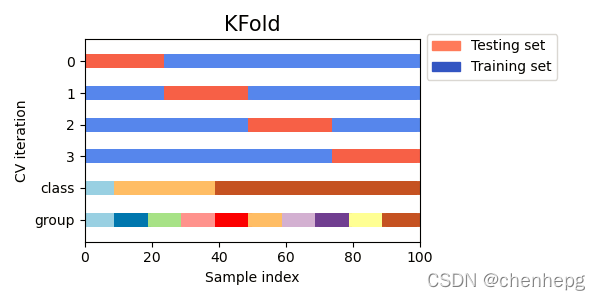
2.4 代码样例
import numpy as np
from sklearn.model_selection import KFold
X = ["a", "b", "c", "d"]
kf = KFold(n_splits=2)
for train, test in kf.split(X):
print("%s %s" % (train, test))
[2 3] [0 1]
[0 1] [2 3]
参考博客:
sklearn函数:KFold(分割训练集和测试集)
sklearn.KFold用法示例
sklearn的KFold,GroupKFold,StratifiedKFold区分
3、GroupKFold
3.1 方法介绍
class sklearn.model_selection.GroupKFold(n_splits=5)
- (1)非重叠的 K 折迭代器变体,按照组的指定进行划分。
- (2)同一组不会出现在两个不同折数据中(不同组的数量必须至少等于折数)。
- (3)每一折数据之间应近似平衡,即:不同组的数量大致相同。
3.2 参数介绍
n_splits int, default=5
折数默认值为5,最小值为2。
3.3 图形化解说
Each subject is in a different testing fold, and the same subject is never in both testing and training. Notice that the folds do not have exactly the same size due to the imbalance in the data.
每组数据在不同的数据折中,同一组数据不可能同时出现在测试集和验证集中。注意,由于数据不均衡,每一折数据的样本量不一样。
下图有10个group,但是被分到不同的4折中。有的折数量多,有的则少,体现了不均衡。
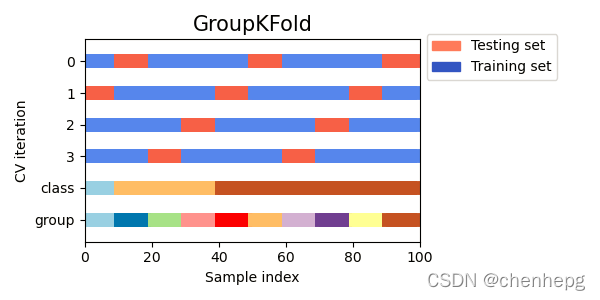
3.4 代码样例
from sklearn.model_selection import GroupKFold
X = [0.1, 0.2, 2.2, 2.4, 2.3, 4.55, 5.8, 8.8, 9, 10]
y = ["a", "b", "b", "b", "c", "c", "c", "d", "d", "d"]
groups = [1, 1, 1, 2, 2, 2, 3, 3, 3, 3]
gkf = GroupKFold(n_splits=3)
for train, test in gkf.split(X, y, groups=groups):
print("%s %s" % (train, test))
[0 1 2 3 4 5] [6 7 8 9]
[0 1 2 6 7 8 9] [3 4 5]
[3 4 5 6 7 8 9] [0 1 2]
参考博客:
sklearn中的数据集的划分
sklearn的KFold,GroupKFold,StratifiedKFold区分
【模型评估_方法_交叉验证法】
4、StratifiedKFold
4.1 方法介绍
class sklearn.model_selection.StratifiedKFold(n_splits=5, *, shuffle=False, random_state=None)
- (1)分层 K 折交叉验证器。
- (2)拆分训练/测试集中的数据,输出对应的索引。
- (3)这个交叉验证对象是 KFold 的变体,它返回分层的每折数据。 每折数据中,每个类别的样本百分比相等。适用于类别不均衡的情况。
4.2 参数介绍
n_splits int, default=5
折数,默认值为5,最小值是2。
shuffle bool, default=False
是否在分批之前打乱每个类的样本。 请注意,每折数据的顺序不会被打乱。
random_state int, RandomState instance or None, default=None
随机种子,当 shuffle 为 True 时,random_state 影响索引的排序,它控制每个类的每个折叠的随机性。 否则,将 random_state 保留为 None。
4.3 图形化解说
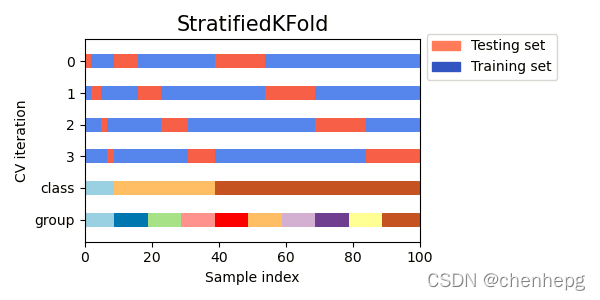
4.4 代码样例
from sklearn.model_selection import StratifiedKFold, KFold
import numpy as np
X, y = np.ones((50, 1)), np.hstack(([0] * 45, [1] * 5))
skf = StratifiedKFold(n_splits=3)
for train, test in skf.split(X, y):
print('train - {} | test - {}'.format(np.bincount(y[train]), np.bincount(y[test])))
# train - [30 3] | test - [15 2]
# train - [30 3] | test - [15 2]
#train - [30 4] | test - [15 1]
kf = KFold(n_splits=3)
for train, test in kf.split(X, y):
print('train - {} | test - {}'.format(np.bincount(y[train]), np.bincount(y[test])))
# train - [28 5] | test - [17]
# train - [28 5] | test - [17]
# train - [34] | test - [11 5]
上面的列子,可以看到 StratifiedKFold 保留了训练和测试数据集中的类比(大约 1 / 10)。
5、ShuffleSplit
5.1 方法介绍
class sklearn.model_selection.ShuffleSplit(n_splits=10, *, test_size=None, train_size=None, random_state=None)
(1)随机排列交叉验证器。
(2)返回拆分后的 训练集和测试集 的索引。
(3)注意:与其他交叉验证策略相反,随机拆分并不能保证所有折叠都会不同,对于大型数据集来说,仍有数据重叠的可能性。
5.2 参数介绍
n_splits int, default=10
重新洗牌和拆分迭代的次数。
test_size float or int, default=None
如果为浮点型,则值应介于 0.0 和 1.0 之间,表示拆分中测试数据集的比例。
如果是 整型,则表示测试样本的绝对数量。
如果为 None,则该值设置为测试集的补集。
如果 train_size 也是 None,则将设置为 0.1。
train_size float or int, default=None
如果是浮点型,则应介于 0.0 和 1.0 之间,表示拆分中训练数据集的比例。
如果是 int,则表示训练样本的绝对数量。
如果为 None,则该值设置为训练集的补集。
random_state int, RandomState instance or None, default=None
控制生成的训练和测试指标的随机性。
5.3 图形化解说
请注意,ShuffleSplit 不受类或组的影响。
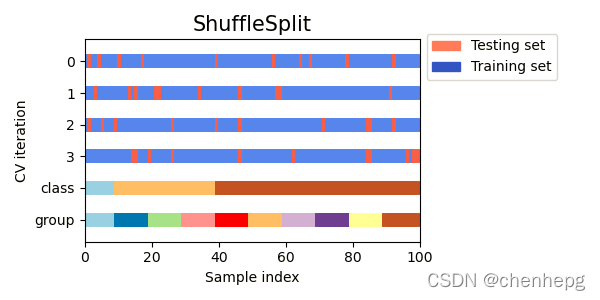
5.4 代码样例
from sklearn.model_selection import ShuffleSplit
X = np.arange(10)
ss = ShuffleSplit(n_splits=5, test_size=0.25, random_state=0)
for train_index, test_index in ss.split(X):
print("%s %s" % (train_index, test_index))
[9 1 6 7 3 0 5] [2 8 4]
[2 9 8 0 6 7 4] [3 5 1]
[4 5 1 0 6 9 7] [2 3 8]
[2 7 5 8 0 3 4] [6 1 9]
[4 1 0 6 8 9 3] [5 2 7]
6、StratifiedShuffleSplit
6.1 方法介绍
sklearn.model_selection.StratifiedShuffleSplit(n_splits=10, *, test_size=None, train_size=None, random_state=None)
- (1)分层 随机切分 交叉验证器。
- (2)返回拆分后的 训练集和测试集 的索引。
- (3)这个交叉验证对象是 StratifiedKFold 和 ShuffleSplit 的合并,它返回分层的随机切分。 但是确保了每一折数据中,每个类别的样本百分比几乎相同。
- (4)注意:与 ShuffleSplit 策略一样,与其他交叉验证策略相反,分层随机切分并不能保证所有折数据都会不同,对于大型数据集来说,仍有数据重叠的可能性。
6.2 参数介绍
n_splits int, default=10
重新洗牌和拆分迭代的次数。
test_size float or int, default=None
如果为浮点型,则值应介于 0.0 和 1.0 之间,表示拆分中测试数据集的比例。
如果是 整型,则表示测试样本的绝对数量。
如果为 None,则该值设置为测试集的补集。
如果 train_size 也是 None,则将设置为 0.1。
train_size float or int, default=None
如果是浮点型,则应介于 0.0 和 1.0 之间,表示拆分中训练数据集的比例。
如果是 int,则表示训练样本的绝对数量。
如果为 None,则该值设置为训练集的补集。
random_state int, RandomState instance or None, default=None
控制生成的训练和测试指标的随机性。
6.3 图形化解说
StratifiedShuffleSplit 是 ShuffleSplit 的变体,它返回分层的随机拆分,即通过为每个目标类保留与完整集中相同的百分比来创建拆分。
这是交叉验证行为的可视化。
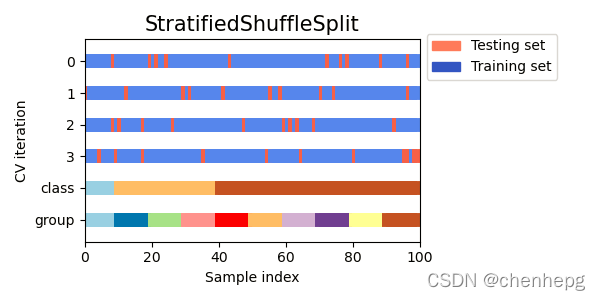
6.4 代码样例
无代码
7、StratifiedGroupKFold
7.1 方法介绍
sklearn.model_selection.StratifiedGroupKFold(n_splits=5, shuffle=False, random_state=None)
(1)StratifiedGroupKFold是分层抽样结合非重叠分组的变体。
(2)该交叉验证返回对象是 StratifiedKFold尽可能返回非重叠分组后的结果,同时确保每个类别的样本比例在每一折数据中相同。也就是同时受到类别和分组的影响。
(3)同一组不会出现在两个不同的折叠中(组的数量必须至少等于折叠的数量)。
(4)GroupKFold 和 StratifiedGroupKFold 之间的区别在于:GroupKFold试图创建平衡折叠,使得每个折叠中不同组的数量大致相同,而 StratifiedGroupKFold 则尽可能地保障每个类别在不通折数据集和总体样本的比例一致,还要保障非重复的分配组到每一折数据中。
7.2 参数介绍
n_splitsint, default=5
折数,最少为2.
shuffle bool, default=False
是否在分批之前打乱每个类的样本。 请注意,每拆数据的样本不会被打乱。
该方法只会对于类别分布相似的组间进行乱序,但不会只想全局乱序。
random_state int or RandomState instance, default=None
当 shuffle 为 True 时,random_state 影响索引的排序,它控制每个类的每个折叠的随机性。 否则,将 random_state 保留为 None。 为跨多个函数调用的可重现输出传递 int。
7.3 图形化解说
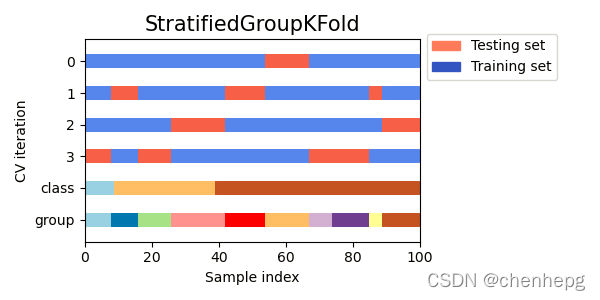
7.4 代码样例
from sklearn.model_selection import StratifiedGroupKFold
X = list(range(18))
y = [1] * 6 + [0] * 12
groups = [1, 2, 3, 3, 4, 4, 1, 1, 2, 2, 3, 4, 5, 5, 5, 6, 6, 6]
sgkf = StratifiedGroupKFold(n_splits=3)
for train, test in sgkf.split(X, y, groups=groups):
print("%s %s" % (train, test))
[ 0 2 3 4 5 6 7 10 11 15 16 17] [ 1 8 9 12 13 14]
[ 0 1 4 5 6 7 8 9 11 12 13 14] [ 2 3 10 15 16 17]
[ 1 2 3 8 9 10 12 13 14 15 16 17] [ 0 4 5 6 7 11]
8、总结
上面主要介绍了KFold、GroupFold、StratifiedKFold及它们的变体。除此之外还有其他切分方法。
详细内容请参见官网:Splitter Classes。

















 215
215

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









