







GD32,在电源电路参考设计
资料来源于微信公众号“life_and_family”,更多相关资料可以关注下该公众号
对于GD32,在电源电路设计方面的一些参考建议,以GD32F1x0为例子
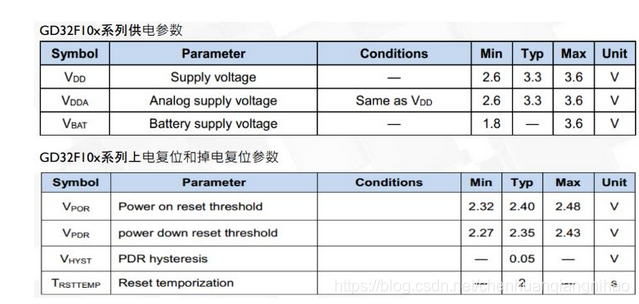
VDD脚必须外接电容(N*0.luf+l0uf陶瓷电容);
◆VDDA脚必须外接电容(0.luf+luf陶瓷电容);
◆VBAT引脚必须连接至外部电池连接至VDD电源上;VREF+引脚可以直连至VDDA,如果VREF上使用单独的外部参考电压,必须在这个引脚上连接一个0.luF和I个luf的电容;
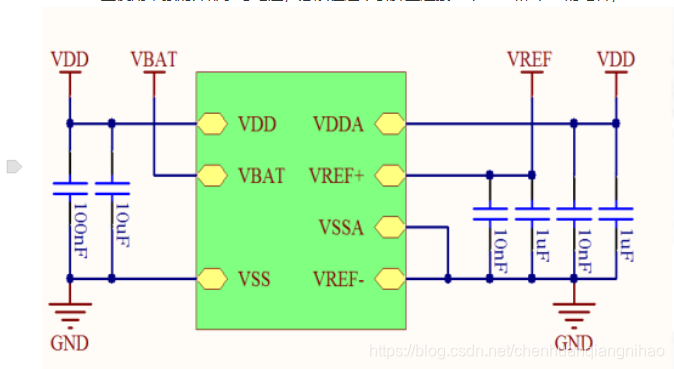
对于PCB布线方面建议:
电压跌落相关解决方案口采用独立供电方案:
1.MCU和耗电设备独立供电;优化电源方案
2.提高电源的适应性和抗干扰能力;
3适当调整负载电容,根据电路实际需求做相关调整;
4.有些型号MCU掉电电压可配置,可根据需求调整掉电电压范围;
更多资料来源于微信公众号:
stm32的VDDA与VDD应该怎样连接?
接入主供电VCC,然后经由VCC分别接俩电感后一个连接VDDD一个连接VDDA,其中,VDDA最好再经由电容再次滤波,因为模拟电源要求比数字电源高!
VDD是主供电电源,也是IO口输出电平的输入电源。VDDA是模拟电源,当使用到模拟信号的时候,比如AD(模数)或者DA(数模)的时候,系统会使用VDDA的电压作为参考电压来。不要求精准使用的话,可以直接把VDDA和VDD同时接入3.3V就行。如果要求精准
有些把VREF VDDA接3.3V,是用外部基准还是内部基准?



















 6275
6275

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









