






第三章 图形处理单元(GPU)
从历史上看,在管线的最后阶段已经开始使用硬件图形加速,首先用于执行三角形扫描线的光栅化。在接下来的几代硬件中又重新回到了管线内部,直到最后在硬件加速中直接实现了一些上层application阶段的算法。相对于软件的实现方式,使用特定硬件的唯一优势是运行速度,但是速度恰好是至关重要的。
在过去的十年里,图形硬件经历一些令人难以置信的变化。第一个支持硬件顶点处理功能(NVIDIA GeForce256)的消费者级别的显卡发布于1999年。NVIDIA创建了一个术语graphics processing unit(GPU)用于区分GeForce256显卡与以前的仅支持光栅处理的芯片,并一直坚持使用该术语[898]。在接下来的几年里,GPU已经从一个复杂的固定功能管线的可配置实现方式,演变为高度可编程的“一张白纸”,使得开发人员能编写自己的算法进行实现。使用各种不同类型的可编程shaders是控制GPU的基本方法。其中,vertex shader支持对每一个顶点执行各种操作(包括变换和变形)。与此类似,pixel shader对每一个单独的像素点进行处理,支持对每一个像素执行复杂的shading计算公式。此外,geometry shader支持在GPU运行时新建或删除几何图元(point,lines,triangles)。可以把计算的结果值写入到多个高精度的缓存中,并重新作为顶点或纹理数据进行使用。由于效率问题,管线的部分阶段依然保持可配置的,而不是可编程的,但是GPU发展的趋势是可编程性和灵活性。

图3.1 渲染管线的GPU实现。根据用户对每个阶段对应操作的控制级别分别设置为不同的颜色。绿色表示该阶段是完全可编程的。黄色表示该阶段是可配置的,但不可编程的,比如,clipping阶段的执行是可选的或者增加用户自定义的裁剪平面。最后,蓝色对应的阶段是完全由固定功能管线组成的。
3.1 GPU Pipeline Overview
GPU实现了第2章所描述的geometry和rasterization conceptual管线阶段。这些阶段被划分为多个具有不同的可配置或可编程级别的硬件阶段。图3.1显示了不同的可配置或可编程级别对应的不同阶段的颜色。需要注意的是这种物理硬件阶段的划分方式与第2章所使用的functional阶段的划分方式略有不同。
其中,vertex shader是一个完全可编程阶段,通常用于实现“Model and View Transform(模型和视图变换)”,“Vertex Shading(顶点着色)”和“Projection(投影)”functional阶段。而geometry shader则是可选的,geometry shader也是一个完全可编程的阶段,是对一个图元(point,line,triangle)的全部顶点进行处理。可以用于执行每个图元的shading操作,删除图元或者创建新的图元。另外,clipping,screen mapping,triangle setup以及triangle traversal阶段全部是固定功能的管线阶段,分别实现了该名称对应的functional阶段。与vertex和geometry shaders一样,pixel shader也是完全可编程的,并执行“Pixel Shading” function阶段。最后是merge阶段,该阶段介于shader阶段的完全可编程性和其他阶段的固定功能特性之间。尽管该阶段是不可编程的,但是具有高度可配置性,并且可以设置以执行多种不同的操作。当然,merger阶段实现了对应的“Merging”functional阶段,负责修改color,Z-buffer,blend,stencil以及其他相关的buffers数据。
随着时间的推移,GPU管线已经慢慢减少了硬编码操作,不断增加管线的灵活性和控制。在这个发展过程中,最重要的一步是引入了可编程的shader阶段。下一节将会描述各种可编程阶段的通用性质。
3.2 The Programmable Shader Stage
在现代GPU的shader阶段(比如Vista平台的DirectX 10以及之后的版本,所支持的Shader Model 4.0)使用了一个common-shader core(通用着色器内核)。这意味着vertex,pixel以及geometry shaders共享同一个编程模型。在本书中我们会区分common-shader core与unified shaders,其中comon-shader core是以应用程序编程人员角度进行功能描述,而unified shaders是一种与这种内核一一对应的GPU架构。详见第18章18.4节。另外,common-shader core是图形API;含有unified shaders是一种GPU特性。在早期的GPUs中,vertex和pixel shaders没有什么共性,并且不支持geometry shaders。尽管如此,现代的GPU模型中大部分设计元素都可以用于旧的硬件;对于旧的硬件大部设计元素要么是更简单要么是被舍弃,而不是从根本上进行改变。现在我们重点关注Shader Model 4.0,在后面的章节中会再讨论旧版本的GPU的shader models。
完整讲述shader编程模型超出了本书的讨论范围,而且有很多文档,书籍和网站已经详细讲解了相关内容[261,338,647,1084]。但是,在这里我们还是要适当地进行描述。通常使用类C的shading languages(着色编程语言)如HLSL,Cg和GLSL编写shaders。然后把这些语言编译成一种独立于机器的汇编语言,也称为intermediate language(IL,中间语言)。在以前的shader models版本中允许直接使用汇编语言编写shader,但是在DirectX 10中,汇编语言只是作为HLSL的调试输出形式存在。之后在一个单独的步骤中把这种汇编语言转换为实际的机器语言,通常是在驱动中完成。这种编译顺序支持在不同的硬件实现之间相互兼容。这种汇编语言可以被看成是定义了一个虚拟机,是shading语言编译生成的目标代码。
该虚拟机是一种由各种类型的寄存器和一组指令集编写的数据源组成的处理器。由于大多图形操作都是基于较短长度的向量(最大长度为4)操作,该处理能够支持4路SIMD(single-instruction multipe-data,单指令多数据)运算。每一个寄存器含有4个独立的数据。基本的数据类型是32位单精度浮点标量和向量值;另外,在最新的硬件中还增加了对32位整形数的支持。浮点类型的向量值通常包含的数据为postions(xyzw),法向量,矩阵行向量,颜色值(rbga)或者纹理坐标(uvwq)。整形数通常用于表示计数,索引或位掩码。此外,还支持一些组合的数据类型,比如结构体,数组,矩阵。为了更方便地执行向量运算,swizzling(分配运算),还支持复制向量的任一个分量值。也就是说,向量的各个元素可以重新排列或根据需要进行复制。同样还支持masking(掩码)操作,只有指定的向量元素才会被使用。
一次draw call就是调用图形API绘制一组图元,因此会引起图形管线的执行。每一个可编程shader阶段都具有两种输入类型:uniform inputs和varying inputs,其中uniform输入类型是把在一次draw call的整个过程中输入值保持为常量(但是在多次draw calls中发生改变),varying输入类型表示shader中处理的每一个vertex或pixel具有不同的输入值。纹理是一种特殊的uniform输入类型,以前都是表示把一张color图片应用到一个表面上,但是现在一般把纹理看成是任意大小的数据。另外很重要的一点是,尽管shaders具有多种不同的输入类型,分别使用不同方法处理,但是shaders的输出类型则是受到严格限制的。这是shaders与运行在通常处理器上的程序最重要的不同点。底层的虚拟机提供了特定的寄存器用于表示这些不同的输入和输出类型。通过只读的constant registers或constant bauffers可以访问Uniform类型的输入数据,之所以称为constant是因为该寄存器中的数据在一次draw all期间为常量。可用的常量寄存器数量远大于用于表示输入或输出变量的寄存器数量。这是因为输入和输出变量需要针对每一个顶点或像素单独存储,而uniform输入数据只需要存储一次,并在draw call期间在所有的顶点或像素之间进行重用。虚拟机中还包括通用的temporary registers(临时寄存器),用于存放临时变量。使用临时寄存器中整形值可以以及数组索引的方式访问所有类型的寄存器。图3.2中显示了shader虚拟机的输入和输出类型。
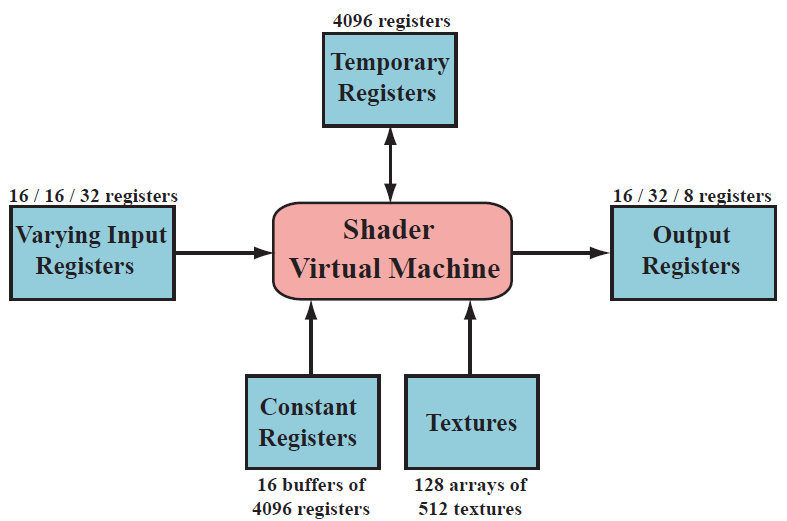
图3.2 DirectX 10对应的通常着色内核虚拟机以及寄存器配置布局。每一种资源的旁边标出了该资源的最大可用数量。使用斜线分隔的三个数字(从左到右)分别指vertex,geometry和pixel shaders的最大限制数量。
图形计算中的常用操作在现代GPUs中都可以高效的执行。一般情况下,计算速度最快的操作是标量和向量的乘法,加法以及组合运算,比如乘加运算和点积运算。其他的操作,如reciprocal(倒数),square root(平方根),sine(正弦),cosine(余弦),exponentiation(求幂)和logarithm(对数)的计算成本要稍微更高一点,但仍然是相当快速的。虽然纹理贴图操作是很高效的,但是该操作的性能可能会受到一些因素的影响,比如等待获取资源的访问结果所花的时间。Shading编程语言对于最常用的操作运算(比如加法和减法运算)提供了相应的运算符,比如
×
和
+
。其他的运算操作则是对外提供了相应的instrinsic functions(内置函数),比如
术语flow control(控制流)是指使用分支指令改变代码执行的流程。这些指令用于实现高级语言结构中的条件语句,比如“if”和“case”语句,以及各种类型的循环。Shaders支持两种类型的控制流。一种为static flow control(静态控制流),这种控制流分支是基于uniform类型的输入变量。也就是说在一次draw call过程中,代码的执行流程保持不变。静态控制流主要好处是允许在多种不同的情况下(比如,各种不同的光源数量)使用同一个shader。另一种为dynamic flow control(动态控制流),是基于各种不同的输入变量进行控制。动态控制流比静态控制流的功能更加强大,但是计算成本也更高,尤其是代码流程在多次shader调用之间不规律变化的情况下。正如第18章18.4.2节我们将会讨论的,在一个shader中需要同时执行大量的vertices或pixels计算。如果控制流对一些元素选择了“if”分支,对另一些元素选择了“else”分支,实际上两个分支的所有元素都会被计算(并且对于每个元素不被使用的分支将被丢弃)。
Shader程序可以在应用程序加载之前进行离线编译,或者在应用程序运行时编译。与任何其他的编译器一样,shader编译器也有各种选项用于生成不同的输出文件,并且支持使用不同的优化级别。编译完成的shader以文本字符串的形式保存,并通过驱动传递到GPU中。
3.3 The Evolution of Programmable Shading
设计一种可编程shading框架的想法可以追溯到1984年Cook提出的shade trees[194]。图3.3中显示了一个简单的shader以及对应的shade tree。在80年代后期诞生的RenderMan Shading Language[30,1283]就是基于这种想法开发出来的,并且在今天依然被广泛用于电影工业渲染中。在GPUs原生支持可编程shaders之前,关于如何使用多个渲染通道实现可编程shading,已经有人做出了一些尝试。比如1999年Quake III:Arena游戏中使用的脚本语言是可编程shading领域第一个在商业上取得广泛成功的尝试[558,604]。2000年,Peercy等人描述了一种机制把RenderMan shaders转换为显卡中运行的多个通道。他们发现GPUs缺乏使这种方法变得普遍适用的两个特性:第一,缺乏把计算的结果作为纹理坐标(dependent texture reads,纹理坐标能力)的能力;第二,缺乏对纹理和color buffers中所使用的更大范围和精度的数据类型的支持。其中一个建议的数据类型是一个新颖的(在当时)16位浮点数表示方式。此时,尽管大部GPU支持高度可配置的管线,但还有没有商业上可用的GPU能够支持可编程shading。
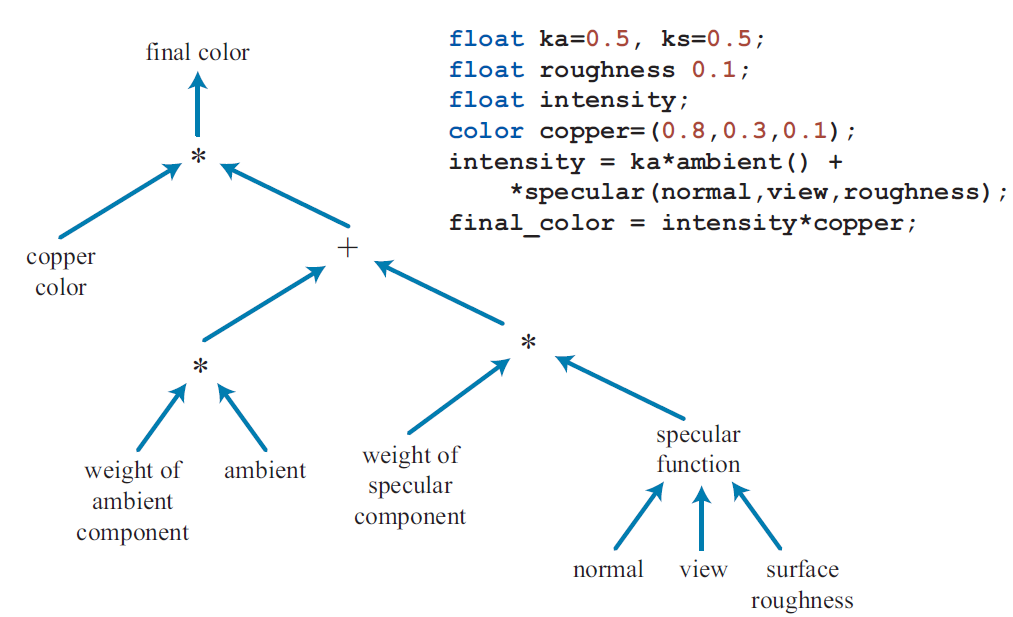
图3.3 一个简单的copper shader的shade tree,以及对应的shader编程语言程序。
2001年初,NVIDIA发布了第一款支持可编程vertex shaders的GPU,GeForce 3,通过使用DirectX 8.0对外开放并扩展支持OpenGL。这些shaders以一种类汇编语言进行编写,并使用驱动转化为GPU运行时的微代码。在DirectX 8.0中还包含了pixel shaders,但是pixel shader SM(shader model) 1.1版本未能达到实际可编程的预期—因为这个非常有限的shader“程序”会被驱动转换为纹理混合状态,而驱动又与硬件“register combiners”连接在一起。这些pixel shader“程序”不仅仅是长度受到限制(最多只支持12个指令),还缺少Peercy等人所指出的真正可编程shading所必需的两个重要因素(dependent texture reads和浮点数据类型)。
注:GeForce 3 支持各种类型的dependent texture reads,但只能在极其有限的条件下。
在这个时期的shaders还不支持控制流(分支)指令,因此条件语句不得不通过计算两种情况,并在这两个结果中选择某一个或进行插值的方法进行模拟。DirectX中定义Shader Model概念,用于区分支持不同shader功能的硬件。比如,GeForce 3支持vertex shader model 1.1以及pixel shader model 1.1(shader model 1.0用于一款从未发布的硬件)。在2001年,GPUs不断发展为更接近于一个通用的pixel shader编程模型。DirectX 8.1增加了对pixel shader model 1.2到1.4的支持(每一个版本表示一个不同的硬件),并进一步扩展了pixel shader的功能,增加了更多的指令以及对depent texture reads更普通的支持。
2002年,随着DirectX 9.0的发布,其中包含了Shader Model 2.0(以及扩展版本2.X),带来了真正的可编程vertex shader和pixel shader功能。通过多次扩展类似的功能也被用于OpenGL中。另外,该版本支持任意的dependent texture reads,并增加了16位浮点数的存储支持,最终完全满足Peercy等人在2000年提出的要求。Shader中限制使用的资源数量得到进一步增长,比如指令数,纹理和寄存器数量,因此shaders变得支持实现更复杂的效果。另外还增加了对控制流的支持。而且Shaders中不断增长的指令长度和复杂性使得汇编编程模型越来越繁琐。幸运的是,DirectX 9.0还包含了一种新的shader编程语言,称为HLSL(High Level Shading Language)。HLSL是Microsoft与NVIDIA合作开发的,NVIDIA还发布了一种支持跨平台的类似语言,称为Cg[818]。与些同时,OpenGL ARB(Architecture Review Board,架构审查委员会)发布了一个用于OpenGL的有点类似的shader编程语言,称为GLSL[647, 1084](也称为GLslang)。这些语言深受C编程语言的语法和设计理念的影响,还包含了一些借鉴于RenderMan Shading Language的元素。
在2004引入的Shader Model 3.0又带来了一些增量性改进,把可选的功能特性转变成了必须的功能,进一步增加了资源的限制数量,并增加了vertex shader对texture reads有限支持。在2005年末(Microsoft的 Xbox 360)和2006年(Sony Computer Entertainment的PLAYSTATION 3 system)引入新一代计算机时,都配置了Shader Model 3.0级别的GPUs。但是fixed-function pipeline并不同有完全消失:Nintendo在2006年末发布的Wii游戏机依然使用了固定功能的GPU[207]。然而,几乎可以肯定这会是fixed-function pipeline类型的最后一款游戏机,因为即使是移动设备如手机都可以使用可编程shaders(见第18章18.4.3节)。
另外,还有一些其他的编程语言和环境可以用于shader开发。例如,Sh语言[837,838]允许通过一个C++库完成GPU shaders的生成和组合[839]。这个开源项目可以运行在大量的平台上。关于shader开发领域的工具环境方面,有一些可视化编程工具允许美术设计人员(大部分设计人员不能熟练使用类C的shader编程语言)自行设计shader。这些工具包括可视化图形编辑器,用于连接预定义的shader构建模块,同时还包括编译工具用于把编辑的结果图形转换成shading语言如HLSL。图3.4中显示了一个shader设计工具(meantal mill,包含在NVIDIA FX Composer 2中)的截图。McGuire等人[847]通过审查可视化shader编程系统提出一种高级别的抽象扩展。
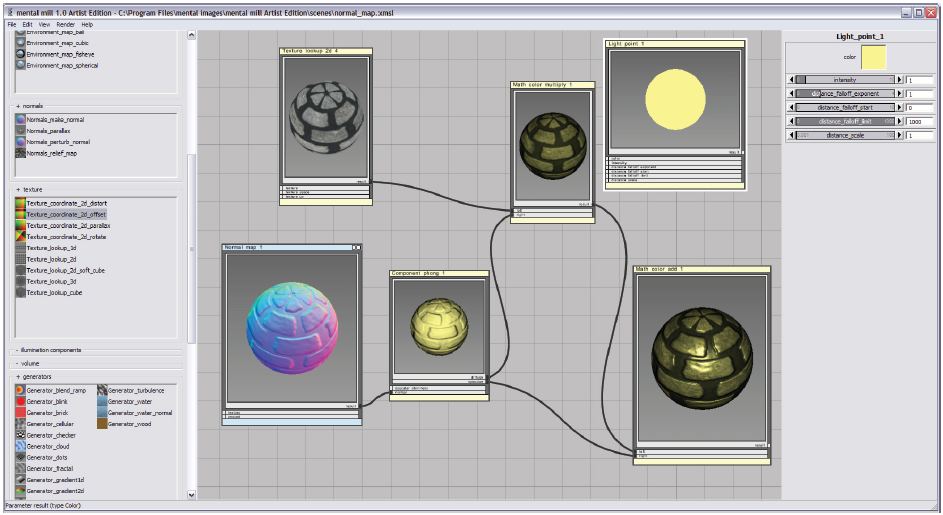
图3.4 用于shader设计的可视化shader图形编辑工具。在左边视图的工具箱中包含有各种各样的操作。当选中每一个工具箱,在右边视图中就会显示对应的参数设置。把每一个工具箱的输入和输出链接起来,可以形成如中间视图右下角所示的最终显示结果。(“mental mill”程序截图,mental images,inc.)
2007年,shader的可编程性得到了进一步大的发展。Shader Model 4.0(包含在DirectX 10.0中[123],同样扩展用于OpenGL中)带来了一些重要的特性,比如支持geometry shader和stream output。
Shader Model 4.0中包含了一个统一的编程模型用于所有的shader(vertex,pixel以及geometry),即之前描述的commom-shader core。进一步增加了可用的资源数量,并增加了对整形数据类型(包括bitwisew位运算)的支持。此外,还需要注意的是Shader Model 4.0 只支持高级语言编写的shaders(用于DirectX的HLSL以及OpenGL的GLSL),不再提供之前版本的shader models中用户自己编写汇编语言的接口。
GPU供应商,Microsoft以及OpenGL ARB一直在持续改进并扩展可编程shading的功能。除了对已经存在的APIs提供的新版本,还带来了新的编程模型,比如NVIDIA的CUDA和AMD的CTM[994],主要是针对非图形应用程序。在18章18.3.1节将会要详细讨论GPU的通用计算领域(GPGPU)。
3.3.1 Comparison of Shader Models
尽管本章重点讨论Shader Model 4.0(编写本书时最新的版本),但是开发人员经常需要支持那些使用旧版本shading models的硬件。由于这个原因,我们对目前几个版本的shading models做一些简单地的比较,包括SM2.0(以及扩展版本2.X),3.0和4.0。列出所有的不同点超出了本书的范围;详细的信息可以参考Microsoft Developer Network(MSDN)和对应的DirectX SDK[261]。
注:Shader Model 1.0到1.4是早期功能有限的版本,已经不再被使用。
在我这里我们重点讨论DirectX,因为DirectX的不同版本,与之相对的是OpenGL扩展版本的发展程度,既可以由OpenGL Architecture Review Board(ARB)批准,还可以由硬件供应商指定。这种扩展系统的好处是,由某个特定的independent hardware vendor(IHV,独立硬件供应商)提供的前沿性的功能可以立即被应用。DirectX 9以及之前的版本通过提供“capability bits”来支持不同的IHV,该bits可以用于检测GPU是否支持某种特性。在DirectX 10中,Microsoft彻底改变了这种方式,转而使用了一种要求所有IHVs都支持的标准化模型。尽管在此重点讨论DirectX,但是下面的讨论同样与OpenGL相关,因为在同一时期的底层GPUs具有同样的功能特性。
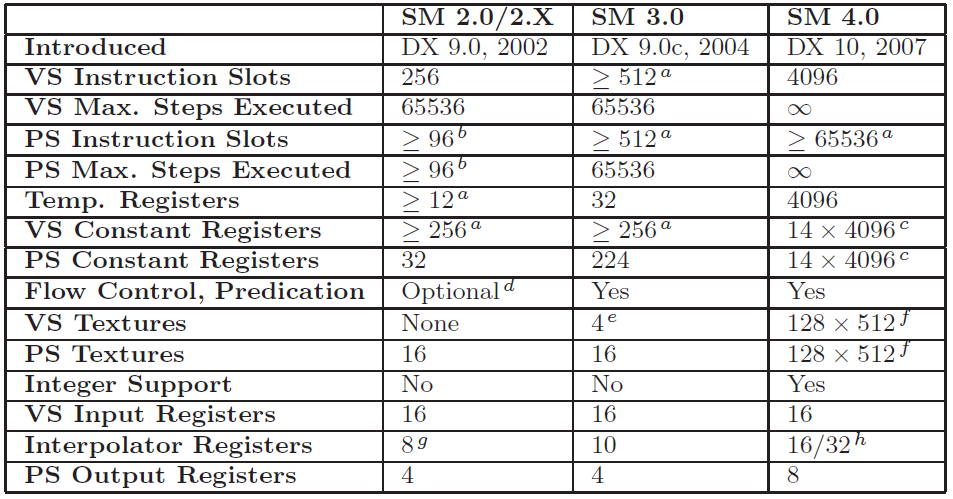
a
最低要求(如果需要可以使用更多)。
b
至少包含32个纹理和64个算术指令。
c
提供了14个constant buffers(其中有两个是私有的,保留给Microsoft/IHVs),每一个buffers最多可以包含4096个常量。
d
Vertex shader需要支持static flow control(基于常量的控制流)。
e
SM 3.0版本的硬件通常具有非常有限的格式,并且不包含用于vertex textures的滤波。
f
增长到128个纹理数组,数组的每一个元素最多可以包含512个纹理。
g
由于数据类型有限的精度和范围,不支持2个颜色插值。
h
Vertex shader输出16个插值,而geometry shader则可以输出32个。
表格3.1 列出了DirectX shader model各个版本[123,261,946,1055]的所支持的shader功能。
表格3.1中比较了各个shader models所能支持的功能。在该表格中,“VS”表示“vertex shader”,“PS”表示“pixel shader”(Shader Model 4.0引入了geometry shader,功能类似于vertex shader所提供的功能)。如果“VS”和“PS”都没有出现,就把表格的该行同时应用于vertex和pixel shaders中。由于shader虚拟机支持4路SIMD,因此每个寄存器都可以存储1到4个独立的变量。“Instruction Slots”是指shader能够包含的最大指令数量。“Max. Steps Executed”表示能够执行,处理分支以及循环运算的最大指令数量。“Temp. Registers”指出了用于存储运算的中间结果的通常寄存器数量。“Constant Registers”表示能够输入到shader中的常量的数量。“Flow Control,Prediction”是指该shader model是否支持计算条件表示式,以及通过分支指令和预测执行循环(即是否能够有条件地执行或者说跳过指令)。“Textures”表示shader能够读取的不同纹理(见第6章)的数量(每一个纹理可能会被读取多次)。“Integer Support”指是否支持通过位运算和整数算术操作整形数据类型。“VS Input Registers”指出了vertex shader能够读取的各种输入寄存器的数量。“Interpolator Registers”是vertex shader的输出寄存器,同时又是pixel shader的输入寄存器。之所以称为interpolator,是因为vertex shader的输出变量值在发送到pixel shader之前,会通过triangle进行插值计算。最后,“PS Output Registers”指出了pixel shader能够输出的寄存器数量—每一个输出寄存器绑定一个不同的buffer或者render target。















 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









