







- ECCV 2016
- Author: Hailin Shi, Yang Yang, Xiangyu Zhu, Shengcai Liao, Zhen Lei, Weishi Zheng, Stan Z. Li
Overview
- Re-id research topics:
- Improving discriminative features.
- Good metric for comparison.
- This paper mainly focus on learning good metrics.
- Influenced by face recognition method (the author also works on face recognition).
- Contributions:
- Moderate Positive Mining, a novel positive sample selection strategy for training CNN while the data has large intra-class variations.
- Metric weight constraint (combine Euclidean distance with Mahalanobis distance).
Moderate positive mining
- Intuitions
- Positive samples with large distance is harmful.
- Positive samples with too little distance have little contribution to convergance.
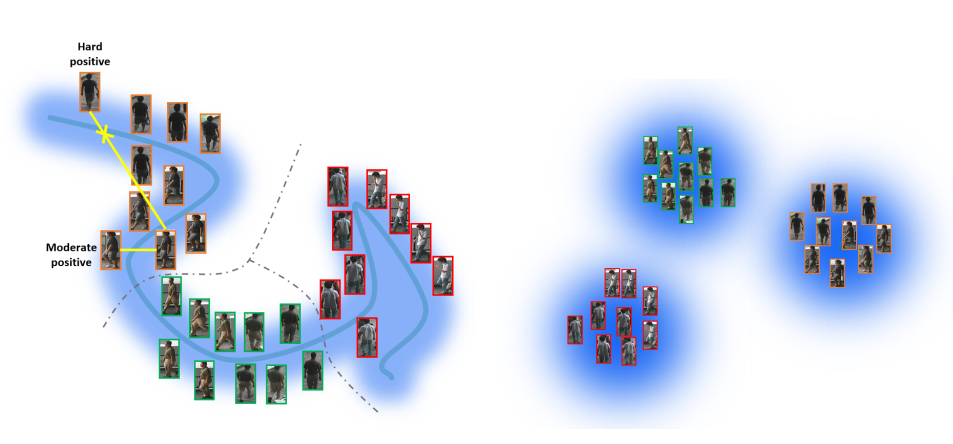
- What to do: reduce the intra-class variance while preserving the intrinsic graphical structure of pedestrian data via mining the moderate positive pairs in the local range (picture).
- Algorithm of choosing moderate positive sample (picture)
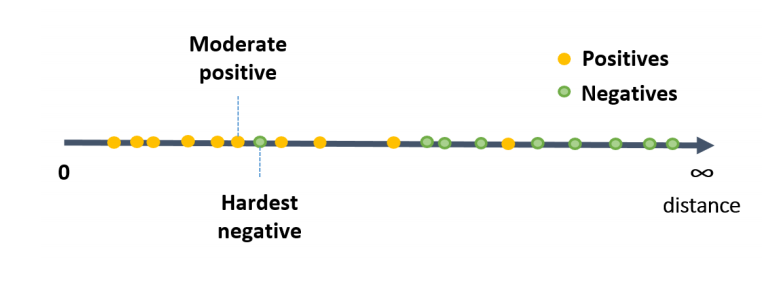
- Compute the distances of 1-all positive&negative samples
- Mine the hardest negative sample (min distance negative), distance=d∗
- Subset of positive samples where distance is larger than d∗
- In this subset, find positive pair with min distance – moderate positive
Metric weight constraint
- Euclidean distance shortcomings:
- Sensitive to the scale?
- Blind to the correlation across dimensions
- Using the Mahalanobis distance is a better choice for multivariate metric, argued by other work
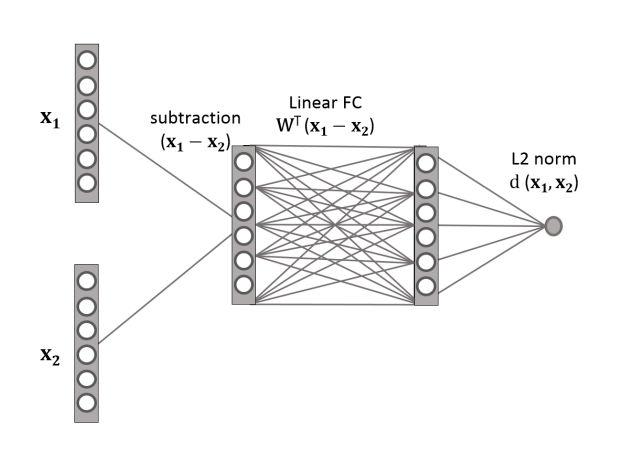
- Another FC after distance between features is calculated to gain Mahalanobis distance.
- Get Mahalanobis distance
- d(x1,x2)=(x1−x2)TM(x1−x2)‾‾‾‾‾‾‾‾‾‾‾‾‾‾‾‾‾‾‾√
- M=WWT (ensure M is semi-definate matrix)
d(x1,x2)=||WT(x1−x2)||2
- This can be implemented by an FC layer
y=f(WTx)
- Get Mahalanobis distance
- Weight constraint
- Euclidean better generalization ability, less discriminability.
- Balance between Euclidean and Mahalanobis distance.
-
M
should have large values at the diagonal (Euclidean) and small values elsewhere, by giving constraint:
||WWT−I||2F≤C
- Further combine the constraint into the loss function as a regularization term:
- Triplet loss: L=d(x1,xp2)+[m−d(x1,xn2)] (margin set to 2 in the experiment)
- Regularization: L̂ =L+λ2||WWT−I||2F (tune λ to get the best trade-off)
- Gradient w.r.t
W
is computed by
∂L̂ ∂W=∂L∂W+λ(WWT−I)W
CNN architecture
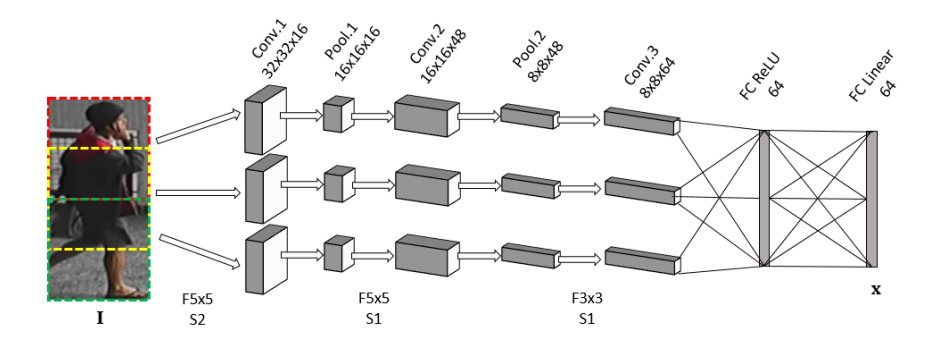
- 3 branches CNN
- Original image 128x64 => 3x64x64 (with overlap)
- Untied (unshared) filter between CNN branches to learn specific features from the different human body parts of pedestrian image.
Experiments
- Their baseline is very weak (worse than CUHK-03 baseline)
- Three parts are analyzed
- Moderate positive and hard negative (improve 10%+)
- Weight constraint, tune on λ ( λ around 10−2 gets good trade-off)
- Tied or untied filters between branches (Untied a little better)
- Augmentation
- Random translation
- Randomly cropped (0-5 pixels) in horizon and vertical, and stretched to recover the size
- Datasets
- CUHK03 (Rank-1: 61.32% with hand-crafted bbox, 52.09% with detected bbox)
- CUHK01 + Market-1501 in training (Rank-1: 86.59%)
- VIPeR (Rank-1: 43.39%)















 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









