







本文主要参考了http://www.cnblogs.com/xrwang/archive/2011/03/09/ransac-1.html
http://grunt1223.iteye.com/blog/961063
http://www.cnblogs.com/xrwang/p/SampleOfRansac.html
http://www.cnblogs.com/yin52133/archive/2012/07/21/2602562.html
例子:给定两个点可确定一条直线,判断第三个点是不是在这条直线上,只需判断第三个点是否符合这条直线的表达式,即向量计算。但在实际测量中,给定一组点,这组点的任意两点都可确定一条直线,由于测量误差,这些直线不一定一致,所以我们要找到适合这组点的直线,必须要这组点到这条直线模型Y=aX+b的误差最小。最小二乘法(线性回归)的思想是通过计算最小均方差关于参数a、b的偏导数为零时的值。但最小二乘法只适合噪声较小的数据,对于只有20%的点是正确点的时候,就不行了。下图就是最小二乘法不适用的时候。

局内点就是肉眼可看出的符合直线模型的点,离的比较远的点就是局外点。最小二乘法是适应于所有点的算法,所以不适用。这时就要用RANSAC算法了。
RANSAC是“RANdom SAmple Consensus(随机抽样一致)”的缩写。它可以从一组包含“局外点”的观测数据集中,通过迭代方式估计数学模型的参数。它是一种不确定的算法——它有一定的概率得出一个合理的结果;为了提高概率必须提高迭代次数。该算法最早由Fischler和Bolles于1981年提出。
RANSAC的基本假设是:
(1)数据由“局内点”组成,例如:数据的分布可以用一些模型参数来解释;
(2)“局外点”是不能适应该模型的数据;
(3)除此之外的数据属于噪声,局外点产生的原因有:噪声的极值;错误的测量方法;对数据的错误假设。
RANSAC也做了以下假设:给定一组(通常很小的)局内点,存在一个可以估计模型参数的过程;而该模型能够解释或者适用于局内点。在模型确定以及最大迭代次数允许的情况下,RANSAC总是能找到最优解。经过我的实验,对于包含80%误差的数据集,RANSAC的效果远优于直接的最小二乘法。
RANSAC通过反复选择数据中的一组随机子集来达成目标。被选取的子集被假设为局内点,并用下述方法进行验证:
1.有一个模型适应于假设的局内点,即所有的未知参数都能从假设的局内点计算得出。
2.用1中得到的模型去测试所有的其它数据,如果某个点适用于估计的模型,认为它也是局内点。
3.如果有足够多的点被归类为假设的局内点,那么估计的模型就足够合理。
4.然后,用所有假设的局内点去重新估计模型,因为它仅仅被初始的假设局内点估计过。
5.最后,通过估计局内点与模型的错误率来评估模型。
这个过程被重复执行固定的次数,每次产生的模型要么因为局内点太少而被舍弃,要么因为比现有的模型更好而被选用。
输入:
data —— 一组观测数据
model —— 适应于数据的模型
n —— 适用于模型的最少数据个数
k —— 算法的迭代次数
t —— 用于决定数据是否适应于模型的阀值
d —— 判定模型是否适用于数据集的数据数目
输出:
best_model —— 跟数据最匹配的模型参数(如果没有找到好的模型,返回null)
best_consensus_set —— 估计出模型的数据点
best_error —— 跟数据相关的估计出的模型错误
iterations = 0
best_model = null
best_consensus_set = null
best_error = 无穷大
while ( iterations < k ) //设置迭代次数为k
maybe_inliers = 从数据集中随机选择n个点
maybe_model = 适合于maybe_inliers的模型参数
consensus_set = maybe_inliers
for ( 每个数据集中不属于maybe_inliers的点 )
if ( 如果点适合于maybe_model,且错误小于t )
将点添加到consensus_set
if ( consensus_set中的元素数目大于d )
已经找到了好的模型,现在测试该模型到底有多好
better_model = 适合于consensus_set中所有点的模型参数
this_error = better_model究竟如何适合这些点的度量
if ( this_error < best_error )
我们发现了比以前好的模型,保存该模型直到更好的模型出现
best_model = better_model
best_consensus_set = consensus_set
best_error = this_error
增加迭代次数
返回 best_model, best_consensus_set, best_error
RANSAC算法的可能变化包括以下几种:
(1)如果发现了一种足够好的模型(该模型有足够小的错误率),则跳出主循环。这样可能会节约计算额外参数的时间。
(2)直接从maybe_model计算this_error,而不从consensus_set重新估计模型。这样可能会节约比较两种模型错误的时间,但可能会对噪声更敏感。对于输入的参数,根据特定的问题和数据集通过实验来确定参数t阈值和d适用的数目。
参数k可以通过理论进行估计:
用p表示一些迭代过程中从数据集内随机选取出的点均为局内点的概率;此时,结果模型很可能有用,因此p也表征了算法产生有用结果的概率。用w表示每次从数据集中选取一个局内点的概率,如式所示:w = 局内点的数目 / 数据集的数目。
事先并不知道w的值,但是可以给出一些鲁棒的值。假设估计模型需要选定n个点,wn是所有n个点均为局内点的概率;1 − wn是n个点中至少有一个点为局外点的概率,此时表明我们从数据集中估计出了一个不好的模型。 (1 − wn)k表示算法永远都不会选择到n个点均为局内点的概率,它和1-p相同。因此,
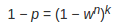
两边取对数:

值得注意的是,这个结果假设n个点都是独立选择的;也就是说,某个点被选定之后,它可能会被后续的迭代过程重复选定到。这种方法通常都不合理,由此推导出的k值被看作是选取不重复点的上限。例如,要从上图中的数据集寻找适合的直线,RANSAC算法通常在每次迭代时选取2个点,计算通过这两点的直线maybe_model,要求这两点必须唯一。

应用:
检测直线的过程
(1)随机从观测点中选择两个点,得到通过该点的直线;
(2)用(1)中的直线去测试其他观测点,由点到直线的距离确定观测点是否为局内点或者局外点;
(3)如果局内点足够多,并且局内点多于原有“最佳”直线的局内点,那么将这次迭代的直线设为“最佳”直线;
(4)重复(1)~(3)步直到找到最佳直线。检测圆的过程
(1)随机从观测点中选择三个点,尝试得到通过这三个点的圆;
(2)用(1)中的圆去测试其他观测点,由点到圆的距离确定观测点是否为局内点或者局外点;
(3)如果局内点足够多,并且局内点多于原有“最佳”圆的局内点,那么将这次迭代的圆设为“最佳”圆;
(4)重复(1)~(3)步直到找到最佳圆。
RANSAC算法的输入是一组观测数据,一个可以解释或者适应于观测数据的参数化模型,一些可信的参数。
用RANSAC算法是 从观测点云PB找一个随机的点对计算不变特征,找目标点云PR里特征最像的来匹配,计算qR和qT。模型对应的是空间中一个点云数据到另外一个点云数据的旋转以及平移。

第一步随机得到的是一个点云中的点对 ,利用其不变特征(两点距离,两点法向量夹角)作为哈希表的索引值搜索另一个点云中的一对对应点对,然后计算得到旋转及平移的参数值。
然后适用变换,找到其他局内点,并在找到局内点之后重新计算旋转及平移为下一个状态。
然后迭代上述过程,找到最终的位置。
RANSAC算法经常用于计算机视觉,例如同时求解相关问题与估计立体摄像机的基础矩阵。
图片的拼接技术。由于镜头的限制,往往需要多张照片才能拍下那种巨幅的风景。在多幅图像合成时,事先会在待合成的图片中提取一些关键的特征点。计算机视觉的研究表明,不同视角下物体往往可以通过一个透视矩(3X3或2X2)阵的变换而得到。RANSAC被用于拟合这个模型的参数(矩阵各行列的值),由此便可识别出不同照片中的同一物体。
RANSAC还可以用于图像搜索时的纠错与物体识别定位。有几条直线是SIFT匹配算法的误判,RANSAC有效地将其识别,并将正确的模型用线框标注出来。在opencv的三维重构和标定模块中有很多应用,如solvePnPRansac,findHomography,estimateAffine3D等。
附录:最小二乘法的算法
#include <math.h>
#include "LineParamEstimator.h"
LineParamEstimator::LineParamEstimator(double delta) : m_deltaSquared(delta*delta) {}
/*****************************************************************************/
/*
* Compute the line parameters [n_x,n_y,a_x,a_y]
* 通过输入的两点来确定所在直线,采用法线向量的方式来表示,以兼容平行或垂直的情况
* 其中n_x,n_y为归一化后,与原点构成的法线向量,a_x,a_y为直线上任意一点
*/
void LineParamEstimator::estimate(std::vector<Point2D *> &data,
std::vector<double> ¶meters)
{
parameters.clear();
if(data.size()<2)
return;
double nx = data[1]->y - data[0]->y;
double ny = data[0]->x - data[1]->x;// 原始直线的斜率为K,则法线的斜率为-1/k
double norm = sqrt(nx*nx + ny*ny);
parameters.push_back(nx/norm);
parameters.push_back(ny/norm);
parameters.push_back(data[0]->x);
parameters.push_back(data[0]->y);
}
/*****************************************************************************/
/*
* Compute the line parameters [n_x,n_y,a_x,a_y]
* 使用最小二乘法,从输入点中拟合出确定直线模型的所需参量
*/
void LineParamEstimator::leastSquaresEstimate(std::vector<Point2D *> &data,
std::vector<double> ¶meters)
{
double meanX, meanY, nx, ny, norm;
double covMat11, covMat12, covMat21, covMat22; // The entries of the symmetric covarinace matrix
int i, dataSize = data.size();
parameters.clear();
if(data.size()<2)
return;
meanX = meanY = 0.0;
covMat11 = covMat12 = covMat21 = covMat22 = 0;
for(i=0; i<dataSize; i++) {
meanX +=data[i]->x;
meanY +=data[i]->y;
covMat11 +=data[i]->x * data[i]->x;
covMat12 +=data[i]->x * data[i]->y;
covMat22 +=data[i]->y * data[i]->y;
}
meanX/=dataSize;
meanY/=dataSize;
covMat11 -= dataSize*meanX*meanX;
covMat12 -= dataSize*meanX*meanY;
covMat22 -= dataSize*meanY*meanY;
covMat21 = covMat12;
if(covMat11<1e-12) {
nx = 1.0;
ny = 0.0;
}
else { //lamda1 is the largest eigen-value of the covariance matrix
//and is used to compute the eigne-vector corresponding to the smallest
//eigenvalue, which isn't computed explicitly.
double lamda1 = (covMat11 + covMat22 + sqrt((covMat11-covMat22)*(covMat11-covMat22) + 4*covMat12*covMat12)) / 2.0;
nx = -covMat12;
ny = lamda1 - covMat22;
norm = sqrt(nx*nx + ny*ny);
nx/=norm;
ny/=norm;
}
parameters.push_back(nx);
parameters.push_back(ny);
parameters.push_back(meanX);
parameters.push_back(meanY);
}
/*****************************************************************************/
/*
* Given the line parameters [n_x,n_y,a_x,a_y] check if
* [n_x, n_y] dot [data.x-a_x, data.y-a_y] < m_delta
* 通过与已知法线的点乘结果,确定待测点与已知直线的匹配程度;结果越小则越符合,为
* 零则表明点在直线上
*/
bool LineParamEstimator::agree(std::vector<double> ¶meters, Point2D &data)
{
double signedDistance = parameters[0]*(data.x-parameters[2]) + parameters[1]*(data.y-parameters[3]);
return ((signedDistance*signedDistance) < m_deltaSquared);
} RANSAC算法
/*****************************************************************************/
template<class T, class S>
double Ransac<T,S>::compute(std::vector<S> ¶meters,
ParameterEsitmator<T,S> *paramEstimator ,
std::vector<T> &data,
int numForEstimate)
{
std::vector<T *> leastSquaresEstimateData;
int numDataObjects = data.size();
int numVotesForBest = -1;
int *arr = new int[numForEstimate];// numForEstimate表示拟合模型所需要的最少点数,对本例的直线来说,该值为2
short *curVotes = new short[numDataObjects]; //one if data[i] agrees with the current model, otherwise zero
short *bestVotes = new short[numDataObjects]; //one if data[i] agrees with the best model, otherwise zero
//there are less data objects than the minimum required for an exact fit
if(numDataObjects < numForEstimate)
return 0;
// 计算所有可能的直线,寻找其中误差最小的解。对于100点的直线拟合来说,大约需要100*99*0.5=4950次运算,复杂度无疑是庞大的。一般采用随机选取子集的方式。
computeAllChoices(paramEstimator,data,numForEstimate,
bestVotes, curVotes, numVotesForBest, 0, data.size(), numForEstimate, 0, arr);
//compute the least squares estimate using the largest sub set
for(int j=0; j<numDataObjects; j++) {
if(bestVotes[j])
leastSquaresEstimateData.push_back(&(data[j]));
}
// 对局内点再次用最小二乘法拟合出模型
paramEstimator->leastSquaresEstimate(leastSquaresEstimateData,parameters);
delete [] arr;
delete [] bestVotes;
delete [] curVotes;
return (double)leastSquaresEstimateData.size()/(double)numDataObjects;
} 优点与缺点
RANSAC的优点是它能鲁棒的估计模型参数。例如,它能从包含大量局外点的数据集中估计出高精度的参数。RANSAC的缺点是它计算参数的迭代次数没有上限;如果设置迭代次数的上限,得到的结果可能不是最优的结果,甚至可能得到错误的结果。RANSAC只有一定的概率得到可信的模型,概率与迭代次数成正比。RANSAC的另一个缺点是它要求设置跟问题相关的阀值。
RANSAC只能从特定的数据集中估计出一个模型,如果存在两个(或多个)模型,RANSAC不能找到别的模型。















 195
195











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









