







首先 明白一个关键点:
self attetion: 自注意力, 什么叫做自注意力;
衡量各个输入向量之间的关联度,(或称相关性)
- 自注意力的本意:
举例讲来, 现在有一个输入序列, 该输入序列由12 个向量构成,
那么自注意力,便是对这12个输入向量之间, 相互算各自的关联性, 这是自注意力的初衷;
而在输入的多个向量之间寻找相关性, 这个相关性,通过注意力分数来体现了。
- 多头注意力:
理解这一点, 便知道了 多头注意力的 思想了;
单个自注意力, 使用的是一种方式来衡量了 各个输入向量之间的相关性;
那么,多个注意力便是用多种方式来衡量各个输入向量之间的相关性;
1. 模型的输入
1.1 输入单个向量 或 多个向量
现实任务中,
-
有输入单个向量的任务;
-
也有同时输入多个向量, 即输入一个序列;

1.2 输入vector的生成
输入向量的编码有多种形式:
-
one-hot encoding:
[ 1 0 0 0 0 0 …] -
Word Embedding:
相比于 One hot 向量, 词嵌入向量,会包含语义的信息,
每个词汇对应一个 向量, 一个句子 对应了 多个 长度不相等的向量, 此时一个句子, 是一个序列 sequence,
比方说 将词嵌入向量 二维坐标表示出来是, 给个类别的下 的 实例, 会各自 聚类在某一处;

-
将一帧长度的音频信号 表示成 一个向量;
即 有 多种 做法, 可以 用一个向量 来 表示出 一帧 长度内的语音信号;
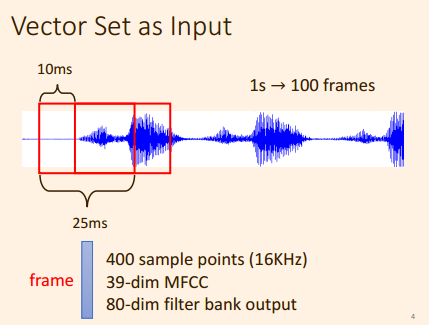
1.3 输入与输出
这里着重介绍第一种, 输出向量的长度, 与输入向量的个数对应;
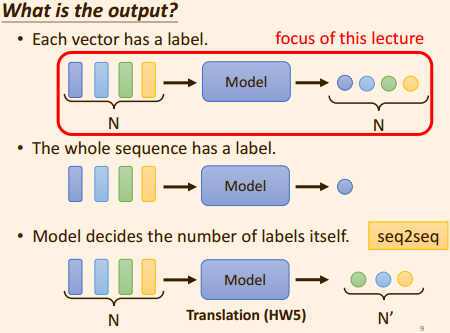
2. self-attention 产生的原因:
以 词性标注任务,
对一个句子 输入的每一个单词 进行 词性划分;

例如 :i saw a saw;
第一个saw 是 动词, 第二saw 是 名词 锯子;
此时,如何解决 对于全连接层, 相同的输入, 却要输出不同的结果?
解决方法: 考虑输入的上下文信息, 即该输入的前几个输入, 以及后面的几个输入, 考虑上下文的信息;
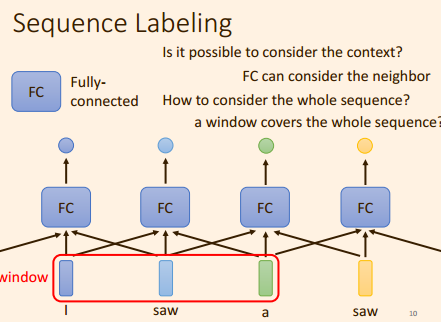
但是, 此时 又存在另外一个问题: 考虑输入的前多少个, 后多少个信息 才算合适的呢?
如果,将整个输入序列都覆盖住, 这样不但会增加FC 层的参数, 而且很容易产生过拟合;
那么输入时,该考虑输入的前后多少个信息才合适呢?
为了解决这个 问题, self -attention 出现了,
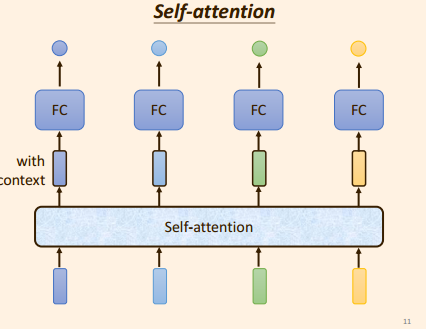
将单个向量
V
V
V 输入到 self attention 中:
self-attention 会考虑 整个输入序列,
得到一个包含上下文信息的向量
V
1
V1
V1 ,(即包含了 V的前后向量的信息);
然后在将包含上下文信息的向量
V
1
V1
V1 输入到 FC层中;
相比没有self attention 时, 是直接将 输入 V V V 输入到 FC层中;
从而FC 处理单个向量中的信息, 而 self -attention 处理了多个向量之间信息(即整个序列);
2.1 self -attention 实现机理:
那么 self -attention 是
如何做到将一个输入的向量经过变换之后 获得上下文信息的向量?
-
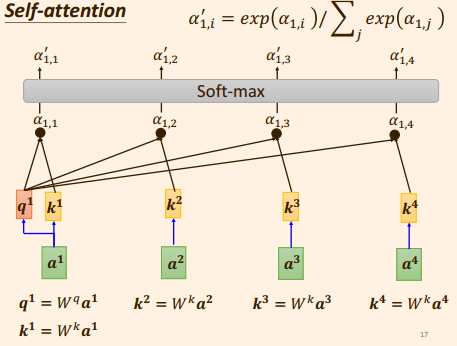
计算单个向量 a 1 a_1 a1 与 其他输入向量 a j a_j aj之间的 注意力分数 α 1 , j \alpha_{1,j} α1,j;

-
那么注意力分数 α 1 , j \alpha_{1,j} α1,j 是如何实现的呢? 计算过程?
2.1: 求出向量 a 1 a^1 a1 本身的咨询值 query: q 1 q^1 q1 ;( q 1 q^1 q1 由参数矩阵 w q w^q wq 与 a 1 a^1 a1 相乘获得;)
q 1 = W q a 1 q^1 = W^q a^1 q1=Wqa12.2: 求出向量 a 2 a^2 a2 的 key值: k 2 k^2 k2 . ( k 2 k^2 k2 由参数矩阵 w k w^k wk 与 a 2 a^2 a2 相乘获得:)
k 2 = W k a 2 k^2 = W^k a^2 k2=Wka2
2.3: 将 q 1 q^1 q1 与 k 2 k^2 k2 两者做点积, 得到 a 1 a^1 a1与 a 2 a^2 a2 之间的注意力分数 α 1 , 2 \alpha_{1,2} α1,2 ;
注意, 这里是否可以将 点积 换成 相加, Fastformer论文?

-
从而求出向量 a 1 a^1 a1 与其他输入向量 a j a^j aj 之间的注意力分数;

-
然后各个相关性 分数 α 1 , j \alpha_{1,j} α1,j 通过一个 softamax , 得到一个归一化后的注意力分数 α 1 , j ’ \alpha^’_{1,j} α1,j’ . (softmax 也可以换成relu 实验一下)
- 此时, 先产生另外一个变量
v
i
v^i
vi,
v
i
v^i
vi通过参数矩阵
w
v
w^v
wv 与自身向量
a
i
a^i
ai 两者之间相乘得到;
V i = W v a i V^i = W^v a^i Vi=Wvai

- 然后, 将 各个注意力分数 α 1 , j ’ \alpha^’_{1,j} α1,j’ 与每一个自身的 v i v^i vi 相乘得到一个向量, 将这些向量求和, 得到最终的 b 1 b^1 b1;
由此可知, 注意力分数
α
1
,
j
’
\alpha^’_{1,j}
α1,j’, 与
v
i
v^i
vi 最大的,将会主导
b
1
b^1
b1 的产生;

- 重复上述过程,我们便得到经过 self attention 的各个
b
j
b ^j
bj;
















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









