







 本文是Pandas数据分析系列的第四篇,主要介绍数据拼接(行堆叠与列拼接)和数据透视操作。通过concat和merge函数实现数据的横向和纵向合并,并探讨了不同参数的用法。同时,讲解了unstack和stack方法在数据透视中的应用。
本文是Pandas数据分析系列的第四篇,主要介绍数据拼接(行堆叠与列拼接)和数据透视操作。通过concat和merge函数实现数据的横向和纵向合并,并探讨了不同参数的用法。同时,讲解了unstack和stack方法在数据透视中的应用。
Pandas系列目录(文末有惊喜大礼喔):
Pandas数据分析①——数据读取(CSV/TXT/JSON)
Pandas数据分析②——数据清洗(重复值/缺失值/异常值)
Pandas数据分析③——数据规整1(索引和列名调整/数据内容调整/排序)
Pandas数据分析⑤——数据分组与函数使用(Groupby/Agg/Apply/mean/sum/count)
Pandas数据分析⑥——数据分析实例(货品送达率与合格率/返修率/拒收率)
Pandas数据分析⑦——数据分析实例2(泰坦尼克号生存率分析)
数据规整是在数据清洗完毕后,将其调整成适合分析的结构,为后续的深入分析作准备,主要分为以下几类:
索引和列名调整: 设定新索引,筛选想要的列,更改列名
数据排序:根据索引或列进行排序
数据格式调整:更改数据类型,更改数据内容(去除空格标点符号/截取/替换/统一数据单位等),增加用于分析的辅助列
数据拼接:行堆叠和列拼接
数据透视:行或列维度转换
上一篇介绍前3种,本篇介绍后2种
一、数据拼接
1、行堆叠
① concat(objs, axis=0, join=‘outer’, join_axes=None, ignore_index=False,
keys=None, levels=None, names=None, verify_integrity=False,
copy=True)
参数说明:
objs: 拼接的series或dataframe
axis:拼接轴方向,默认为0,沿行拼接;若为1,沿列拼接
join:默认外联’outer’,拼接另一轴所有的label,缺失值用NaN填充;内联’inner’,只拼接另一轴相同的label;
join_axes: 指定需要拼接的轴的labels,可在join既不内联又不外联的时候使用
ignore_index:对index进行重新排序
keys:多重索引,便于区分来源表
sort: 按值排序
② Series 使用
s1 = pd.Series([0, 1], index=['a', 'b'])
s2 = pd.Series([2, 3, 4], index=['c', 'd', 'e'])
s3 = pd.Series([5, 6], index=['f', 'g'])
print(s1)
print(s2)
print(s3)
print(pd.concat([s1, s2, s3], axis=1)) # 沿着axis=1会有多列,没有指定join则默认outer
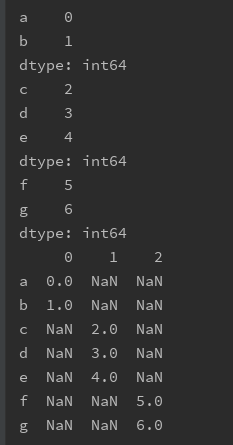
s4 = pd.concat([s 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章

















 2478
2478

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









