






公众号:dify实验室
基于LLMOps平台-Dify的一站式学习平台。包含不限于:Dify工作流案例、DSL文件分享、模型接入、Dify交流讨论等各类资源分享。
前言
单一信息源往往难以满足双重需求:仅依赖内部知识库可能导致信息滞后,无法回应最新事件或进展;而单纯依赖实时网络搜索,则可能面临信息过载、质量参差不齐、缺乏权威性等问题。为了克服这些挑战,我们可以设计一个能够智能协同内部知识库与外部互联网搜索,并最终由大型语言模型(LLM)进行深度整合与精准回答的高级工作流。
本文将详细拆解该工作流的设计理念、节点配置、数据流转及核心优势,为您呈现一个构建强大智能问答系统的实践蓝图。
工作流核心设计思想
本工作流的核心在于“分而治之”与“合而为一”。首先,通过LLM初步理解用户意图,生成多元化的深度搜索指令数组;其次,并行地、有针对性地从内部知识库和外部互联网这两个互补的信息渠道搜集素材;最后,再次利用LLM的强大理解与生成能力,将搜集到的碎片化信息,结合用户的原始问题,融合成一个高质量、高相关的统一答案。DSL文件见文末。
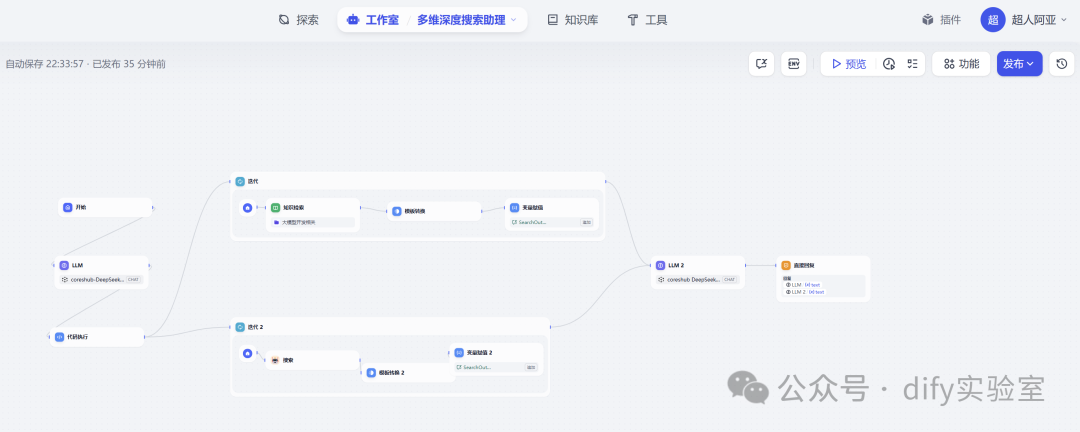
工作流详细步骤拆解
第一步:开始节点 - 用户提问的入口与起点
- 节点类型: 开始
- 功能: 作为整个工作流的触发器,负责接收并承载用户通过界面或API传入的原始问题。这个输入是驱动后续所有处理逻辑的源头。
- 重要性: 用户问题的清晰度与具体性直接影响后续搜索词生成和最终答案的质量。
- 示例输入: 用户可能输入如:“请详细介绍一下近期国家发布的关于人工智能伦理治理的新政策,并分析其可能对AI创业公司带来的机遇与挑战?”
- 输出: 用户的原始提问字符串,将作为变量传递给下一个节点。
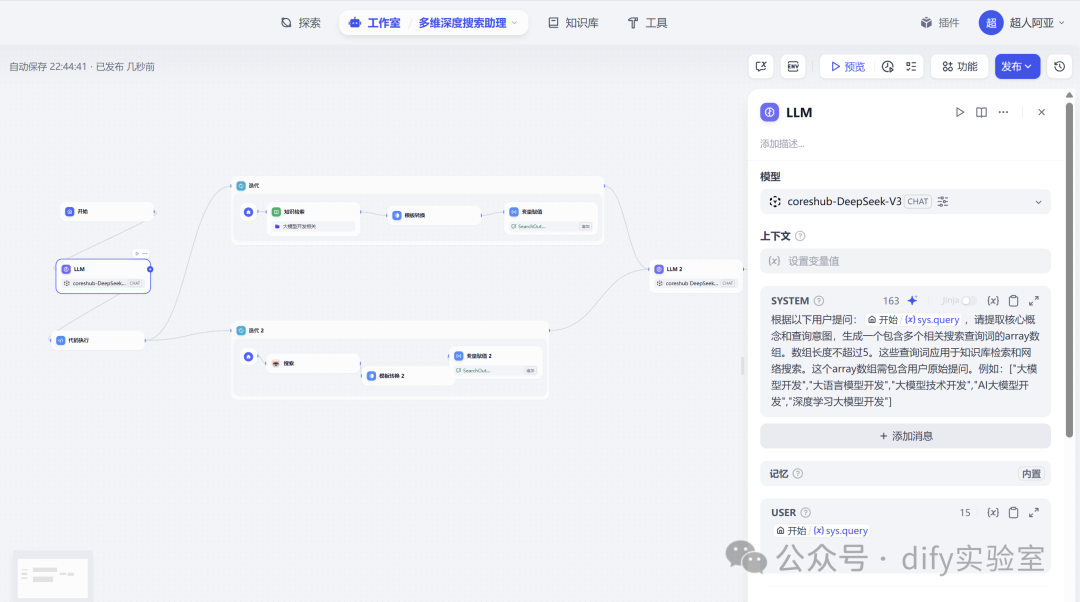
第二步:LLM节点 - 智能解析与搜索词策略化构建
- 节点类型: LLM
- 核心任务: 对用户的原始提问进行深度语义理解,并基于此生成一个结构化的、包含多个相关搜索查询词的数组(列表)。这不仅仅是关键词提取,更是一种基于意图理解的查询扩展和细化。
- 输入: 来自「开始」节点的原始用户提问字符串。
- 提示词:
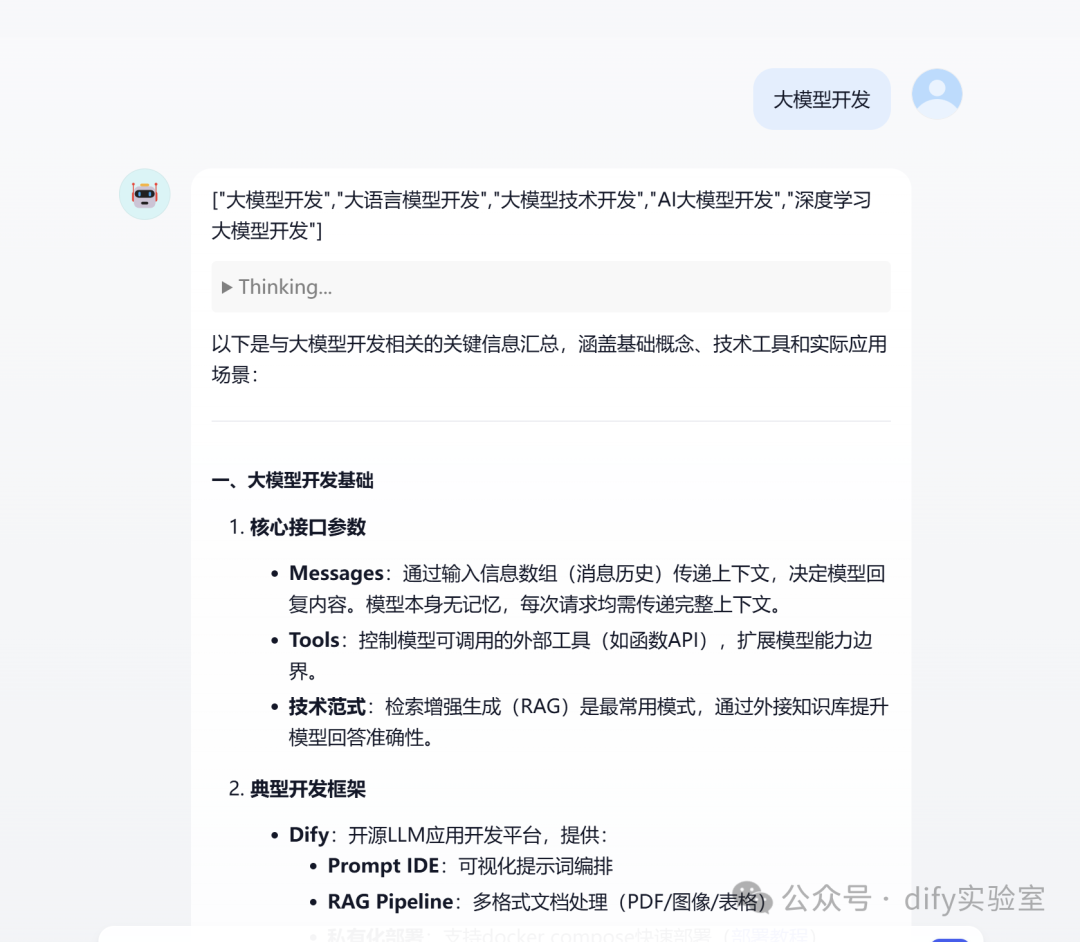
- 根据以下用户提问:'{user_query}',请提取核心概念和查询意图,生成一个包含多个相关搜索查询词的array数组。数组长度不超过5。这些查询词应用于知识库检索和网络搜索。这个array数组需包含用户原始提问。例如:["大模型开发","大语言模型开发","大模型技术开发","AI大模型开发","深度学习大模型开发"]
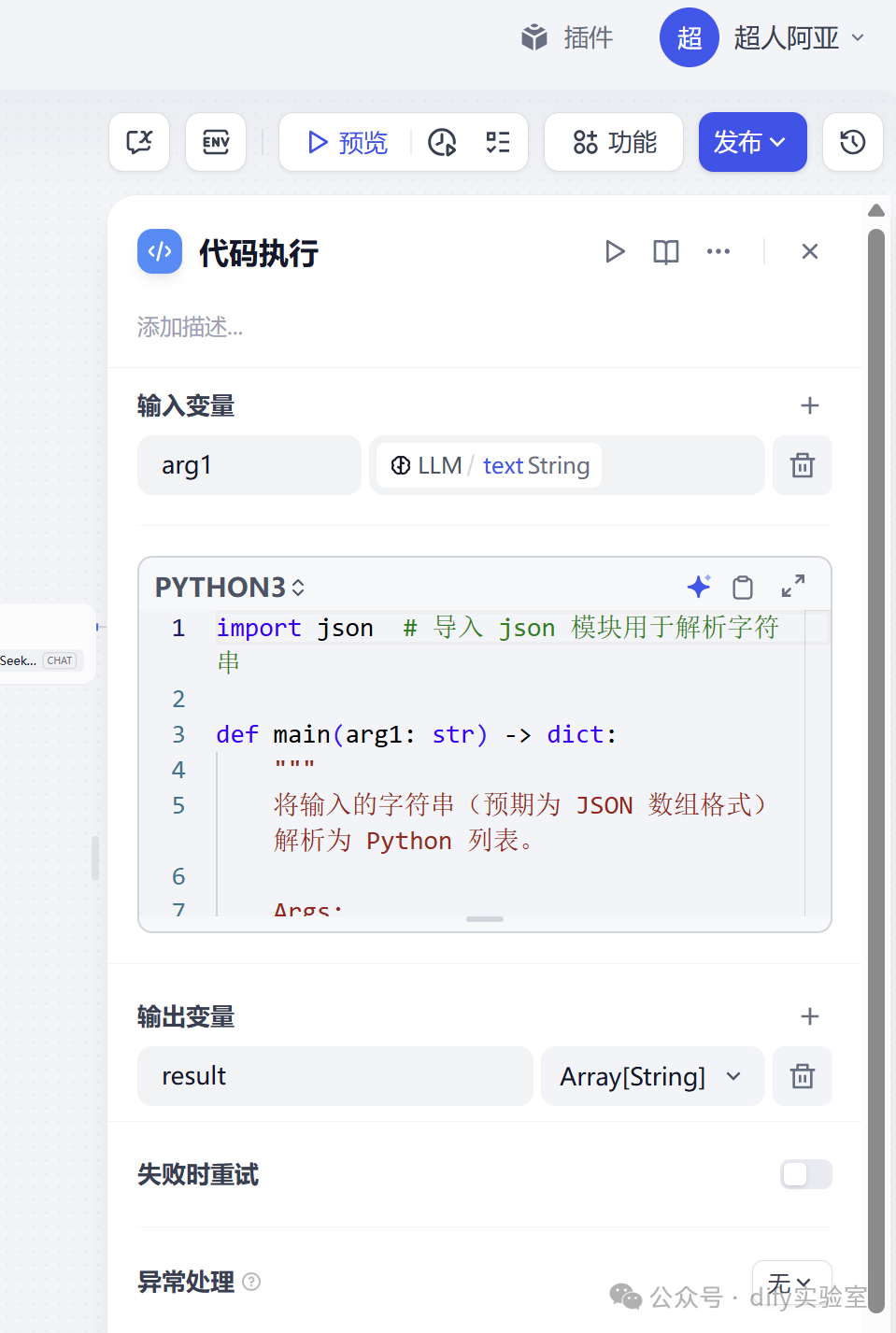
第三步:将代码执行节点将变量类型由string转为array
第四步:并行信息获取 - 知识库深度挖掘与网络实时追踪
这是工作流的核心效率体现环节。上一步生成的数组将作为输入,同时流向两个独立的处理分支。
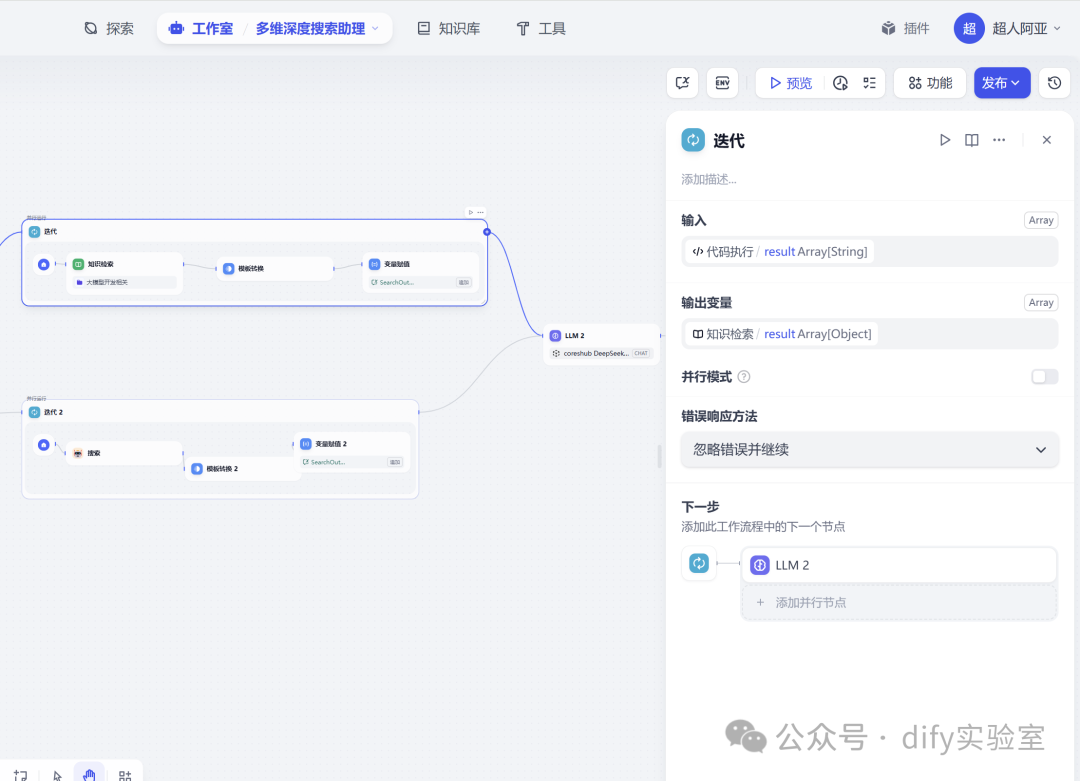
- 分支一:知识库检索 (迭代执行)
- 节点类型: 迭代
- 输入:数组变量。
- 配置:
a.选择或配置需要检索的目标知识库(可以是企业内部文档、产品手册、历史问答对等)。
b.设置迭代:启用对输入数组的迭代功能。这意味着节点将自动遍历数组中的每一个搜索词。
c.配置检索参数:如每个搜索词返回的Top-K相关文档片段数量、相关性阈值等。
-
- 处理逻辑: 对于数组中的每一个搜索词,节点会在指定的知识库中执行一次独立的语义检索,找出最相关的若干信息片段。
- 输出与变量赋值:
a.关键操作:追加赋值。每次迭代检索到的结果(文本片段),都需要被追加到一个预先定义的「会话变量」中。我们设定一个名为SearchOutput 的会话变量。
b.每次迭代后,SearchOutput 的内容会逐渐增长,累积来自知识库的上下文信息。
- 分支二:联网搜索 (并行迭代执行)
·节点类型: 迭代-工具 (Tool) 节点
参照文章:哪有这样的好事!教你使用Dify接入联网搜索功能 还能领取1亿token
·输入: 同样是数组变量。
·配置:
a.同样设置迭代模式:启用对输入数组 search_queries 的迭代。
·处理逻辑: 与知识库分支类似,对于数组中的每一个搜索词,此节点会调用外部搜索引擎执行一次实时的网络搜索,获取最新的网页摘要、新闻报道或其他相关网络信息。
·输出与变量赋值:
a.同样执行追加赋值操作。 将每次迭代从网络上获取的相关搜索结果(通常是文本摘要或片段),追加到同一个会话变量SearchOutput中。
b.这样,SearchOutput就同时包含了知识库和网络搜索两方面的信息。
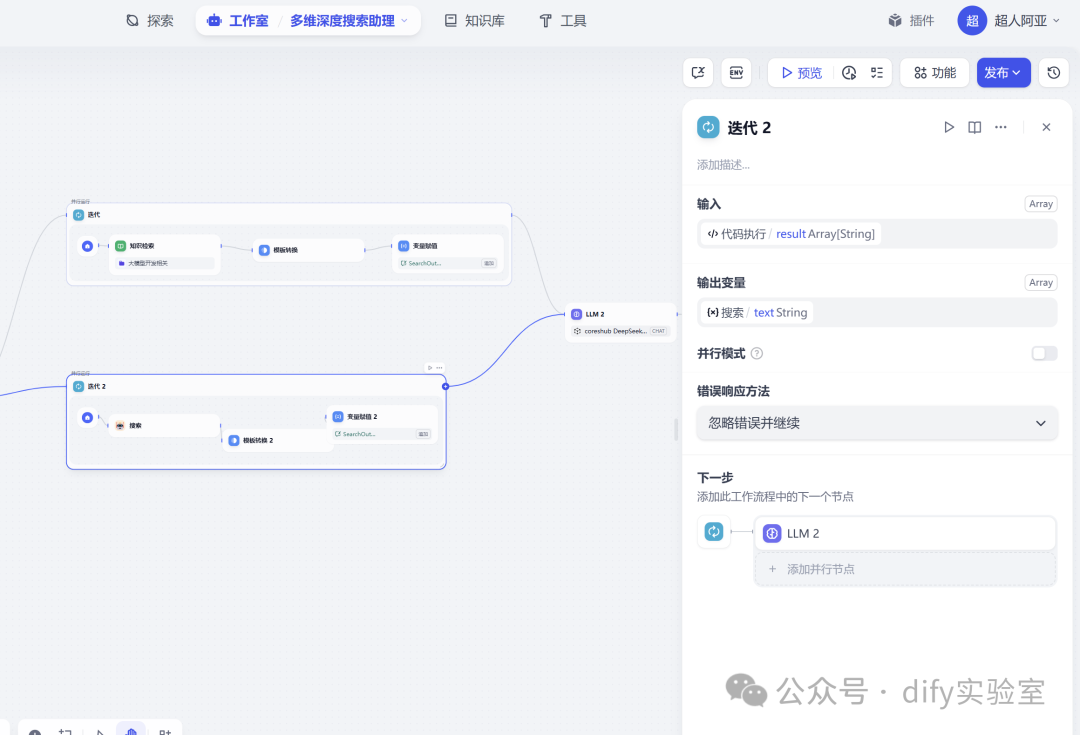
- 并行机制的意义: Dify平台支持并行执行没有直接依赖关系的分支。这两个检索分支都依赖于第二步LLM节点的输出,但它们之间相互独立。并行执行意味着知识库检索和网络搜索可以同时进行,极大地缩短了信息收集阶段的总耗时,提升了工作流的响应速度。工作流会等待这两个并行分支都执行完毕后,才进入下一步。
第五步:信息汇聚点 - 会话变量 SearchOutput
- 角色: 作为一个动态累积的信息池(缓冲区)。
- 内容: 此时,SearchOutput 变量内部已经聚合了通过多个搜索词、从内部知识库和外部互联网两个渠道检索到的所有相关文本信息片段。它可能包含重复或冗余的信息,但确保了信息来源的广泛性。
- 状态: 准备就绪,为最终的答案生成提供丰富的、多源的原始上下文素材。
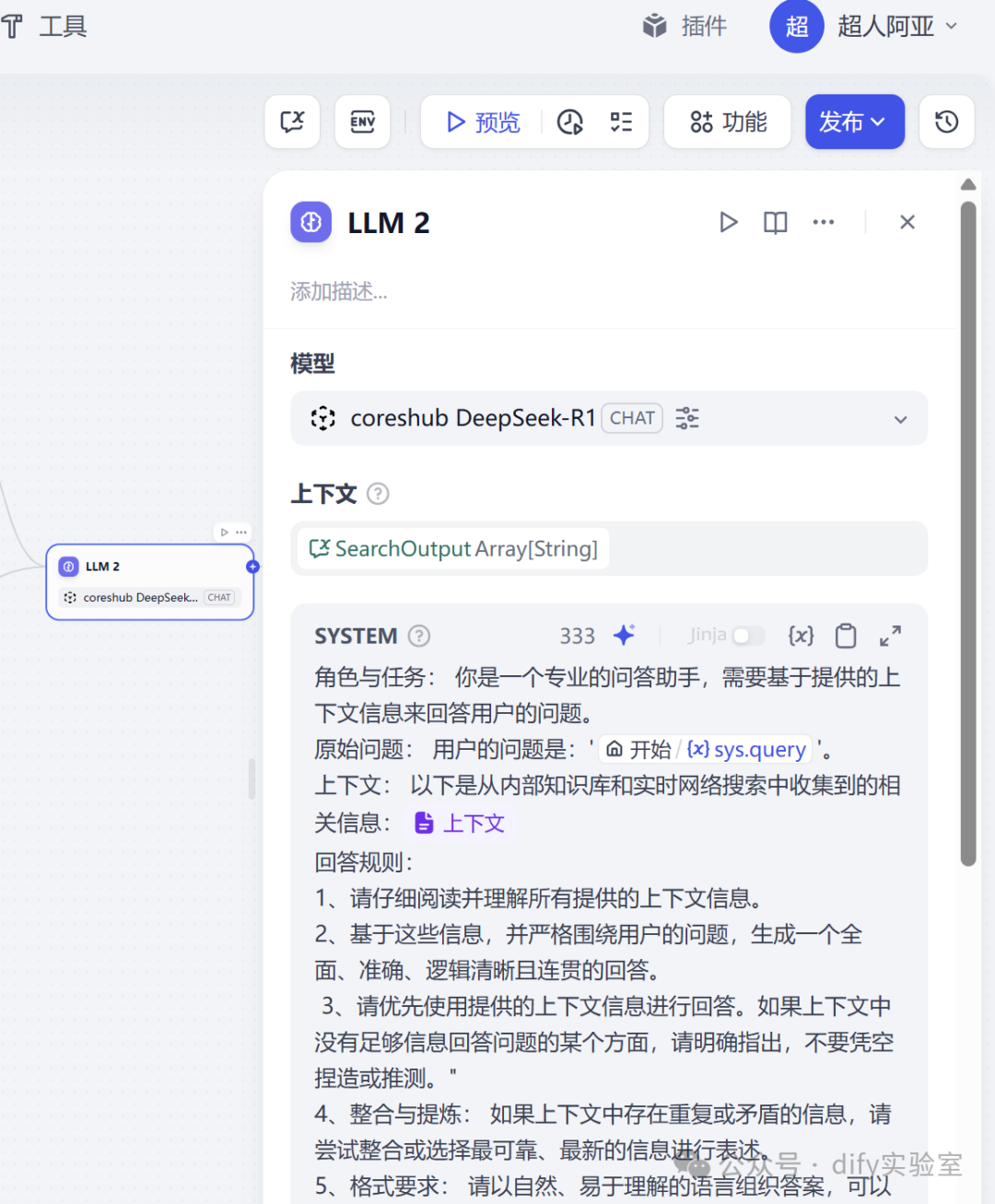
第六步:LLM节点 - 上下文感知、信息整合与答案生成
- 节点类型: LLM
- 核心任务: 这是工作流的“智慧大脑”,负责将前面收集到的零散信息进行深度加工,生成最终面向用户的答案。
- 输入:
- 原始用户提问: 从「开始」节点直接传入,确保LLM始终围绕用户的核心问题进行回答。
- 汇聚的上下文信息: 即会话变量 SearchOutput的全部内容。
- 提示词设计:(提示词详见文末DSL文件)
a.明确角色与任务: "你是一个专业的问答助手,需要基于提供的上下文信息来回答用户的问题。"
b.提供原始问题: "用户的问题是:'{original_user_query}'。"
c.提供上下文: "以下是从内部知识库和实时网络搜索中收集到的相关信息:\n{context_collection}\n---"
d.设定回答规则:
·"请仔细阅读并理解所有提供的上下文信息。"
·"基于这些信息,并严格围绕用户的问题,生成一个全面、准确、逻辑清晰且连贯的回答。"
·强调基于上下文: "请优先使用提供的上下文信息进行回答。如果上下文中没有足够信息回答问题的某个方面,请明确指出,不要凭空捏造或推测。" (这是减少LLM“幻觉”的关键指令)
·整合与提炼: "如果上下文中存在重复或矛盾的信息,请尝试整合或选择最可靠、最新的信息进行表述。"
·格式要求: "请以自然、易于理解的语言组织答案,可以适当分点或分段。"
- 输出: 经过LLM深度理解、分析、整合、提炼后生成的最终答案文本。
第六步:结束节点 - 答案的最终呈现
- 节点类型: 结束
- 功能: 作为工作流的终点,负责接收上一步LLM节点生成的最终答案,并将其输出。这个输出可以展示在Dify的应用界面上,也可以通过API返回给调用方。
- 用户体验: 用户最终看到的是一个经过多源信息融合、精心组织的回应,而非简单的检索结果罗列。
适用场景举例
- 企业级智能客服/虚拟助手: 解答客户关于产品特性(知识库)和相关行业新闻/竞品动态(网络)的问题。
- 研究与分析辅助: 为研究人员快速汇总内部研究报告(知识库)和最新的学术论文/市场报告(网络)的关键信息。
- 内容创作与写作支持: 辅助作者收集特定主题的背景资料,既包括内部积累的素材(知识库),也涵盖当前热点和公开数据(网络)。
- 金融/法律/医疗等专业领域咨询: 结合内部法规库/案例库(知识库)与最新的政策发布/市场变动/医学进展(网络),提供初步的咨询建议。
结语
通过精心设计上述Dify工作流,我们能够构建一个远超单一信息源能力的智能问答系统。它不仅能够理解用户的复杂需求,还能高效、智能地整合内部知识沉淀与外部实时信息,最终生成既权威准确又与时俱进的高质量答案。
关注我可领DSL文件及token福利
往期工作流文章
10分钟构建基于 Dify 的智能文章仿写工作流:配置指南,效率飙升300%!
20分钟从零到一构建Dify智能客服工作流教程(附DSL文件下载)
告别手工录票!Dify 工作流分享:打造多票据识别机器人(附DSL文件)
更多工作流案例,请到公众号主页查看
dify相关资源
如果对你有帮助,欢迎点赞收藏备用。
回复 DSL 获取公众号DSL文件资源
回复 入群 获取二维码,我拉你入群
回复 tk 获取免费token资源
对你有用就点赞后(不点也无妨)从如下地址下载本文 DSL文件:
链接:https://pan.baidu.com/s/1A4RcAFtJCAAfVARTjiG5j
提取码: sbmy
如地址失效,请到公众号主页获取回复 DSL 获取。

















 518
518

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









