






引言
Meta Llama 3.2多语言大型语言模型集合(LM)是一个1B和3B大小(文本输入/文本输出)的预训练和指令微调模型集合。Llama 3.2指令调整的纯文本模型针对多语言对话用例进行了优化,包括智能检索和总结任务。它们在常见的行业基准上优于许多可用的开源和闭源聊天模型。
环境准备
安装Ascend CANN Toolkit和Kernels
安装方法请参考 安装教程或使用以下命令。
安装openMind Library以及openMind Hub Client
- 安装openMind Hub Client
- 安装openMind Library,并安装PyTorch框架及其依赖。
更详细的安装信息请参考openMind官方的 环境安装章节。
安装llama-factory
模型链接和下载
Llama-3.2-3B模型系列由社区开发者在魔乐社区贡献,包括:
- Llama-3.2-3B: https://modelers.cn/models/AI-Research/Llama-3.2-3B
- Llama-3.2-3B-Instruct: https://modelers.cn/models/AI-Research/Llama-3.2-3B-Instruct
通过Git从魔乐社区下载模型的repo,以Llama-3.2-3B-Instruct为例:
模型推理
用户可以使用openMind Library或者LLaMa Factory进行模型推理,以Llama-3.2-3B-Instruct为例,具体如下:
- 使用openMind Library进行模型推理
新建推理脚本inference_llama3.2_3b_chat.py,推理脚本内容为:
执行推理脚本:
推理结果如下:

- 使用LLaMa Factory与模型交互
在LLaMa Factory路径下新建examples/inference/llama3.2_3b_chat.yaml推理配置文件,文件内容为:
使用以下命令与模型进行交互:
交互结果如下:

模型微调
数据集
使用Llama-Factory集成的identity数据集。
修改data/identity.json,将{{name}}替换为openmind,{{author}}替换为shengteng。
微调
新建examples/train_lora/llama3.2_3b_lora_sft.yaml 微调配置文件,微调配置文件如下:
使用以下命令进行微调:
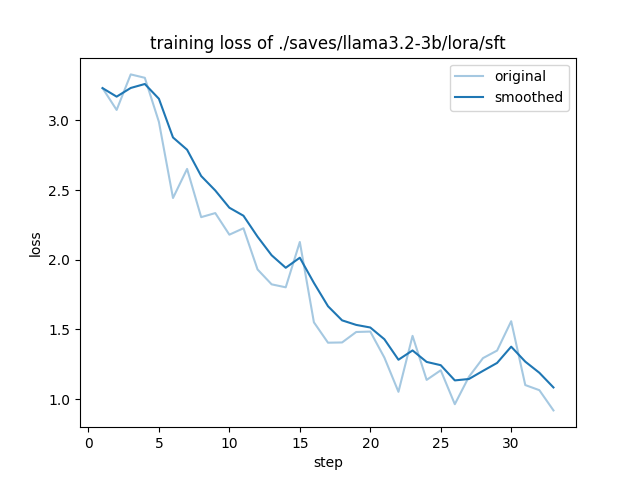
微调可视化
- 训练Loss可视化:
微调后推理
模型推理
修改examples/inference/llama3.2_3b_lora_sft.yaml推理配置文件,文件内容为:
使用以下命令进行推理:
推理结果:

结语
应用使能套件openMind在华为全联接大会2024的展示吸引了我们的注意。通过专家们的分享,得以了解魔乐社区,也了解到openMind在其中发挥的技术能力和未来发展。
通过本次微调的实践,更能体会到openMind套件的魅力。它让微调过程变得更加高效和直观,希望每一位开发者都来尝试它,一起交流经验,更好地提升它的能力。
相关链接:
[1] openMind Library介绍:< https://modelers.cn/docs/zh/openmind-library/overview.html>
[2] openMind Hub Client介绍:< https://modelers.cn/docs/zh/openmind-hub-client/overview.html>















 1308
1308

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









