






Trae+doubao-1.5-pro:只能算初级程序员水平
Trae目前支持三个大模型,默认豆包,以及DeepSeek R1和V3。
昨天的《Trae试用报告,能否真的0手写代码编写软件?》是基于Trae+默认的豆包-1.5-pro所形成的报告。其中吐槽点不少,最核心的问题是四个:
- 所生成的代码与每次对话之间的上下文联系缺失,豆包不记得曾经的修复或优化,错误代码会反复复新生成;
- 无法精确定位bug和优化所对应的代码行,很多时候都是全部代码重新生成。这也是修复的bug反复出现的原因之一;
- 代码编写水平不高,选择的解决方案、实现方式不合理。对代码结构设计不合理,比如对function的规划、变更作用域的设计等。
- 健壮性考虑不周,缺乏对空值、变量类型等校验,程序小bug很多。
Trae+DeepSeek:一步上升至中高级程序员水平
将大模型换成DeepSeek后,Trae的编程水平大幅上升,我感觉已经达到了中高级程序员水平。
一、代码完整度从70%上升到90%
用豆包花了16个小时,推翻重来一次,而用DS只花了1个小时,而且有一半的时间花在让它调整布局上。整体的流程和功能逻辑只有两个bug,其余一次成功。
软件完成后,我让DS总结了本次编写中的bug和优化项,它归纳如下。可见,绝大部分时间都花在了布局调整上。
根据我们的对话,以下是到目前为止发现的所有bug和优化项:
**Bug修复:**
1. `NameError: name 'question_text' is not defined`
- 原因:`question_text`变量在使用前未定义
- 修复:在使用`ttk.Label`之前确保定义`question_text`
2. `_tkinter.TclError: cannot use geometry manager pack inside ... which already has slaves managed by grid`
- 原因:混合使用了`pack`和`grid`布局管理器
- 修复:统一使用`grid`布局
**优化项:**
1. 布局优化:
- 将默写面板分为两列,每列一个题目
- 每个题目包含4个控件:核对结果、题目、输入框和答案
- 确保每列中每行的相应控件严格对齐
2. 控件宽度优化:
- 核对结果:固定3字符宽度
- 题目:固定20字符宽度
- 输入框:固定20字符宽度
- 答案:自适应宽度,占满剩余空间
3. 单数题目处理:
- 当题目数量为单数时,最后一行居中显示
- 确保单数题目与上一行对齐
4. 布局管理器优化:
- 使用`grid`代替`pack`实现精确布局
- 使用`columnconfigure`设置列宽比例
- 使用`minsize`确保最小宽度
- 使用`sticky="ew"`使控件在水平方向拉伸
5. 代码结构优化:
- 移除不必要的Frame嵌套
- 简化布局代码
- 提高代码可读性和可维护性
这些修复和优化已经解决了主要的布局问题,使界面更加整齐美观,同时提高了代码的健壮性。二、程序健壮性大幅提升
对空值、变量类型、传参等的校验基本上一次性自动编写完成。相较豆包大模型,程序bug数量大幅减少,可用性大幅提升。
- 代码示例-DS保存考试结果方法:可以看到DS生成的代码中,变量校验和操作结果验证都一次性生成了。并且代码结构和逻辑清晰简洁,封装性好,可读性强。
def save_results(self):
if not self.current_file:
messagebox.showwarning("警告", "请先选择生词本文件")
return
success = record_results(self.current_file, self.quiz_list, self.error_records)
if success:
messagebox.showinfo("提示", "默写结果已保存")
else:
messagebox.showerror("错误", "保存默写结果失败")- 代码示例-豆包保存考试结果方法
豆包生成的代码中,第一个校验是我通过bug修正让它加的;
第二个校验是我的优化要求,让它显示保存考试结果是否成功,结果它就那么水灵灵地写了一句毫无意义的提示,根本没做校验,无语。
最后,代码结构和逻辑混乱,在保存考试结果函数中才来获取和拆分需要保存的数据。这也就是为为什么豆包每次修改bug都要全部代码重新生成的原因:它根本没做逻辑分割和封装,各种逻辑交叉着散布天地。妥妥的初级程序员,甚至是新手小白的水平。
def record_results(self):
if not self.file_path:
messagebox.showerror("错误", "请先选择生词本")
return
error_list = []
for i, (entry, answer, mode) in enumerate(zip(self.quiz_entries, self.quiz_list, self.quiz_modes)):
user_input = entry.get()
id, eng, chi, cat = answer
if mode == "看中文写英文":
if user_input != eng:
error_list.append((id, eng, chi, cat))
else:
if user_input not in chi:
error_list.append((id, eng, chi, cat))
file_operator.record_exam(self.file_path, self.quiz_list, error_list)
messagebox.showinfo("提示", "记录默写结果成功")三、代码与交互上下文关联大幅提升
绝大部分情况下,DeepSeek都能记得曾经修复过的bug和优化,不再犯曾经犯过的错。DS良好的程序结构设计和逻辑封装功莫大焉。
四、编程模式更符合程序员思维习惯
相比于之前豆包一次性把代码全部生成,导致程序员不知道它干了啥,DeepSeek会首先中生成程序主体框架,例如总共三个.py文件,它只会先生成一个,同时,它先生成主函数,其它function会空置不生成。
尽管看起来没有豆包“自动化”,但这更符合程序员的思维习惯:先搭整体框架、再设计函数或接口、最后再来挨个function实现。虽然需要的步骤更多,但每次交互程序员都知道DS干了啥。看示例:
- 第一步:DS生成主函数
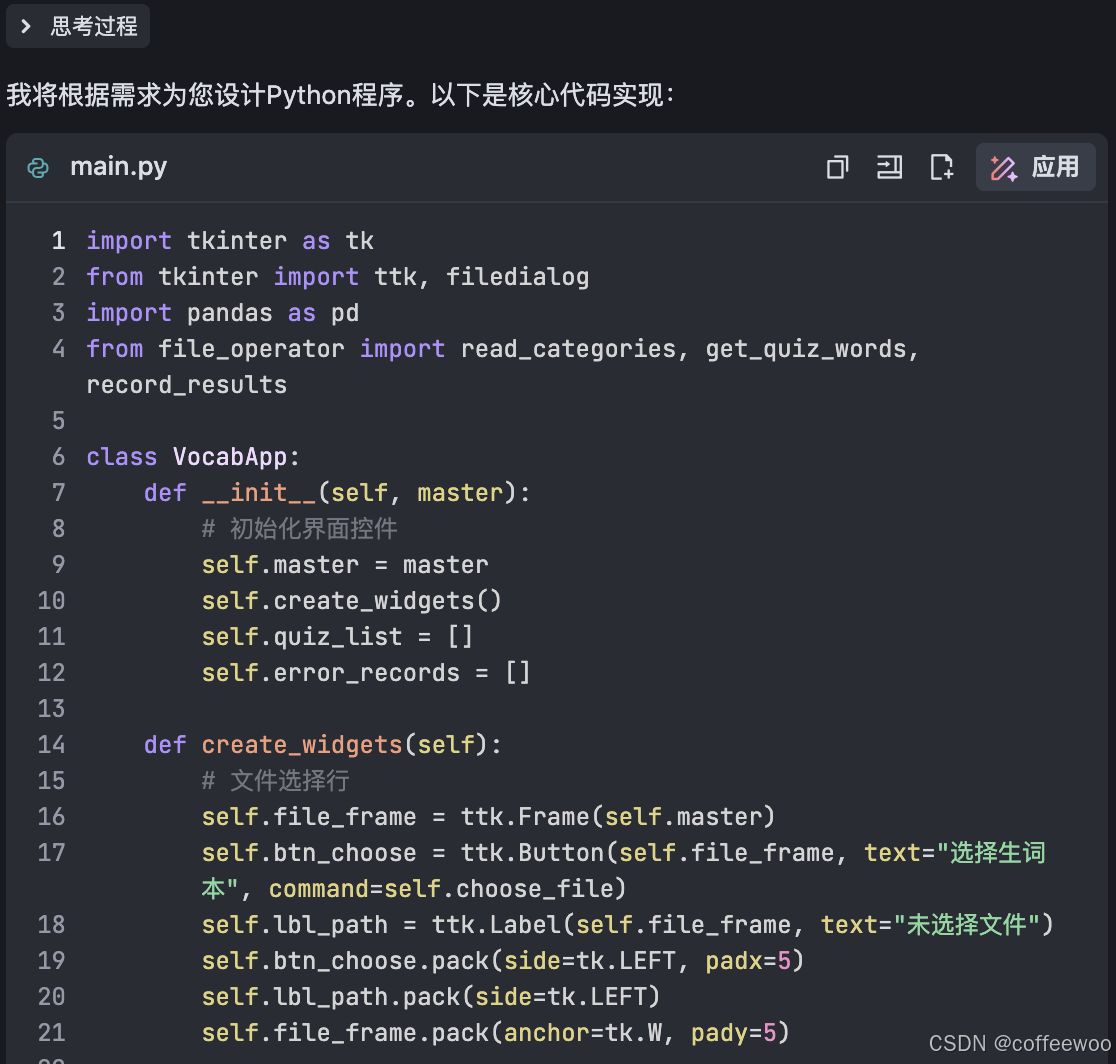
图一:先生成主函数
- 第二步:DS添加了main文件中的其它方法
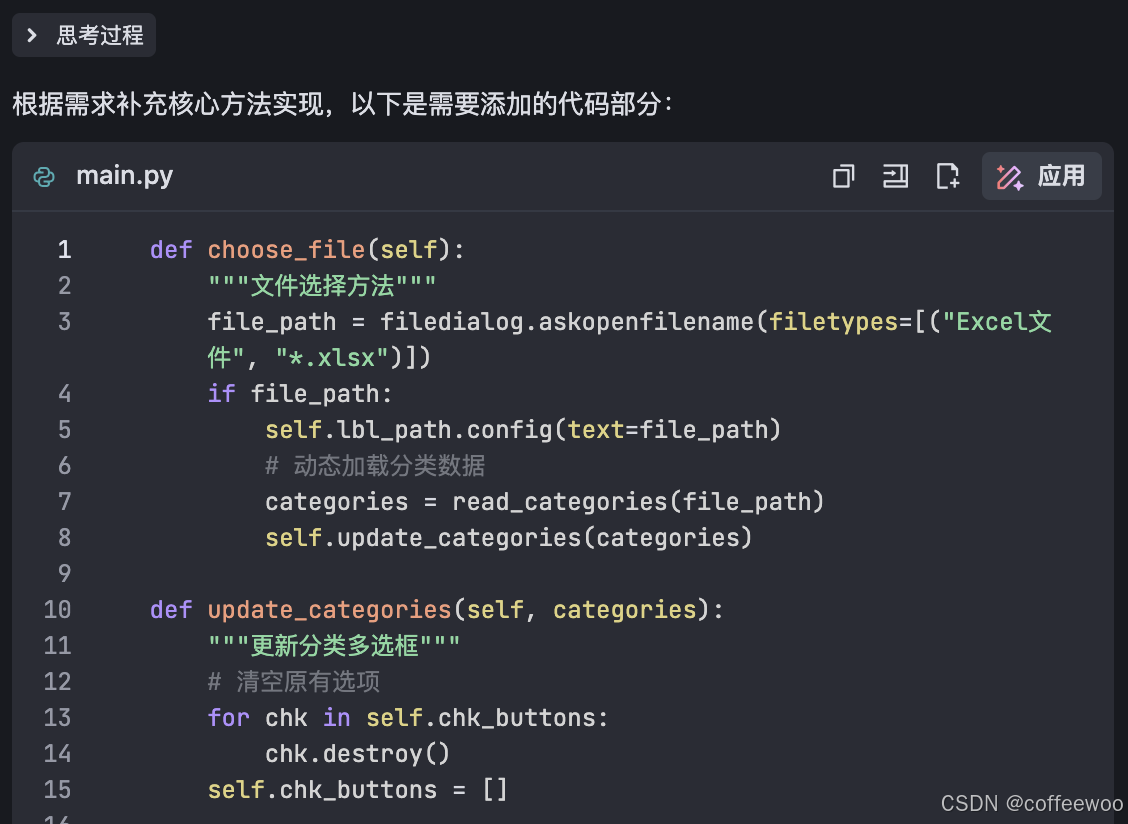
图二:补充其它方法
- 第三步:DS生成文件操作文件和相关方法
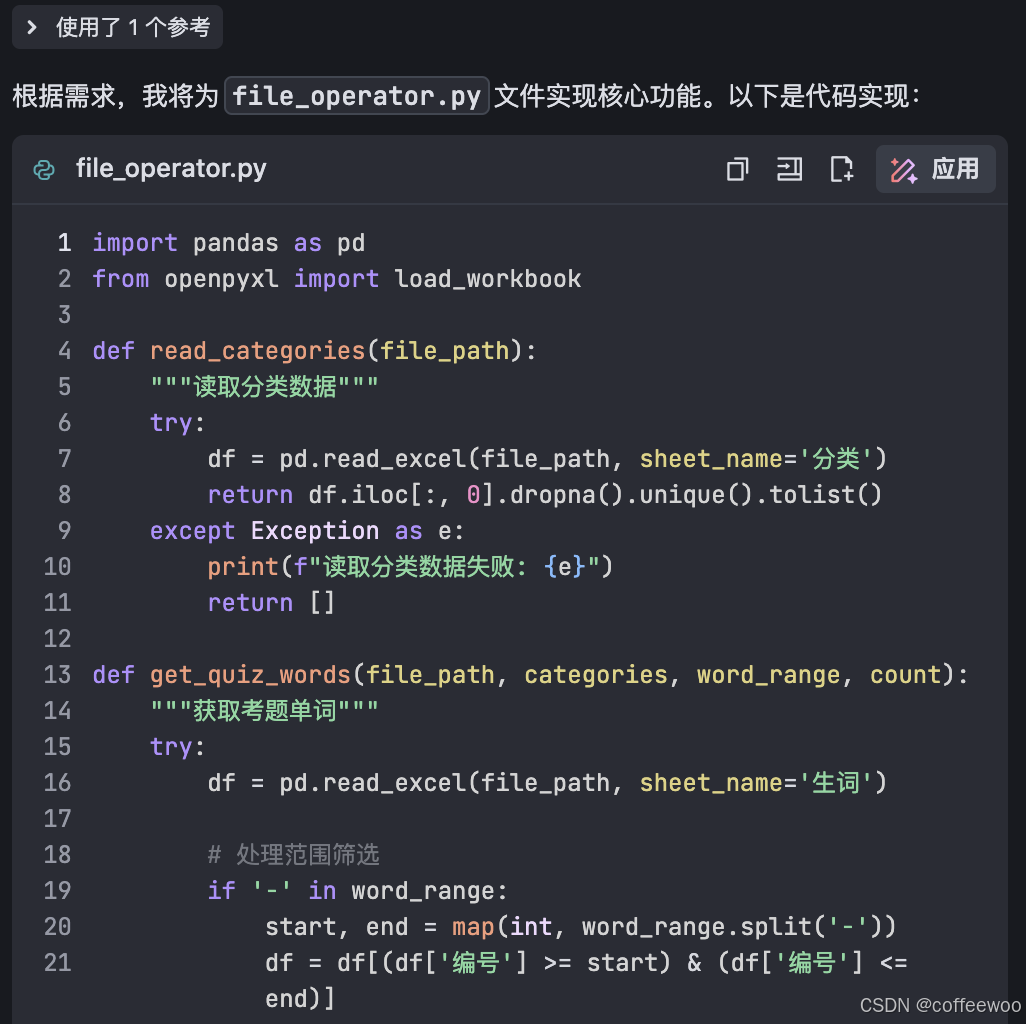
图三:补充文件操作部分
可见,尽管交互步骤更多,但程序员很清楚在干嘛。豆包的“自动化”却让人一头雾水,只见代码哗哗哗产生,却不知道它干了些啥,结果生成的代码还bug一堆。
如果想偷懒,甚至可以不读代码,直接试运行,然后把bug丢到对话框,DS即会自动补充还没实现的方法。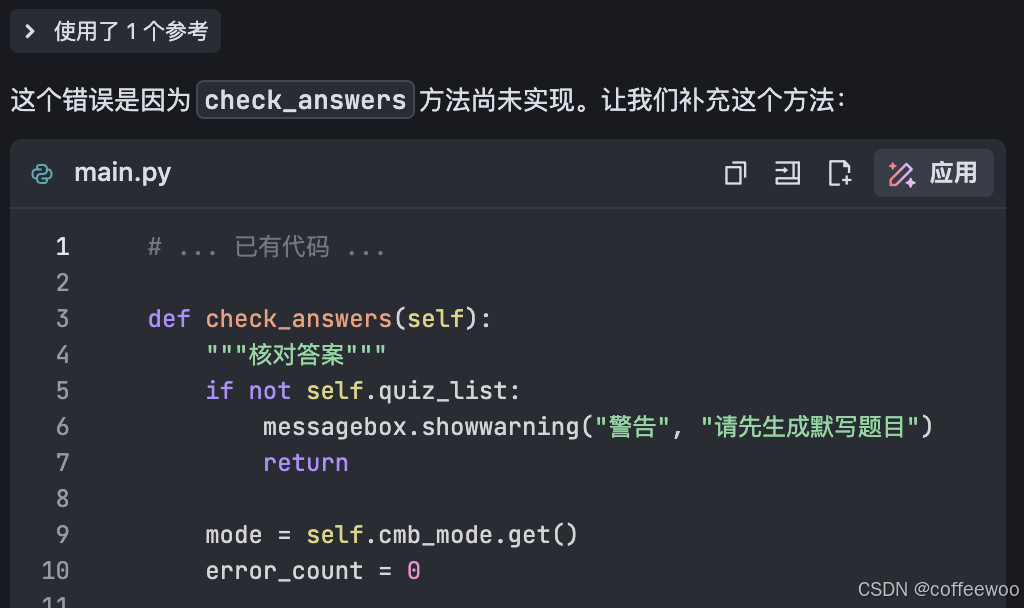
图四:在交互过程中逐步补充方法
这个感觉甚至有点像测试驱动开发了,有种向着目标步步前进的踏实感。
五、交互式编程焦点性很强
豆包在修复bug或优化交互时总是全部重新生成代码,导致交互失焦,程序员不知道哪次交互改了哪些代码。
而DS将最大修改范围定位于一个function内,若bug或优化清晰,还能够精准定位到特定的哪几行代码。所以在修复bug或优化交互时,DS只生成需要修改的代码行,最大输出单位是function,而不会生成全部代码。
若一次性丢给DS若干bug和优化,它会分类处理,再分成几个部分输出,最大输出单元是function。因此,程序员明确知道这次交互改动了哪些代码。举两个例子说明。
示例一:针对优化要求,DS精确定位到代码行,只输出受影响的代码,交互焦点非常清晰。
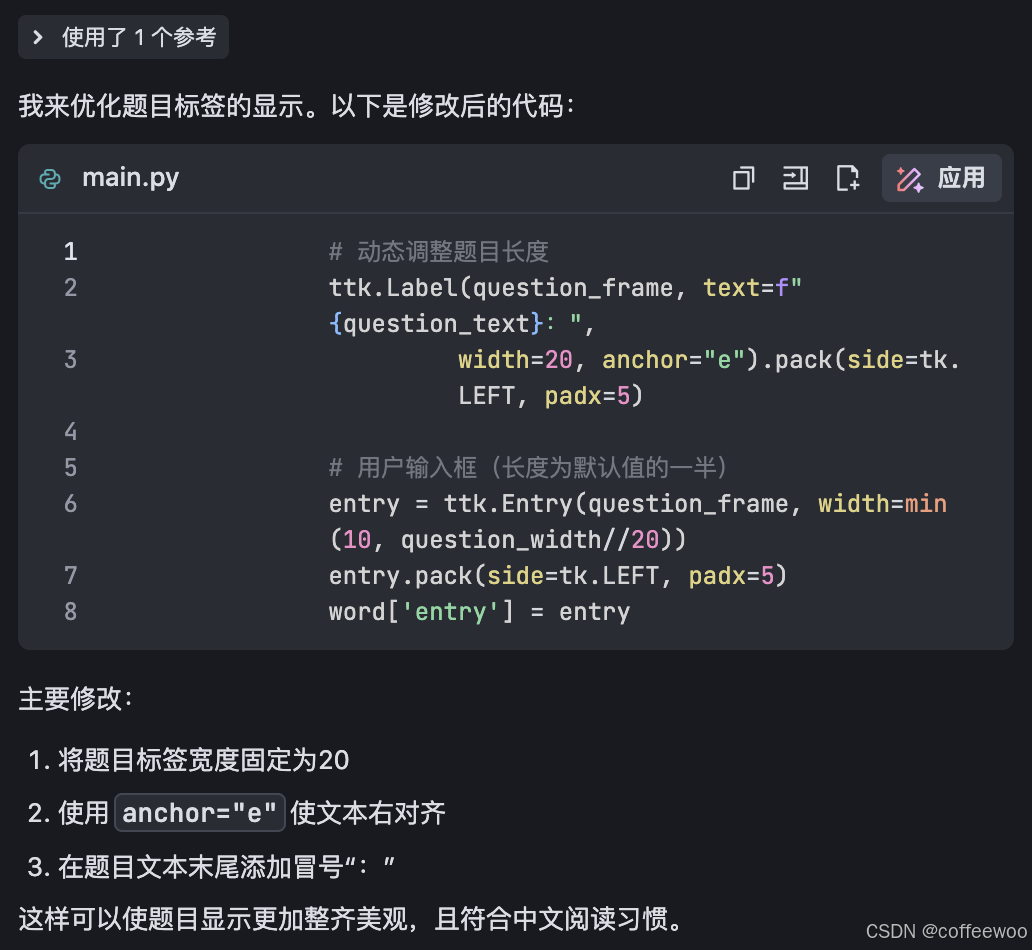
精确对应代码行
示例二:一次性丢多个问题给DS,它会分类处理,并最大以方法为单元返回修改的代码。
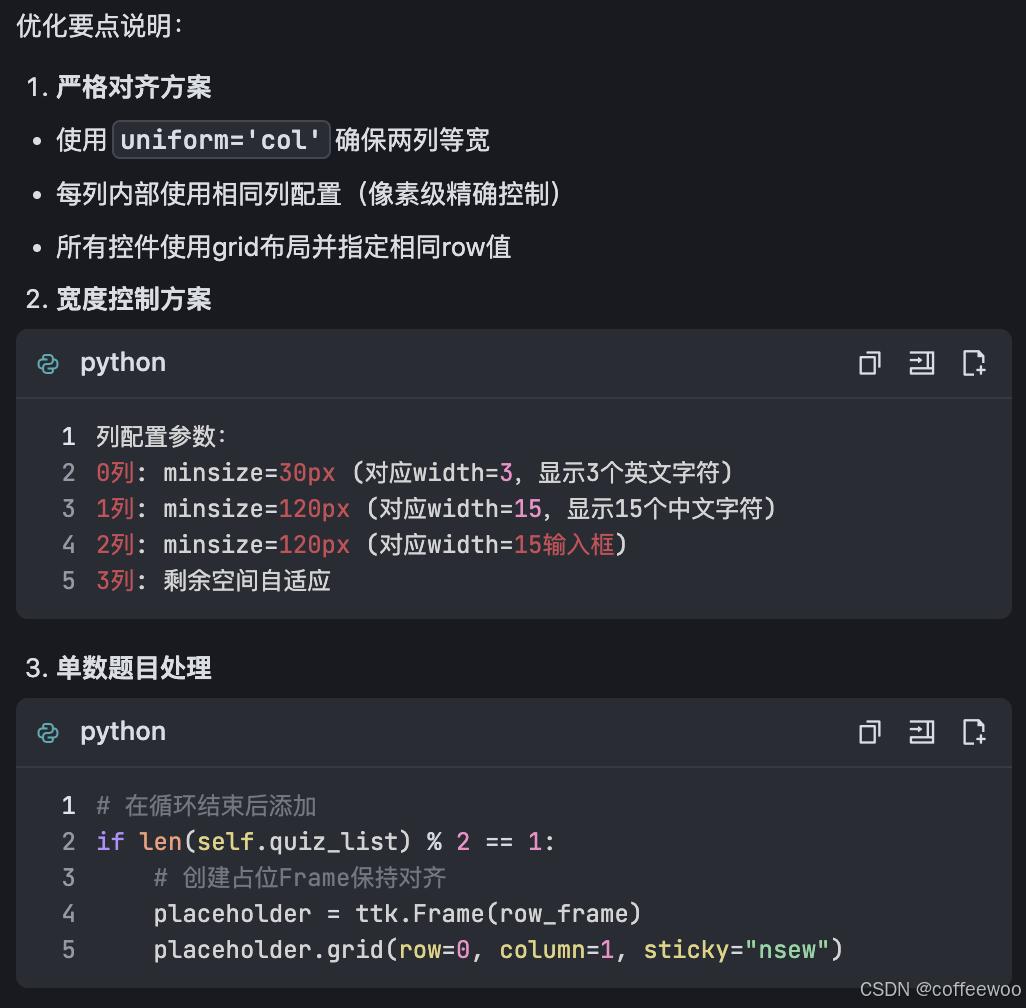
多问题分类处理
六、程序优化设计能力明显上升
最显著的提升就是程序整体结构的优化。DS对function的设计符合单一职责,逻辑拆分和实例变量定义合理,封装性和可读性都很好。请看下面的代码示例:
- DS代码片段:DeepSeek生成的实例变量很清晰,这使得它在后续以function为单位的代码生成、bug修复和优化极少引入新的bug。
import tkinter as tk
from tkinter import ttk, filedialog, messagebox
from file_operator import read_categories, get_quiz_words, record_results
class VocabApp:
def __init__(self, master):
self.master = master
self.master.title("智能背单词")
self.master.geometry("800x600")
self.create_widgets()
self.quiz_list = []
self.error_records = []
self.current_file = None
……- 豆包代码片段:豆包生成的实例变量很混乱,几乎没有封装概念。文件操作参数、单词列表、控件定义混杂在一起。这使得它在后续无法只针对某个函数进行代码生成、bug修复和优化,只能整体重新生成,而这一过程几乎总会带来新的bug,程序可读性和可维护性也很糟糕。
class VocabularyApp:
def __init__(self, root):
self.root = root
self.root.title("智能背单词")
# 控件初始化
self.file_path = None
self.categories = []
self.quiz_list = []
self.quiz_modes = []
self.quiz_answer_labels = [] # 初始化 quiz_answer_labels
# 选择生词本
self.select_file_frame = tk.Frame(root)
self.select_file_frame.pack(anchor=tk.W)
self.select_file_button = tk.Button(self.select_file_frame, text="选择生词本", command=self.select_file)
self.select_file_button.pack(side=tk.LEFT)
self.file_path_label = tk.Label(self.select_file_frame, text="未选择文件")
self.file_path_label.pack(side=tk.LEFT)
# 生词范围、默写词数、默写方式
self.input_frame = tk.Frame(root)
self.input_frame.pack(anchor=tk.W)
self.range_label = tk.Label(self.input_frame, text="生词范围 (起始-结束):")
self.range_label.pack(side=tk.LEFT)
self.range_entry = tk.Entry(self.input_frame)
self.range_entry.pack(side=tk.LEFT)
self.count_label = tk.Label(self.input_frame, text="默写词数:")
self.count_label.pack(side=tk.LEFT)
self.count_entry = tk.Entry(self.input_frame)
self.count_entry.pack(side=tk.LEFT)
self.mode_var = tk.StringVar()
self.mode_var.set("看中文写英文")
self.mode_options = ["看中文写英文", "看英文写中文", "随机"]
self.mode_menu = tk.OptionMenu(self.input_frame, self.mode_var, *self.mode_options)
self.mode_menu.pack(side=tk.LEFT)
# 生词分类
self.category_frame = tk.Frame(root)
self.category_frame.pack(anchor=tk.W)
self.category_label = tk.Label(self.category_frame, text="生词分类:")
self.category_label.pack(side=tk.LEFT)
self.category_vars = []
self.category_checkbuttons = []
# 操作按钮
self.button_frame = tk.Frame(root)
self.button_frame.pack(anchor=tk.W)
self.generate_button = tk.Button(self.button_frame, text="生成默写", command=self.generate_quiz)
self.generate_button.pack(side=tk.LEFT)
self.check_button = tk.Button(self.button_frame, text="核对答案", command=self.check_answers)
self.check_button.pack(side=tk.LEFT)
self.error_button = tk.Button(self.button_frame, text="生成错题记录", command=self.generate_error_records)
self.error_button.pack(side=tk.LEFT)
self.record_button = tk.Button(self.button_frame, text="记录默写结果", command=self.record_results)
self.record_button.pack(side=tk.LEFT)
# 默写面板
self.quiz_frame = tk.Frame(root)
self.quiz_frame.pack(anchor=tk.W)
self.quiz_labels = []
self.quiz_entries = []
# 错题记录
self.error_frame = tk.Frame(root)
self.error_frame.pack(anchor=tk.W)
self.error_tree = ttk.Treeview(self.error_frame, columns=("编号", "英文", "中文", "分类"), show="headings")
self.error_tree.heading("编号", text="编号")
self.error_tree.heading("英文", text="英文")
self.error_tree.heading("中文", text="中文")
self.error_tree.heading("分类", text="分类")
self.error_tree.column("编号", width=150, anchor=tk.CENTER)
self.error_tree.column("英文", width=150, anchor=tk.CENTER)
self.error_tree.column("中文", width=150, anchor=tk.CENTER)
self.error_tree.column("分类", width=150, anchor=tk.CENTER)
self.error_tree.pack(side=tk.LEFT, fill=tk.Y)
# 删除记录
self.delete_button = tk.Button(root, text="删除记录", command=self.delete_record)
self.delete_button.pack(anchor=tk.W)
……七、实现方案选择的合理性明显增强
在这次测试中,DS根据需求理解选择实现方案非常合理。没有出现上一篇文章中豆包选择了不合理的展示控件和文件操作方法,而DS通通一次性选择正确。同时,生成的界面美观度DS也更胜一筹。
- DS生成的界面
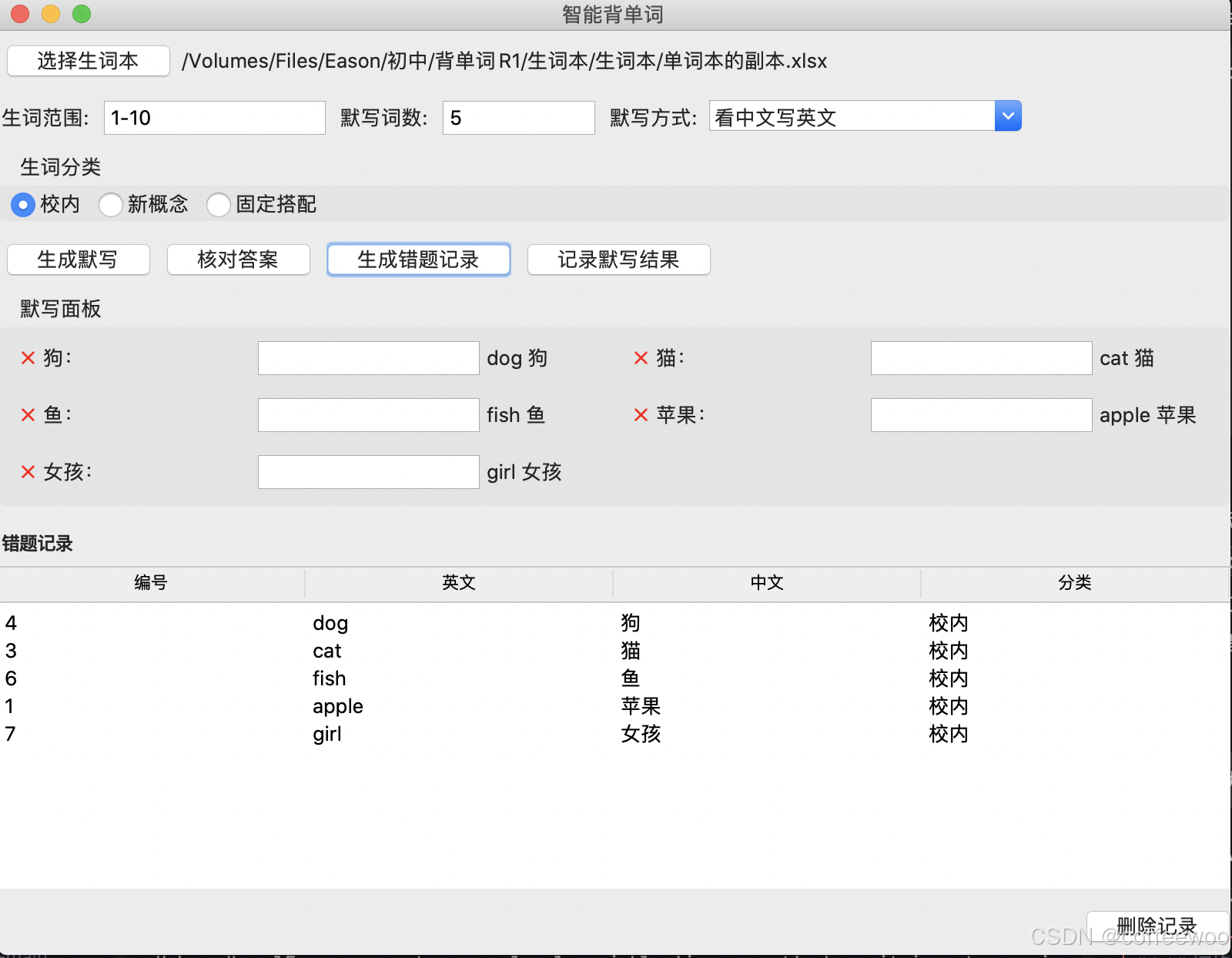
DS生成的界面
- 豆包生成的界面
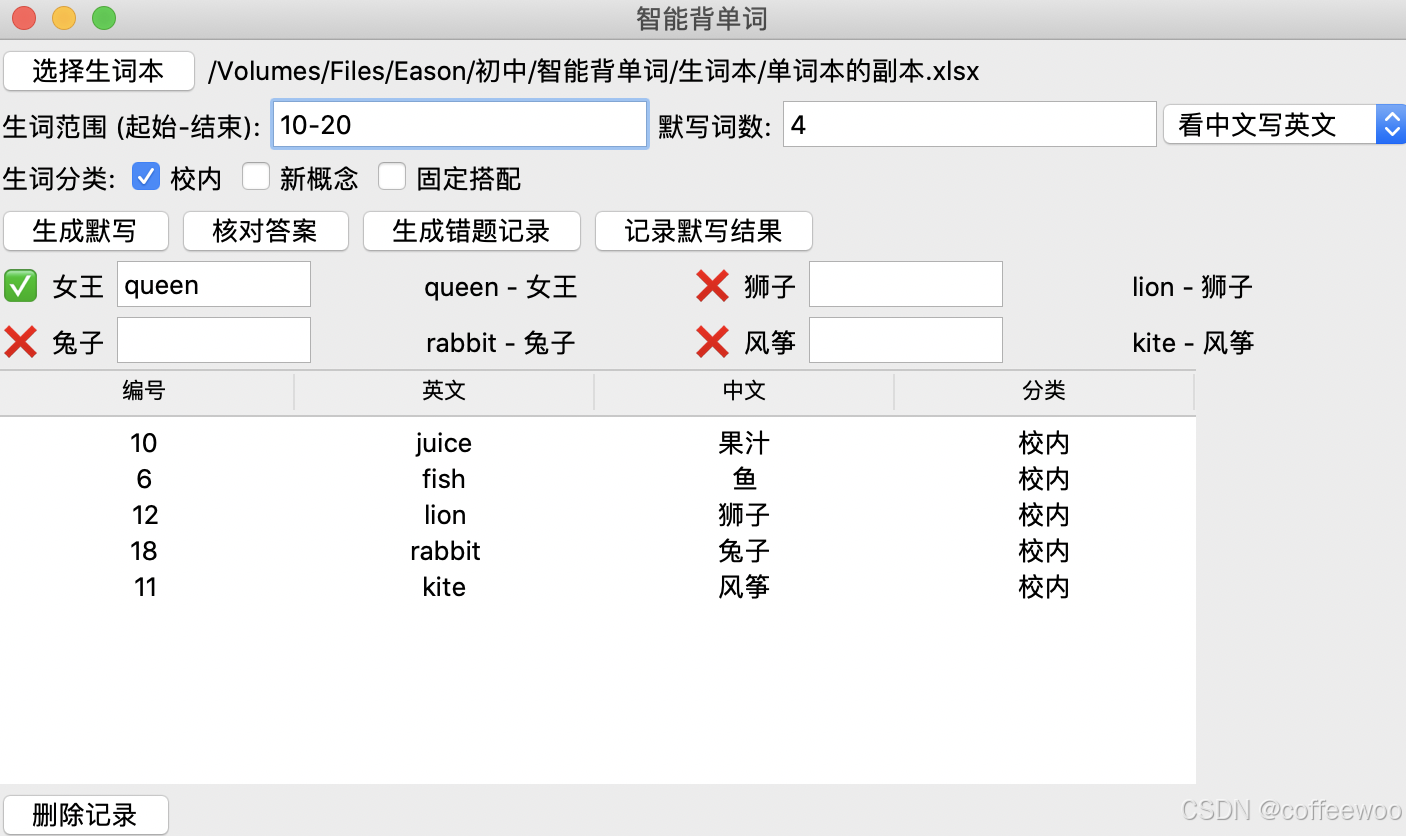
豆包生成的界面
八、唯一不好使的是布局处理
尽管DS布局处理较豆包更胜一筹,但AI无审美,处理布局还是不够理想。做了很多次交互,仍然没有达到理解的结果。这是目前我使用Trae+DeepSeek唯一可吐槽的地方。
总结
如果说Trae+豆包0代码编程过程很折腾的话,Trae+DeepSeek则很享受。DS生成的代码完整度高、健壮性强、封装度好、可阅读性好,关键是交互焦点很清晰、不会反复犯错。可以说,Trae+DeepSeek已经具备了至少中级,甚至更高的编程水平,完全可以成为程序员的强力助手了。
我的探索仍将继续,欢迎转发、关注和收藏,与我一起拥抱AI。

















 2298
2298

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









