







目录
前言
继续记录网络结构论文的笔记。这篇AlexNet论文展示了卷积神经网络的优秀性能和无限潜力,引发了深度学习热潮,自然是必读的。首先对论文的全文做一个简要的总览(顺带加入一些自己的理解),然后再记录一些疑问和思考。下面的这些资料给了我很大启发,在此表示感谢,同时附上原文链接:
AlexNet网络详解及各层作用
AlexNet网络结构分析及pytorch代码
AlexNet详解3
AlexNet 讲解及pytorch实现 ----1 AlexNet主要技术突破点
【深度学习】AlexNet原理解析及实现
从AlexNet理解卷积神经网络的一般结构
AlexNet论文详解
为什么现在的CNN模型都是在GoogleNet、VGGNet或者AlexNet上调整的?
深度学习中关于平均池化和最大池化的理解
AlexNet的基本结构
AlexNet论文下载传送门
AlexNet论文阅读笔记
1 Introduction
提到了研究背景:对于简单的物体识别的任务,小的数据集已经可以胜任这项工作了(例如mnist,性能已经接近人类的分辨能力了)。但是真实世界的物体千奇百怪各有不同,要完成分类任务需要很大的数据集。此时人们也已经认识到了小数据集的缺陷,但是仅仅是在最近人们才有能力获得百万量级图像的数据集。
尽管ImageNet的数据集已经很大了,但是对于物体识别的问题来说还是不够大,需要一些先验知识来补偿我们没有的数据(这个应该是为后面的数据增强做铺垫)。之后文章列举了一些CNN的参考文献,来说明CNN的优势(模型的容量可以通过网络的深度和宽度来控制,具有统计的稳定性和像素依赖的局部性,参数更少更易训练)。
提到了三点CNN发展的有利因素:GPU的进步、对于二位卷积的高度优化、以及诸如ImageNet这样大规模的数据集防止过拟合。
提到了本文模型的优势和技术特点:在ILSVRC-2010和ILSVRC-2012数据集上都取得了最好的效果、模型使用高度优化的GPU实现、一系列新的且不寻常的手段来提高性能并减少训练时间、一些防止过拟合的策略。最后,论文提到模型的深度很重要,本文的模型移除任何一个卷积层(该层包含的参数不超过模型总参数的1%)都会导致性能的下降。
2 The Dataset
提到了ILSVRC (ImageNet Large-Scale Visual Recognition Challenge) 使用了ImageNet的一个子数据集,数据集共有1000类,每类约1000张图像。训练集包含120万张图像,验证集5万,测试集15万。
数据集的图像大小各有不同,但是模型的输入图像是固定大小,需要将原图下采样到一个固定的分辨率256*256。本文的做法是先将原图的短边(高度)缩放到256个像素,然后在图像的中心区域裁剪出256*256的区域。此外,输入图像还需要归一化(减去均值,即在整个数据集中,求每个位置像素的均值,并在该位置减掉均值)。
3 The Architecture
网络包含5个卷积层和3个全连接。创新性的贡献包括:
1、使用了relu激活:relu激活比其他激活函数训练要快得多。相同的网络结构(4层卷积,作者应该是另外训练了一个网络),分别调整两个模型的学习率使得训练最快,可以看到relu(实线)比tanh(虚线)下降快很多。

激活函数的作用除了学到非线性特征(吴恩达深度学习的视频有提到,如果不用激活函数,多层网络实际上就是多个线性网络的级联,和单层的效果是一样的)也有压缩数据范围的作用,如sigmoid是0到1,tanh是-1到1, relu是0到无穷。
2、使用多个GPU训练:网络的训练在两张卡上进行(一张卡放不下),每张卡上仅仅有一半的神经元。此外,由于网络结构的设计问题,需要在计算第三层时需要进行两张卡的通信交互(应该在全连接那里也需要进行两张卡的交互,但是文章在这部分没有提到)。
3、局部响应归一化 (Local Response Normalization):受到真实神经元“侧抑制”效应的启发,作者提出了LRN,该策略有助于提高模型的泛化能力。
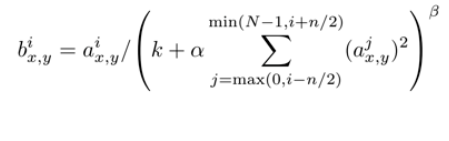

但是对于这种方法对于算法的优化程度存在争议,后期的网络结构基本不再采用这种方法,这一点在吴恩达的深度学习视频中也有提到。
4、重叠的最大池化层:本文使用3*3的核,步长设置为2,对feature map进行最大池化操作。采用重叠的最大池化可以将top-1和top-5的错误率分别降低0.4%和0.3%。本文通过观察发现训练模型时使用重叠池化比非重叠池化更不容易过拟合(仅仅是通过实验发现的,其实没有理论依据)。
5、网络结构:下面就是网络的总体结构了。网络由5个卷积层和3个全连接层组成,最后一层全连接输入一个1000层的输出层并计算softmax。网络的loss是最大化所有样本的平均logistic概率(应该就是交叉熵)。第2、4、5卷积层只与同一GPU的前一层相连,第3层与前一层的两个GPU里面的所有神经元相连,所有全连接都是与两个GPU里面的所有层相连。LRN只在第一层卷积层和第二个卷积层后面出现。Max-pooling在两个LRN层后,还有第五个卷积层后出现。所有卷积层和全连接都用relu激活。卷积核的大小和数量在网络结构图中可以看到。值得注意的是,输入图像是224*224时,需要填0(填0方式也很奇怪,应该是需要在最后填三个0),因此输入采用227*227大小的图像更合适。

由于GPU的发展,目前的硬件条件已经能完全支持大型的网络(文中用到的GPU还是GTX 580),因此网络结构上也不需要将网络切成两半,可以直接让网络的所有层都与前一层的所有feature map相连。在吴恩达的深度学习视频课中提到了现代的AlexNet:

这里另外说一下关于卷积层尺寸的计算:

AlexNet详解3中提到了将网络模块化,图片中对应的序号也就是AlexNet中对应的层的编号:






CNN的前面部分,卷积-激活函数-降采样-标准化。这个可以说是一个卷积过程的标配,CNN的结构就是这样,从宏观的角度来看,就是一层卷积,一层降采样这样循环的,中间适当地插入一些函数来控制数值的范围,以便后续的循环计算。模块后面部分是全连接层,全连接层就和人工神经网络的结构一样的,结点数多,连接线也多,所以这儿引出了一个dropout层。之后就是一个输出的结果,结合上softmax做出分类。有几类,输出几个结点,每个结点保存的是属于该类别的概率值。
4 Reducing Overfitting
本文模型的主要问题是过拟合,因此文中提到了很多避免过拟合的方案,包括:
1、数据增强(数据增广):
上面已经将图像rescale成256*256,而输入图像是224*224(227*227),因此需要再从256*256的图像中框出224*224的区域。本文采取的数据增强的方法是将224*224的框进行一定的水平垂直的平移,这样框出的输入图像就有一定的不同。此外,再将输出图像进行水平翻转。这样将原始训练集扩充了 (256-224) * (256-224) * 2 = 2048倍。在测试时,在256*256的图像中框出左上、右上、左下、右下和中间5个位置,再把它们的水平翻转样本也拿过来,这样一共10个图像单独进行预测,并将softmax结果求平均,作为最终的预测结果。
第二个数据增强的方式是改变图像RGB通道的亮度值(依据的原理是改变光照的颜色和强度,目标的特性是不变的)。方法是采用PCA算法,对RGB像素的3*3协方差矩阵求特征值和特征向量,对每一个像素值:
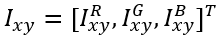
加上如下的值:
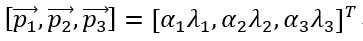

word中的公式不能直接复制过来真是僵,只能截图了。
2、Dropout:
Dropout减小了神经元对于前一层单一神经元的依赖性,迫使网络在前一层不同神经元的组合中学习到更鲁棒的特征。另外一个对Dropout的理解在吴恩达深度学习中提到过,每次训练Dropout的神经元都不同,因此网络的结构都不同,那么可以认为输出是很多不同的网络结构求平均预测得到的。
在测试时,本文提到的做法是将Dropout层的所有神经元的输出乘以Dropout的概率(例如训练时神经元随机失活的概率是0.5,那么测试时该层所有神经元的输出要乘0.5),相当于对Dropout层求几何平均。在吴恩达深度学习视频中提到测试时不需要进行任何额外的操作,这两种做法应该对结果没影响。
Dropout被用到了网络的前两个全连接层中。
Dropout常常在全连接层中,因为全连接结点连接太多了,大大消耗了内存资源,且有些是没有必要的。

由此可见全连接参数量的巨大。
5 Details of learning
这部分提到了一个权重的缓慢衰减(衰减系数是0.0005),具有正则化作用同时也能减小训练误差。

后面就是一些论文的结果了,这里就不多说了。
疑问和思考
为什么用最大池化:
深度学习中关于平均池化和最大池化的理解提到,根据相关理论,特征提取的误差主要来自两个方面:
(1)邻域大小受限造成的估计值方差增大;
(2)卷积层参数误差造成估计均值的偏移。
一般来说,mean-pooling能减小第一种误差(邻域大小受限造成的估计值方差增大),更多的保留图像的背景信息,max-pooling能减小第二种误差(卷积层参数误差造成估计均值的偏移),更多的保留纹理信息。Stochastic-pooling则介于两者之间,通过对像素点按照数值大小赋予概率,再按照概率进行亚采样,在平均意义上,与mean-pooling近似,在局部意义上,则服从max-pooling的准则。
LeCun的“Learning Mid-Level Features For Recognition”对前两种pooling方法有比较详细的分析对比,如果有需要可以看下这篇论文。
为什么要用重叠的池化层:
提高精度, 不容易产生过拟合。在以前的CNN中普遍使用平均池化层,AlexNet全部使用最大池化层,避免了平均池化层的模糊化的效果,并且步长比池化的核的尺寸小,这样池化层的输出之间有重叠,提升了特征的丰富性。但也有最直接的缺点:
1.增加了计算量
2.丰富特征的同时无可避免也带来了部分特征信息的冗余(对max pooling而言,提取出来的结果可能是有重复的)
AlexNet的基本结构指出: 在其他数据集实验发现,重叠池化的效果不如非重叠池化,理由是当使用重叠池化时,下一个池化区域的最大值很可能就是上一个池化区域最大元素的副本,此时相当于造成了特征冗余。
为什么网络深度往往越深越好:
在AlexNet论文中没有提及网络加深对于性能的影响,但是VGG论文中描述得很详细(虽然也是实验得出的,没有太严谨的理论依据),详情可以看我的VGG阅读笔记。
下面谈一些阅读后的思考:
理解1:
卷积层是提炼特征,全连接层负责做分类,所以说卷积层后面应该是不一定要全连接收尾,卷积层后也可以连接其他的分类器(诸如一些传统的机器学习算法)。
理解2:
本来希望希望AlexNet论文讲解一些网络超参数的选择(卷积核大小,步长,个数,网络深度什么的怎么选,为什么这么选),但是论文中没有提到这些参数的选择问题,只是单纯地介绍网络结构,整篇论文看完还是不知道怎么设计网络。下面这篇博客中提到了超参数的选择(感觉还是玄学啊):
AlexNet详解3指出:AlexNet和LeNet的区别,AlexNet用了两个全连接层,更加强调了全连接的作用,LeNet只用了一个。为了减少权重的数目才提出了dropout,其他的区别其实不能叫做区别
下面可以看到AlexNet网络细节参数设计的需求其实大部分都是因为竞赛的需要,并没有什么特别的设计
• 输入尺寸:227*227像素(因为竞赛的需要)
• 卷积层:好多(因为输入尺寸的需要)
• 降采样层:好多(因为输入尺寸的需要)
• 标准化层:这个反正就是一个公式
• 输出:1000个类别(因为竞赛的需要)
这儿要说明一下:不要以为卷积层的个数、降采样层的个数、卷积核的尺寸、卷积核的个数这些网络细节会对最后的训练结果产生什么了不得的影响,这些就按照你的输入图像的尺寸来就行了。没有什么说头,你也可以去参考现在已经有的网络结构去设计,都可以的。这些参数大多都是手动调的,依据就是看看学习的结果如何。















 831
831











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









