






词嵌入(Word Embedding, WE),任务是把不可计算、非结构化的词转换为可以计算、结构化的向量,从而便于进行数学处理。
一个更官方一点的定义是:词嵌入是是指把一个维数为所有词的数量的高维空间(one-hot形式表示的词)【嵌入】到一个维数低得多的连续向量空间中,每个单词或词组被映射为实数域上的向量。
Word Embedding 解决了 One-Hot 独热编码的两个问题。参考:一、独热编码(One-Hot)
- Word Embedding 矩阵给每个单词分配一个固定长度的向量表示,这个长度可以自行设定,实际上会远远小于字典长度,将词向量映射到了一个更低维的空间。
- Word Embedding 矩阵使两个词向量之间的夹角值(最常用到的相似度计算函数是余弦相似度(cosine similarity))作为他们之间关系的一个衡量,保持词向量在该低维空间中具备语义相似性,越相关的词,它们的向量在这个低维空间里靠得越近。
Word Embedding 示例图:参考Word Embedding介绍
展示将 “way back into love” 翻译成中文的过程:

第一步:将 “way back into love” 四个词分别用四个不同的向量表示(图中采用 One-Hot 独热编码方式为例);
第二步:通过 Word2vec/GloVe 等词嵌入Word Embedding 方法提取文本特征,并将这四个高维向量进行降维,得到四个词各自对应的 embedding(图中以 2 维向量作为示例)。
第三步:需要再经过 Model 之后做进一步的提取文本特征,才能得到对 “way back into love” 的翻译结果。
1 Word2Vec
Word2Vec 中有两种基本的模型:CBOW 和 Skip-Gram。参考自然语言处理与词嵌入
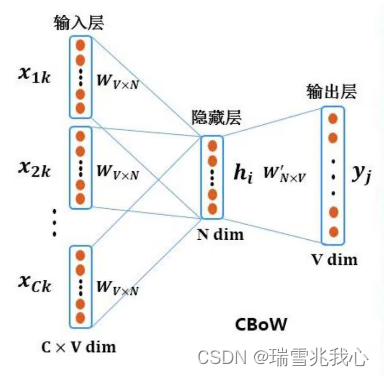
1.1 连续词袋模型(CBOW)
连续词袋模型(Continuous Bag-of-Words Model, CBOW)是通过用环境中的每一个词去预测中心词。相当于一句话中扣掉一个词,让你猜这个词是什么。其本质是通过背景词(context word)来预测一个单词是否是中心词(center word)。
CBOW 示例:参考更详细的示例解析
| 我 | XX | 你 | ... |
| 输入 | 输出 | 输入 | ... |
- 在 CBOW 中,会定义一个为 window_size 的参数,假如 window 的大小为 1,那么中心词的前 1 个词和后面 1 个词就被选入了我们的窗口里,以 XX 为例,上下文的词为 ['我', '你'] 。
- 然后模型先将每个字符处理为 One-Hot 形式,其中维度大小为词表的大小(不同词的个数)。例如,一篇文章由 1000 个不同的词构成,那么词表大小即为1000,每个词的 One-Hot 编码大小为 1*1000。
- 接着,将 One-Hot 向量进行相加。获得了一个输入向量以及目标向量后,将输入向量 X输入全连接层(设置好维度参数)中,进行参数的优化训练。(这里优化的目标是让模型能够学的词与词之间的上下文关系,我们的代价函数就是使得 sofamax 中预测的分布 y 与真实值 Y 这两个矩阵的交叉熵最小化,也可以最小化这两个矩阵的差平方,即损失值)
- 训练结束后,对我们真正有用的是隐藏层中的权重 W,这就是我们所需要的词向量。
CBOW 原理图:
1.2 Skip-Gram
Skip-Gram 是通过用中心词来预测上下文。其本质则是在给定中心词(center word)的情况下,预测一个词是否是它的上下文(context word)。
CBOW 示例:参考网络模型是如何计算的
| XX | 爱 | XX |
| 输出 | 输入 | 输出 |
Skip-Gram 原理图:
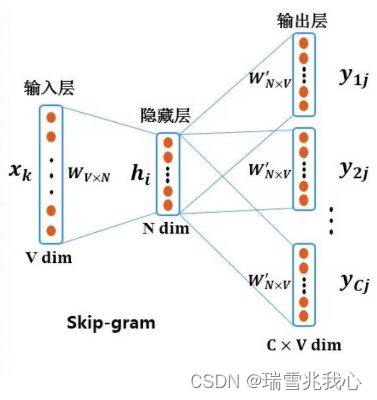
- 输入的中心词 One-Hot 独热编码向量
- 输入乘以 center word 的矩阵 W 得到词向量
- 词向量乘以另一个context word 的矩阵 W(t) 得到对每个词语的相似度
- 对相似度得分取 Softmax 得到概率,与答案对比计算损失。
我们提到预测中心词和上下文的最终目的还是通过中心词和上下文,去训练得到单词语义上的关系,同时还做了降维,最终得到想要的 embedding 了。
1.3 缺点
由于词和向量是一对一的关系,所以 Word2vec 无法解决多义词的问题。
2 GloVe
GloVe 的全称叫 Global Vectors for Word Representation,它是一个基于全局词频统计(count-based & overall statistics)的词表征(word representation)工具,它可以把一个单词表达成一个由实数组成的向量,这些向量捕捉到了单词之间一些语义特性,比如相似性(similarity)、类比性(analogy)等。参考GloVe
共现矩阵(Co-Occurrence Matrix)指的是矩阵中的每一个元素 Xij 代表单词 i 和上下文单词 j 在特定大小的上下文窗口(context window)内共同出现的次数。
例如,语料库(corpus)中有如下两句话:
- 句子1:小唐喜欢看电视剧,小王也喜欢看电视剧
- 句子2:小唐还喜欢看电影
有以上两句话,设置滑窗为2,可以得到一个词典为:{'小唐', '小王', '还', '也', '喜欢', '看', '电视剧', '电影'}。这样我们可以得到一个共现矩阵(对称矩阵):
| 小唐 | 小王 | 还 | 也 | 喜欢 | 看 | 电视剧 | 电影 | |
| 小唐 | 0 | 0 | 1 | 0 | 1 | 0 | 0 | 0 |
| 小王 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 0 |
| 还 | 1 | 0 | 0 | 0 | 1 | 0 | 0 | 0 |
| 也 | 0 | 1 | 0 | 0 | 1 | 0 | 0 | 0 |
| 喜欢 | 1 | 0 | 1 | 1 | 0 | 3 | 0 | 0 |
| 看 | 0 | 0 | 0 | 0 | 3 | 0 | 2 | 1 |
| 电视剧 | 0 | 0 | 0 | 0 | 0 | 2 | 0 | 0 |
| 电影 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 0 |
GloVe 模型仅对单词共现矩阵中的非零元素训练,从而有效地利用全局统计信息,并生成有意义的子结构向量空间。给出相同的语料库,词汇,窗口大小和训练时间,它的表现都优于 Word2Vec,它可以更快地实现更好的效果,并且无论速度如何,都能获得最佳效果。















 542
542











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











