






BERT(Bidirectional Encoder Representation from Transformers),基于 Transformer 的双向编码表示,模型训练时的两个任务是预测句子中被掩盖的词以及判断输入的两个句子是不是上下句。
论文中介绍了2种版本:BERT_BASE 和 BERT_LARGE。两个 BERT 的模型相比于 Transformer 有更多的编码器层数、前馈神经网络和多注意力头,如 BERT_BASE 有12层、768 个隐藏层神经元,12个多注意力头;BERT_LARGE 有24层,1024 个隐藏层神经元、16个多注意力头。
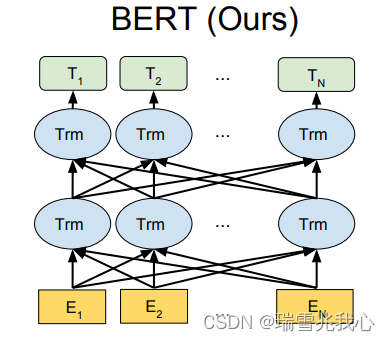
BERT 的基础集成单元是 Transformer 的 Encoder 编码层,整体框架是由多层 Transformer 的encoder 堆叠而成的,每一层的编码器 encoder 则是由一层 muti-head-attention 和一层 feed-forword 组成。
关于 Transformer 的编码器 Encoder 原理介绍请参考:Transformer
1 模型输入
我们知道文本预处理最重要的一步就是分词(Tokenize),执行分词的算法模型称为分词器(Tokenizer) ,划分好的一个个词称为 Token,这个过程称为 Tokenization 。
我们将一个个的 token(可以理解为小片段)表示成向量,我们分词的目的就是尽可能的让这些向量蕴含更多有用的信息,然后把这些向量输入到算法模型中。
在 BERT 中,输入的向量 X = (batch_size, max_len, embedding) 是由三种不同的 embedding 求和 WordPiece Token Embedding + Segment Embedding + Position Embedding 而成,使用字符 [CLS](分类标识 Classification Token) 对 Token 进行分类以及 [SEP](特殊标识 Special Token)对 Token 进行分隔。
 假设 batch_size = 1,输入的句子长度 = 512,每个词的向量表示的长度 = 768,那么整个模型的输入就是一个 512 * 768 维的 tensor。
假设 batch_size = 1,输入的句子长度 = 512,每个词的向量表示的长度 = 768,那么整个模型的输入就是一个 512 * 768 维的 tensor。
1.1 WordPiece Embedding
WordPiece Embedding 是指把 Word 拆成 Piece 一片一片的,使得我们的此表会变得精简,并且寓意更加清晰。
1.1.1 古典分词方法
古典分词方法是把一句话分成一个个词。比如按标点符号分词 、按语法规则分词和按照空格进行分词。
古典分词方法的缺点:参考Tokenizer-BPE算法原理
- 对于未在词表中出现的词(Out Of Vocabulary, OOV ),模型将无法处理(未知符号标记为 [UNK])
- 词表中的低频词或稀疏词在模型训无法得到训练(因为词表大小有限,太大会影响效率)
- 最困难的是很多语言难以用空格进行分词,例如 "loved", "loving", "loves" 这三个单词。其实本身的语义都是“爱”的意思,但是如果我们以单词为单位,那它们就算不一样的词,在英语中不同后缀的词非常的多,就会使得词表变的很大,训练速度变慢,训练的效果也不好;又比如模型也无法通过 "old", "older", "oldest" 之间的关系学到 "smart", "smarter", "smartest" 之间的关系,增加了训练冗余,另一方面也造成了大词汇量问题。
1.1.2 拆分为单个字符方法
拆分为单个字符方法直接把一个词分成一个一个的字母和特殊符号。虽然能解决 OOV 问题,也避免了大词汇量问题,但缺点也明显,粒度太细,训练花费的成本太高,增加了建模难度。
1.1.3 基于子词的分词方法(Subword Tokenization)
基于子词的分词方法(Subword Tokenization),简称为 Subword 算法,意思就是把一个词切成更小的一块一块的子词。通过一个有限的词表来解决所有单词的分词问题,同时尽可能将结果中 token 的数目降到最低。
BPE(Byte-Pair Encoding)双字节编码,又称 digram coding 双字母组合编码,是 Subword Tokenization 的一种主要的实现方式,通过将数据压缩,来在固定大小的词表中实现可变⻓度的子词。
BPE 的训练过程:参考BPE算法原理及案例
- 首先准备足够大的训练语料库;确定期望的 subword 词表大小;
- 将语料库中所有词分成一个一个的单个字符,然后在末尾添加停止符后缀 "</ w>"(不加 "</ w>" 该子词可以出现在词首;加了 "</ w>" 表明该子词位于词尾,并统计每个字符出现的频率;
- 挑出频次最高的字符组成字符对合并成新的 subword,将新组成的 subword 加入词表,然后将语料中所有该字符对融合(merge)成 subword(新字符依然可以参与后续的 merge);
- 重复第 4 步直到达到第 2 步设定的 subword 词表大小或下一个最高频的字节对出现频率为 1 才结束。
BPE 算法通过训练,能够把上面的 3 个单词 "loved", "loving", "loves" 拆分成 "lov", "ed", "ing", "es" 四部分,这样可以把词的本身的意思和时态分开,有效的减少了词表的数量。
1.2 Position Embedding
Position Embedding 是将单词的位置信息编码成特征向量(因为我们的网络结构没有 RNN 或者 LSTM,因此我们无法得到序列的位置信息,所以需要构建一个 Position Embedding)
BERT 和 Transformer 中 Position Embedding 的区别:
BERT 是初始化一个 Position Embedding,然后通过训练将其学出来;而 Transformer 则是通过制定规则来构建一个 Position Embedding。
1.3 Segment Embedding
Segment Embedding 是用于区分两个句子的向量表示。这个在问答等非对称句子中是用区别的。
2 网络结构
BERT 的每一层由一个 Transformer 的 编码层 encoder(一个 Multi-Head-Attention + Residual Connection + Layer Normalization + Feed-Forword + Residual Connection + Layer Normalization)叠加产生。
3 预训练
3.1 训练方法
BERT 的训练方法分为预训练(Pre-Training)和微调(Fine-Turning)两个阶段。参考深入理解预训练(pre-learning)和微调(fine-tuning)
3.1.1 预训练
预训练就是指预先训练的一个模型或者指预先训练模型的过程(现在我们常用的预训练模型都是网上他人调试好的优秀网络模型)
3.1.2 微调
微调就是指将预训练过的模型作用于自己的数据集,并使参数适应自己数据集的过程。
如果不做微调的话:
- 从头开始训练,需要大量的数据,计算时间和计算资源;
- 存在模型不收敛,参数不够优化,准确率低,模型泛化能力低,容易过拟合等风险。
3.2 训练任务
3.2.1 掩码语言模型(Masked Language Model, MLM)
BERT 采取了一种随机屏蔽的方法实现双向编码表示,在输入数据中随机将部分字符利用特殊标志 [MASK] 替代,然后预测 [MASK] 替代位置的原本字符是什么。这样处理的优点是在预测 [MASK] 的过程中,模型通过 Self-Attention 机制能够捕获 [MASK] 位置前后的信息,实现了真正的双向表示。
为了减少预训练阶段与微调阶段存在的差异,在 BERT 实际预训练过程中,15% 训练数据的字符 WordPiece Token 会被选择进行以下三种操作中的一种。
① 80% 的概率选择用 [MASK] 替换,例如 “这个篮球是黑色的” 被替换成 “这个篮球是 “ [MASK] ”;
② 10% 的概率选择用另一个随机单词替换,例如 “这个篮球是黑色的” 可能被替换成 “这个篮球是绿色的”;
③ 10% 的概率保持原本单词不变,例如 “这个篮球是黑色的” 保持原语句不变。
3.2.2 下一句预测(Next Sentence Prediction, NSP)
下一句预测是指预测一个句子是否跟在另一个句子后面。选择语料中 50% 的句子,与其相应的下一句一起形成上下句,作为正样本;其余 50% 的句子随机选择一句和非下一句一起形成上下句,作为负样本。通过对模型进行训练,使其能够根据当前句子信息预测出下一个句子的内容。
在句子预测任务中,BERT 预训练模型可以推断两个句子之间的联系。
4 缺点
- 被 [Mask] 掉的单词做了“独立性假设”,他们之间没有任何关系,是条件独立的,然而有时候这些单词之间是有关系的。
- BERT 在预训练时会出现特殊的 [MASK],但是它在下游的 Fine-Tune 阶段中不会出现,这就造成了预训练和微调之间数据的不匹配。
















 697
697











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











