






1 原理
基于图神经网络的学术推荐算法(Graph Neural Network based Academic Recommendation Algorithm, GARec)
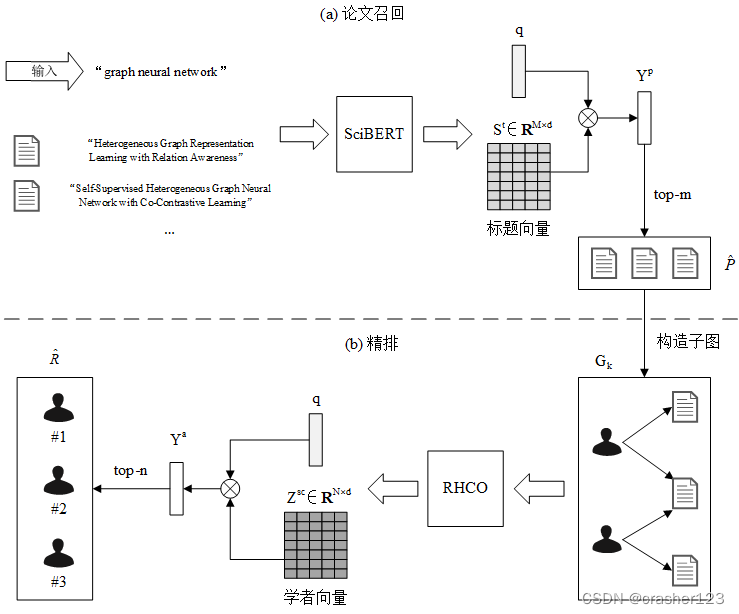
基于图神经网络的学术推荐算法(GARec)就是一种基于GNN的学术推荐方法,可以实现对用户的学术兴趣爱好进行建模,并采用图神经网络的模型对学者进行推荐。
GARec的工作原理主要分为以下几个步骤:
- 构建学术关系网络
首先,需要构建一个学术关系网络,网络中的节点代表学术论文或学者,边代表它们之间的关系。例如,两篇论文之间具有引用关系,或者两位学者之间具有合作关系,可以在它们之间连接一条边。
- 建立学者-论文特征矩阵
针对学者和论文,需要提取出一些相关的特征,例如学者的研究领域、论文的关键词等信息。这里可以使用自然语言处理技术进行特征提取和向量化操作,将每位学者和每篇论文表示为一个特征向量。
- 使用GNN进行学术推荐
接下来,将学术关系网络和学者-论文特征矩阵输入到GNN模型中进行推荐。GNN模型会对网络中的节点进行嵌入(embedding),使得每个学者和论文都可以在一个低维空间中表示出来。在这个低维空间中,相似的学者和论文会被赋予相近的坐标,即具有相似的向量表示。
- 结合用户兴趣进行个性化推荐
最后,根据用户的学术兴趣和历史行为,将这些信息融合到GNN模型中,对学术推荐结果进行个性化过滤和排序。例如,如果用户对某个领域的研究比较感兴趣,那么在推荐结果中就会更多地包含这个领域的论文和学者。
总体来说,基于图神经网络的学术推荐算法(GARec)具有以下优点:
-
能够结合学术关系网络、学者-论文特征矩阵和GNN模型进行推荐,使推荐结果更加准确和全面。
-
能够对学术论文进行建模和推荐,不仅可以为学者提供相关的论文推荐,也能够促进学术交流和合作。
-
能够结合用户的兴趣爱好进行个性化推荐,提高了推荐效果和用户体验。
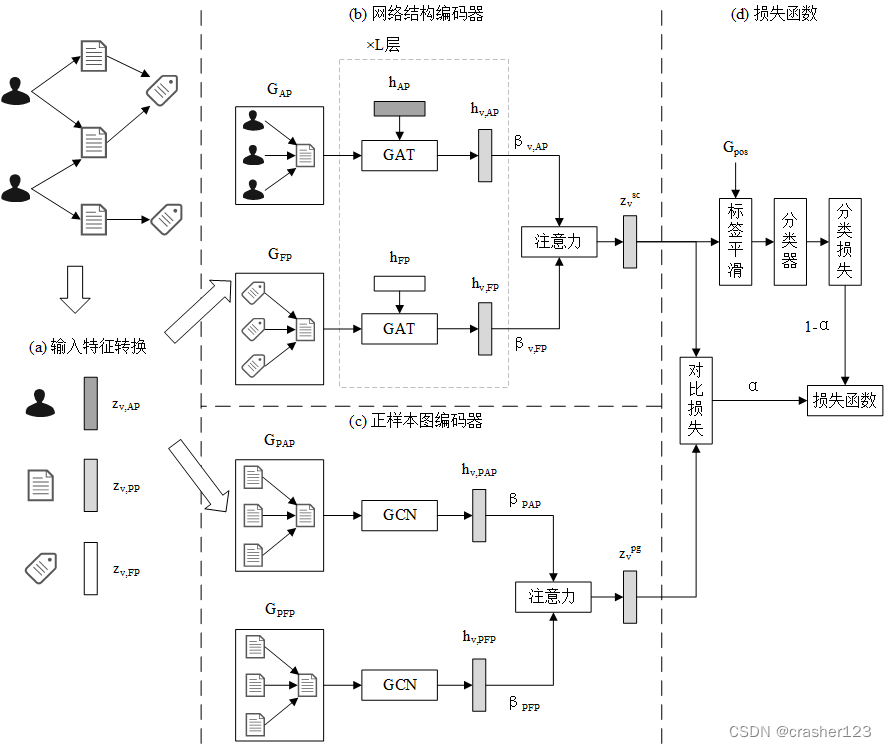
基于对比学习的关系感知异构图神经网络(Relation-aware Heterogeneous Graph Neural Network with Contrastive Learning, RHCO)
2 核心代码
import torch
import torch.nn as nn
import torch.nn.functional as F
from transformers import AutoTokenizer, AutoModel
class ContrastiveSciBERT(nn.Module):
def __init__(self, out_dim, tau, device='cpu'):
"""用于对比学习的SciBERT模型
:param out_dim: int 输出特征维数
:param tau: float 温度参数τ
:param device: torch.device, optional 默认为CPU
"""
super().__init__()
self.tau = tau
self.device = device
self.tokenizer = AutoTokenizer.from_pretrained('allenai/scibert_scivocab_uncased')
self.model = AutoModel.from_pretrained('allenai/scibert_scivocab_uncased').to(device)
self.linear = nn.Linear(self.model.config.hidden_size, out_dim)
def get_embeds(self, texts, max_length=64):
"""将文本编码为向量
:param texts: List[str] 输入文本列表,长度为N
:param max_length: int, optional padding最大长度,默认为64
:return: tensor(N, d_out)
"""
encoded = self.tokenizer(
texts, padding='max_length', truncation=True, max_length=max_length, return_tensors='pt'
).to(self.device)
return self.linear(self.model(**encoded).pooler_output)
def calc_sim(self, texts_a, texts_b):
"""计算两组文本的相似度
:param texts_a: List[str] 输入文本A列表,长度为N
:param texts_b: List[str] 输入文本B列表,长度为N
:return: tensor(N, N) 相似度矩阵,S[i, j] = cos(a[i], b[j]) / τ
"""
embeds_a = self.get_embeds(texts_a) # (N, d_out)
embeds_b = self.get_embeds(texts_b) # (N, d_out)
embeds_a = embeds_a / embeds_a.norm(dim=1, keepdim=True)
embeds_b = embeds_b / embeds_b.norm(dim=1, keepdim=True)
return embeds_a @ embeds_b.t() / self.tau
def forward(self, texts_a, texts_b):
"""计算两组文本的对比损失
:param texts_a: List[str] 输入文本A列表,长度为N
:param texts_b: List[str] 输入文本B列表,长度为N
:return: tensor(N, N), float A对B的相似度矩阵,对比损失
"""
# logits_ab等价于预测概率,对比损失等价于交叉熵损失
logits_ab = self.calc_sim(texts_a, texts_b)
logits_ba = logits_ab.t()
labels = torch.arange(len(texts_a), device=self.device)
loss_ab = F.cross_entropy(logits_ab, labels)
loss_ba = F.cross_entropy(logits_ba, labels)
return logits_ab, (loss_ab + loss_ba) / 2
import argparse
import random
import warnings
import torch
import torch.nn.functional as F
import torch.optim as optim
from dgl.dataloading import MultiLayerNeighborSampler, NodeDataLoader
from dgl.utils import to_dgl_context
from tqdm import tqdm
from gnnrec.config import DATA_DIR
from gnnrec.hge.rhgnn.model import RHGNN
from gnnrec.hge.utils import set_random_seed, get_device, add_node_feat
from gnnrec.kgrec.utils import load_rank_data, recall_paper, TripletNodeCollator, calc_metrics, \
METRICS_STR
def sample_triplets(field_id, true_author_ids, false_author_ids, num_triplets):
"""根据领域学者排名采样三元组(t, ap, an),表示对于领域t,学者ap的排名在an之前
:param field_id: int 领域id
:param true_author_ids: List[int] top-n学者id,真实排名
:param false_author_ids: List[int] 不属于top-n的学者id
:param num_triplets: int 采样的三元组数量
:return: tensor(N, 3) 采样的三元组
"""
n = len(true_author_ids)
easy_margin, hard_margin = int(n * 0.2), int(n * 0.05)
easy_triplets = [
(field_id, true_author_ids[i], true_author_ids[i + easy_margin])
for i in range(n - easy_margin)
] # 简单样本
hard_triplets = [
(field_id, true_author_ids[i], true_author_ids[i + hard_margin])
for i in range(n - hard_margin)
] # 困难样本
m = num_triplets - len(easy_triplets) - len(hard_triplets)
true_false_triplets = [
(field_id, t, f)
for t, f in zip(random.choices(true_author_ids, k=m), random.choices(false_author_ids, k=m))
] # 真-假样本
return torch.tensor(easy_triplets + hard_triplets + true_false_triplets)
def train(args):
set_random_seed(args.seed)
device = get_device(args.device)
g, author_rank, field_ids, true_relevance = load_rank_data(device)
out_dim = g.nodes['field'].data['feat'].shape[1]
add_node_feat(g, 'pretrained', args.node_embed_path, use_raw_id=True)
field_paper = recall_paper(g.cpu(), field_ids, args.num_recall) # {field_id: [paper_id]}
sampler = MultiLayerNeighborSampler([args.neighbor_size] * args.num_layers)
sampler.set_output_context(to_dgl_context(device))
triplet_collator = TripletNodeCollator(g, sampler)
model = RHGNN(
{ntype: g.nodes[ntype].data['feat'].shape[1] for ntype in g.ntypes},
args.num_hidden, out_dim, args.num_rel_hidden, args.num_rel_hidden,
args.num_heads, g.ntypes, g.canonical_etypes, 'author', args.num_layers, args.dropout
).to(device)
if args.load_path:
model.load_state_dict(torch.load(args.load_path, map_location=device))
optimizer = optim.Adam(model.parameters(), lr=args.lr)
scheduler = optim.lr_scheduler.CosineAnnealingLR(
optimizer, T_max=len(field_ids) * args.epochs, eta_min=args.lr / 100
)
warnings.filterwarnings('ignore', 'Setting attributes on ParameterDict is not supported')
for epoch in range(args.epochs):
model.train()
losses = []
for f in tqdm(field_ids):
false_author_ids = list(set(g.in_edges(field_paper[f], etype='writes')[0].tolist()) - set(author_rank[f]))
triplets = sample_triplets(f, author_rank[f], false_author_ids, args.num_triplets).to(device)
aid, blocks = triplet_collator.collate(triplets)
author_embeds = model(blocks, blocks[0].srcdata['feat'])
author_embeds = author_embeds / author_embeds.norm(dim=1, keepdim=True)
aid_map = {a: i for i, a in enumerate(aid.tolist())}
anchor = g.nodes['field'].data['feat'][triplets[:, 0]]
positive = author_embeds[[aid_map[a] for a in triplets[:, 1].tolist()]]
negative = author_embeds[[aid_map[a] for a in triplets[:, 2].tolist()]]
loss = F.triplet_margin_loss(anchor, positive, negative, args.margin)
losses.append(loss.item())
optimizer.zero_grad()
loss.backward()
optimizer.step()
scheduler.step()
torch.cuda.empty_cache()
print('Epoch {:d} | Loss {:.4f}'.format(epoch, sum(losses) / len(losses)))
torch.save(model.state_dict(), args.model_save_path)
if epoch % args.eval_every == 0 or epoch == args.epochs - 1:
print(METRICS_STR.format(*evaluate(
model, g, out_dim, sampler, args.batch_size, device, field_ids, field_paper,
author_rank, true_relevance
)))
torch.save(model.state_dict(), args.model_save_path)
print('模型已保存到', args.model_save_path)
embeds = infer(model, g, 'author', out_dim, sampler, args.batch_size, device)
author_embed_save_path = DATA_DIR / 'rank/author_embed.pkl'
torch.save(embeds.cpu(), author_embed_save_path)
print('学者嵌入已保存到', author_embed_save_path)
@torch.no_grad()
def evaluate(model, g, out_dim, sampler, batch_size, device, field_ids, field_paper, author_rank, true_relevance):
model.eval()
predict_rank = {}
field_feat = g.nodes['field'].data['feat']
author_embeds = infer(model, g, 'author', out_dim, sampler, batch_size, device) # (N_author, d)
for i, f in enumerate(field_ids):
aid = g.in_edges(field_paper[f], etype='writes')[0].cpu().unique()
similarity = torch.matmul(author_embeds[aid], field_feat[f]).cpu()
predict_rank[f] = (aid, similarity)
return calc_metrics(field_ids, author_rank, true_relevance, predict_rank)
@torch.no_grad()
def infer(model, g, ntype, out_dim, sampler, batch_size, device):
model.eval()
embeds = torch.zeros((g.num_nodes(ntype), out_dim), device=device)
loader = NodeDataLoader(g, {ntype: g.nodes(ntype)}, sampler, device=device, batch_size=batch_size)
for _, output_nodes, blocks in tqdm(loader):
embeds[output_nodes[ntype]] = model(blocks, blocks[0].srcdata['feat'])
embeds = embeds / embeds.norm(dim=1, keepdim=True)
return embeds
def main():
parser = argparse.ArgumentParser(description='GARec算法 训练学者排名GNN模型')
parser.add_argument('--seed', type=int, default=0, help='随机数种子')
parser.add_argument('--device', type=int, default=0, help='GPU设备')
# R-HGNN
parser.add_argument('--num-hidden', type=int, default=64, help='隐藏层维数')
parser.add_argument('--num-rel-hidden', type=int, default=8, help='关系表示的隐藏层维数')
parser.add_argument('--num-heads', type=int, default=8, help='注意力头数')
parser.add_argument('--num-layers', type=int, default=2, help='层数')
parser.add_argument('--dropout', type=float, default=0.5, help='Dropout概率')
parser.add_argument('--epochs', type=int, default=100, help='训练epoch数')
parser.add_argument('--batch-size', type=int, default=1024, help='批大小')
parser.add_argument('--neighbor-size', type=int, default=10, help='邻居采样数')
parser.add_argument('--margin', type=float, default=0.02, help='三元组损失间隔参数')
parser.add_argument('--lr', type=float, default=0.001, help='学习率')
parser.add_argument('--load-path', help='模型加载路径,用于继续训练')
# 采样三元组
parser.add_argument('--num-triplets', type=int, default=200, help='每个领域采样三元组数量')
# 评价
parser.add_argument('--eval-every', type=int, default=10, help='每多少个epoch评价一次')
parser.add_argument('--num-recall', type=int, default=200, help='每个领域召回论文的数量')
parser.add_argument('node_embed_path', help='预训练顶点嵌入路径')
parser.add_argument('model_save_path', help='模型保存路径')
args = parser.parse_args()
print(args)
train(args)
if __name__ == '__main__':
main()
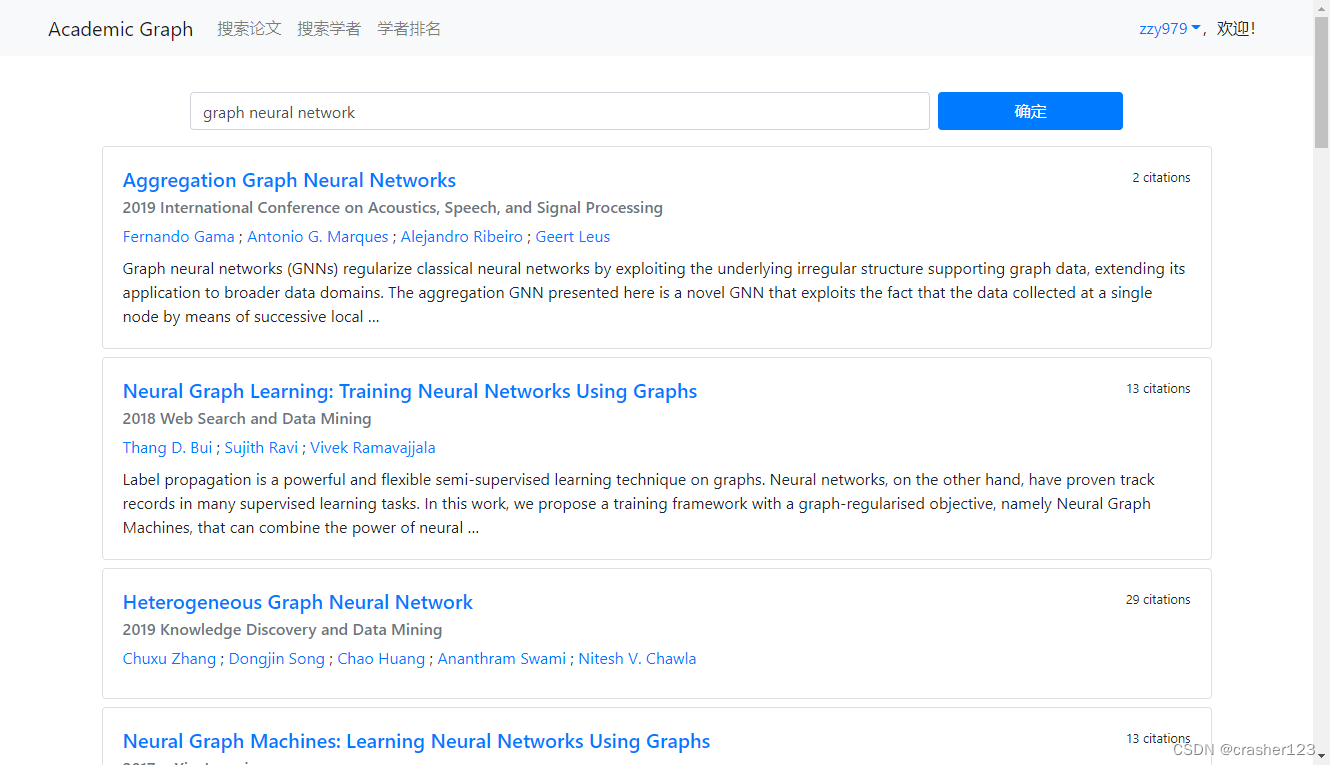
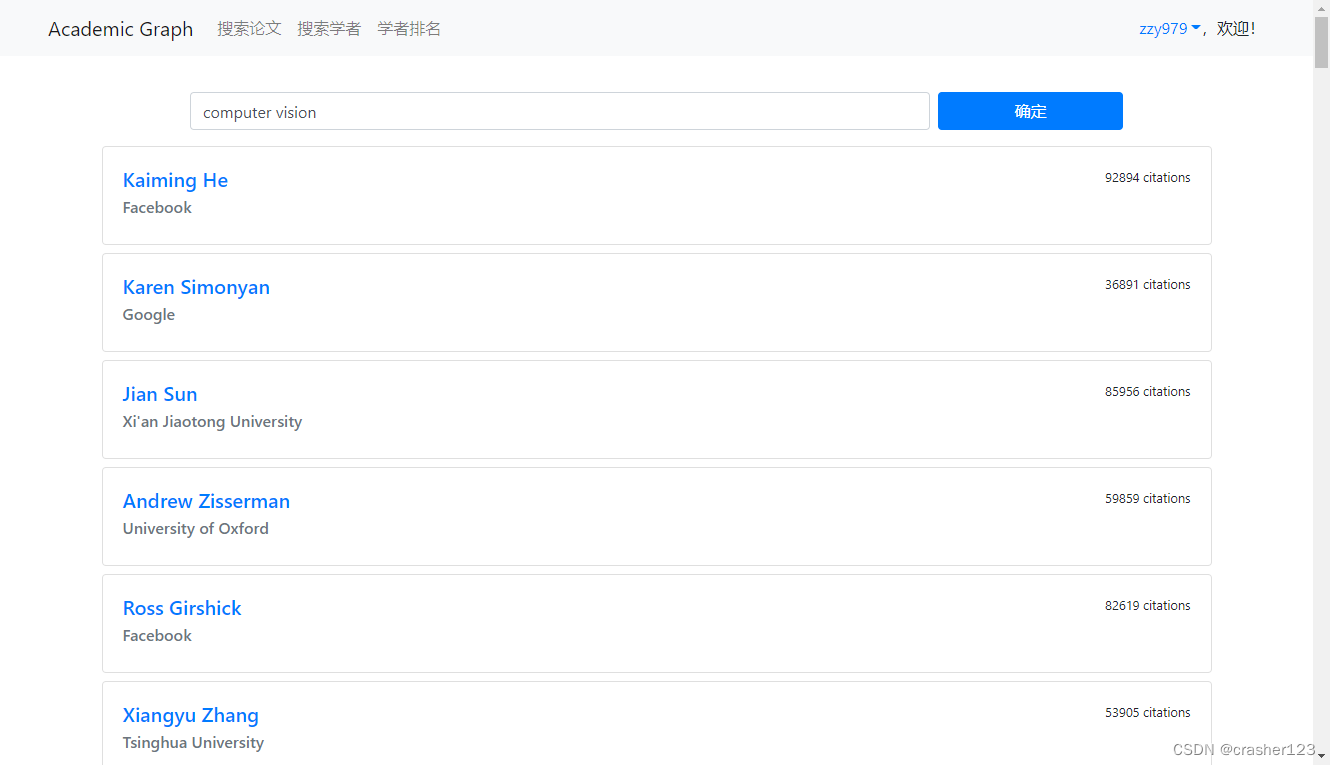
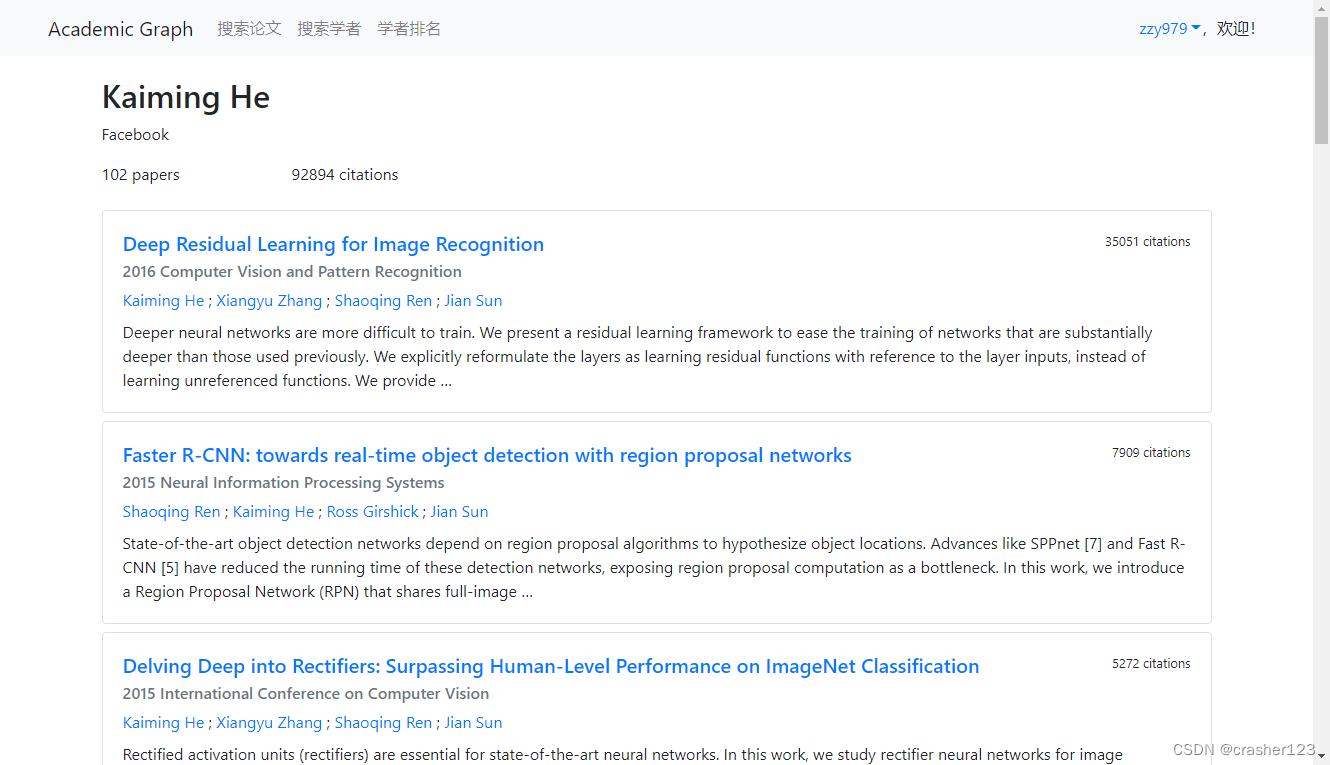
3 运行效果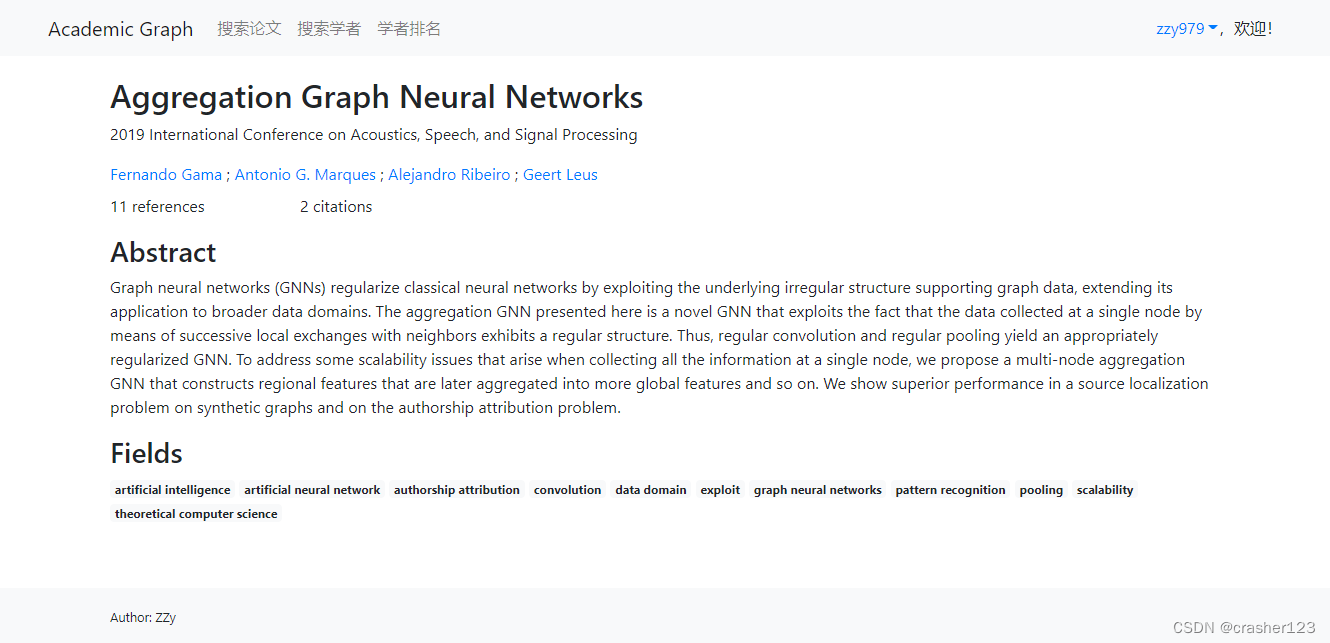















 1417
1417











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









