






本文的 原始地址 ,传送门
下面的正文,如果 出现图片 缺少, 请去原文查找:
尼恩:LLM大模型学习圣经PDF的起源
在40岁老架构师 尼恩的读者交流群(50+)中,经常性的指导小伙伴们改造简历。
经过尼恩的改造之后,很多小伙伴拿到了一线互联网企业如得物、阿里、滴滴、极兔、有赞、希音、百度、网易、美团的面试机会,拿到了大厂机会。
然而,其中一个成功案例,是一个9年经验 网易的小伙伴,当时拿到了一个年薪近80W的大模型架构offer,逆涨50%,那是在去年2023年的 5月。
不到1年,小伙伴也在团队站稳了脚跟,成为了名副其实的大模型 应用 架构师。接下来,尼恩架构团队,通过 梳理一个《LLM大模型学习圣经》 帮助更多的人做LLM架构,拿到年薪100W, 这个内容体系包括下面的内容:
-
《LLM大模型学习圣经:从0到1精通RAG架构,基于LLM+RAG构建生产级企业知识库》
-
《LLM大模型学习圣经:从0到1吃透大模型的顶级架构》
-
《LLM 智能体 学习圣经:从0到1吃透 LLM 智能体 的架构 与实操》
-
《LLM 智能体 学习圣经:从0到1吃透 LLM 智能体 的 中台 架构 与实操》
-
《Spring AI 学习圣经 和配套视频 》
以上学习圣经 的 配套视频, 2025年 5月份之前发布。
什么是 Text2SQL
Text2SQL 是一种将自然语言文本转换为 SQL 查询语句的技术。
简单的来说,就是你说一句需求,Text2SQL 帮你写SQL,并且得到你想要的答案。
它旨在让用户能够使用自然语言来与数据库进行交互,而无需具备专业的 SQL 知识。
例如, “查找年龄大于 30 岁的用户” 这样的自然语言描述, 通过 Text2SQL 转换为 “SELECT * FROM users WHERE age > 30” 这样的 SQL 查询。
Text2SQL 能基本 干掉 我们 sql boy 的工作。
Text2SQL 属于 智能 BI(Business Intelligence,即 商业智能 是一种将数据转化为有价值的信息和见解,以支持企业决策和业务发展的技术和应用。
从这个角度讲 ,BI boy 的工作 ,也快没了
智能 BI 是在传统 BI 基础上,融合了 人工智能 、机器学习、自然语言处理等先进技术,从而具备更强大的数据处理、分析和洞察能力的系统。
它能够自动发现数据中的模式、趋势和关联,为企业提供更精准、深入的业务分析和预测,帮助企业管理者做出更明智的决策。
Text2SQL 关键功能
- 数据整合与管理:、
能从多个不同的数据源,如数据库、文件系统、云服务等,采集和整合数据,并进行清洗、转换和加载,以确保数据的一致性和准确性。
- 可视化分析:
通过直观的图表、图形和仪表板等可视化方式展示数据,使用户能够快速理解数据的含义和趋势。用户还可以通过交互操作,如钻取、筛选、排序等,深入分析数据。
- 自助式分析:
赋予业务用户自行探索和分析数据的能力,无需依赖专业的技术人员。用户可以通过简单的拖拽、选择等操作,快速创建自己所需的分析报表和图表。
- 智能洞察与预测:
利用机器学习和数据挖掘算法,自动发现数据中的隐藏信息和规律,进行趋势预测和异常检测。例如,预测销售额、客户流失率等,帮助企业提前制定应对策略。
- 自然语言处理与对话式分析:
允许用户通过自然语言与智能 BI 系统进行交互,提出问题并获得即时回答。用户可以用日常语言询问关于数据的问题,系统会理解并返回相应的分析结果,使数据分析更加便捷和高效。
从关键功能我们可以得到一个可落地的场景 Text2SQL
Text2SQL 工作原理
Text2SQL 系统通常基于深度学习模型,如循环神经网络(RNN)、长短时记忆网络(LSTM)或 Transformer 等。
这些模型在大量的自然语言文本和对应的 SQL 查询语句对上进行训练,学习如何将自然语言中的语义信息映射到 SQL 的语法结构和语义上。
Text2SQL 关键技术
- 语义理解:
需要准确理解自然语言文本中的语义信息,包括实体、属性、关系等。
例如,对于 “查询上海的员工信息”,要能识别出 “上海” 是地点实体,“员工信息” 是要查询的内容,以及它们之间的关系是查询特定地点的员工信息。
- 语法生成:
根据语义理解的结果,生成符合 SQL 语法的查询语句。这涉及到将自然语言中的逻辑和意图转换为正确的 SQL 关键字、运算符和语句结构。
比如,将 “找出销售额最高的产品” 转换为 “SELECT product_name FROM sales WHERE sales_amount = (SELECT MAX (sales_amount) FROM sales)”。
Text2SQL 应用场景
- 数据库查询:
普通用户可以通过自然语言输入查询需求,方便快捷地从数据库中获取所需信息,无需编写复杂的 SQL 语句。
例如,业务人员可以直接问 “查询上个月销售业绩超过 100 万的销售人员名单”,而不必了解 SQL 的具体语法。
- 数据可视化:
与数据可视化工具结合,用户通过自然语言描述数据需求,Text2SQL 将其转换为 SQL 查询,然后将查询结果可视化展示,帮助用户更直观地理解数据。
- 智能客服:
在企业的客服系统中,客服人员可以使用自然语言通过 Text2SQL 查询数据库,快速获取客户信息、订单状态等相关数据,提高服务效率和质量。
Text2SQL 难点
- 语义模糊性:
自然语言往往存在模糊性和多义性,不同的人可能对同一句话有不同的理解,这给准确的语义理解和 SQL 转换带来困难。
例如,“查找红色和蓝色的汽车”,可能被理解为查找同时具有红色和蓝色的汽车,或者是查找红色的汽车和蓝色的汽车两类
- 复杂查询处理:
对于复杂的业务逻辑和嵌套查询,Text2SQL 需要准确解析自然语言中的多层语义和逻辑关系,并生成正确的 SQL 语句。
例如,“查询每个部门中工资高于该部门平均工资的员工信息”,这需要模型理解部门、员工、工资之间的关系,并进行相应的分组和比较操作。
- 跨领域适应性:
不同领域的数据库具有不同的表结构、字段名称和业务规则,Text2SQL 模型需要具备较强的跨领域适应性,才能在各种不同的数据库环境中准确工作。
Text2SQL 实现的 3大架构
如果我们需要自己实现一个 Text2SQL,应该考虑什么
Text2SQL的实现路径一般有如下 3大架构 方案:
-
**基于PE 工程 实操 的Text2SQL **
-
基于SQLDatabaseChain的方法
-
基于Agent的方法
架构一:基于PE 工程实操的实操Text2SQL
基于prompt template提示词工程实操的实操Text2SQL
NL2SQL核心在于如何把自然语言组装成Prompt,并交给LLM转化成SQL。
知乎 官网上一个标准自然语言转SQL的例子。
首先 准备一堆提示词:

接下来就直接 在 AI界面 进行 提问,让ai 编写sql:
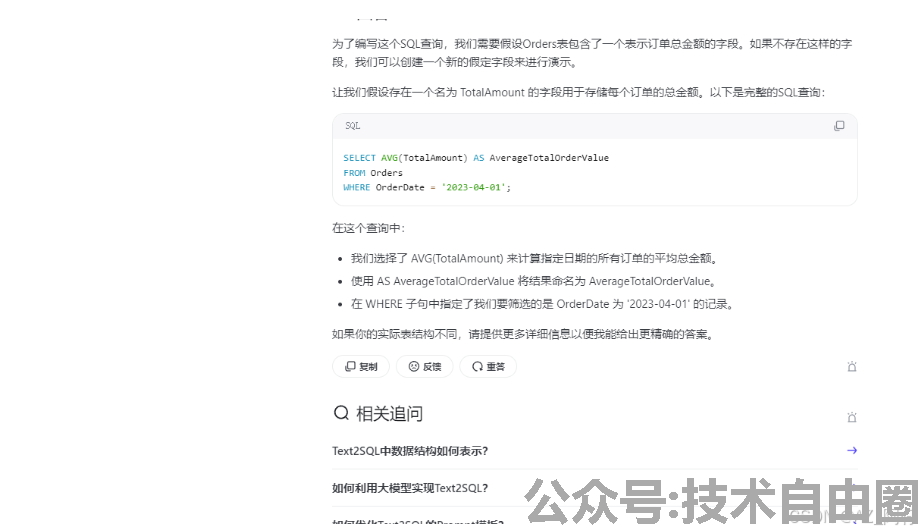
可以对比一下OpenAI的结果。
同样的 系统提示词。
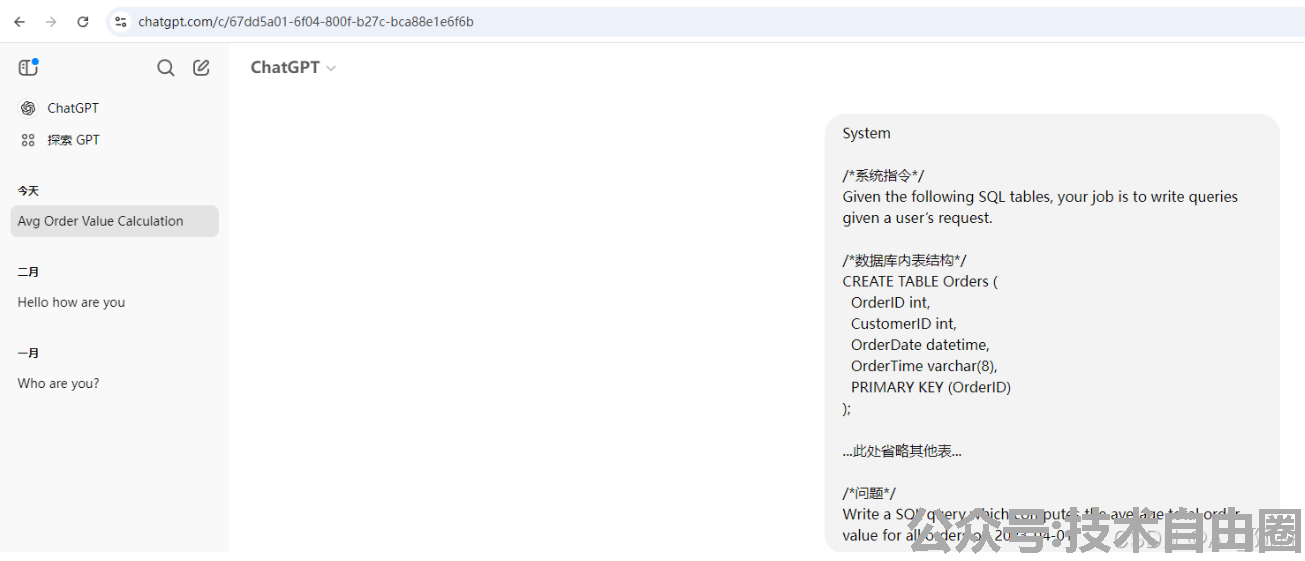
接下来就直接 在 OpenAI 界面 进行 提问,让ai 编写sql:

两者对比起来,差距好像有点明显啊, OpenAI 还是牛逼多了
NL2SQL的Prompt 提示词工程
对于 NL2SQL 来说,NL2SQL的Prompt基本上就是几个部分组成:
- 指令(Instruction):
比如,“你是一个SQL生成专家。请参考如下的表格结构,直接输出SQL语句,不要多余的解释。”
- 数据结构(Table Schema):
类似于语言翻译中的“词汇表”。
即需要使用的数据库表结构,由于大模型无法直接访问数据库,需要把元数据的结构组装进入Prompt,通常包括表名、列名、列的类型、列的含义、主外键信息。
- 用户问题(Questions):
自然语言表达的问题,比如,“统计上个月的平均订单额”。
- 参考样例(Few-shot):
这是一个可选项,当然也是提示工程的常见技巧。
即指导大模型生成本次SQL的参考样例。
- 其他提示(Tips):
其他认为有必要的指示。比如要求生成的SQL中不允许出现的表达式,或者要求列名必须用“table.column"的形式等
架构二:基于SQLDatabase实操Text2SQL
LangChain 提供基于LLM的SQLDatabaseChain 数据库操作 链。
关于 LangChain 的系统化学习,请参考 尼恩团队的 LangChain 学习圣经。
LangChain学习圣经:从0到1,精通LLM大模型开发框架
SQLDatabaseChain 可以利用LLM的能力将自然语言表述的query转化为SQL,连接DB进行查询,并利用LLM组装润色结果,返回最终 answer。
实操第一步骤:本地使用Mysql创建表
CREATE TABLE `orders` (
`OrderID` int NOT NULL,
`CustomerID` int DEFAULT NULL,
`OrderDate` datetime DEFAULT NULL,
`OrderTime` varchar(8) DEFAULT NULL,
PRIMARY KEY (`OrderID`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_0900_ai_ci;
实操第2步骤:插入25条数据
INSERT INTO `test_db`.`orders` (`OrderID`, `CustomerID`, `OrderDate`, `OrderTime`) VALUES (1, 101, '2024-01-01 10:30:00', '10:30:00');
INSERT INTO `test_db`.`orders` (`OrderID`, `CustomerID`, `OrderDate`, `OrderTime`) VALUES (2, 102, '2024-02-15 14:45:00', '14:45:00');
INSERT INTO `test_db`.`orders` (`OrderID`, `CustomerID`, `OrderDate`, `OrderTime`) VALUES (3, 103, '2024-03-20 09:15:00', '09:15:00');
INSERT INTO `test_db`.`orders` (`OrderID`, `CustomerID`, `OrderDate`, `OrderTime`) VALUES (4, 104, '2024-04-05 16:20:00', '16:20:00');
INSERT INTO `test_db`.`orders` (`OrderID`, `CustomerID`, `OrderDate`, `OrderTime`) VALUES (5, 105, '2024-05-12 11:50:00', '11:50:00');
INSERT INTO `test_db`.`orders` (`OrderID`, `CustomerID`, `OrderDate`, `OrderTime`) VALUES (6, 106, '2024-06-25 13:30:00', '13:30:00');
INSERT INTO `test_db`.`orders` (`OrderID`, `CustomerID`, `OrderDate`, `OrderTime`) VALUES (7, 107, '2024-07-08 15:40:00', '15:40:00');
INSERT INTO `test_db`.`orders` (`OrderID`, `CustomerID`, `OrderDate`, `OrderTime`) VALUES (8, 108, '2024-08-18 17:10:00', '17:10:00');
INSERT INTO `test_db`.`orders` (`OrderID`, `CustomerID`, `OrderDate`, `OrderTime`) VALUES (9, 109, '2024-09-03 08:25:00', '08:25:00');
INSERT INTO `test_db`.`orders` (`OrderID`, `CustomerID`, `OrderDate`, `OrderTime`) VALUES (10, 110, '2024-10-10 12:00:00', '12:00:00');
INSERT INTO `test_db`.`orders` (`OrderID`, `CustomerID`, `OrderDate`, `OrderTime`) VALUES (11, 111, '2024-11-22 14:15:00', '14:15:00');
INSERT INTO `test_db`.`orders` (`OrderID`, `CustomerID`, `OrderDate`, `OrderTime`) VALUES (12, 112, '2024-12-07 16:30:00', '16:30:00');
INSERT INTO `test_db`.`orders` (`OrderID`, `CustomerID`, `OrderDate`, `OrderTime`) VALUES (13, 113, '2025-01-14 09:45:00', '09:45:00');
INSERT INTO `test_db`.`orders` (`OrderID`, `CustomerID`, `OrderDate`, `OrderTime`) VALUES (14, 114, '2025-02-28 13:00:00', '13:00:00');
INSERT INTO `test_db`.`orders` (`OrderID`, `CustomerID`, `OrderDate`, `OrderTime`) VALUES (15, 115, '2025-03-11 15:20:00', '15:20:00');
INSERT INTO `test_db`.`orders` (`OrderID`, `CustomerID`, `OrderDate`, `OrderTime`) VALUES (16, 116, '2025-04-23 17:40:00', '17:40:00');
INSERT INTO `test_db`.`orders` (`OrderID`, `CustomerID`, `OrderDate`, `OrderTime`) VALUES (17, 117, '2025-05-06 10:10:00', '10:10:00');
INSERT INTO `test_db`.`orders` (`OrderID`, `CustomerID`, `OrderDate`, `OrderTime`) VALUES (18, 118, '2025-06-19 12:30:00', '12:30:00');
INSERT INTO `test_db`.`orders` (`OrderID`, `CustomerID`, `OrderDate`, `OrderTime`) VALUES (19, 119, '2025-07-31 14:50:00', '14:50:00');
INSERT INTO `test_db`.`orders` (`OrderID`, `CustomerID`, `OrderDate`, `OrderTime`) VALUES (20, 120, '2025-08-13 16:05:00', '16:05:00');
INSERT INTO `test_db`.`orders` (`OrderID`, `CustomerID`, `OrderDate`, `OrderTime`) VALUES (21, 121, '2025-09-26 08:40:00', '08:40:00');
INSERT INTO `test_db`.`orders` (`OrderID`, `CustomerID`, `OrderDate`, `OrderTime`) VALUES (22, 122, '2025-10-09 11:15:00', '11:15:00');
INSERT INTO `test_db`.`orders` (`OrderID`, `CustomerID`, `OrderDate`, `OrderTime`) VALUES (23, 123, '2025-11-21 13:35:00', '13:35:00');
INSERT INTO `test_db`.`orders` (`OrderID`, `CustomerID`, `OrderDate`, `OrderTime`) VALUES (24, 124, '2025-12-04 15:55:00', '15:55:00');
INSERT INTO `test_db`.`orders` (`OrderID`, `CustomerID`, `OrderDate`, `OrderTime`) VALUES (25, 125, '2026-01-17 09:20:00', '09:20:00');
实操第3步骤:撸铁
写一个 python 代码, 调用openai接口作为llm,连接数据库, 然后 得到查询的结果
当然,这个代码也是用ai写的, 一句话就生成了。
现在 ai 已经 把 crud代码 一下写完了, crud boy 的活(牛马活儿),已经快被 ai干没了。
pip install --upgrade --quiet langchain langchain-community langchain-openai
pip install langchain-experimental
pip install mysql-connector-python
pip install psycopg2-binary
from langchain.llms import OpenAI
from langchain.utilities import SQLDatabase
from langchain_experimental.sql import SQLDatabaseChain
import os
// OPENAI_API_KEY 需要填入 openai的key,魔法节点选择漂亮国,防止被封
os.environ["OPENAI_API_KEY"] = "your open ai key"
// db = SQLDatabase.from_uri("sqlite:///..../Chinook.db")
db = SQLDatabase.from_uri("mysql+mysqlconnector://root:123456@localhost:3306/test_db")
llm = OpenAI(temperature=0, verbose=True)
db_chain = SQLDatabaseChain.from_llm(llm, db, verbose=True)
db_chain.run("总共有多少订单?")
跑代码之前,通过pip 安装一些需要的python库。
调用结果如下:
G:\lession\AI2\demo\demo_16\example\text2sql01.py:13: LangChainDeprecationWarning: The method `Chain.run` was deprecated in langchain 0.1.0 and will be removed in 1.0. Use :meth:`~invoke` instead.
db_chain.run("总共有多少订单?")
> Entering new SQLDatabaseChain chain...
总共有多少订单?
SQLQuery:SELECT COUNT(*) AS total_orders FROM orders
SQLResult: [(25,)]
Answer:25
> Finished chain.

基于SQLDatabaseChain实现的Text2SQL是最基础的实践方式。
简单,而且粗暴。
但,SQLDatabaseChain 对于逻辑复杂的查询在稳定性、可靠性、安全性方面可能无法达到预期,比如输出幻觉问题、数据安全问题。
架构三:基于Agent 智能体实操Text2SQL
LangChain的SQL Agent提供一种比Chain更灵活的与SQL数据库交互的方式。
这里又用到 LangChain ,关于 LangChain 的系统化学习,请参考 尼恩团队的 LangChain 学习圣经。
LangChain学习圣经:从0到1,精通LLM大模型开发框架
LangChain的SQL Agent介绍
LangChain 的SQL Agent主要有以下优点:
- 可以根据Database Schema和数据库的内容(如描述特定的表)回答问题
- 可以通过运行生成的查询、捕获回溯信息并正确地重新生成,以此来纠错
- 可以根据需要多次查询数据库以回答用户问题
- 仅检索相关表格的schema节省token
使用create_sql_agent构造器来初始化SQL Agent,Agent使用的SQLDatabaseToolkit包含用于执行以下操作的工具:
- 创建和执行查询
- 检查查询语法
- 检索表格的描述
- ……等等
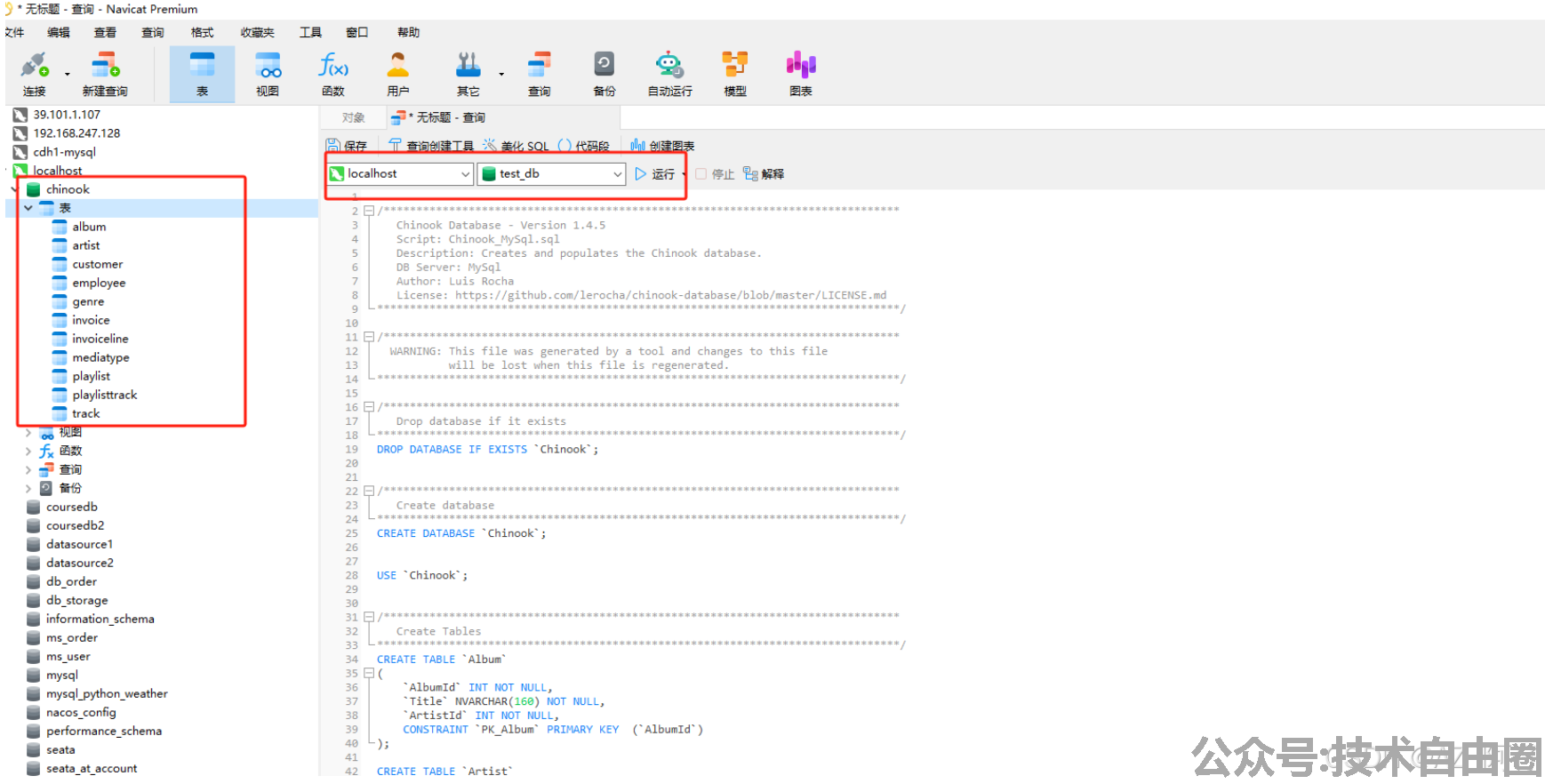
实操第一步骤:创建数据库文件 chinook 库
来自 https://github.com/lerocha/chinook-database/blob/master/ChinookDatabase/DataSources/Chinook_MySql.sql
直接把文件内容拷贝到navicate执行,可以得到chinook库和对应的表格
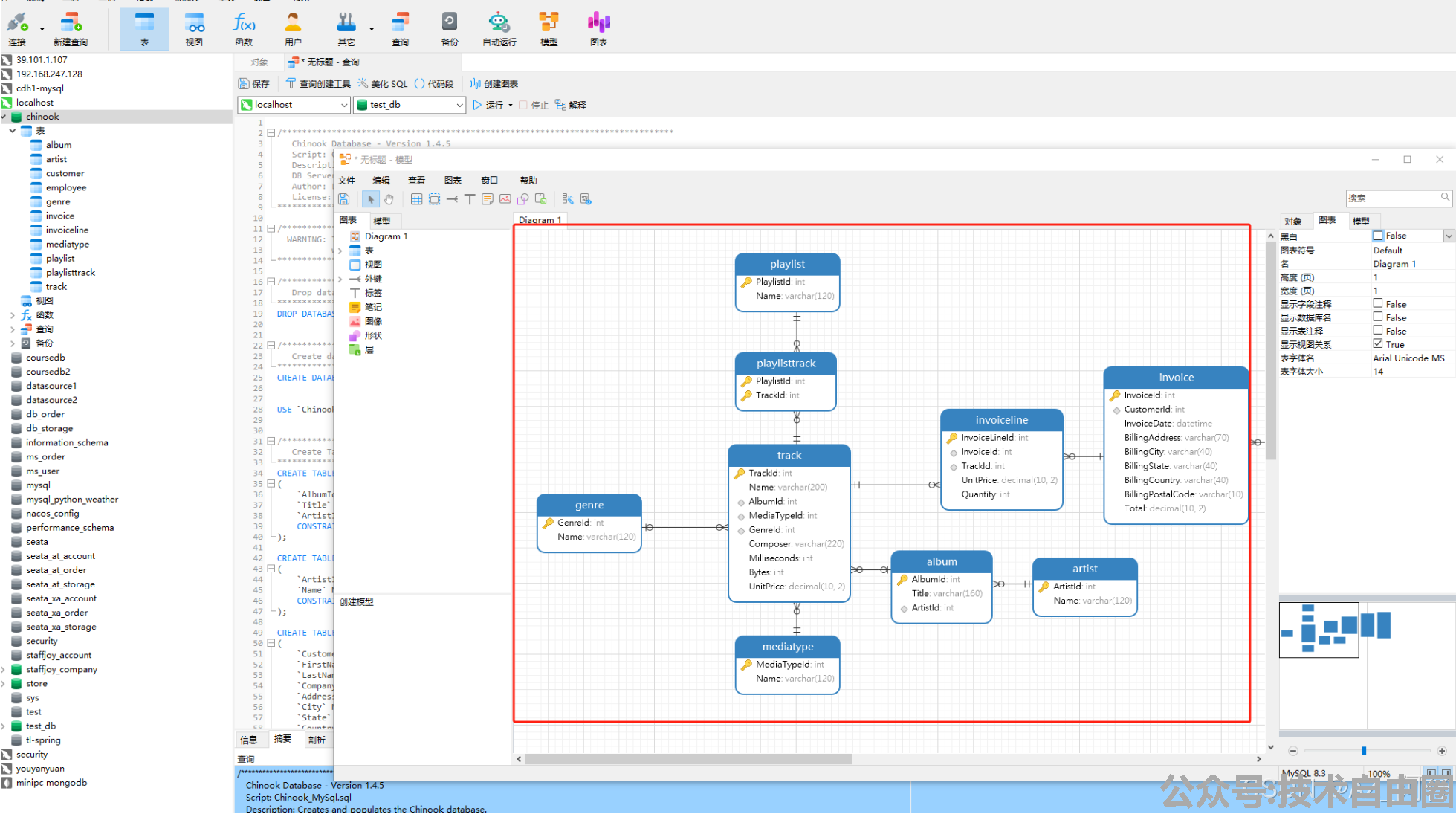
通过navicate逆向数据库到模型可以得到 表结构和关系,这个关系可以作为后续的Promot内容基础
使用如下代码
from langchain.llms import OpenAI
from langchain.utilities import SQLDatabase
from langchain_experimental.sql import SQLDatabaseChain
import os
os.environ["OPENAI_API_KEY"] = "sk-proj-your open ai key"
//连接本地数据库
db = SQLDatabase.from_uri("mysql+mysqlconnector://root:123456@localhost:3306/chinook")
// 打印数据库类型和表格
print(db.dialect)
print(db.get_usable_table_names())
db.run("SELECT * FROM Artist LIMIT 10;")
运行结果如下:
mysql
['album', 'artist', 'customer', 'employee', 'genre', 'invoice', 'invoiceline', 'mediatype', 'playlist', 'playlisttrack', 'track']

实操第2步骤:使用 agent_executor 实现Text2SQL
我们将使用OpenAI聊天模型和"openai-tools" agent,该 agent 将使用OpenAI的 function-calling API来驱动agent 的工具选择和调用。
代码如下:
agent_executor = create_sql_agent(llm, db=db, agent_type="openai-tools", verbose=True)
正如我们所看到的,agent 将首先选择哪些表是相关的,然后将这些表的schema和一些示例行添加到prompt中。
from langchain.utilities import SQLDatabase
from langchain_community.agent_toolkits import create_sql_agent
from langchain_openai import ChatOpenAI
import os
os.environ["OPENAI_API_KEY"] = "sk-proj-your open ai key"
db = SQLDatabase.from_uri("mysql+mysqlconnector://root:123456@localhost:3306/chinook")
llm = ChatOpenAI(model="gpt-3.5-turbo", temperature=0)
agent_executor = create_sql_agent(llm, db=db, agent_type="openai-tools", verbose=True)
agent_executor.invoke(
"List the total sales per country. Which country's customers spent the most?"
)
运行结果:
)G:\lession\AI2\demo\demo_16\example\text2sql03.py:1: LangChainDeprecationWarning: Importing SQLDatabase from langchain.utilities is deprecated. Please replace deprecated imports:
>> from langchain.utilities import SQLDatabase
with new imports of:
>> from langchain_community.utilities import SQLDatabase
You can use the langchain cli to **automatically** upgrade many imports. Please see documentation here <https://python.langchain.com/docs/versions/v0_2/>
from langchain.utilities import SQLDatabase
> Entering new SQL Agent Executor chain...
Invoking: `sql_db_list_tables` with `{}`
album, artist, customer, employee, genre, invoice, invoiceline, mediatype, playlist, playlisttrack, track
Invoking: `sql_db_schema` with `{'table_names': 'customer, invoice, invoiceline'}`
CREATE TABLE customer (
`CustomerId` INTEGER NOT NULL,
`FirstName` VARCHAR(40) CHARACTER SET utf8mb3 COLLATE utf8mb3_general_ci NOT NULL,
`LastName` VARCHAR(20) CHARACTER SET utf8mb3 COLLATE utf8mb3_general_ci NOT NULL,
`Company` VARCHAR(80) CHARACTER SET utf8mb3 COLLATE utf8mb3_general_ci,
`Address` VARCHAR(70) CHARACTER SET utf8mb3 COLLATE utf8mb3_general_ci,
`City` VARCHAR(40) CHARACTER SET utf8mb3 COLLATE utf8mb3_general_ci,
`State` VARCHAR(40) CHARACTER SET utf8mb3 COLLATE utf8mb3_general_ci,
`Country` VARCHAR(40) CHARACTER SET utf8mb3 COLLATE utf8mb3_general_ci,
`PostalCode` VARCHAR(10) CHARACTER SET utf8mb3 COLLATE utf8mb3_general_ci,
`Phone` VARCHAR(24) CHARACTER SET utf8mb3 COLLATE utf8mb3_general_ci,
`Fax` VARCHAR(24) CHARACTER SET utf8mb3 COLLATE utf8mb3_general_ci,
`Email` VARCHAR(60) CHARACTER SET utf8mb3 COLLATE utf8mb3_general_ci NOT NULL,
`SupportRepId` INTEGER,
PRIMARY KEY (`CustomerId`),
CONSTRAINT `FK_CustomerSupportRepId` FOREIGN KEY(`SupportRepId`) REFERENCES employee (`EmployeeId`)
)ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE utf8mb4_0900_ai_ci
/*
3 rows from customer table:
CustomerId FirstName LastName Company Address City State Country PostalCode Phone Fax Email SupportRepId
1 Luís Gonçalves Embraer - Empresa Brasileira de Aeronáutica S.A. Av. Brigadeiro Faria Lima, 2170 São José dos Campos SP Brazil 12227-000 +55 (12) 3923-5555 +55 (12) 3923-5566 luisg@embraer.com.br 3
2 Leonie Köhler None Theodor-Heuss-Straße 34 Stuttgart None Germany 70174 +49 0711 2842222 None leonekohler@surfeu.de 5
3 François Tremblay None 1498 rue Bélanger Montréal QC Canada H2G 1A7 +1 (514) 721-4711 None ftremblay@gmail.com 3
*/
CREATE TABLE invoice (
`InvoiceId` INTEGER NOT NULL,
`CustomerId` INTEGER NOT NULL,
`InvoiceDate` DATETIME NOT NULL,
`BillingAddress` VARCHAR(70) CHARACTER SET utf8mb3 COLLATE utf8mb3_general_ci,
`BillingCity` VARCHAR(40) CHARACTER SET utf8mb3 COLLATE utf8mb3_general_ci,
`BillingState` VARCHAR(40) CHARACTER SET utf8mb3 COLLATE utf8mb3_general_ci,
`BillingCountry` VARCHAR(40) CHARACTER SET utf8mb3 COLLATE utf8mb3_general_ci,
`BillingPostalCode` VARCHAR(10) CHARACTER SET utf8mb3 COLLATE utf8mb3_general_ci,
`Total` DECIMAL(10, 2) NOT NULL,
PRIMARY KEY (`InvoiceId`),
CONSTRAINT `FK_InvoiceCustomerId` FOREIGN KEY(`CustomerId`) REFERENCES customer (`CustomerId`)
)ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE utf8mb4_0900_ai_ci
/*
3 rows from invoice table:
InvoiceId CustomerId InvoiceDate BillingAddress BillingCity BillingState BillingCountry BillingPostalCode Total
1 2 2021-01-01 00:00:00 Theodor-Heuss-Straße 34 Stuttgart None Germany 70174 1.98
2 4 2021-01-02 00:00:00 Ullevålsveien 14 Oslo None Norway 0171 3.96
3 8 2021-01-03 00:00:00 Grétrystraat 63 Brussels None Belgium 1000 5.94
*/
CREATE TABLE invoiceline (
`InvoiceLineId` INTEGER NOT NULL,
`InvoiceId` INTEGER NOT NULL,
`TrackId` INTEGER NOT NULL,
`UnitPrice` DECIMAL(10, 2) NOT NULL,
`Quantity` INTEGER NOT NULL,
PRIMARY KEY (`InvoiceLineId`),
CONSTRAINT `FK_InvoiceLineInvoiceId` FOREIGN KEY(`InvoiceId`) REFERENCES invoice (`InvoiceId`),
CONSTRAINT `FK_InvoiceLineTrackId` FOREIGN KEY(`TrackId`) REFERENCES track (`TrackId`)
)ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE utf8mb4_0900_ai_ci
/*
3 rows from invoiceline table:
InvoiceLineId InvoiceId TrackId UnitPrice Quantity
1 1 2 0.99 1
2 1 4 0.99 1
3 2 6 0.99 1
*/
Invoking: `sql_db_query` with `{'query': 'SELECT c.Country, SUM(i.Total) AS TotalSales\nFROM customer c\nJOIN invoice i ON c.CustomerId = i.CustomerId\nGROUP BY c.Country\nORDER BY TotalSales DESC'}`
[('USA', Decimal('523.06')), ('Canada', Decimal('303.96')), ('France', Decimal('195.10')), ('Brazil', Decimal('190.10')), ('Germany', Decimal('156.48')), ('United Kingdom', Decimal('112.86')), ('Czech Republic', Decimal('90.24')), ('Portugal', Decimal('77.24')), ('India', Decimal('75.26')), ('Chile', Decimal('46.62')), ('Hungary', Decimal('45.62')), ('Ireland', Decimal('45.62')), ('Austria', Decimal('42.62')), ('Finland', Decimal('41.62')), ('Netherlands', Decimal('40.62')), ('Norway', Decimal('39.62')), ('Sweden', Decimal('38.62')), ('Belgium', Decimal('37.62')), ('Denmark', Decimal('37.62')), ('Italy', Decimal('37.62')), ('Poland', Decimal('37.62')), ('Spain', Decimal('37.62')), ('Australia', Decimal('37.62')), ('Argentina', Decimal('37.62'))]The total sales per country are as follows:
1. USA: $523.06
2. Canada: $303.96
3. France: $195.10
4. Brazil: $190.10
5. Germany: $156.48
The country whose customers spent the most is the USA with a total sales amount of $523.06.
> Finished chain.
这里打印了 agent_executor 智能体的 思考过程。
思考过程,包括 推理出了可以执行的mysql,执行mysql,并得出了最后的结论
从这里,我们得到了可执行的mysql,以及问题的答案,那么接下来应该思考的是性能的优化,那么,优化谁?
又该优化什么地方?
这里我们需要优化agent的性能, 需要使用 few-shot 能力
实操第3步骤:RAG:使用动态few-shot prompt
为了优化 agent 性能,我们可以提供具有特定领域知识的自定义prompt。
在这种情况下,我们将使用example selector 创建few shot prompt,该example selector根据用户输入动态构建few shot prompt。
通过在 prompt 中插入相关的query作为参考,可以帮助模型进行更好的查询。
个人的理解,可以认为是属于提示词类型的RAG
from langchain.utilities import SQLDatabase
from langchain_community.agent_toolkits import create_sql_agent
from langchain_openai import ChatOpenAI
import os
// 我们需要一些用户输入SQL查询示例:
examples = [
{"input": "List all artists.", "query": "SELECT * FROM Artist;"},
{
"input": "Find all albums for the artist 'AC/DC'.",
"query": "SELECT * FROM Album WHERE ArtistId = (SELECT ArtistId FROM Artist WHERE Name = 'AC/DC');",
},
{
"input": "List all tracks in the 'Rock' genre.",
"query": "SELECT * FROM Track WHERE GenreId = (SELECT GenreId FROM Genre WHERE Name = 'Rock');",
},
{
"input": "Find the total duration of all tracks.",
"query": "SELECT SUM(Milliseconds) FROM Track;",
},
{
"input": "List all customers from Canada.",
"query": "SELECT * FROM Customer WHERE Country = 'Canada';",
},
{
"input": "How many tracks are there in the album with ID 5?",
"query": "SELECT COUNT(*) FROM Track WHERE AlbumId = 5;",
},
{
"input": "Find the total number of invoices.",
"query": "SELECT COUNT(*) FROM Invoice;",
},
{
"input": "List all tracks that are longer than 5 minutes.",
"query": "SELECT * FROM Track WHERE Milliseconds > 300000;",
},
{
"input": "Who are the top 5 customers by total purchase?",
"query": "SELECT CustomerId, SUM(Total) AS TotalPurchase FROM Invoice GROUP BY CustomerId ORDER BY TotalPurchase DESC LIMIT 5;",
},
{
"input": "Which albums are from the year 2000?",
"query": "SELECT * FROM Album WHERE strftime('%Y', ReleaseDate) = '2000';",
},
{
"input": "How many employees are there",
"query": 'SELECT COUNT(*) FROM "Employee"',
},
]
os.environ["OPENAI_API_KEY"] = "sk-your open ai key"
db = SQLDatabase.from_uri("mysql+mysqlconnector://root:123456@localhost:3306/chinook")
llm = ChatOpenAI(model="gpt-3.5-turbo", temperature=0)
from langchain_community.vectorstores import FAISS
from langchain_core.example_selectors import SemanticSimilarityExampleSelector
from langchain_openai import OpenAIEmbeddings
// 我们可以创建example selector。这里将采用实际的用户输入,并选择一些示例添加到few-shot prompt中。使用SemanticSimilarityExampleSelector基于配置的embedding和向量存储执行语义搜索,以找到与输入最相似的示例:
example_selector = SemanticSimilarityExampleSelector.from_examples(
examples,
OpenAIEmbeddings(),
FAISS,
k=5,
input_keys=["input"],
)
// 创建FewShotPromptTemplate,它的参数包括example selector、用于格式化每个示例的example prompt,以及放在格式化示例前后的字符串前缀和后缀
from langchain_core.prompts import (
ChatPromptTemplate,
FewShotPromptTemplate,
MessagesPlaceholder,
PromptTemplate,
SystemMessagePromptTemplate,
)
// Prompt的内容如下,由系统指令、few-shot示例和用户query组成:
system_prefix = """You are an agent designed to interact with a SQL database.
Given an input question, create a syntactically correct {dialect} query to run, then look at the results of the query and return the answer.
Unless the user specifies a specific number of examples they wish to obtain, always limit your query to at most {top_k} results.
You can order the results by a relevant column to return the most interesting examples in the database.
Never query for all the columns from a specific table, only ask for the relevant columns given the question.
You have access to tools for interacting with the database.
Only use the given tools. Only use the information returned by the tools to construct your final answer.
You MUST double check your query before executing it. If you get an error while executing a query, rewrite the query and try again.
DO NOT make any DML statements (INSERT, UPDATE, DELETE, DROP etc.) to the database.
If the question does not seem related to the database, just return "I don't know" as the answer.
Here are some examples of user inputs and their corresponding SQL queries:"""
few_shot_prompt = FewShotPromptTemplate(
example_selector=example_selector,
example_prompt=PromptTemplate.from_template(
"User input: {input}\nSQL query: {query}"
),
input_variables=["input", "dialect", "top_k"],
prefix=system_prefix,
suffix="",
)
// 底层代理是OpenAI tools agent,它使用OpenAI function calling,因此完整的prompt应该是带有human message template 和 agent_scratchpad MessagesPlaceholder的 chat prompt。few-shot prompt将用于system message
full_prompt = ChatPromptTemplate.from_messages(
[
SystemMessagePromptTemplate(prompt=few_shot_prompt),
("human", "{input}"),
MessagesPlaceholder("agent_scratchpad"),
]
)
prompt_val = full_prompt.invoke(
{
"input": "How many arists are there",
"top_k": 5,
"dialect": "SQLite",
"agent_scratchpad": [],
}
)
// print(prompt_val.to_string())
agent = create_sql_agent(
llm=llm,
db=db,
prompt=full_prompt,
verbose=True,
agent_type="openai-tools",
)
agent.invoke({"input": "How many artists are there?"})
运行结果
G:\lession\AI2\demo\demo_16\example\text2sql03.py:1: LangChainDeprecationWarning: Importing SQLDatabase from langchain.utilities is deprecated. Please replace deprecated imports:
>> from langchain.utilities import SQLDatabase
with new imports of:
>> from langchain_community.utilities import SQLDatabase
You can use the langchain cli to **automatically** upgrade many imports. Please see documentation here <https://python.langchain.com/docs/versions/v0_2/>
from langchain.utilities import SQLDatabase
> Entering new SQL Agent Executor chain...
Invoking: `sql_db_list_tables` with `{}`
album, artist, customer, employee, genre, invoice, invoiceline, mediatype, playlist, playlisttrack, track
Invoking: `sql_db_schema` with `{'table_names': 'customer, invoice, invoiceline'}`
CREATE TABLE customer (
`CustomerId` INTEGER NOT NULL,
`FirstName` VARCHAR(40) CHARACTER SET utf8mb3 COLLATE utf8mb3_general_ci NOT NULL,
`LastName` VARCHAR(20) CHARACTER SET utf8mb3 COLLATE utf8mb3_general_ci NOT NULL,
`Company` VARCHAR(80) CHARACTER SET utf8mb3 COLLATE utf8mb3_general_ci,
`Address` VARCHAR(70) CHARACTER SET utf8mb3 COLLATE utf8mb3_general_ci,
`City` VARCHAR(40) CHARACTER SET utf8mb3 COLLATE utf8mb3_general_ci,
`State` VARCHAR(40) CHARACTER SET utf8mb3 COLLATE utf8mb3_general_ci,
`Country` VARCHAR(40) CHARACTER SET utf8mb3 COLLATE utf8mb3_general_ci,
`PostalCode` VARCHAR(10) CHARACTER SET utf8mb3 COLLATE utf8mb3_general_ci,
`Phone` VARCHAR(24) CHARACTER SET utf8mb3 COLLATE utf8mb3_general_ci,
`Fax` VARCHAR(24) CHARACTER SET utf8mb3 COLLATE utf8mb3_general_ci,
`Email` VARCHAR(60) CHARACTER SET utf8mb3 COLLATE utf8mb3_general_ci NOT NULL,
`SupportRepId` INTEGER,
PRIMARY KEY (`CustomerId`),
CONSTRAINT `FK_CustomerSupportRepId` FOREIGN KEY(`SupportRepId`) REFERENCES employee (`EmployeeId`)
)COLLATE utf8mb4_0900_ai_ci ENGINE=InnoDB DEFAULT CHARSET=utf8mb4
/*
3 rows from customer table:
CustomerId FirstName LastName Company Address City State Country PostalCode Phone Fax Email SupportRepId
1 Luís Gonçalves Embraer - Empresa Brasileira de Aeronáutica S.A. Av. Brigadeiro Faria Lima, 2170 São José dos Campos SP Brazil 12227-000 +55 (12) 3923-5555 +55 (12) 3923-5566 luisg@embraer.com.br 3
2 Leonie Köhler None Theodor-Heuss-Straße 34 Stuttgart None Germany 70174 +49 0711 2842222 None leonekohler@surfeu.de 5
3 François Tremblay None 1498 rue Bélanger Montréal QC Canada H2G 1A7 +1 (514) 721-4711 None ftremblay@gmail.com 3
*/
CREATE TABLE invoice (
`InvoiceId` INTEGER NOT NULL,
`CustomerId` INTEGER NOT NULL,
`InvoiceDate` DATETIME NOT NULL,
`BillingAddress` VARCHAR(70) CHARACTER SET utf8mb3 COLLATE utf8mb3_general_ci,
`BillingCity` VARCHAR(40) CHARACTER SET utf8mb3 COLLATE utf8mb3_general_ci,
`BillingState` VARCHAR(40) CHARACTER SET utf8mb3 COLLATE utf8mb3_general_ci,
`BillingCountry` VARCHAR(40) CHARACTER SET utf8mb3 COLLATE utf8mb3_general_ci,
`BillingPostalCode` VARCHAR(10) CHARACTER SET utf8mb3 COLLATE utf8mb3_general_ci,
`Total` DECIMAL(10, 2) NOT NULL,
PRIMARY KEY (`InvoiceId`),
CONSTRAINT `FK_InvoiceCustomerId` FOREIGN KEY(`CustomerId`) REFERENCES customer (`CustomerId`)
)COLLATE utf8mb4_0900_ai_ci ENGINE=InnoDB DEFAULT CHARSET=utf8mb4
/*
3 rows from invoice table:
InvoiceId CustomerId InvoiceDate BillingAddress BillingCity BillingState BillingCountry BillingPostalCode Total
1 2 2021-01-01 00:00:00 Theodor-Heuss-Straße 34 Stuttgart None Germany 70174 1.98
2 4 2021-01-02 00:00:00 Ullevålsveien 14 Oslo None Norway 0171 3.96
3 8 2021-01-03 00:00:00 Grétrystraat 63 Brussels None Belgium 1000 5.94
*/
CREATE TABLE invoiceline (
`InvoiceLineId` INTEGER NOT NULL,
`InvoiceId` INTEGER NOT NULL,
`TrackId` INTEGER NOT NULL,
`UnitPrice` DECIMAL(10, 2) NOT NULL,
`Quantity` INTEGER NOT NULL,
PRIMARY KEY (`InvoiceLineId`),
CONSTRAINT `FK_InvoiceLineInvoiceId` FOREIGN KEY(`InvoiceId`) REFERENCES invoice (`InvoiceId`),
CONSTRAINT `FK_InvoiceLineTrackId` FOREIGN KEY(`TrackId`) REFERENCES track (`TrackId`)
)COLLATE utf8mb4_0900_ai_ci ENGINE=InnoDB DEFAULT CHARSET=utf8mb4
/*
3 rows from invoiceline table:
InvoiceLineId InvoiceId TrackId UnitPrice Quantity
1 1 2 0.99 1
2 1 4 0.99 1
3 2 6 0.99 1
*/
Invoking: `sql_db_query` with `{'query': 'SELECT c.Country, SUM(i.Total) AS TotalSales\nFROM customer c\nJOIN invoice i ON c.CustomerId = i.CustomerId\nGROUP BY c.Country\nORDER BY TotalSales DESC'}`
[('USA', Decimal('523.06')), ('Canada', Decimal('303.96')), ('France', Decimal('195.10')), ('Brazil', Decimal('190.10')), ('Germany', Decimal('156.48')), ('United Kingdom', Decimal('112.86')), ('Czech Republic', Decimal('90.24')), ('Portugal', Decimal('77.24')), ('India', Decimal('75.26')), ('Chile', Decimal('46.62')), ('Hungary', Decimal('45.62')), ('Ireland', Decimal('45.62')), ('Austria', Decimal('42.62')), ('Finland', Decimal('41.62')), ('Netherlands', Decimal('40.62')), ('Norway', Decimal('39.62')), ('Sweden', Decimal('38.62')), ('Belgium', Decimal('37.62')), ('Denmark', Decimal('37.62')), ('Italy', Decimal('37.62')), ('Poland', Decimal('37.62')), ('Spain', Decimal('37.62')), ('Australia', Decimal('37.62')), ('Argentina', Decimal('37.62'))]The total sales per country are as follows:
1. USA: $523.06
2. Canada: $303.96
3. France: $195.10
4. Brazil: $190.10
5. Germany: $156.48
The country whose customers spent the most is the USA with a total sales amount of $523.06.
> Finished chain.

通过RGA 处理高维列 、高维查询?
什么是高维列?
在数据处理和分析中,“高维列” 是一个相对的概念,通常是指数据集中具有较多列(特征)的情况。
当数据集的列数较多,比如几十列、上百列甚至更多时,就可以将其称为具有高维列。
这里的 “高维” 是相对于一些常见的、列数较少的简单数据集而言的。
例如
-
低维列:一个只包含姓名、年龄、性别三列的数据集是低维的
-
高维列:而一个包含了用户的各种行为数据、属性数据等几十列的数据集则可被认为是高维列数据集。
对于当前的例子来说, 为了过滤包含专有名词(如地址、歌曲名称或艺术家)的列,我们首先需要仔细检查拼写以便正确过滤数据。
什么是高维查询?
其实就是 类似语义搜索,把 关键词转换成 的高维向量, 用 向量的相似距离计算 去查询。
撸代码:通过RGA 处理高维列 、高维查询
如何通过RGA 处理高维列 、高维查询?
- 用数据库中所有不同的专用名词创建一个向量存储
- 每当用户在问题中包含专有名词时让agent查询向量存储,以找到该词的正确拼写。
通过这种方式,agent可以确保在构建目标查询之前了解用户所指的实体。
// 先用cpu版本 的 faiss 向量库,简单点
pip install faiss-cpu
代码如下
from langchain.utilities import SQLDatabase
from langchain_community.agent_toolkits import create_sql_agent
from langchain_openai import ChatOpenAI
import os
// 我们需要一些用户输入SQL查询示例:
examples = [
{"input": "List all artists.", "query": "SELECT * FROM Artist;"},
{
"input": "Find all albums for the artist 'AC/DC'.",
"query": "SELECT * FROM Album WHERE ArtistId = (SELECT ArtistId FROM Artist WHERE Name = 'AC/DC');",
},
{
"input": "List all tracks in the 'Rock' genre.",
"query": "SELECT * FROM Track WHERE GenreId = (SELECT GenreId FROM Genre WHERE Name = 'Rock');",
},
{
"input": "Find the total duration of all tracks.",
"query": "SELECT SUM(Milliseconds) FROM Track;",
},
{
"input": "List all customers from Canada.",
"query": "SELECT * FROM Customer WHERE Country = 'Canada';",
},
{
"input": "How many tracks are there in the album with ID 5?",
"query": "SELECT COUNT(*) FROM Track WHERE AlbumId = 5;",
},
{
"input": "Find the total number of invoices.",
"query": "SELECT COUNT(*) FROM Invoice;",
},
{
"input": "List all tracks that are longer than 5 minutes.",
"query": "SELECT * FROM Track WHERE Milliseconds > 300000;",
},
{
"input": "Who are the top 5 customers by total purchase?",
"query": "SELECT CustomerId, SUM(Total) AS TotalPurchase FROM Invoice GROUP BY CustomerId ORDER BY TotalPurchase DESC LIMIT 5;",
},
{
"input": "Which albums are from the year 2000?",
"query": "SELECT * FROM Album WHERE strftime('%Y', ReleaseDate) = '2000';",
},
{
"input": "How many employees are there",
"query": 'SELECT COUNT(*) FROM "Employee"',
},
]
os.environ["OPENAI_API_KEY"] = "sk-your open ai key"
db = SQLDatabase.from_uri("mysql+mysqlconnector://root:123456@localhost:3306/chinook")
llm = ChatOpenAI(model="gpt-3.5-turbo", temperature=0)
// 需要每个实体的唯一值,为此我们定义一个函数将结果解析为元素列表
import ast
import re
// 定义数据库查询结果处理函数
def query_as_list(db, query):
res = db.run(query)
res = [el for sub in ast.literal_eval(res) for el in sub if el]
res = [re.sub(r"\b\d+\b", "", string).strip() for string in res]
return list(set(res))
artists = query_as_list(db, "SELECT Name FROM Artist")
albums = query_as_list(db, "SELECT Title FROM Album")
albums[:5]
from langchain_community.vectorstores import FAISS
from langchain_core.example_selectors import SemanticSimilarityExampleSelector
from langchain_openai import OpenAIEmbeddings
//我们可以创建example selector。
//这里将采用实际的用户输入,并选择一些示例添加到few-shot prompt中。
//使用SemanticSimilarityExampleSelector基于配置的embedding和向量存储执行语义搜索,以找到与输入最相似的示例:
// ==================== 语义相似性示例选择器配置 ====================
// 创建基于语义的示例选择器,用于动态选择与用户问题最相关的few-shot示例
example_selector = SemanticSimilarityExampleSelector.from_examples(
examples, // 预定义的示例数据集,格式应为[{"input": "问题1", "query": "SQL1"}, ...]
OpenAIEmbeddings(), // 使用OpenAI的文本嵌入模型计算语义相似度
FAISS, // 采用Meta的FAISS向量数据库进行高效相似性搜索
k=5, // 每次选择与用户输入最相似的前5个示例
input_keys=["input"], // 指定使用示例中的input字段进行相似度匹配
)
// 导入提示模板组件
from langchain_core.prompts import (
ChatPromptTemplate,
FewShotPromptTemplate,
MessagesPlaceholder,
PromptTemplate,
SystemMessagePromptTemplate,
)
//后面 创建FewShotPromptTemplate,它的参数包括example selector、用于格式化每个示例的example prompt,以及放在格式化示例前后的字符串前缀和后缀
// Prompt的内容如下,由系统指令、few-shot示例和用户query组成:
system_prefix = """You are an agent designed to interact with a SQL database.
Given an input question, create a syntactically correct {dialect} query to run, then look at the results of the query and return the answer.
Unless the user specifies a specific number of examples they wish to obtain, always limit your query to at most {top_k} results.
You can order the results by a relevant column to return the most interesting examples in the database.
Never query for all the columns from a specific table, only ask for the relevant columns given the question.
You have access to tools for interacting with the database.
Only use the given tools. Only use the information returned by the tools to construct your final answer.
You MUST double check your query before executing it. If you get an error while executing a query, rewrite the query and try again.
DO NOT make any DML statements (INSERT, UPDATE, DELETE, DROP etc.) to the database.
If the question does not seem related to the database, just return "I don't know" as the answer.
Here are some examples of user inputs and their corresponding SQL queries:"""
system = """You are an agent designed to interact with a SQL database.
Given an input question, create a syntactically correct {dialect} query to run, then look at the results of the query and return the answer.
Unless the user specifies a specific number of examples they wish to obtain, always limit your query to at most {top_k} results.
You can order the results by a relevant column to return the most interesting examples in the database.
Never query for all the columns from a specific table, only ask for the relevant columns given the question.
You have access to tools for interacting with the database.
Only use the given tools. Only use the information returned by the tools to construct your final answer.
You MUST double check your query before executing it. If you get an error while executing a query, rewrite the query and try again.
DO NOT make any DML statements (INSERT, UPDATE, DELETE, DROP etc.) to the database.
If you need to filter on a proper noun, you must ALWAYS first look up the filter value using the "search_proper_nouns" tool!
You have access to the following tables: {table_names}
If the question does not seem related to the database, just return "I don't know" as the answer."""
// 构建few-shot提示模板
few_shot_prompt = FewShotPromptTemplate(
example_selector=example_selector, // 连接示例选择器
example_prompt=PromptTemplate.from_template(
"User input: {input}\nSQL query: {query}" // 单个示例的展示格式
),
input_variables=["input", "dialect", "top_k"], // 动态变量:用户输入、数据库方言、结果数量限制
prefix=system_prefix, // 系统级指令前缀,包含基本行为准则
suffix="", // 后缀留空,保持提示结构简洁
)
// ==================== 完整对话提示整合 ====================
// 底层代理是OpenAI tools agent,
// 它使用OpenAI function calling
// 因此完整的prompt应该是带有human message template 和 agent_scratchpad MessagesPlaceholder的 chat prompt。
// few-shot prompt将用于system message
// 构建符合OpenAI工具代理要求的对话提示模板
full_prompt = ChatPromptTemplate.from_messages([
SystemMessagePromptTemplate(prompt=few_shot_prompt), // 将few-shot提示包装为系统消息
("human", "{input}"), // 用户原始输入占位符
MessagesPlaceholder("agent_scratchpad"), // 保留代理思考过程的暂存空间
])
// 测试提示模板生成效果
prompt_val = full_prompt.invoke({
"input": "How many arists are there", // 包含拼写错误的测试问题(artists拼错为arists)
"top_k": 5, // 结果数量上限
"dialect": "SQLite", // 指定数据库方言
"agent_scratchpad": [], // 初始化时思考记录为空
})
// ==================== 自定义实体检索工具 ====================
// 创建自定义检索器工具和最终agent:
from langchain.agents.agent_toolkits import create_retriever_tool
// 创建实体验证检索器
vector_db = FAISS.from_texts(
artists + albums, // 合并艺术家和专辑名称作为检索范围
OpenAIEmbeddings() // 使用相同嵌入模型保证语义一致性
)
retriever = vector_db.as_retriever(
search_kwargs={"k": 5} // 返回最相似的5个候选实体
)
// 工具描述(关键功能说明)
retriever_description = """
实体验证工具:用于确认用户提到的专有名词是否存在于数据库中
输入:可能包含拼写错误的实体名称(如"alis chain")
输出:最接近的有效实体列表(如匹配到"Alice In Chains")
使用场景:在生成SQL查询前验证过滤条件中的实体有效性
"""
// 将检索器封装为Agent可用工具
retriever_tool = create_retriever_tool(
retriever,
name="search_proper_nouns", // 工具名称(需与代理提示中的工具调用匹配)
description=retriever_description // 自然语言描述,供LLM理解工具用途
)
// ==================== 最终代理创建 ====================
// 配置完整的对话提示模板(集成系统指令和工具调用)
final_prompt = ChatPromptTemplate.from_messages([
("system", system_prefix), // 系统级行为准则
("human", "{input}"), // 用户问题输入
MessagesPlaceholder("agent_scratchpad") // 工具调用记录暂存区
])
// 创建支持工具调用的SQL代理
sql_agent = create_sql_agent(
llm=llm, // 预初始化的ChatGPT-3.5模型
db=db, // SQLDatabase数据库连接对象
extra_tools=[retriever_tool], // 注入实体验证工具
prompt=final_prompt, // 集成了few-shot示例的提示模板
agent_type="openai-tools", // 使用OpenAI函数调用格式
verbose=True, // 启用详细日志输出(显示思考过程)
)
// ==================== 代理执行示例 ====================
// 典型错误查询场景测试(包含拼写错误alis和错误分词)
agent_response = sql_agent.invoke({
"input": "How many albums does alis in chain have?" // 正确应为"Alice In Chains"
})
运行结果:
G:\lession\AI2\demo\demo_16\example\text2sql05.py:1: LangChainDeprecationWarning: Importing SQLDatabase from langchain.utilities is deprecated. Please replace deprecated imports:
>> from langchain.utilities import SQLDatabase
with new imports of:
>> from langchain_community.utilities import SQLDatabase
You can use the langchain cli to **automatically** upgrade many imports. Please see documentation here <https://python.langchain.com/docs/versions/v0_2/>
from langchain.utilities import SQLDatabase
> Entering new SQL Agent Executor chain...
Invoking: `search_proper_nouns` with `{'query': 'alis in chain'}`
Alice In Chains
Aisha Duo
Xis
Da Lama Ao Caos
A-Sides
Invoking: `sql_db_query` with `{'query': "SELECT COUNT(*) AS album_count FROM album WHERE artistid = (SELECT artistid FROM artist WHERE name = 'Alice In Chains')"}`
[(1,)]Alice In Chains has 1 album.
看起来结果不错,但是真的就那么简单么?
query_as_list 函数介绍:
执行数据库查询并处理结果,返回去重后的清理数据列表
def query_as_list(db, query):
"""执行数据库查询并处理结果,返回去重后的清理数据列表
参数:
db: 数据库连接对象,需具有run()方法执行查询
query: 要执行的SQL查询语句
返回:
list: 去重后的非空字符串列表,已移除纯数字内容
处理流程:
1. 执行查询获取原始结果
2. 将字符串结果转换为二维列表结构
3. 扁平化处理并过滤空值
4. 清理字符串中的数字内容
5. 去重后返回最终结果
"""
// 执行数据库查询,获取原始结果(通常为字符串格式)
// 假设返回格式为字符串表示的二维列表,例如:"[[值1, 值2], [值3], ...]"
res = db.run(query)
// 将字符串解析为Python列表结构(安全解析)
// 示例转换:"[[A, 1], [B], []]" → [['A', 1], ['B'], []]
// 使用嵌套列表推导式展开为扁平列表,同时过滤空元素
// 转换后示例:['A', 1, 'B']
res = [el for sub in ast.literal_eval(res) for el in sub if el]
// 清理每个字符串:
// 1. 使用正则替换移除纯数字(\b表示单词边界,匹配单独的数字)
// 2. 移除清理后可能产生的空字符串并去除两端空白
// 示例转换:'A1' → 'A', '123' → '', ' B ' → 'B'
res = [re.sub(r"\b\d+\b", "", string).strip() for string in res]
// 使用集合去重后转回列表(会丢失原始顺序)
// 示例最终结果:['A', 'B']
return list(set(res))
Text2SQL 难点与挑战
挑战1:当前AI模型输出SQL的准确性
当前AI模型输出SQL的准确性还远无法达到人类工程师的输出精度。
挑战2:自然语言表达本身的歧义性
自然语言表达本身的歧义性,而SQL是一种精确编程语言。
因此在实际应用中,可能会出现无法理解,或者错误理解的情况。
比如,“谁是这个月最厉害的销售”,那么AI是理解成订单数量最多,还是订单金额最大?
挑战3:缺乏外部行业知识导致错误
尽管可以通过Prompt输入数据结构信息帮助AI模型来理解,但有时候AI可能会由于缺乏外部行业知识导致错误。
比如,“分析去年的整体客户流失率?”,如果AI缺乏对“客户流失率”的理解,自然就会出错或者编造。
NL2SQL的方案在企业应用中还会面临两个严重的挑战:
1、可能会出现正常运行的“假象”
即正常完成了任务,但实际结果是错误的。
由于NL2SQL是直接输出用于数据库访问的语句,理论上只要不存在基本的语法错误,就可以执行成功,即使转换的SQL在语义上是错误的!
NL2SQL输出语义准确性衡量的复杂性本质上来自于这样一个事实:判断AI输出的一段代码是否正确,要比判断一个选择题答案是否正确,或者一段字符串的相似度要复杂的多。
评估NL2SQL模型输出正确性的复杂所在:你既不能用输出SQL的执行结果来判断,也不能简单的把输出SQL与标准答案对比来判断。
简单来说,就是你平时自己写的代码,看起来能跑,但是实际上和需求不一致
2、 企业应用的特点会加大错误输出的概率
数据量更大
语义复杂,容易理解错误
Text2SQL 未来的优化方向
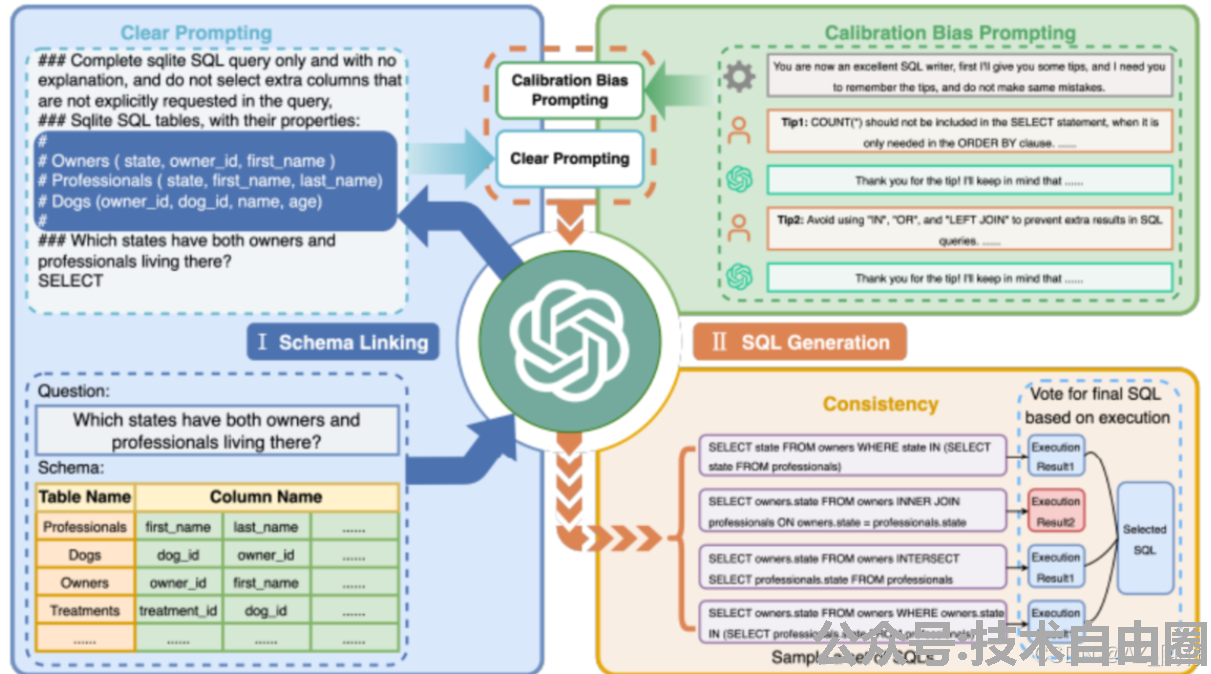
在传统的text2SQL的提示中通过注入一些相似的样例,利用LLM的上下文学习能力,以提高输出SQL的精度
- Clear Prompting:
通过对Prompt提供更清晰的层次,并只嵌入必要的数据结构信息,来优化提示。
一个重要的思想是,在构建Prompt之前,先通过大语言模型来分析本次输入最可能相关的数据实体(table)及其列(column)信息,即仅召回本次最可能用到的table和column,然后组装到Prompt,而不是把整个数据库的结构全部组装进入。
- Claibration Bias Prompting:
通过在上下文信息中嵌入一些偏差提示,可以简单的理解为指示大模型在一些场景下需要遵循的一些规则或者“注意点”。
- Consistent Output:
这是一种输出处理方式,也是解决大模型输出不确定性的一种方案。
可以解释为:让大模型输出多次SQL,然后根据输出的SQL执行结果进行“投票。
比如让LLM输出四次SQL,其中三个的执行结果都是一致的,另一个结果不一致,那么就认为这三次的输出是正确的,类似Agent的做法。
目前可选的text2sql开源框架
市面上开原框架比较多,但是看起来鱼龙混杂,要么文档烂,要么社区支持更新的慢,
这里 推荐 vanna
https://github.com/vanna-ai/vanna?tab=readme-ov-file
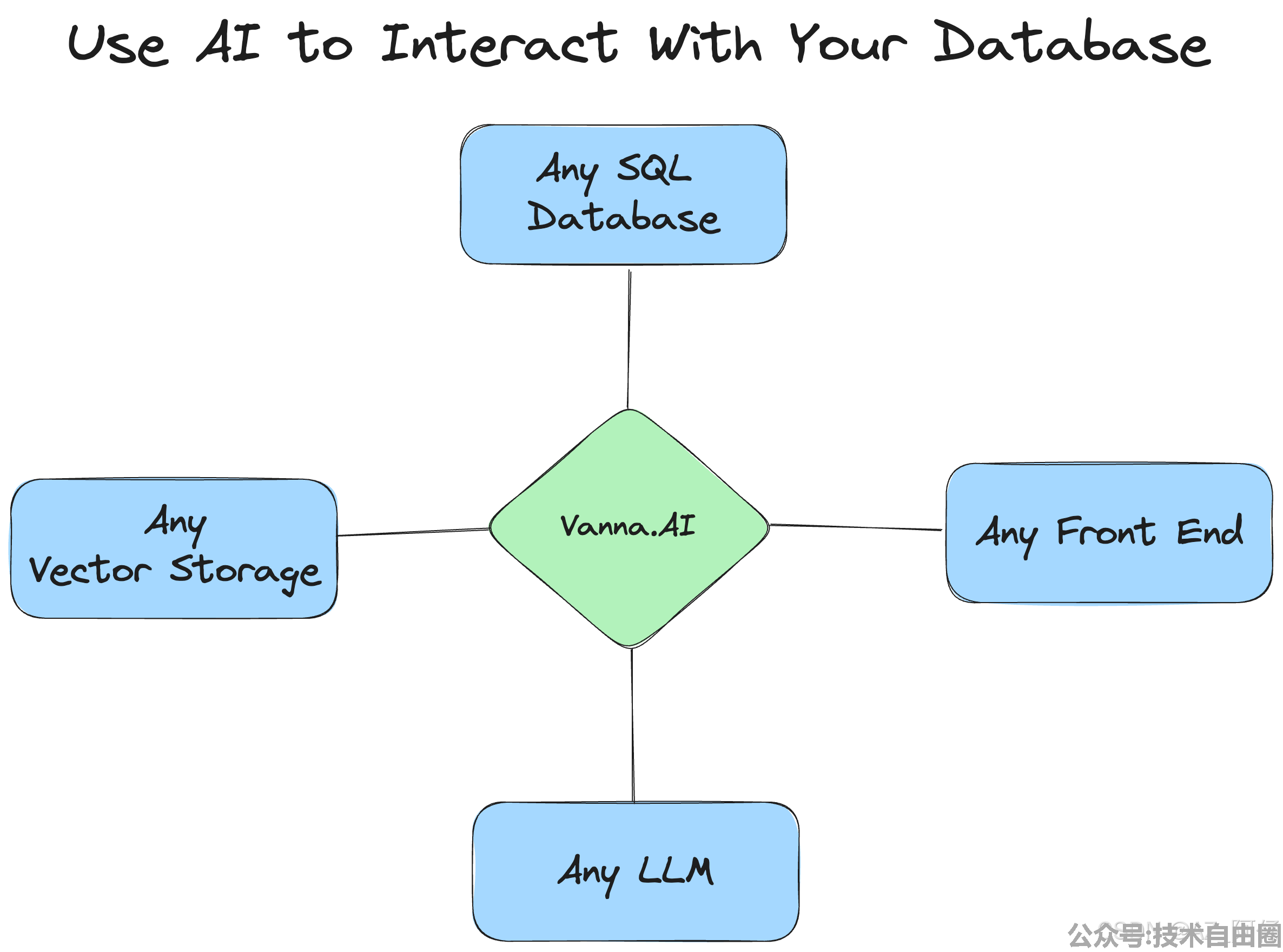
目前14.4k star,数量比较大,readme写的比较有高级感,原理图示清晰,介绍视频一目了然
vanna可以结合多种关系型数据库,非关系型数据库、向量数据库,支持多种多模型和前端
vanna工作示意图也是一目了然
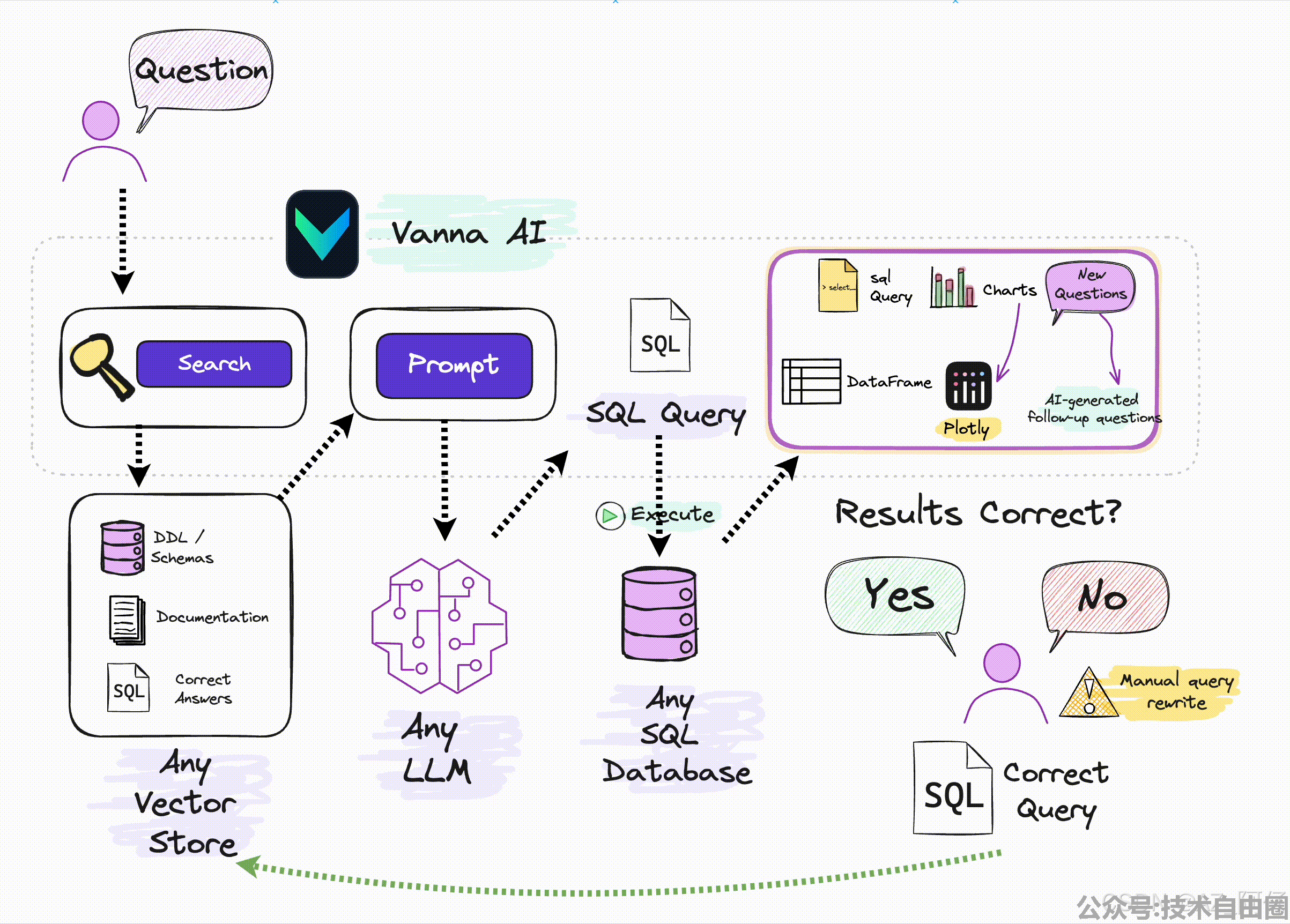
整个流程,和上边我们手撸的感觉是不是比较类似
Vanna 通过两个简单的步骤工作 —— 在数据上训练一个 RAG “模型”,然后提出问题,这些问题将返回 SQL 查询,这些查询可以设置为在您的数据库上自动运行。
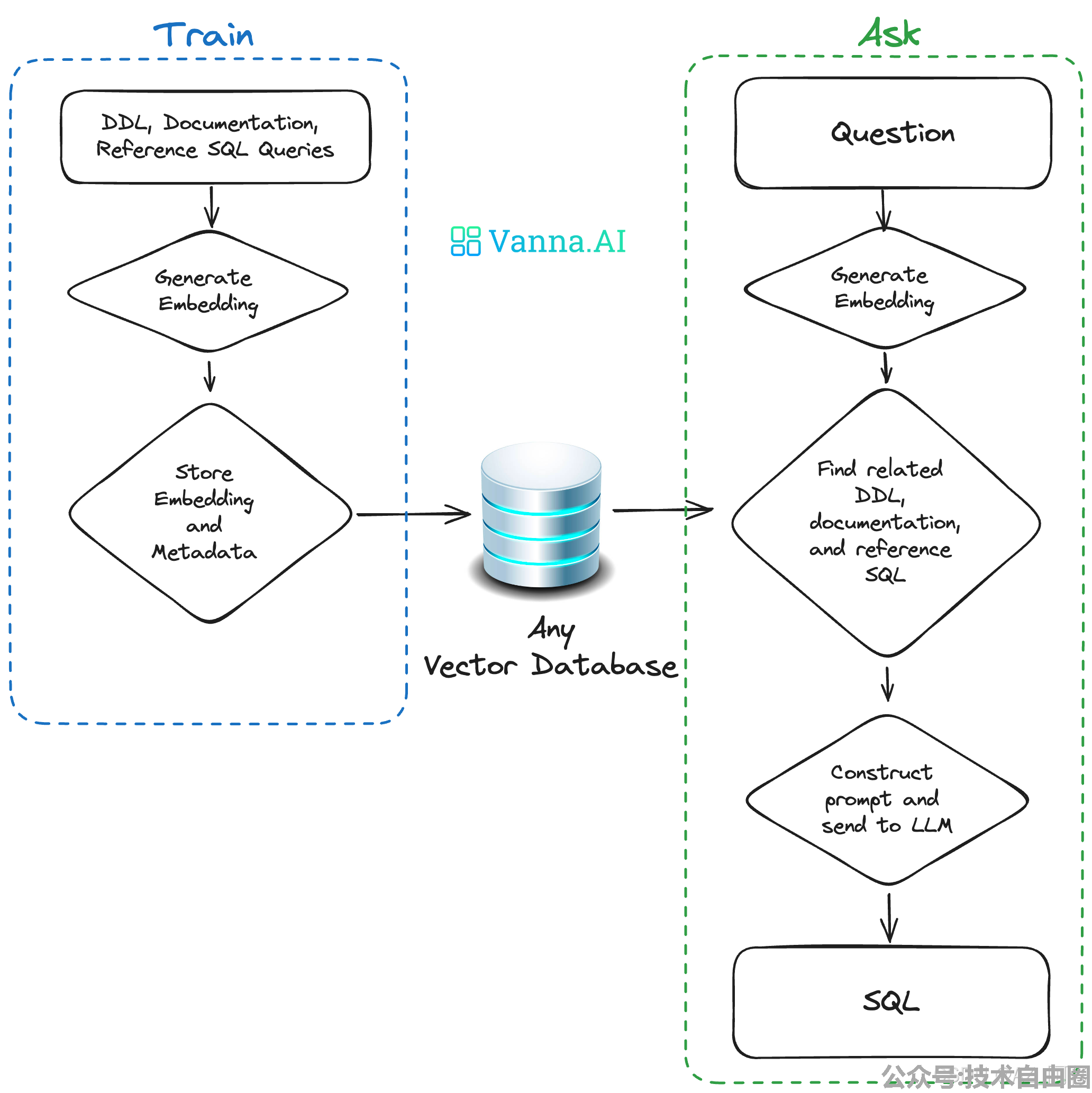
如果不知道RAG是什么,也不需要担心 。
只需要有这样的思路:“训练”了一个模型,该模型存储了一些元数据,然后使用它来“问”问题。
剩下的细节vanna都屏蔽掉了。
vanna编程接口
这里看到可以使用 jupyter notebook,那么也是挺轻量级了,存在 vanna-streamlit 就可以容易搭建web ui
vanna-flask 方便做后端应用开发,可以打包成微服务。。。
vanna支持的大模型
官网给出支持的大模型比较丰富
居然连Zhipu也支持。。。 https://zhipuai.cn/
vanna支持的数据库
相当丰富,关系型非关系型大数据都支持了
vanna安装
pip install vanna
vanna简单的例子
对于数据来说,我们仍旧使用 chinook
对于vanna来说,我们需要创建一个账号(其实这一步你甚至也可以跳过,但是申请了之后可以得到一个api key,有备无患)
搞AI,魔法和google账号是必需品,可以直接sign in,注册就不说了,该填啥就填啥

保存好这个key,因为只会显示一次,如果实在忘记了,就只才能重新创建一个
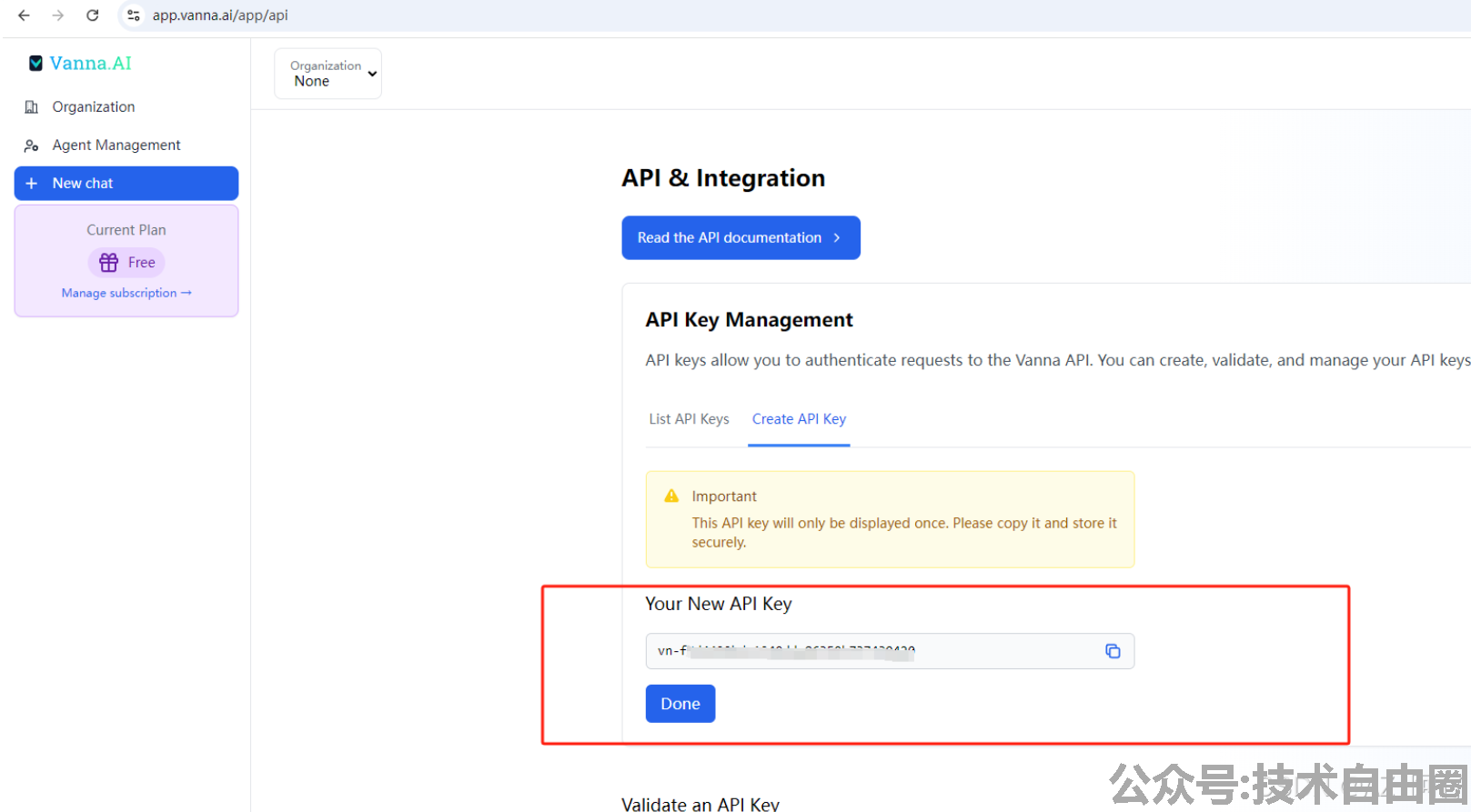
可以先来一个简单例子
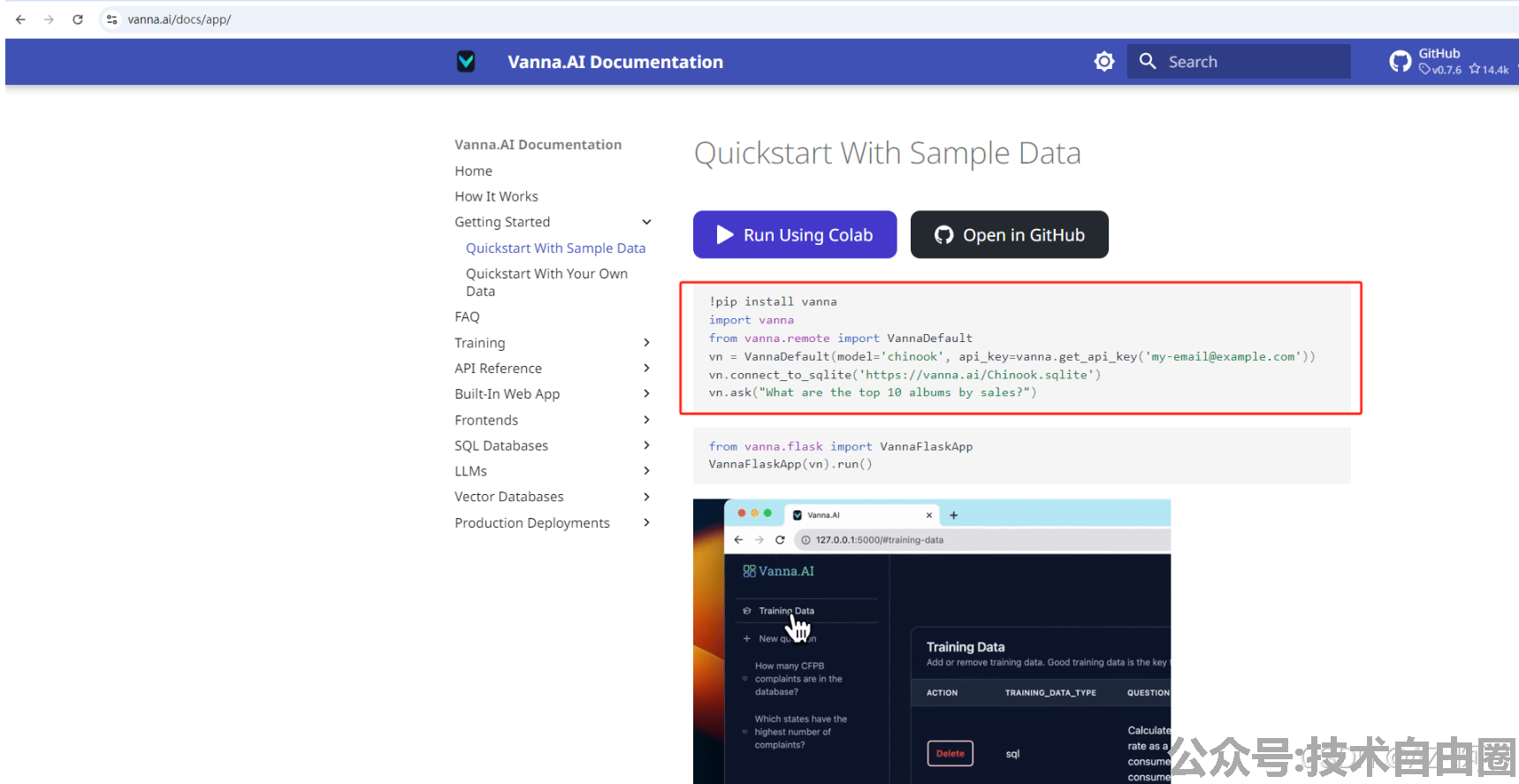
https://vanna.ai/docs/mysql-openai-standard-chromadb/
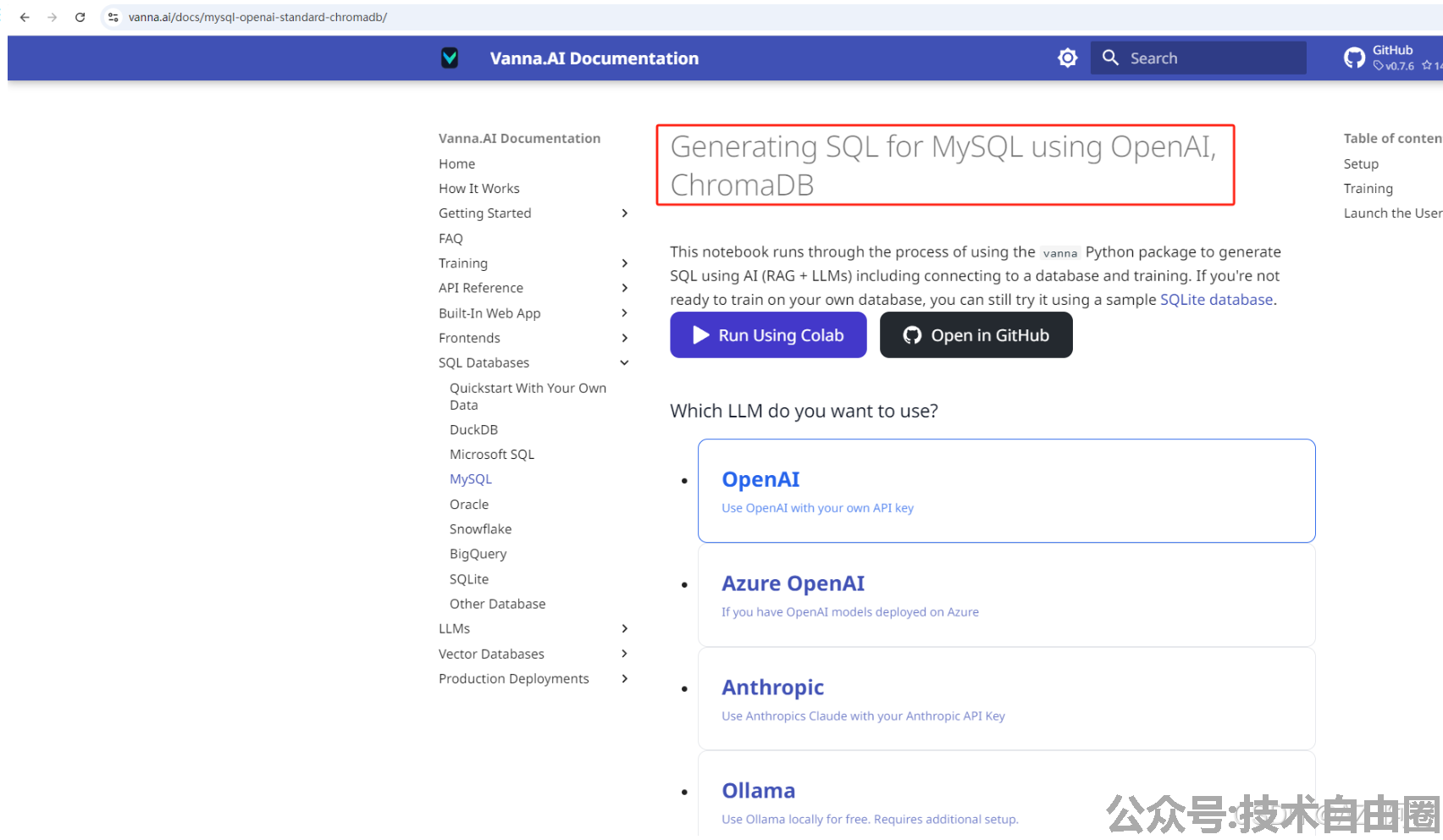
点点点就可以step by step的进行操作,最后得到一个可执行的代码,具体代码含义请参考 注释
from vanna.openai import OpenAI_Chat
from vanna.chromadb import ChromaDB_VectorStore
import os
class MyVanna(ChromaDB_VectorStore, OpenAI_Chat):
def __init__(self, config=None):
ChromaDB_VectorStore.__init__(self, config=config)
OpenAI_Chat.__init__(self, config=config)
os.environ["OPENAI_API_KEY"] = "sk-proj-your open ai key"
vn = MyVanna(config={'api_key': 'sk-proj-your open ai key', 'model': 'gpt-3.5-turbo'})
// 连接本地数据库
vn.connect_to_mysql(host='localhost', dbname='chinook', user='root', password='123456', port=3306)
// 把数据库的 FROM INFORMATION_SCHEMA.COLUMNS 告诉vanna
df_information_schema = vn.run_sql("SELECT * FROM INFORMATION_SCHEMA.COLUMNS")
// 这将把信息模式分解成便于处理的小部分,这些小部分可供大语言模型(LLM)引用。
plan = vn.get_training_plan_generic(df_information_schema)
plan
// 告诉vn这些作为训练内容,这里的粗浅理解为RAG,train得越多,结果一般就约接近你的要求
vn.train(plan=plan)
// The following are methods for adding training data. Make sure you modify the examples to match your database.
// 可以使用sql得到数据,再给到vanna
vn.train(ddl="""
SELECT * FROM customer
""")
// 描述数据库的业务逻辑, 这里的提示词可以通过上边数据库翻转模型的描述,将中文描述扔到豆包里边,让豆包帮你生成提示词
vn.train(documentation="The Chinook database is a sample database of great significance as an alternative, which can serve as a substitute for the NorthWind database. It is mainly applied in scenarios related to representing digital media stores. This database encompasses a wealth of content, including 11 tables. These tables record relevant data such as artists, albums, media tracks, invoices, and customers. Based on this information, think deeply about the application and value of the Chinook database in the field of digital media stores.")
// 获取数据
training_data = vn.get_training_data()
training_data
// You can remove training data if there's obsolete/incorrect information.
vn.remove_training_data(id='1-ddl')
// 使用 flask 得到一个网页
from vanna.flask import VannaFlaskApp
app = VannaFlaskApp(vn)
app.run()
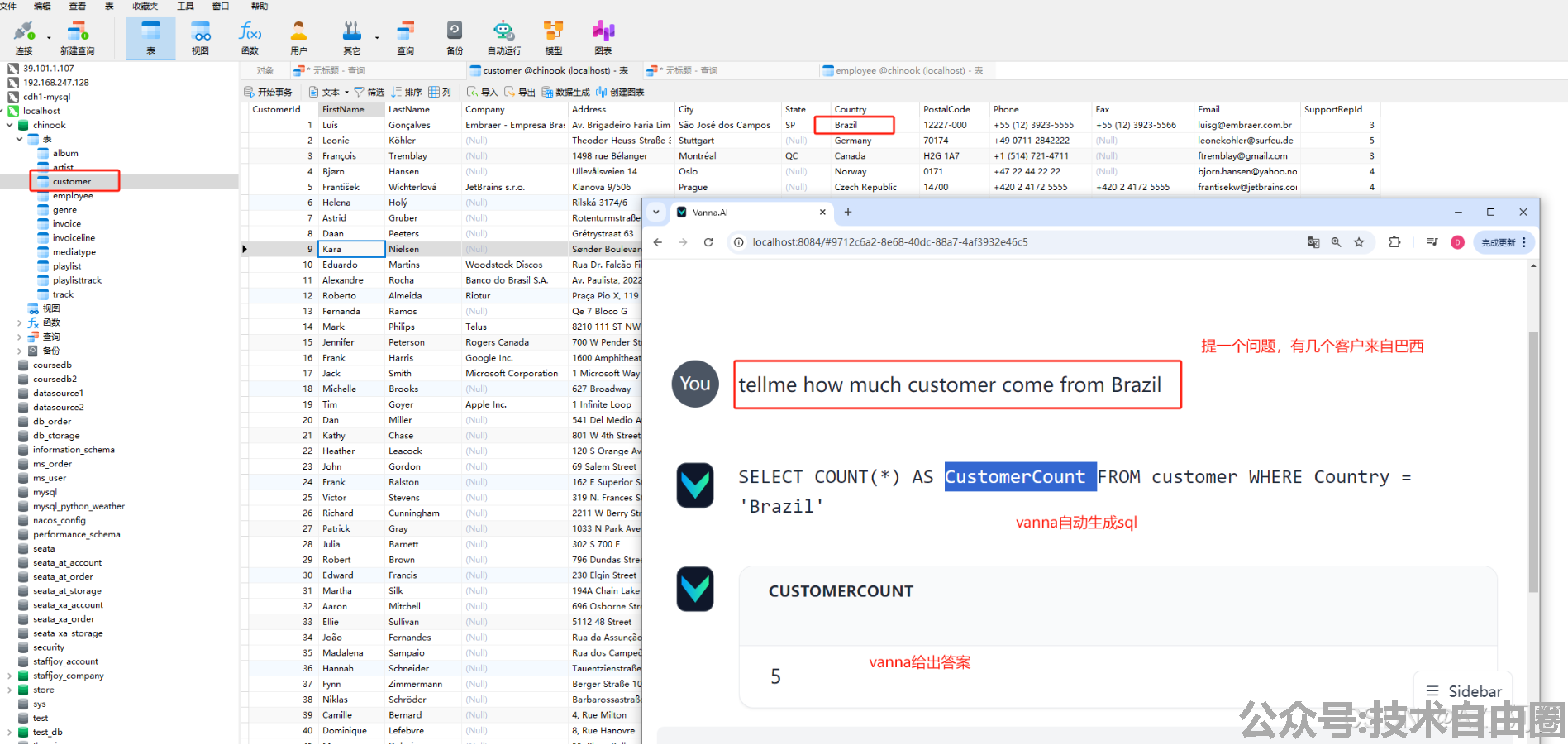
总结一下 text2SQL
所需要的能力与技术和RAG,Promot这块关系比较紧密
用到的核心是 zero-shot ,属于零样本学习,零样本学习旨在让模型在没有见过特定任务的训练样本的情况下,能够完成对该任务的学习和推理。
也就是说,模型需要利用已有的知识和经验,来理解和处理从未遇到过的新情况或新类别,它也面临着一些挑战,
比如对新类别信息的理解和表示可能不够准确,容易受到数据偏差和噪声的影响,以及在复杂任务中性能可能不如有监督学习等。
遇到问题,找老架构师取经
借助此文,尼恩给解密了一个高薪的 秘诀,大家可以 放手一试。保证 屡试不爽,涨薪 100%-200%。
后面,尼恩java面试宝典回录成视频, 给大家打造一套进大厂的塔尖视频。
通过这个问题的深度回答,可以充分展示一下大家雄厚的 “技术肌肉”,让面试官爱到 “不能自已、口水直流”,然后实现”offer直提”。
在面试之前,建议大家系统化的刷一波 5000页《尼恩Java面试宝典PDF》,里边有大量的大厂真题、面试难题、架构难题。
很多小伙伴刷完后, 吊打面试官, 大厂横着走。
在刷题过程中,如果有啥问题,大家可以来 找 40岁老架构师尼恩交流。
另外,如果没有面试机会,可以找尼恩来改简历、做帮扶。
遇到职业难题,找老架构取经, 可以省去太多的折腾,省去太多的弯路。
尼恩指导了大量的小伙伴上岸,前段时间,刚指导一个40岁+被裁小伙伴,拿到了一个年薪100W的offer。
狠狠卷,实现 “offer自由” 很容易的, 前段时间一个武汉的跟着尼恩卷了2年的小伙伴, 在极度严寒/痛苦被裁的环境下, offer拿到手软, 实现真正的 “offer自由” 。

















 9万+
9万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









