







怎样注册谷歌账号?最近一段时间,有许多朋友反应到他们的谷歌账户登录出现了问题。
尽管他们很清楚自己的账号和密码,却仍然无法正常登录,这严重影响了他们的工作进度,让他们感到非常焦虑。因此,我特地创建了这个谷歌账户登录问题的解决指南。希望这可以为大家带来帮助!
谷歌账号登录异常怎么解决?
解决谷歌账户登录问题,有以下几种方法:
1、可能您更换了手机号码、登录位置发生改变或者登陆次数过多,导致谷歌为了保护您的安全锁定了您的账号。此时,可以尝试更换代理网络、改善IP伪装,或者尝试租用一个海外手机号码来接收验证码。
2、如果无法验证您的Google账户,可能是因为网络地址不够干净,伪装程度不足,或者同一个手机号码已经验证过其他谷歌账户或者已经绑定了过多的辅助号码。
3、如果账户无法登录,可能是因为谷歌检测到使用了假IP登录,或者使用免费工具频繁改变IP地址。另一种可能就是该账户同时登录了很多设备或者用于登录多个区域,造成该账户没有固定的IP和设备可以登录。还可能是因为发送垃圾邮件、进行产品评论或发送小广告等,违反了谷歌的政策。
4、如果Google无法验证您的身份,那么您将无法登录您的账户。要解决这个问题,需要尽可能提供尽可能多的关于账户的信息。
怎样注册谷歌账号?在使用谷歌账户的过程中,我希望各位注意以下几点:
首先,建议开启账户的两步验证。
其次,应选择一个比较稳定的代理,并避免使用免费的工具,因为他们的网络不稳定且频繁更换路线和地区,可能会引起谷歌的注意。
如果条件允许,建议尝试自建代理服务器。更换代理时也不要过于频繁,需要登出账户后每隔半小时再切换一次。
不要发送垃圾邮件或者发布不适当的评论,每个月至少登录一次账户,避免长时间不用。
尽量减少切换设备的频率,避免在公共设备上使用账户。
接下来我们来看具体操作教程。
- 首先在出现登录问题时,我们看一下这个页面:
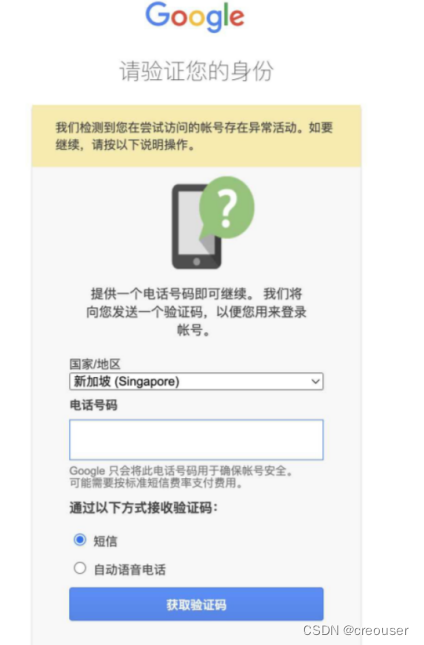
这个问题的解决方案很简单,只需要输入手机号码接收验证码即可。中国的手机号码也可以使用,但是要注意以下几点:
●如果要验证手机号码,必须确保在过去的15天内,没有在谷歌上注册过相同的号码!
●如果账户出现异常活动,有四次验证的机会。如果超过四次,将需要等待24小时后再验证。
●为了更顺利通过验证,建议使用人数较少的IP地址登录,并在登录前清除浏览器的缓存。
- 在选择国家或地区时,只需要输入手机号码,不需要进行选择。下面的图片是用中国的手机号码,要记得输入国家代码“+86”,外国手机号码同理。
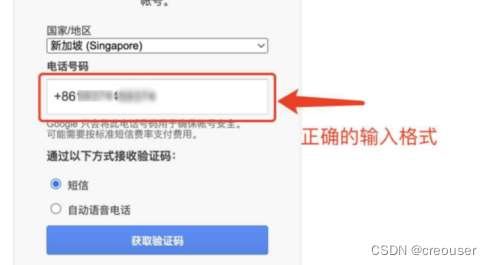
3、接收到验证码后,只需要输入验证码的6位数字,前面的"G-"不需要输入。
总结:
怎样注册谷歌账号?如果谷歌浏览器无法登录账号,不要紧张,冷静分析!我给出的建议是可以行得通的,关键在于要注意每一步的细节。只需按照步骤进行,耐心操作,你就能解决谷歌浏览器登录问题了!


















 914
914

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









