







1. Transformer的原理。
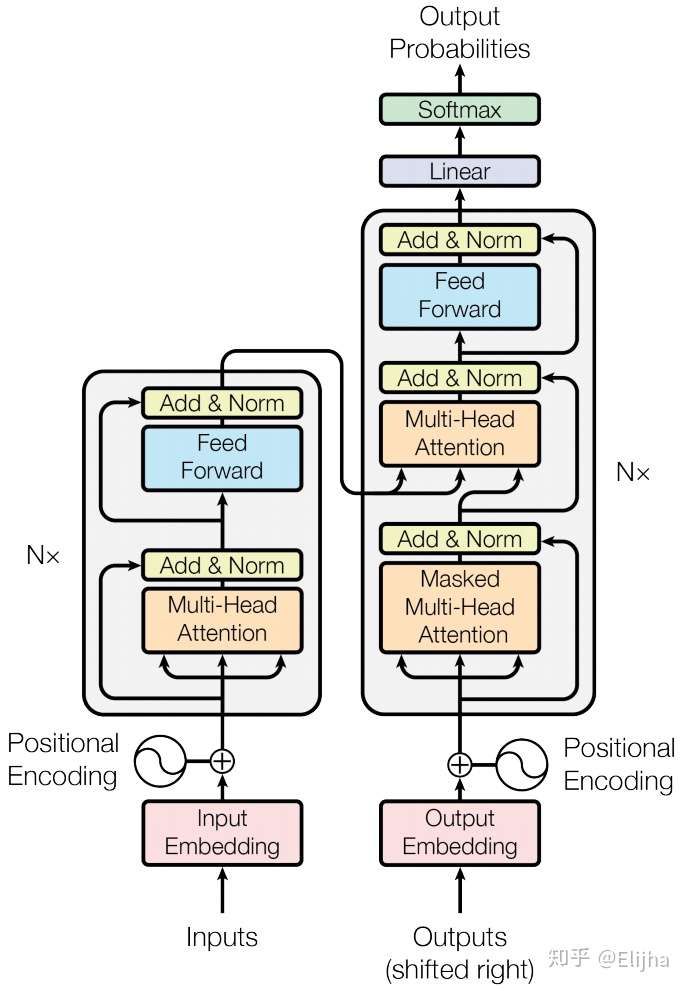
Transformer 是Seq2Seq的升级版,以前Seq2Seq encoder和decoder都是有CNN模型或者LSTM模型组成,现在就把这些模型替换成多个attention
2. BERT的原理。

2.1.采取新的预训练的目标函数:the “masked language model” (MLM) 随机mask输入中的一些tokens,然后在预训练中对它们进行预测。这样做的好处是学习到的表征能够融合两个方向上的context。这个做法我觉得非常像skip-gram。过去的同类算法在这里有所欠缺,比如上文提到的ELMo,它用的是两个单向的LSTM然后把结果拼接起来;还有OpenAI GPT,虽然它一样使用了transformer,但是只利用了一个方向的注意力机制,本质上也一样是单项的语言模型。
2.2.增加句子级别的任务:“next sentence prediction”
作者认为很多NLP任务比如QA和NLI都需要对两个句子之间关系的理解,而语言模型不能很好的直接产生这种理解。为了理解句子关系,作者同时pre-train了一个“next sentence prediction”任务。具体做法是随机替换一些句子,然后利用上一句进行IsNext/NotNext的预测。
3. 利用预训练的BERT模型将句子转换为句向量,进行文本分类。
export BERT_BASE_DIR=/path/to/bert/uncased_L-12_H-768_A-12 export GLUE_DIR=/path/to/glue python run_classifier.py \ --task_name=MRPC \ --do_train=true \ --do_eval=true \ --data_dir=$GLUE_DIR/MRPC \ --vocab_file=$BERT_BASE_DIR/vocab.txt \ --bert_config_file=$BERT_BASE_DIR/bert_config.json \ --init_checkpoint=$BERT_BASE_DIR/bert_model.ckpt \ --max_seq_length=128 \ --train_batch_size=32 \ --learning_rate=2e-5 \ --num_train_epochs=3.0 \ --output_dir=/tmp/mrpc_output/















 524
524











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









