






目录
一、引言
(一)强化学习的发展背景
强化学习(Reinforcement Learning, RL)是机器学习的一个重要分支,它通过让智能体(Agent)在环境中进行试错学习,以最大化累积奖励。近年来,强化学习在许多领域取得了显著的成果,如游戏、机器人控制和自动驾驶等。随着大语言模型(LLMs)的兴起,强化学习也被引入到语言模型的优化中,以提升模型的决策能力和生成质量。
(二)强化学习在大语言模型中的应用
大语言模型虽然在自然语言处理任务中表现出色,但在某些复杂任务中,如需要长期规划或动态决策的任务,其性能仍有待提升。强化学习通过引入奖励机制,可以让语言模型在生成文本或做出决策时更加灵活和高效。例如,在智能写作助手、自动化决策系统和游戏等场景中,强化学习可以帮助模型更好地适应动态环境。
二、强化学习的基本概念
(一)强化学习的定义
强化学习是一种通过试错学习来最大化累积奖励的学习方法。智能体在环境中采取行动,根据环境的反馈(奖励)来调整其策略,以达到最优的行为模式。
(二)强化学习的关键组件
-
智能体(Agent):学习和决策的主体。
-
环境(Environment):智能体所处的外部环境,提供反馈和奖励。
-
状态(State):智能体在环境中的当前情况。
-
动作(Action):智能体在环境中可以采取的行为。
-
奖励(Reward):环境对智能体行为的反馈,用于指导智能体的学习。
-
策略(Policy):智能体选择动作的规则。
-
价值函数(Value Function):评估状态或动作的长期价值。
三、强化学习在大语言模型中的应用
(一)优化文本生成
通过强化学习,可以优化语言模型的文本生成能力,使其生成的文本更符合人类的写作风格和逻辑。
(二)提升模型决策能力
在需要动态决策的任务中,强化学习可以帮助语言模型更好地评估不同选择的后果,从而做出更优的决策。
四、强化学习优化技术的实现方法
(一)环境设计
环境设计是强化学习的关键步骤之一。需要定义清晰的状态、动作和奖励机制,以引导模型的学习。
(二)策略网络与价值网络
策略网络用于选择动作,价值网络用于评估状态或动作的价值。在强化学习中,策略网络和价值网络通常通过神经网络实现。
(三)训练过程
训练过程中,智能体通过与环境的交互,不断调整策略,以最大化累积奖励。
五、代码示例
(一)环境与代理的实现
以下是一个基于Python的强化学习环境和代理的实现代码示例:
import numpy as np
class Environment:
def __init__(self):
self.state = np.random.randint(0, 2, size=(4, 4))
def reset(self):
self.state = np.random.randint(0, 2, size=(4, 4))
return self.state
def step(self, action):
reward = 0
done = False
if action == 0:
self.state = np.roll(self.state, 1, axis=0)
elif action == 1:
self.state = np.roll(self.state, -1, axis=0)
elif action == 2:
self.state = np.roll(self.state, 1, axis=1)
elif action == 3:
self.state = np.roll(self.state, -1, axis=1)
if np.sum(self.state) == 0:
reward = 1
done = True
return self.state, reward, done
class Agent:
def __init__(self):
self.policy = np.random.rand(4, 4, 4)
def choose_action(self, state):
return np.argmax(self.policy[state[0], state[1]])
def update_policy(self, state, action, reward):
self.policy[state[0], state[1], action] += reward(二)强化学习训练
以下是一个基于Python的强化学习训练代码示例:
env = Environment()
agent = Agent()
for episode in range(100):
state = env.reset()
done = False
while not done:
action = agent.choose_action(state)
next_state, reward, done = env.step(action)
agent.update_policy(state, action, reward)
state = next_state六、强化学习优化的应用场景
(一)智能写作助手
通过强化学习,智能写作助手可以根据用户的反馈动态调整生成的文本,使其更符合用户的写作风格和需求。
(二)自动化决策系统
在自动化决策系统中,强化学习可以帮助模型更好地评估不同选择的后果,从而做出更优的决策。
(三)游戏与仿真
在游戏和仿真场景中,强化学习可以帮助模型更好地适应动态环境,提升其决策能力和适应性。
七、强化学习优化的注意事项
(一)环境设计的复杂性
环境设计需要考虑状态、动作和奖励的定义,这可能非常复杂,需要根据具体任务进行调整。
(二)策略网络的稳定性
策略网络的稳定性对强化学习的性能至关重要。需要通过适当的训练策略和超参数调整来确保策略网络的稳定性。
(三)性能评估与调试
强化学习模型的性能评估需要综合考虑奖励、策略和环境的复杂性。调试过程中需要仔细分析模型的行为和性能。
八、架构图与流程图
(一)架构图
以下是一个强化学习优化的整体架构图:
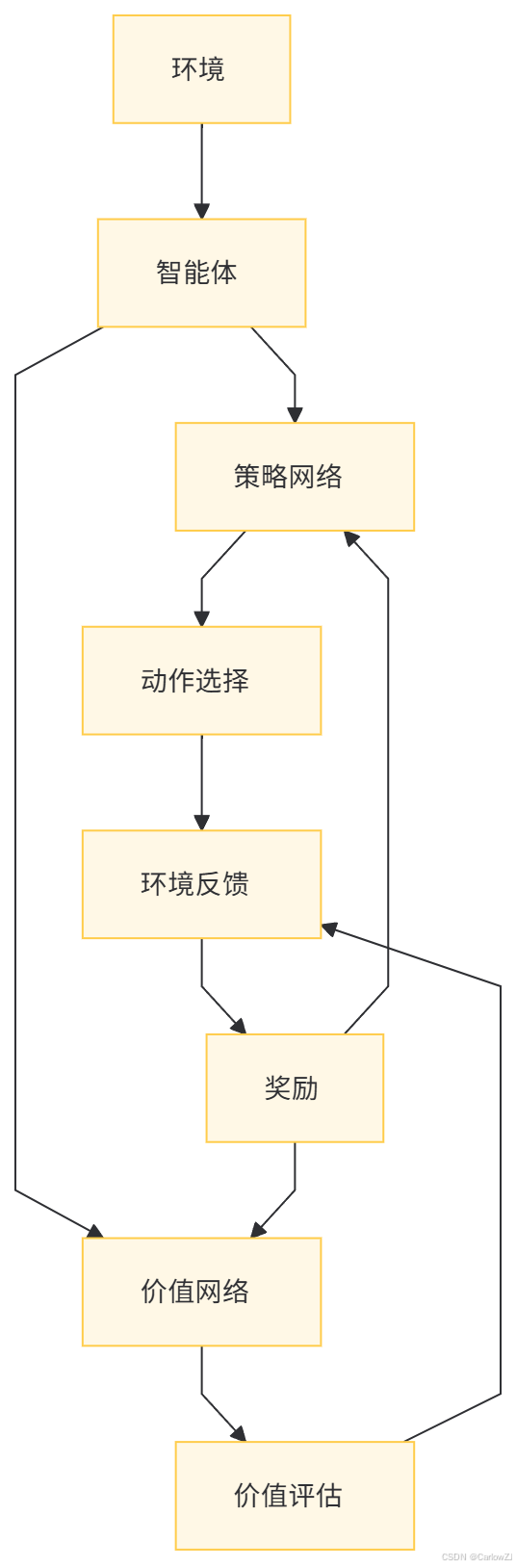
(二)流程图
以下是一个强化学习优化的详细流程图:
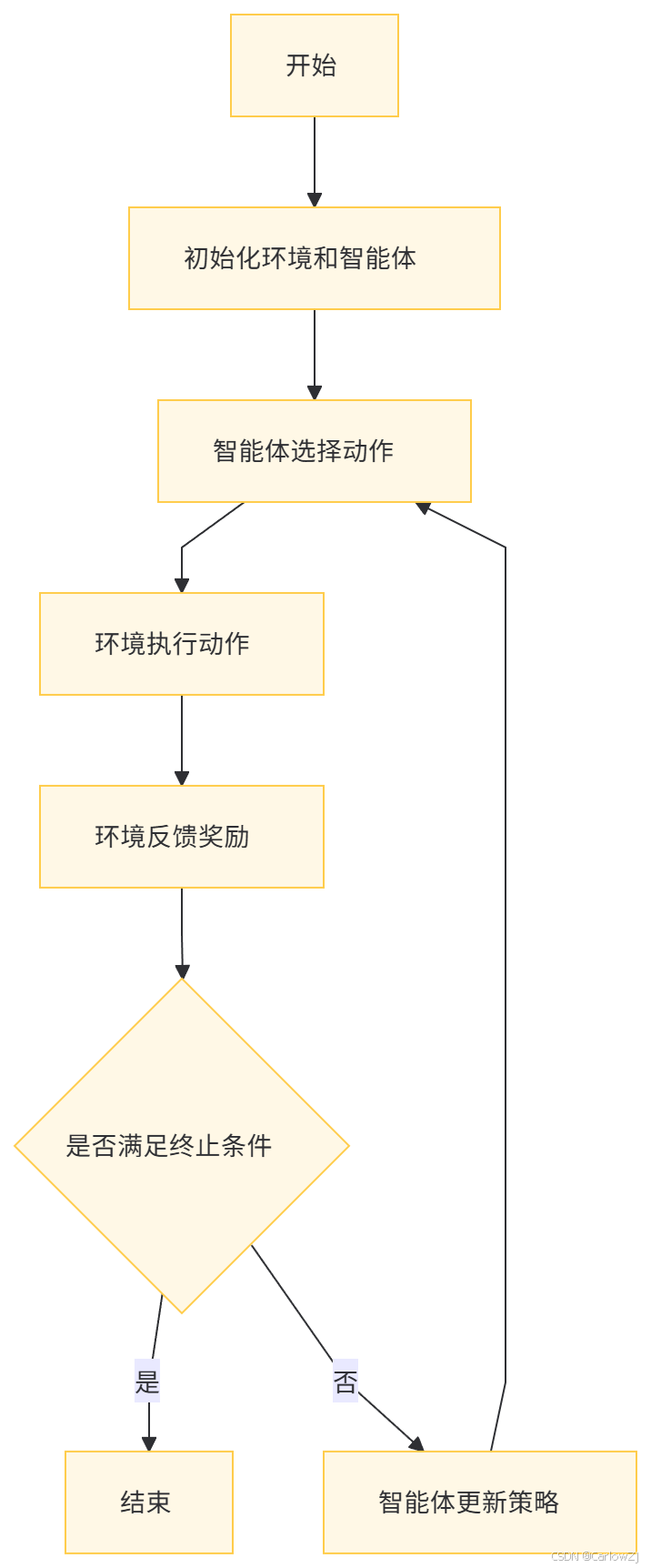
九、总结
强化学习是优化大语言模型的重要技术之一,通过引入奖励机制和动态决策能力,可以显著提升模型的性能和适应性。本文详细介绍了强化学习的基本概念、应用场景、实现方法、代码示例以及注意事项,并通过架构图和流程图帮助读者更好地理解整个过程。希望本文对您有所帮助!如果您有任何问题或建议,欢迎在评论区留言。
在未来的文章中,我们将继续深入探讨大语言模型的更多高级技术,如联邦学习、多模态融合等,敬请期待!
十、参考文献
-
Sutton, R. S., & Barto, A. G. (2018). Reinforcement Learning: An Introduction. MIT Press.
-
Mnih, V., Kavukcuoglu, K., Silver, D., Graves, A., Antonoglou, I., Wierstra, D., & Riedmiller, M. (2013). Playing Atari with deep reinforcement learning. arXiv preprint arXiv:1312.5602.
-
Silver, D., Huang, A., Maddison, C. J., Guez, A., Sifre, L., van den Driessche, G., ... & Hassabis, D. (2016). Mastering the game of Go with deep neural networks and tree search. Nature, 529(7587), 484-489.
-
Devlin, J., Chang, M. W., Lee, K., & Toutanova, K. (2018). BERT: Pre-training of deep bidirectional transformers for language understanding. arXiv preprint arXiv:1810.04805.



















 952
952

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











