






架构是一个非常宽泛的话题,从组织结构上来说,涉及到前端、后端、运维;从软件设计上来说,涉及到需求分析、设计、编码、测试;从物理结构上来说,涉及到CDN、负载均衡、网关、服务器、数据库。当前一些架构方面的书籍,一般都从单体架构讲起,逐步过渡到微服务、云原生等,但这难免会让人疑惑,是否微服务就是最好的架构,或者说,当我从零设计一款系统时,面对现在各领域层出不穷的框架、技术,我到底应该如何选择?
时代在变化,架构在演化。我想从另一个角度看架构,从现在的视角出发,我们该如何设计一个架构,哪些技术应该被使用,哪些技术不应该被使用。
“云”的变化
“云”已经深入各行各业,以前我们会讨论应不应该上云,现在我们只会讨论什么东西上云、什么东西不上,这正是一个技术变得成熟的表现。
现在的云厂商,不止涉及 PaaS 层,SaaS 和 IaaS 也有,但一般我们用的最多的,还是在 PaaS 层上。原先可能我们在 PaaS 层部署我们的服务,享受虚拟硬件的灵活,可是我们很快发现,如果软件层面依然笨重,或者说我们还需要关心这个软件应该部署在哪里、端口怎么配置,我们要扩容到哪台虚拟的服务器等等这些问题,我们总感觉“云”还少了些什么。
幸运的是,容器化和 Kubernetes 的流行彻底解决了这个问题,软件真正的独立出来,无需关心它运行的环境,它只需要关心的是:计算力、存储、网络等它运行必备的资源,这些资源 Kubernetes 都为它抽象了出来。所以把 Kubernetes 誉为“云”时代的操作系统不无道理,它是“云”的最后一块拼图。
以前常碰到的一个场景是,运维问后端开发:“你这个项目要部署到哪台服务器?”,而开发只能说:“我不管布到哪台,能访问就行。”(这个场景和产品与开发的对话、客户与产品的对话是不是异曲同工😄)
这个场景归根结底,还是角度问题。当然,在云上,这不是问题。

因此,现在无论开发一个什么样的系统,都可以先把云、Kubernetes 作为架构的底层。
给系统装上眼睛
可观察性如火如荼的发展,OpenTelemetry为越来越多的人所熟知,现在上线的系统,如果还忽略这块的内容,就显得有些退步了。
可观察性一般是指:日志、监控、链路追踪。我一般会把它继续细分成五大块:
日志
日志的重要性不言而喻,一般我们也最关注这一块,如果连线上服务的日志都看不到了,那这个服务也就离灭亡不远了。
监控
随着 Prometheus 的流行,监控也越来越为人认可。Prometheus 为我们带来的是一套完整的、统一的监控方案,包括硬件、中间件、软件。原先没有 Prometheus,可能很多工作都只能自己做。
告警
告警一般都会被归类到监控,也不怎么被人重视。这正是我一定要单独把告警列出来的原因,一方面,告警不仅仅是指针对异常监控指标的告警,日志也可以告警;链路追踪也可以告警;甚至软件本身也可以告警,这些需求都是很常见的。告警系统如何聚合这些指标、如何汇总、如何清洗、如何抑制,都是一个很大的课题,这篇文章无法深入的展开来讲。总之,一个好用的告警系统一定是能够及时告警、告警信息完整可追溯、告警不会引起疲劳。
当前很多告警系统都流于表面,或者告警太频繁引起疲劳、或者没有合理分级、或者没有合理划分 Tag 等等。
堆栈追踪
这块很少有文章会提,其实堆栈追踪是非常重要的,不仅是用于性能分析层面。比如:当你收到一个服务内存告警,你应该如何排查?
如果是 Java 还好,JVM 可以提供一些 Profiler;如果是 Go 语言,恰恰你忽略了使用 pprof,那实际上这个排查已经中断了,你无法得知服务的哪行代码引起了内存异常。
所以不管是哪种语言,一般都会提供 Profiler 分析,一定要提早接入,当真正出现问题时,你会感谢那时候有远见的自己的。😄
链路追踪
链路追踪是可观察性的最后一环,一般也是最难的一环。
因为既然要追踪,势必要深入代码,带来一定的侵入性,那些吹嘘无侵入、低侵入的都要仔细鉴别,一般不侵入是不可能的。
而且到底要追踪到那个粒度也是个问题,是深入到每个函数调用、还是到服务之间的链路即可。如果到服务间链路即可,可能有一些云原生项目,如:Cilium 能提供无侵入的追踪,但也只能到服务层。
有个Deepflow的开源项目,号称真正零侵入,而且能深入追踪到函数层,它通过 eBPF 技术达到完全的代码无感知,这块我正在研究中,不是特别懂。
一般链路追踪是最不重要的,以上四块基本上能发现大部分问题了。而且链路追踪的实施会很大的影响到开发进度。所以这块属于锦上添花,有也很好,没有也不要紧。
随着Cilium、DeepFlow 等技术的发展,我相信,链路追踪可以实现真正的代码无侵入。
加上了以上技术后,我们的架构图景更新如下图:
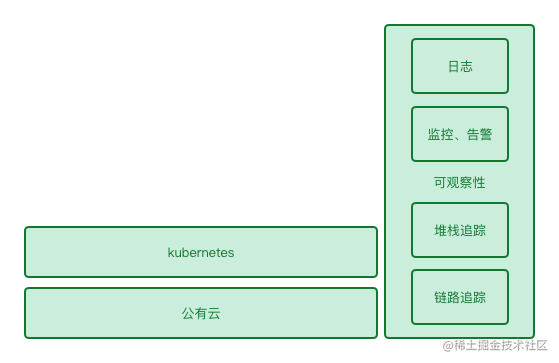
“三高”架构
让我们先从一个小故事开始,这个故事的主人公叫小明,是公司的主程,一天,他被老板叫到了办公室:
老板:“小明啊,我们公司要推出一个线上商城,凭我们的质量和服务,这个商城一定会跑火🔥,这个开发的重担就落在你身上了。”
小明:“好的,老板。你希望这个商城开发成什么样?”
老板:“就是能买东西就行了,淘宝是什么样,我们就做成什么样,你就按日活千万给我设计。你放心,人、钱、资源,要什么尽管提,时间长点也不要紧,我只要能做出来。”
小明接到任务,心理有点虚,去网上搜了很多淘宝的技术文章,不停的学习:高可用、高性能、高并发、分库分表、服务拆分、多级缓存、TiDB各种技术都被添加到他的设计里,最终跑出来的性能测试成绩也算不错,达到了千万日活的目标。给老板的演示也很顺利,虽然老板看不懂这些技术名词,但就是觉得很🐂。
可是系统上线了,每天 bug 不断,不是用户抱怨自己的商品不见了;就是某个微服务挂了,导致系统不可用。小明每天都疲于排查问题和修复问题,终于有一天,他成功在 35 岁前领到了“毕业证”。
在这个故事里,读者觉得问题出在哪里?是老板这个资本家不懂装懂,还是这个目标不够实际,亦或者小明过度设计?
我认为都不是,你可以说老板的目标定的过高,但他也许真的调研过市场,确信能够达到日活千万的目标;而且,人都是有慕强心理的,天生喜欢向强者看齐,这并不是坏事;站在小明的角度,他也没错,他努力学习,天天加班,终于把系统搞了出来,可还是功亏一篑。
我认为真正的问题是共识,准确说,是时间的共识。
在过去互联网蓬勃发展的日子,大家的潜意识里总存在一种共识,那就是要快点。我要快点搞出来,以免被别人抢先;我要快点抢占市场,才能一家独大;我要快点招人,扩大体量。这种快,带来了 996、带来了内卷,带来了焦虑。很多时候,人没问题,事也没问题,但需要一点时间,慢慢发酵。
在这个故事场景中,老板希望快点抢占市场,因此希望软件系统能一步到位。于是小明只能去搜索学习,而很多知识实际是有梯度的,小明也许能成为一个优秀的架构,但可惜,他现在不是。这就像让一个小学生去学初中知识,尚且可行;让一个小学生去学高等数学,不搞出一点问题来才是怪事。互联网把所有的信息汇总了起来,一方面,我们能更快的获取信息;但是另一方面,我们或多或少都接触到了不属于我们这个层次的信息,这并不利于我们成长。
所谓“三高”架构也是如此,“三高”不是一蹴而就的,高可用、高性能、高并发也不是并列关系,我们谈到“三高”,似乎内心出现的是这个模型:

但实际上,“三高”是一个递进关系,也就是说,随着时间和体量的变化,我们的关注点依次上升。
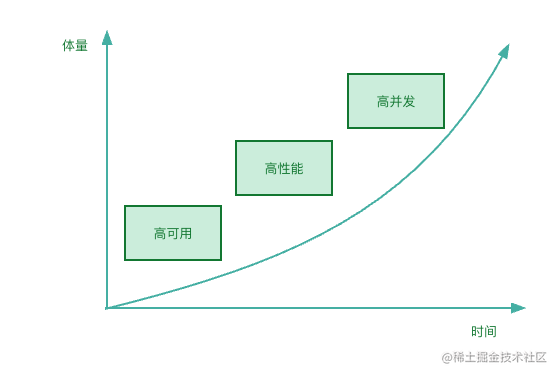
在项目初期,体量很小,我们的关注点应该更落在高可用上,能正常使用才是关键。慢一点,问题真的不大。
随着时间推移,项目体量越来越大,市场竞争也逐渐激烈。这时,良好的性能就成了脱颖而出的关键,我们需要拓展节点、优化索引,以提升系统性能。
等业务越做越大,我们才需要去考虑高并发下的架构重构问题。
所以根据以上的总结,我会给出一个如下架构模版,这个模版应该是所有新项目均可使用的默认模版:
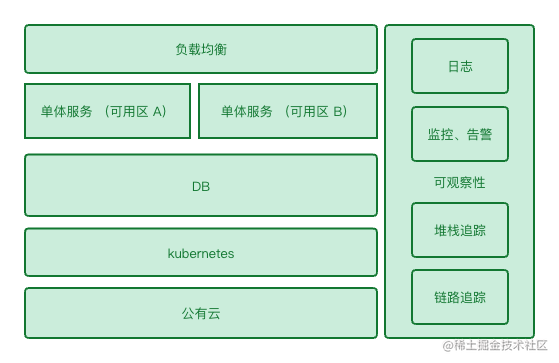
从上往下看,负载均衡我们一般都是用的云 LB,接入 Kubernetes Ingress,不需要引入什么高级的网关,Ingress 已经能支持基础功能。(现在叫 Gateway)
服务层是单体架构,也就是所有代码都在同一进程,但是,要在代码内部做好分层,分好模块,定义好模块间调用规则。
服务层的可用性由冗余保证,我们会在不同可用区的机器上冗余一套服务B,服务A、B 代码完全相同,都可以处理请求。有了这个冗余,一方面可以做到零停机时间;另一方面,一个服务崩溃不影响另一个服务,一个可用区崩溃(挖断光缆)不影响另一个可用区。
还可以在不同地域冗余部署一套完全一致的架构,比如上海一套、广州一套。上海作为线上环境,广州作为预发布环境(数据定期同步),可以做发布前测试、性能压测等等工作。
数据层也是单 DB 实例,甚至不用按模块分库,所有模块都在同一库中,只是表名上有模块前缀。这样做的考虑是不想引入跨库事务,跨库事务必然会带来分布式事务,这其中的知识又可以写成一本书。
数据层的可用性一方面有主备(但是主备机不需要读写分离,这样就不会有读写不一致的问题,备机平常不对外服务);另一方面即使线上数据库实例挂了,短时间起不来。我们还有预发环境的数据库作为备选方案。
这就已经足够了,不需要更多的高深技术,顶多需要搜索加上 ElasticSearch,需要 NoSQL 运行一个 MongoDB,等等等等。我们可以花更多的精力在实现业务上,而不是疲于处理底层架构。
这个基础的架构模版,重点关注的是“高可用”。但又克制的限制了引入的技术,实现有限的“高可用”,尽可能的让系统中参与的角色变少,因为多就代表通信,通信就代表复杂。
让架构演化
近来,可演化架构逐渐为人们所熟知,人们越来越了解到,没有人能在一开始设计出一套完美架构,软件与其他工业最大的区别就在于软件是可变化的,而且它应该变化。
但是可演化架构能否成功实施又取决于两点:一是原先的架构是否简单、清晰;二是组织是否支持和理解演化。这里最关键的是第二点,一方面,人们总是对变化的事物存在一定的抗拒,他们会问:“这样真的好吗?会不会影响现在?会不会变得更差?”;另一方面,组织是否有人真的懂系统如何演化,举个例子:现在基于这个基础架构模板,有一张表已经超过五千万行,其实这张表本身是一种类似日志的表,它内部的旧数据已经不会再变动。这时候最好的方案应该是使用分区表,但组织里有人为了自己的 KPI,强行推进整个数据库的分库分表工作,用于在晋升时吹牛。这就不叫演化,这叫揠苗助长。
总之,当我们设计好了一个基础架构,我们也要呵护好它,在为它进行任何改动之前,先要考虑这个改动会带来什么,是不是能正好解决我的问题? 而不是解决一个问题带来一百个新问题。
演化需要时间,需要耐心,猩猩不可能在一天之内变成人。原先软件行业一直存在一种浮躁气息,技术层出不穷,人人都想一步到位。现在潮水退去,泡沫破灭,希望技术也能回归本源,回到演化的正确道路来。
感谢观看~ 🎶
求职(远程、Golang)启事
本人非 985、211,普通本科大学,无大厂经历😂。
有一颗对技术充满热情的心和喜欢独立思考的大脑,单兵作战能力强。
SAIL作者,设计开发过多款业务、技术系统。
如果您愿意让我成为您的同事,可私聊我或者通过邮箱(690174435@qq.com)与我联系。















 3118
3118











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









