







本文来源公众号“OpenCV与AI深度学习”,仅用于学术分享,侵权删,干货满满。
原文链接:一文带你读懂YOLOv1~YOLOv11
可以和之前的文章江大白 | 目标检测YOLOv1-YOLO11,算法进化全记录(建议收藏!)_yolov5 江大白-CSDN博客结合来看。
YOLO (You Only Look Once) 是一系列实时对象检测机器学习算法。对象检测是一项计算机视觉任务,它使用神经网络对图像中的对象进行定位和分类。这项任务的应用范围很广,从医学成像到自动驾驶汽车。多种机器学习算法用于对象检测,其中一种是卷积神经网络 (CNN)。
CNN 是任何 YOLO 模型的基础,研究人员和工程师使用这些模型执行对象检测和分割等任务。YOLO 模型是开源的,它们在该领域得到了广泛的应用。这些模型从一个版本到另一个版本都在改进,从而提高了准确性、性能和附加功能。本文将探讨整个 YOLO 家族,我们将从原始到最新开始,探索它们的架构、用例和演示。
YOLOv1
在引入 YOLO 对象检测之前,研究人员使用了基于卷积神经网络 (CNN) 的方法,如 R-CNN 和 Fast R-CNN。这些方法使用两步过程来预测边界框,然后使用回归对这些框中的对象进行分类。这种方法速度缓慢且占用大量资源,但 YOLO 模型彻底改变了对象检测。当 Joseph Redmon 和 Ali Farhadi 于 2016 年开发第一个 YOLO 时,它通过新的增强架构克服了传统对象检测算法的大部分问题。
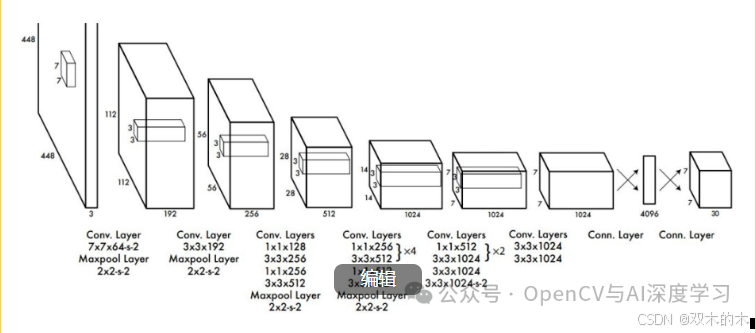
最初的 YOLO 架构由 24 个卷积层和 2 个完全连接的层组成,其灵感来自用于图像分类的 GoogLeNet 模型。YOLOv1 方法在当时是第一个。
网络的初始卷积层从图像中提取特征,而全连接层预测输出概率和坐标。这意味着边界框和分类都在一个步骤中进行。这个一步式流程简化了操作并实现了实时效率。此外,YOLO 体系结构还使用了以下优化技术。
-
-
Leaky ReLU 激活:Leaky ReLU 有助于防止“垂死的 ReLU”问题,即神经元在训练过程中可能会卡在不活跃的状态。
-
Dropout 正则化:YOLOv1 在第一个全连接层之后应用 dropout 正则化,以防止过拟合。
-
数据增强
-
如何工作的?
YOLO 模型的本质是将对象检测视为回归问题。YOLO 方法是将单个卷积神经网络 (CNN) 应用于完整图像。此网络将图像划分为多个区域,并预测每个区域的边界框和概率。
这些边界框由预测概率加权。然后,可以对这些权重进行阈值处理,以仅显示高分检测。
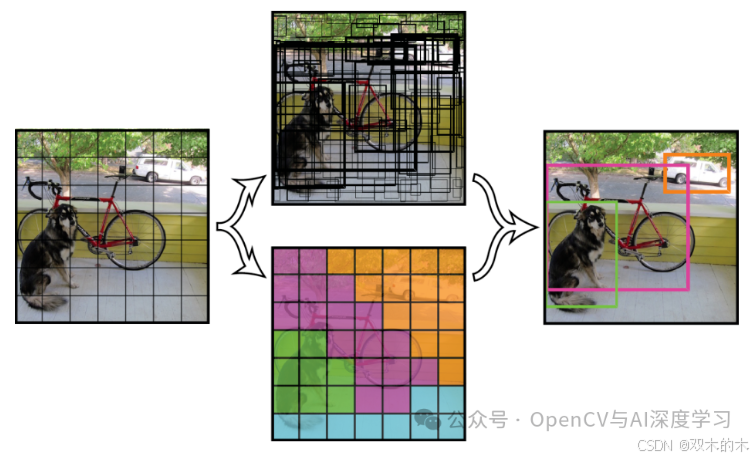
YOLOv1 将输入图像划分为一个网格 (SxS),每个网格单元负责预测其内部对象的边界框和类概率。每个边界框预测都包含一个置信度分数,指示框中存在对象的可能性。研究人员使用交并比 (IOU) 等技术计算置信度分数,该技术可用于筛选预测。尽管 YOLO 方法新颖且速度很快,但它面临一些限制,如下所示。
-
-
泛化:YOLOv1 难以检测在训练中无法准确看到的新对象。
-
空间约束:在 YOLOv1 中,每个网格单元格只能预测两个框,并且只能有一个类,这使得它难以处理成群出现的小对象,例如鸟群。
-
损失函数限制:YOLOv1 损失函数在小边界框和大边界框中处理错误的方式相同。大框中的小错误通常是可以的,但小错误对 IOU 的影响要大得多。
-
定位错误:YOLOv1 的一个主要问题是准确性,它经常错误地定位对象在图像中的位置。
-
现在我们已经介绍了 YOLO 的基本机制,让我们看看研究人员如何在下一个版本中升级此模型的功能。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 4万+
4万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









