






点击下方卡片,关注“自动驾驶之心”公众号
戳我-> 领取自动驾驶近15个方向学习路线
今天自动驾驶之心为大家分享清华大学和威斯康星大学麦迪逊分校最新的工作!统一自动驾驶纵向轨迹数据集(Ultra-AV)。如果您有相关工作需要分享,请在文末联系我们!
自动驾驶课程学习与技术交流群事宜,也欢迎添加小助理微信AIDriver004做进一步咨询
论文作者 | Hang Zhou等
编辑 | 自动驾驶之心
摘要
自动驾驶车辆在交通运输领域展现出巨大潜力,而理解其纵向驾驶行为是实现安全高效自动驾驶的关键。现有的开源AV轨迹数据集在数据精炼、可靠性和完整性方面存在不足,从而限制了有效的性能度量分析和模型开发。
本研究针对这些挑战,构建了一个(Ultra-AV),用于分析自动驾驶汽车的微观纵向驾驶行为。该数据集整合了来自14 个的数据,涵盖多种自动驾驶汽车类型、测试场景和实验环境。我们提出了一种数据处理框架,以获得高质量的纵向轨迹数据和跟驰轨迹数据。最后,本研究通过对安全性、通行效率、稳定性和可持续性等多个性能维度的评估,以及对跟驰模型变量之间关系的分析,验证了数据的有效性。我们的工作不仅为研究人员提供了标准化的数据和指标,用于分析自动驾驶汽车的纵向行为,还为数据采集和模型开发提供了指导方法**。
介绍
理解自动驾驶汽车的纵向驾驶行为对于确保其安全性和优化交通流至关重要。然而,现有的开源自动驾驶汽车轨迹数据集缺乏精细的数据清理和标准化,导致:
数据质量不均,影响模型开发和性能评估。
缺乏完整性和可靠性,难以进行跨数据集研究。
分析效率低,影响AV安全测试和仿真研究。
本研究提出了一种统一的自动驾驶汽车纵向轨迹数据集(Ultra-AV),有以下特点:
大规模数据集: 数据总量 2.6GB,涵盖 14 个不同的自动驾驶数据源,涉及 30 多种测试和实验场景,包含 超过 1000 万个数据点,相当于 280 小时以上的行驶数据。
标准化数据格式: 统一不同数据源的数据格式,使其适用于跨数据集研究。
数据处理框架: 提供一种高效的数据处理方法,提高数据的可用性,支持自动驾驶仿真测试和行为建模。
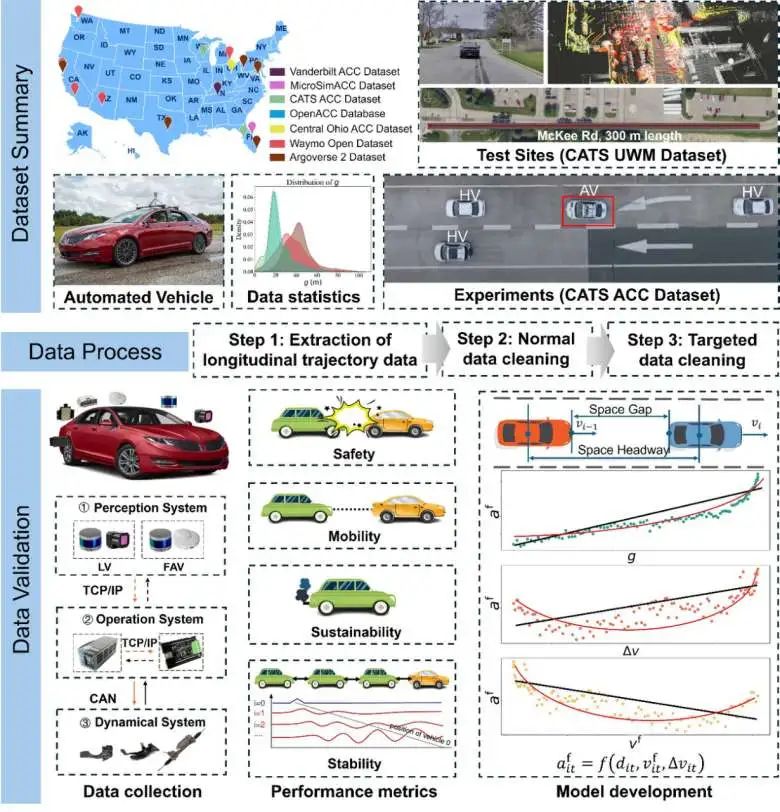
方法
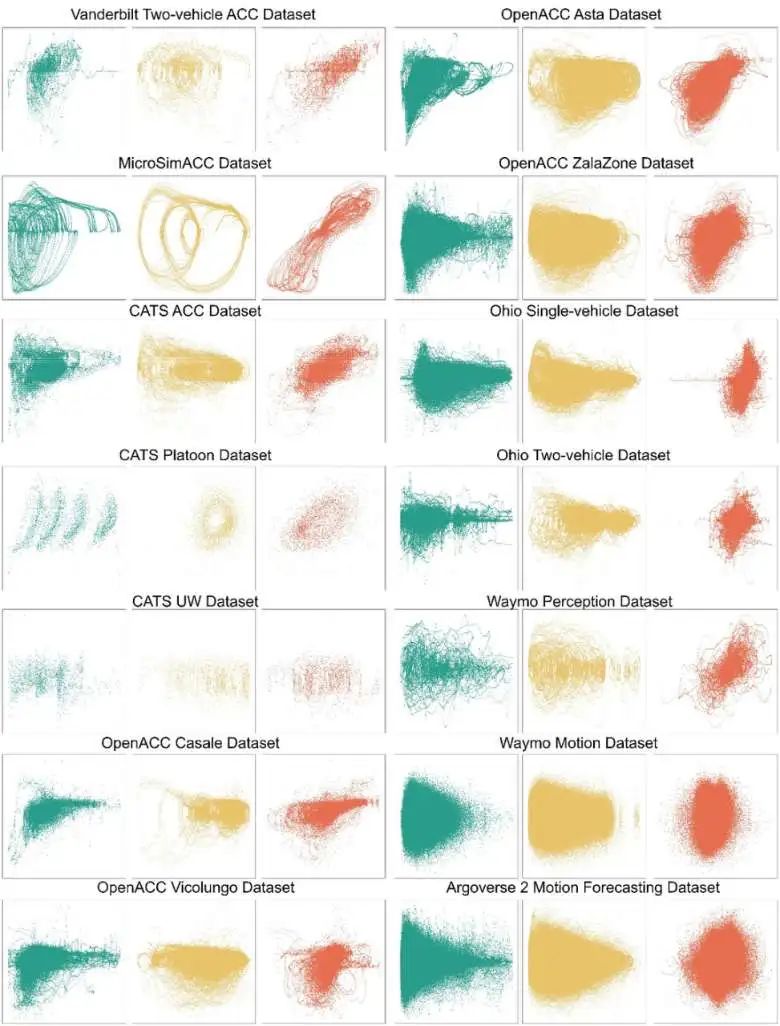
如图所示,我们的统一数据集涵盖了14个不同来源的数据集。这些数据集收集自美国和欧洲的多个城市,确保了所选城市的多样性和代表性,使研究具备更广泛的适用性。
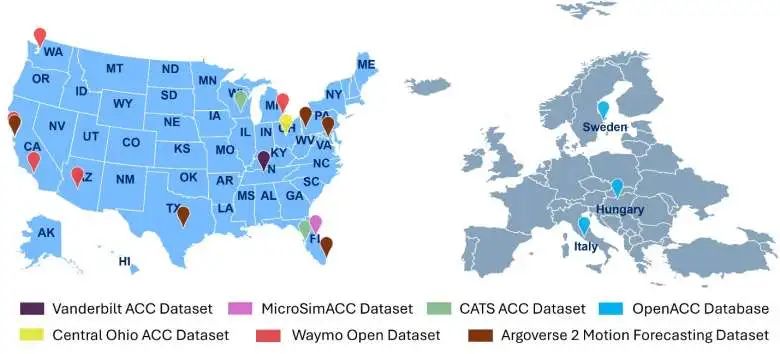
此外,大多数被整合的数据集都包含自动驾驶汽车的长时间轨迹,这些数据广泛应用于自动驾驶行为分析。然而,一些特定数据集,如 Waymo Open Dataset中的 Waymo Motion Dataset 和Argoverse 2 Motion Forecasting Dataset,其轨迹时间较短,分别为9.1 秒和11 秒(采样频率为 10Hz)。这些数据集主要用于Motion Forecasting领域的研究,尽管轨迹较短,但其采集地点通常位于复杂交通环境中的市区,能够提供在复杂场景下分析自动驾驶行为的机会。因此,本研究特别包含了对这两个数据集的分析,以确保数据集的全面性和适用性。
本研究提出了一种数据处理框架,用于标准化并清理自动驾驶汽车轨迹数据。该框架包含以下三步。
Step 1: 轨迹数据提取
从多个AV数据集中提取统一格式的纵向轨迹数据,包括汽车位置、速度、车头时距等关键变量。关键变量如下:
| 变量 | 描述 |
|---|---|
| Trajectory ID | 轨迹数据的唯一标识 |
| Time Index | 轨迹数据时间索引 |
| LV Position | 领航车(LV)位置 |
| LV Speed | 领航车速度 |
| FAV Position | 跟驰车(FAV)位置 |
| FAV Speed | 跟驰车速度 |
| Space Headway | 车头间距 |
| Speed Difference | 车速差 |
针对处理过后的数据,我们通过三个方面对数据进行验证分析。
Step 2: 通用数据清理
为了提高数据的可靠性,采用以下清理策略:
移除异常值: 删除超过 均值 ± 标准差 的数据点。
缺失值填补: 删除时间戳不连续的数据点,并采用线性插值补全缺失数据。
轨迹数据重构: 重新整理数据结构,确保数据的可解释性。
Step 3: 数据特定清理
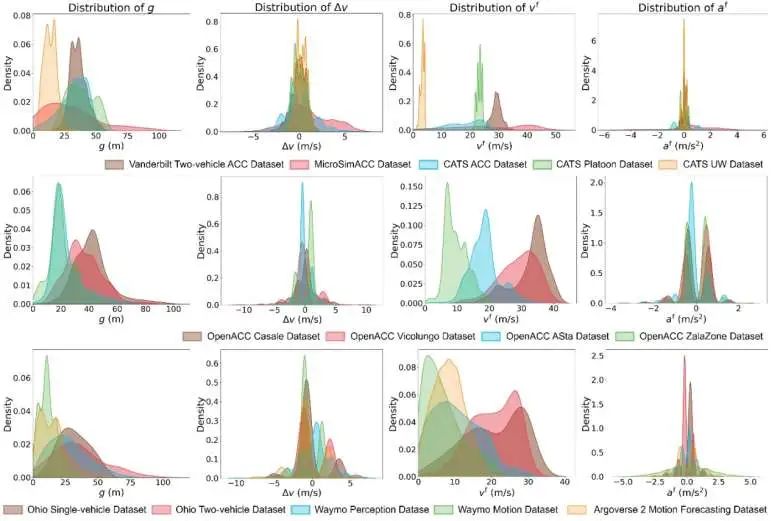
针对车队跟驰场景,设定阈值去除异常数据,以提高分析准确性。下图展示了处理后的数据分布。其中分别代表车头间距,车速,车速差,和加速度。
数据采集
结合作者所在课题组的数据方案和文献,我们认为目前自动驾驶汽车的数据采集通常来自多种高精度传感器的数据整合,包括LiDAR(激光雷达),*GPS(全球定位系统),DSRC(车载通信单元),高清摄像头等。图中显示了作者课题组基于Lincoln MKZ的自动驾驶汽车测试平台。

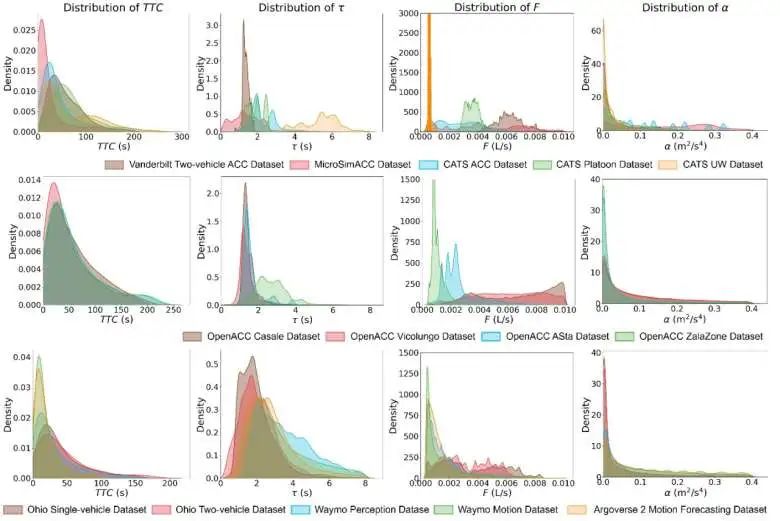
关键性能指标
为评估自动驾驶汽车的性能,我们采用以下性能指标:
安全性指标: Time-to-Collision ()。
稳定性指标: 加速度变化率()。
可持续性指标: 燃油消耗()。
通行效率指标: 车头时距()。
分析结果如图所示。
跟驰模型开发
最后,为了分析自动驾驶汽车的纵向行为,本研究探讨了加速度与输入变量(车头间距、车速和车速差)之间的关系。下图绘制了这些变量之间的散点图,其中y轴是加速度,绿/黄/橙色图片的横轴分别代表车头间距,车速,以及车速差。可以看出,车头间距和车速差对加速度的影响显著,而加速度与车速之间无明显线性关系。其中,加速度与车头间距呈非线性正相关,与车速差呈线性负相关。
结论
本研究回顾了多个自动驾驶轨迹数据集,并开发了统一自动驾驶纵向轨迹数据集,主要贡献包括:
标准化纵向轨迹数据集 - 统一并清理不同数据源的数据,提高数据可用性。
高质量的跟驰数据集 - 通过去噪和数据清理,保证数据分析的准确性。
跟驰行为分析 - 研究加速度与输入变量之间的非线性关系。
本文的连接和相关代码、数据可以在以下链接里找到:
Ultra-AV 数据集论文 - Scientific Data
GitHub 代码仓库 - Ultra-AV Dataset
① 自动驾驶论文辅导来啦

② 国内首个自动驾驶学习社区
『自动驾驶之心知识星球』近4000人的交流社区,已得到大多数自动驾驶公司的认可!涉及30+自动驾驶技术栈学习路线,从0到一带你入门自动驾驶感知(端到端自动驾驶、世界模型、仿真闭环、2D/3D检测、语义分割、车道线、BEV感知、Occupancy、多传感器融合、多传感器标定、目标跟踪)、自动驾驶定位建图(SLAM、高精地图、局部在线地图)、自动驾驶规划控制/轨迹预测等领域技术方案、大模型,更有行业动态和岗位发布!欢迎扫描加入

③全网独家视频课程
端到端自动驾驶、仿真测试、自动驾驶C++、BEV感知、BEV模型部署、BEV目标跟踪、毫米波雷达视觉融合、多传感器标定、多传感器融合、多模态3D目标检测、车道线检测、轨迹预测、在线高精地图、世界模型、点云3D目标检测、目标跟踪、Occupancy、CUDA与TensorRT模型部署、大模型与自动驾驶、NeRF、语义分割、自动驾驶仿真、传感器部署、决策规划、轨迹预测等多个方向学习视频(扫码即可学习)

④【自动驾驶之心】全平台矩阵


















 8535
8535

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









