






点击下方卡片,关注“具身智能之心”公众号
更多干货,欢迎加入国内首个具身智能全栈学习社区:具身智能之心知识星球(戳我),这里包含所有你想要的。
本文为论文作者投稿,这里提出了 MoManipVLA,一种全新的通用移动操作视觉-语言-动作模型(Vision-Language-Action Model, VLA)。该模型能够在真实场景中仅用 50 个训练轨迹 即实现 40% 的成功率,显著提升了移动操作任务的效率与泛化能力。

论文地址: https://arxiv.org/abs/2503.13446
项目主页: https://gary3410.github.io/momanipVLA/
1. 简介
移动操作使机器人能够在广阔空间内执行复杂的操作任务,这需要对移动底座和机械臂进行全身协调控制。随着居家服务、智能制造、物流仓储等领域对机器人自主移动操作需求的日益增长,任务复杂性和物体多样性对移动操作模型的泛化性提出了严峻挑战。
然而,现有的移动操作框架缺少大规模预训练,导致整体泛化性低下。同时,收集手脚协同的移动操作数据轨迹昂贵成本,进一步限制了移动操作模型性能。
近年来,视觉-语言-动作模型(VLA) [1, 2] 在任务泛化和场景适应方面展现了卓越性能。然而,现有的 VLA 研究主要聚焦于固定底座操作,由于缺乏对移动底座动作的预测能力,使其难以直接应用于移动操作场景。为此,我们提出了 MoManipVLA,一个高效的策略迁移框架,将固定底座的 VLA 模型迁移到移动操作任务中。
具体而言,MoManipVLA 利用预训练的 VLA 模型生成高泛化的 末端执行器路标(Waypoint),以指导移动操作轨迹的生成。同时,我们为移动底座和机械臂设计了基于场景约束的 运动规划目标,包括:
可达性(Reachability)
轨迹平滑性(Smoothness)
避碰(Collision Avoidance)
从而最大限度地提高移动操作轨迹的 物理可行性。为了高效规划全身运动,我们提出了一种 双层轨迹优化框架(Bi-level Trajectory Optimization):
上层优化 负责预测底座运动轨迹,以增强机械臂的操作策略空间。
下层优化 选择机械臂的最佳轨迹,确保其遵循 VLA 模型的规划完成任务。

更详细的demo video可以在项目主页观看。
2. 方法
我们的方法的核心思想是 利用 VLA 的强泛化能力,引导机器人底座和手臂的轨迹生成,通过 动作规划目标 生成物理可行的轨迹,让机械臂末端执行器在移动操作设定下到达 VLA 预测的路标,从而完成后续操作任务。
2.1 策略迁移网络
在大规模互联网数据集上预训练的 VLA 模型在 任务泛化 和 场景迁移 方面展现了极强的性能。然而,现有的 VLA 仅限于 固定底座操作。为了高效迁移到 移动操作任务,我们提出了 MoManipVLA 框架,具体如图1所示。
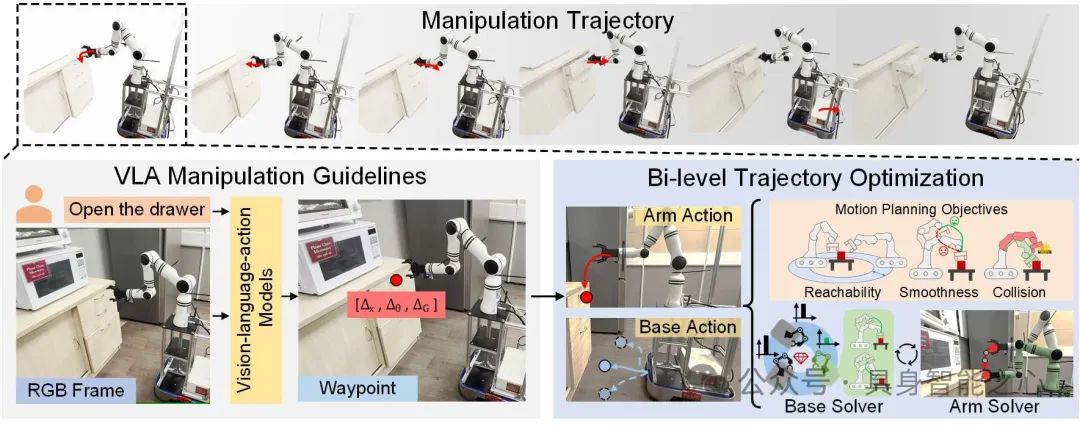
具体来说:
VLA 模型生成末端执行器路标 —— 通过视觉观测,预训练 VLA 模型输出机械臂末端执行器的高泛化路标。
优化动作规划目标 —— 设计 运动规划优化目标(Motion Planning Objectives),确保交互轨迹物理可行(可达性、避碰、平滑性)。
双层轨迹优化框架 —— 由于底座和机械臂的位姿搜索空间庞大,我们进一步提出 双层轨迹优化框架(Bi-level Trajectory Optimization):
上层优化 预测底座运动轨迹,以增强后续操作策略空间,确保末端执行器可以到达路标。
下层优化 机械臂动作,以精准执行 VLA 预测的目标路标。
2.2 移动运动规划目标
运动规划旨在为机器人底座和手臂生成路标之间的运动轨迹。我们通过设计不同的约束来为交互轨迹赋予可达性、平滑性和无碰撞物理含义。我们主要设计了三个约束:可达性(Reachability cost)、平滑性(Smoothness cost)和避碰(Collision cost),具体如图2所示。
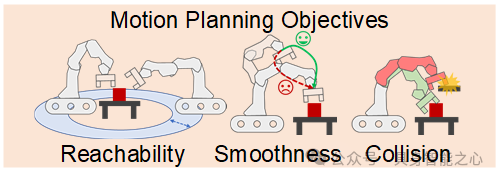
可达性(Reachability Cost):
由于移动操作需要机器人与大范围内的物体进行交互,底座位姿显著影响手臂能否到达目标物体。
我们使用 逆运动学(IK)求解器 计算可达性成本。
在最大迭代次数( )内获取关节角度解表明轨迹是可到达的。迭代次数越多,IK求解速度越慢意味着关节角度越接近范围限制,可达成本越高。
轨迹平滑性(Smoothness Cost):
约束机器人手臂 关节角度 以及 底座的平移和旋转 保持连续平滑,避免突然变化。
平滑轨迹 有助于机器人控制的稳定性。
避碰(Collision Cost):
机器人需要避免 手臂、移动底座和环境中的物体 之间的碰撞,以确保安全。
我们利用 nvblox 计算 ESDF(欧几里得距离场),并通过 随机采样机器人表面上的查询点 评估碰撞风险。
其中, 为安全距离阈值。只有当距离小于该阈值时,才会对整体目标产生贡献,从而促使生成的轨迹尽可能远离障碍物。
2.3 双层轨迹优化框架
由于 移动底座和机械臂的姿态搜索空间庞大,直接搜索最优解非常困难。因此,我们提出 双层轨迹优化框架 来提高轨迹生成的效率:
上层优化 预测底座轨迹,以增强后续机械臂的操作策略空间。
下层优化 机械臂轨迹,使其遵循预训练 VLA 模型的规划完成操作任务。
具体如图3所示
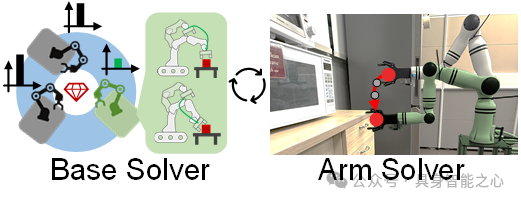
整个双层轨迹优化算法流程可以概括为以下伪代码:
初始化:根据当前观测状态与 VLA 预测的路标,利用线性插值生成初始轨迹。设定初始时刻 。
上层优化阶段:
对于每个迭代步 ,固定当前机械臂状态,随机采样底座候选轨迹;
针对每个底座候选随机采样交互轨迹并计算期望成本,选择期望值较低的候选作为新的底座状态;
更新底座轨迹直到满足终止条件。
下层优化阶段:
固定优化后的底座轨迹,利用 Dual Annealing 算法对机械臂轨迹进行细化;
在每次迭代中,通过 IK 求解器更新机械臂关节角度,并计算平滑性与碰撞成本;
最终确定机械臂的最优轨迹,使末端执行器精准到达目标路标。
终止:当整体目标函数收敛或达到最大迭代次数时,输出最终生成的轨迹。
3. 实验与评估
为了验证 MoManipVLA 的有效性,我们在模拟环境与真实机器人平台上进行了实验。下面详细介绍实验设置、评估指标以及结果分析。
3.1 OVMM 基准测试
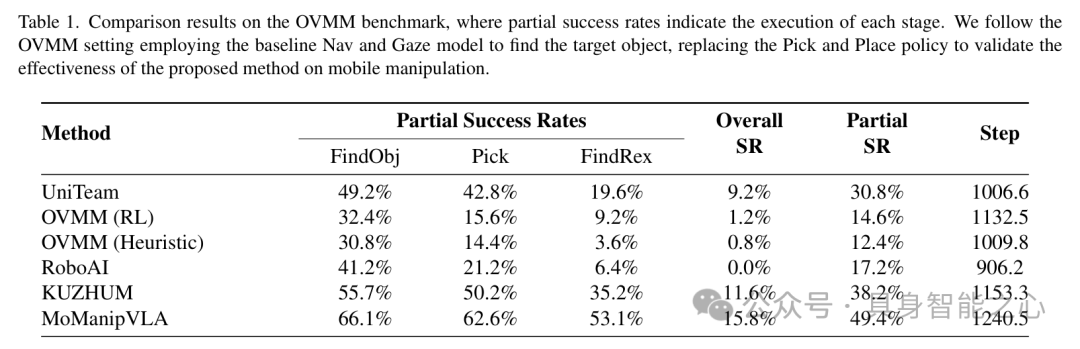
我们在 Open Vocabulary Mobile Manipulation (OVMM) 基准测试平台上进行实验。该平台包含 60 个模拟场景模型以及超过 18,000 个 3D 物体模型。任务定义为 “将目标物体从容器 A 移动到容器 B”,涵盖导航、目标定位、抓取和放置等多个阶段。
我们的方法分别实现了4.2%的总体成功率和11.2%的部分成功率增益。这表明我们的方法可以协调机器人底座和手臂的运动,使末端执行器与目标对象保持合理的空间关系。
下表展示了各方法在 OVMM 模拟器上的详细对比结果。
3.2 真实世界实验
我们使用hexman echo plus底座和RM65机械臂组成移动实验平台,利用Grounding SAM[3]获取机械臂和目标物体mask,以分别用于生成碰撞查询点和构造不包含目标物体的ESDF。我们遵循ORB-SLAM设定使用Realsense T265来获取相机实时位姿。得益于预训练VLA模型的泛化能力,仅使用50个样本完成VLA微调,在移动操作任务上达到40%的成功率。可视化结果如图4所示。
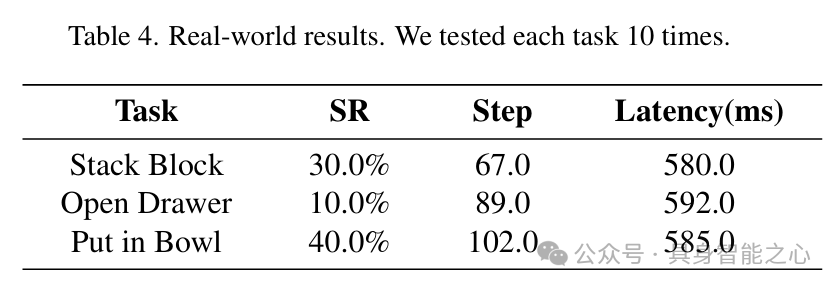
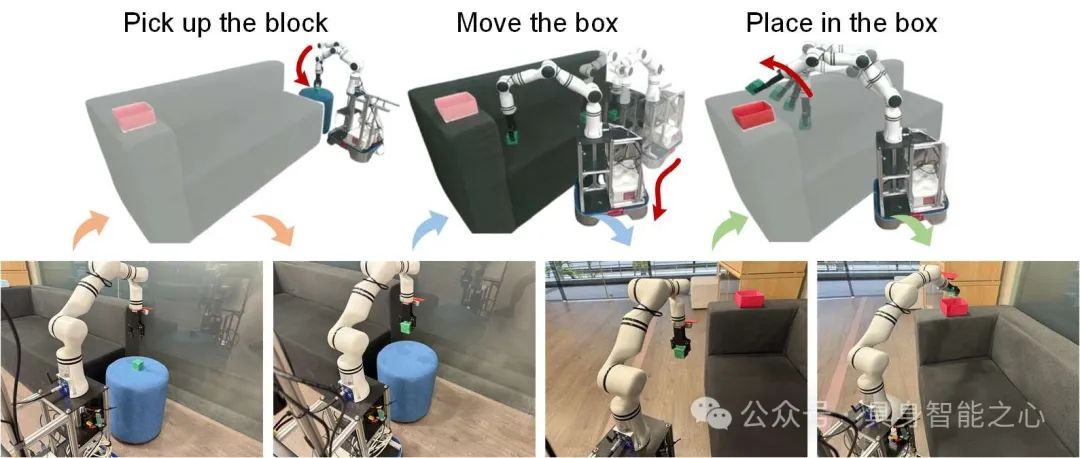
图4 真实世界移动操作可视化 4. 讨论
4.1 方法优势
高泛化能力
MoManipVLA 能够利用大规模数据中学到的知识,实现跨任务、跨场景的高泛化性。实验结果显示,在仅 50 个样本的微调下,真实环境任务的成功率已达到 40%,证明了该方法在数据稀缺场景下的有效性。物理可行性保障
MoManipVLA 生成的轨迹在物理上更为安全和可执行。可达性、平滑性和避碰三重约束的引入确保了生成轨迹不仅满足任务目标,同时符合机器人运动学与动力学约束。高效的双层优化框架
将高维度的全身搜索问题分解为底座与机械臂两个子问题,通过双层优化策略降低了计算复杂度,系统在保持高成功率的同时实现了实时性能。
4.2 方法局限性与未来工作
尽管 MoManipVLA 在多任务上取得显著进展,但其仍依赖预训练模型的质量、存在搜索空间非凸局部最优问题以及长时任务规划不足,未来将通过引入全局优化方法、基于学习的搜索策略和集成任务规划模块等手段加以改进。
参考文献
[1] Songming Liu, Lingxuan Wu, Bangguo Li, Hengkai Tan, Huayu Chen, Zhengyi Wang, Ke Xu, Hang Su, and Jun Zhu. Rdt-1b: a diffusion foundation model for bimanual manipulation. arXiv preprint arXiv:2410.07864, 2024.
[2] MooJinKim,KarlPertsch, SiddharthKaramcheti, TedXiao, Ashwin Balakrishna, Suraj Nair, Rafael Rafailov, Ethan Foster, Grace Lam, Pannag Sanketi, et al. Openvla: An open-source vision-language-action model. arXiv preprint arXiv:2406.09246, 2024.
[3] Tianhe Ren, Shilong Liu, Ailing Zeng, Jing Lin, Kunchang Li, He Cao, Jiayu Chen, Xinyu Huang, Yukang Chen, Feng Yan, et al. Grounded sam: Assembling open-world models for diverse visual tasks. arXiv preprint arXiv:2401.14159, 2024.
“具身智能之心”公众号持续推送具身智能领域热点:
往期 · 推荐
机械臂操作
港大最新!RoboTwin:结合现实与合成数据的双臂机器人基准
伯克利最新!CrossFormer:一个模型同时控制单臂/双臂/轮式/四足等多类机器人
四足或人形机器人
Fourier ActionNet:傅利叶开源全尺寸人形机器人数据集&发布全球首个全流程工具链
斯坦福大学 | ToddlerBot:到真实世界的零样本迁移,低成本、开源的人形机器人平台
TeleAI&港科大最新!离线学习+在线对齐,扩散模型驱动的四足机器人运动
Robust Robot Walker:跨越微小陷阱,行动更加稳健!
斯坦福大学最新!Helpful DoggyBot:四足机器人和VLM在开放世界中取回任意物体
机器人学习
视觉强化微调!DeepSeek R1技术成功迁移到多模态领域,全面开源
UC伯克利最新!Beyond Sight: 零样本微调异构传感器的通用机器人策略
CoRL 2024 | 通过语言优化实现策略适应:实现少样本模仿学习
NeurIPS 2024 | BAKU:一种高效的多任务Policy学习Transformer
人形机器人专场!有LLM加持能有多厉害?看HYPERmotion显身手
NeurIPS 2024 | 大规模无动作视频学习可执行的离散扩散策略
波士顿动力最新!可泛化的扩散策略:能有效操控不同几何形状、尺寸和物理特性的物体
RSS 2024 | OK-Robot:在机器人领域集成开放知识模型时,真正重要的是什么?
MIT最新!还在用URDF?URDF+:一种针对机器人的具有运动环路的增强型URDF
VisionPAD:3DGS预训练新范式!三大感知任务全部暴力涨点
NeurIPS 2024 | VLMimic:5个人类视频,无需额外学习就能提升泛化性?
纽约大学最新!SeeDo:通过视觉语言模型将人类演示视频转化为机器人行动计划
CMU最新!SplatSim: 基于3DGS的RGB操作策略零样本Sim2Real迁移
LLM最大能力密度100天翻一倍!清华刘知远团队提出Densing Law
机器人干活总有意外?Code-as-Monitor 轻松在开放世界实时精确检测错误,确保没意外
斯坦福大学最新!具身智能接口:具身决策中语言大模型的基准测试
机器人控制
RoboMatrix:一种以技能为中心的机器人任务规划与执行的可扩展层级框架
港大DexDiffuser揭秘!机器人能拥有像人类一样灵巧的手吗?
TPAMI 2024 | OoD-Control:泛化未见环境中的鲁棒控制(一览无人机上的效果)
VLA
上海AI Lab最新!Dita:扩展Diffusion Transformer以实现通用视觉-语言-动作策略
北大最新 | RoboMamba:端到端VLA模型!推理速度提升3倍,仅需调整0.1%的参数
英伟达最新!NaVILA: 用于导航的足式机器人视觉-语言-动作模型
优于现有SOTA!PointVLA:如何将3D数据融入VLA模型?
北京大学最新!HybridVLA:打通协同训练,各种任务中均SOTA~
北京大学最新 | 成功率极高!DexGraspVLA:首个用于灵巧抓取的分层VLA框架
ICLR'25 | VLAS:将语音集成到模型中,新颖的端到端VLA模型(西湖大学&浙大)
清华大学最新!UniAct:消除异质性,跨域跨具身泛化,性能超越14倍参数量的OpenVLA
简单灵活,便于部署 | Diffusion-VLA:通过统一扩散与自回归方法扩展机器人基础模型
其他(抓取,VLN等)
TPAMI2025 | NavCoT:中山大学具身导航参数高效训练!
CVPR2025 | 长程VLN平台与数据集:迈向复杂环境中的智能机器人
CVPR2025满分作文!TSP3D:高效3D视觉定位,性能和推理速度均SOTA(清华大学)
模拟和真实环境SOTA!MapNav:基于VLM的端到端VLN模型,赋能端到端智能体决策
场面混乱听不清指令怎么执行任务?实体灵巧抓取系统EDGS指出了一条明路
北京大学与智元机器人联合实验室发布OmniManip:显著提升机器人3D操作能力
动态 3D 场景理解要理解什么?Embodied VideoAgent来揭秘!
NeurIPS 2024 | HA-VLN:具备人类感知能力的具身导航智能体
博世最新!Depth Any Camera:任意相机的零样本度量深度估计
真机数据白采了?银河通用具身大模型已充分泛化,基于仿真数据!
港科大最新!GaussianProperty:无需训练,VLM+3DGS完成零样本物体材质重建与抓取
VinT-6D:用于机器人手部操作的大规模多模态6D姿态估计数据集
机器人有触觉吗?中科大《NSR》柔性光栅结构色触觉感知揭秘!
波士顿动力最新SOTA!ThinkGrasp:通过GPT-4o完成杂乱环境中的抓取工作
LLM+Zero-shot!基于场景图的零样本物体目标导航(清华大学博士分享)
PoliFormer: 使用Transformer扩展On-Policy强化学习,卓越的导航器
具身硬核梳理
Diffusion Policy在机器人操作任务上有哪些主流的方法?
强化学习中 Sim-to-Real 方法综述:基础模型的进展、前景和挑战
墨尔本&湖南大学 | 具身智能在三维理解中的应用:三维场景问答最新综述
十五校联合出品!人形机器人运动与操控:控制、规划与学习的最新突破与挑战
扩散模型也能推理时Scaling,谢赛宁团队研究可能带来文生图新范式
全面梳理视觉语言模型对齐方法:对比学习、自回归、注意力机制、强化学习等
基础模型如何更好应用在具身智能中?美的集团最新研究成果揭秘!
关于具身智能Vision-Language-Action的一些思考
具身仿真×自动驾驶
视频模型For具身智能:Video Prediction Policy论文思考分析
性能爆拉30%!DreamDrive:时空一致下的生成重建大一统
真机数据白采了?银河通用具身大模型已充分泛化,基于仿真数据!
高度逼真3D场景!UNREALZOO:扩展具身智能的高真实感虚拟世界
MMLab最新FreeSim:一种用于自动驾驶的相机仿真方法
麻省理工学院!GENSIM: 通过大型语言模型生成机器人仿真任务
EmbodiedCity:清华发布首个真实开放环境具身智能平台与测试集!
华盛顿大学 | Manipulate-Anything:操控一切! 使用VLM实现真实世界机器人自动化
东京大学最新!CoVLA:用于自动驾驶的综合视觉-语言-动作数据集

















 1317
1317

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









