






作者 | 紫炎 编辑 | 自动驾驶之心
原文链接:https://zhuanlan.zhihu.com/p/1897955823860311908
点击下方卡片,关注“自动驾驶之心”公众号
>>点击进入→自动驾驶之心『端到端自动驾驶』技术交流群
本文只做学术分享,如有侵权,联系删文
《HiP-AD: Hierarchical and Multi-Granularity Planning with Deformable Attention for Autonomous Driving in a Single Decoder》是一篇发表于 2025 年 3 月的论文,来自于nullmax.ai, 旨在提升端到端自动驾驶系统在闭环评估中的性能,特别是在规划模块的查询设计与交互方面~
论文链接:https://arxiv.org/pdf/2503.08612
背景
首先,大多数方法 UniAD, DriveTransformer, VAD, Para-drive, SparseAD 将端到端自动驾驶任务形式化为一种通过轨迹回归进行的模仿学习任务,且监督信号较为稀疏,主要关注轨迹的拟合,而非闭环控制。相比之下,面向闭环的自动驾驶方法则面临其他挑战,例如非凸优化问题 和转向误差。
CarLLaVA 通过将标准航点解耦为时间约束和空间约束的航点,用于纵向和横向控制,在很大程度上缓解了上述问题。然而,CarLLaVA 构建在一个预训练的大语言模型之上,缺乏中间的感知结果,因此可解释性不足,并且未探讨轨迹多样性的问题。
本文提出了一种 多粒度的规划查询表示方式,结合分层航点预测机制用于端到端自动驾驶,如图(c-d)所示。具体来说,我们将航点拆分为:时间维度、空间路径维度、以及驾驶风格维度的预测,并分别使用相应的规划查询(planning queries)来建模。
此外文章将每种类型的航点多样化为多个粒度,通过不同的采样策略(如频率、距离和速度)进行划分,从而在训练过程中引入更丰富的监督信息。这些多粒度航点能够被有效地聚合,以促进不同特征之间的交互。因此,稀疏航点提供了全局信息,而密集航点输出则更适合用于细粒度的控制。更重要的是,这种多粒度设计显著缓解了“自车犹豫”问题——即在某些场景中,自车持续等待,直到闭环仿真超时为止。该方法能够在不引入因果线索的情况下,鼓励车辆在复杂场景(例如交通标志、超车等)中的行为学习。
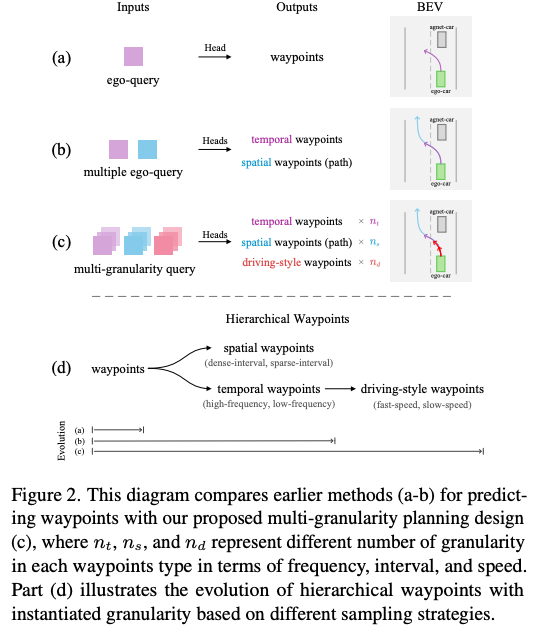
其次,像 UniAD和 VAD这样的序列式范式仅仅在可学习的 ego 查询与感知 Transformer 的输出之间建立了交互。而 Para-Drive的并行方法则是让 ego 查询只与 BEV 特征进行交互。这些方法都缺乏规划模块与感知和场景特征(如图像或 BEV 特征)之间的全面交互,从而限制了规划的有效性。
相比之下,DriveTransformer允许 ego 查询在一个统一的 Transformer 中同时与感知特征和图像特征进行全面交互。但该方法依然面临挑战:ego 查询在没有规划轨迹的先验信息情况下,通过全局注意力从多视角图像中提取有价值信息是非常困难的。
为了解决这一问题,本文提出使用结合物理位置的规划可变形注意力(planning deformable attention),以动态地采样靠近规划轨迹的图像特征。该机制可以轻松地整合进统一框架中,并与感知任务协同运行。
具体而言,我们设计了一个统一解码器,将包含来自检测任务(包括运动预测)、地图理解任务和规划任务的混合任务查询(hybrid task queries)作为输入。这使得规划和感知任务能够在 BEV 空间中相互交换信息,同时通过航点的几何先验,使规划查询可以与图像空间交互。
主要贡献
多粒度规划查询表示(multi-granularity planning query representation):HiP-AD 引入了一种多粒度的规划查询表示方法,整合了空间、时间和驾驶风格等多种采样模式下的异构路标点(heterogeneous waypoints)。这种表示为轨迹预测提供了额外的监督,增强了自车的精确闭环控制能力。
规划可变形注意力机制:利用规划轨迹的几何特性,HiP-AD 结合可变形注意力机制,实现了基于物理位置的图像特征有效检索。这种机制允许模型动态地从透视视图中提取相关的图像特征,提高了感知的准确性。
统一解码器架构(UniDecoder):HiP-AD 在一个统一的解码器中同时执行感知、预测和规划任务。通过在鸟瞰图(BEV)空间中,规划查询与感知查询的迭代交互,实现了全面的任务融合。
实现方法
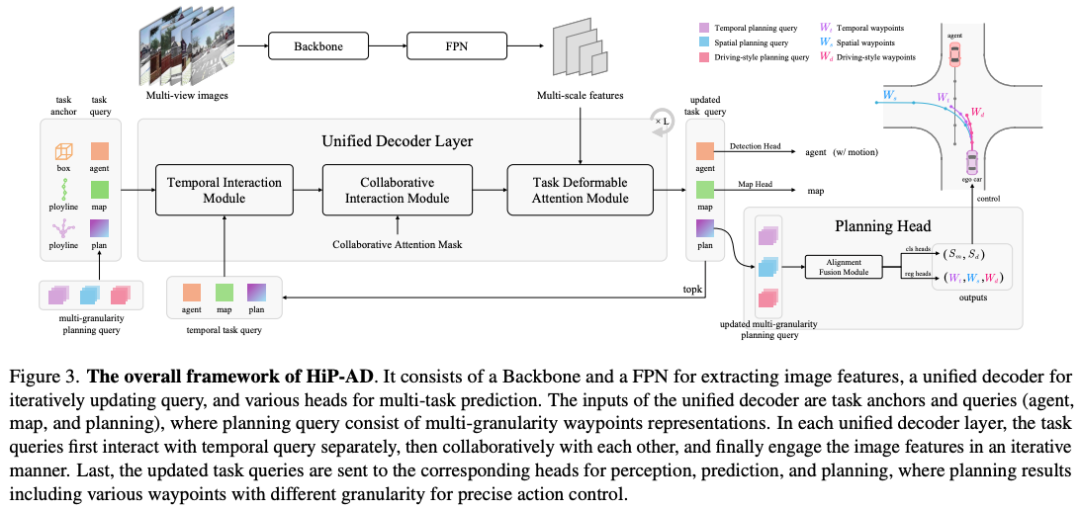
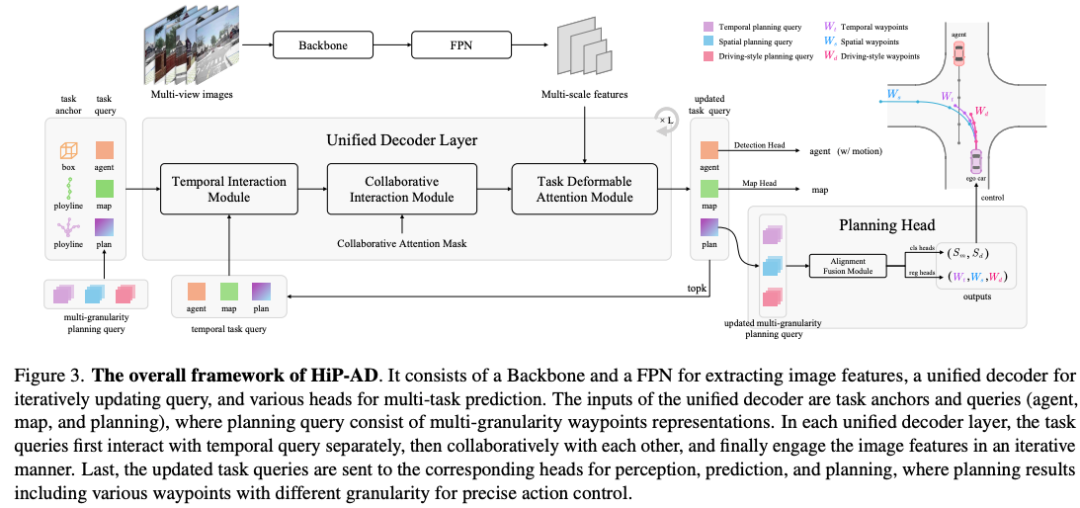
总体框架
HiP-AD 的整体网络结构如图 所示。它由一个骨干网络(backbone)组成,后接一个特征金字塔网络(FPN)模块,用于从多视角图像I中提取多尺度特征F。随后是一个统一解码器(unified decoder)以及多个特定任务的预测头。
这个统一解码器接收混合任务锚点(anchors)和查询(queries)作为输入,这些输入是以下几种查询的拼接结果:
智能体查询(agent queries)对应于目标检测和运动预测
地图查询(map queries) 在线地图构建
规划查询(planning queries)和轨迹预测任务
网络中的检测和运动预测头、地图理解头以及规划头分别用于完成各自的任务。其中,规划头会输出用于自动驾驶控制的时间、空间以及驾驶风格三类航点。此外,更新后的 top kak_aka、kmk_mkm、kpk_pkp 个查询会被保存在记忆模块中,用于后续的时序交互。
Unified Decoder
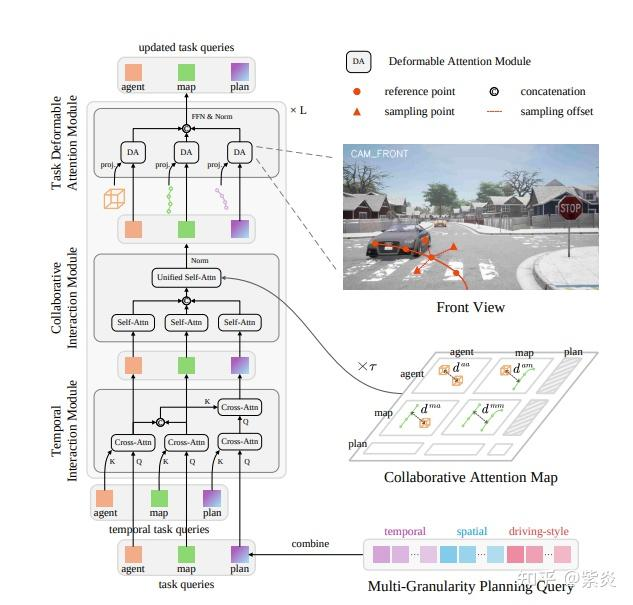
统一解码器(unified decoder)由三个模块组成:
时间交互模块(Temporal Interaction Module)
跨任务交互模块(Collaborative Interaction Module)
任务可变形聚合模块(Task Deformable Aggregation Module)
每个模块分别用于支持时间维度上的交互、不同任务之间的协同交互,以及任务与图像之间的特征交互。对于每个入的任务查询(task query),都关联有一个对应的锚点(anchor):
Agent query(智能体查询) 使用框型锚点(box anchors)Aa
Map query(地图查询) 使用折线型锚点(polyline anchors)表示,Am
Planning query(规划查询) 同样建模为折线型锚点,通过其未来 T个航点(waypoints)构建而成。Ap
时间交互(Temporal Interaction)时间交互模块用于建立当前任务特征与历史任务特征之间的通信。这些历史特征通过前一帧推理中 top-k 选择机制 被保留下来。如图左下角所示,该模块为每个任务的时间交互设计了三种不同的 跨注意力机制(cross-attention mechanisms),此外还包含一个 额外的跨注意力机制,专门用于增强 规划查询(planning query) 与 历史感知查询(temporal perception queries) 之间的交互,重点关注历史的周围环境元素。
协同交互(Collaborative Interaction)协同交互模块实现了跨任务交互。它包括三个独立的自注意力机制(self-attention mechanisms),每个机制专门负责一个任务,并且还包含一个统一的自注意力模块,用于在不同任务之间进行交互。不同于使用全局注意力(global attention),我们为每对查询构建了一个几何注意力图(geometric attention map),以便专注于局部和相对元素。以感知查询(perception query)为例,我们通过缩放距离作为注意力权重,动态调整 BEV 感受野(receptive fields)。
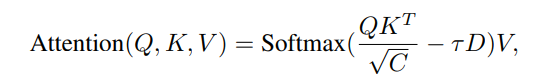
τ 是一个通过 MLP 函数从Q中学习得到的可学习系数。D 表示两个物体实例之间的欧几里得距离,类似地,我们将最小距离的计算扩展,用于生成注意力权重,通过引入地图-目标体(map-agent)、地图-地图(map-map)、目标体-地图(agent-map)锚点之间的交互来实现。对于规划查询(planning queries),没有距离限制,这使得它们能够从所有任务中获取信息。
任务可变形注意力(Task Deformable Attention)使用全局注意力与所有多视角图像特征进行交互的方法,我们采用了独立的可变形注意力模块,为每个任务查询提取局部稀疏特征,以更贴合各自任务的需求。具体而言,我们将任务锚点(task anchors)通过相机参数投影到多视角图像上,对于规划任务,我们将参考航点(reference waypoints)分布在多个预定义的高度值上,并将其投影到多视角图像上。为了采样周围点的特征,我们使用多个多层感知机(MLP)根据投影后的参考点来学习空间偏移量(spatial offsets)和相关权重(associated weights)。(Planning Deformable Attention, PDA)

P 是映射函数. 他整合了未来轨迹的特征,来表达场景特征,避免碰撞风险
分层与多粒度规划(Hierarchical and Multi-granularity Planning)
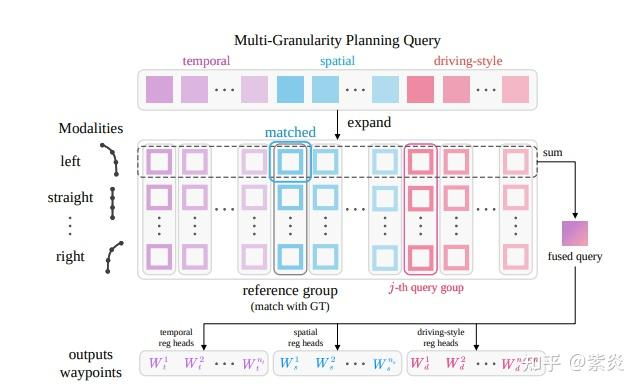
分层航点(Hierarchical Waypoints):文章使用了时间(temporal)和空间(spatial)航点,还引入了驾驶风格(driving-style)航点,虽然驾驶风格航点在形式上类似于时间航点,但它们进一步融合了速度信息,以便在复杂环境中更好地学习自车行为。此外,文章还引入了一种多采样策略(multi-sampling strategy),以实现丰富的轨迹监督和精细的控制。该策略结合了:
空间航点的稀疏与密集间隔;
时间与驾驶风格航点的高频与低频采样;
不同速度条件下的驾驶风格航点。
这样的设计使得稀疏间隔的航点可以提供更广泛的全局语义上下文,有助于更高层次的决策制定;而密集间隔的航点则支持更精细的操作控制。
时间与空间航点之间,以及高低频、稀密间隔采样策略之间,是互补关系,共同构建了更鲁棒、更高效的规划能力。此外,驾驶风格航点结合不同速度,能帮助模型更准确地理解如超车或紧急制动等场景,在闭环评估中提供更灵活的纵向控制能力。
多粒度规划查询(multi-granularity planning queries),用于预测这些异构航点(heterogeneous waypoints)。 时间粒度(temporal)查询;空间粒度(spatial)查询;驾驶风格粒度(driving-style)查询。当这些查询通过统一解码器(unified decoder)处理之后,同一模态下不同粒度的规划查询会被对齐并聚合,生成一个融合后的查询(fused query),从而增强信息的互补性与整体效果。最终,这个融合查询被用于预测所有粒度下的航点(waypoints),并借助额外的监督信号来进一步优化轨迹预测。
对齐匹配(Align Matching)
在训练过程中,我们在每个查询组内采用了赢家通吃(winner-takes-all的匹配方式来选择最优模态(modality)进行优化。每个查询组包含具有相同粒度(granularity)的所有模态。不同于为每组航点单独进行匹配的做法,我们提出了一种对齐匹配策略(align matching strategy),该策略指定某一组航点作为参考航点 并使用其对应的真实标签进行匹配。核心思想是:在训练轨迹预测时,为了减少模态间匹配混乱和提高效率,不是对所有模态独立匹配并优化,而是选定一个最优的模态(比如更接近 GT 的左转、右转或直行轨迹)作为“参照轨迹”进行训练优化,强化模型对正确轨迹模式的学习。这样能在多模态预测中聚焦于最有可能的真实行为。
实验结果
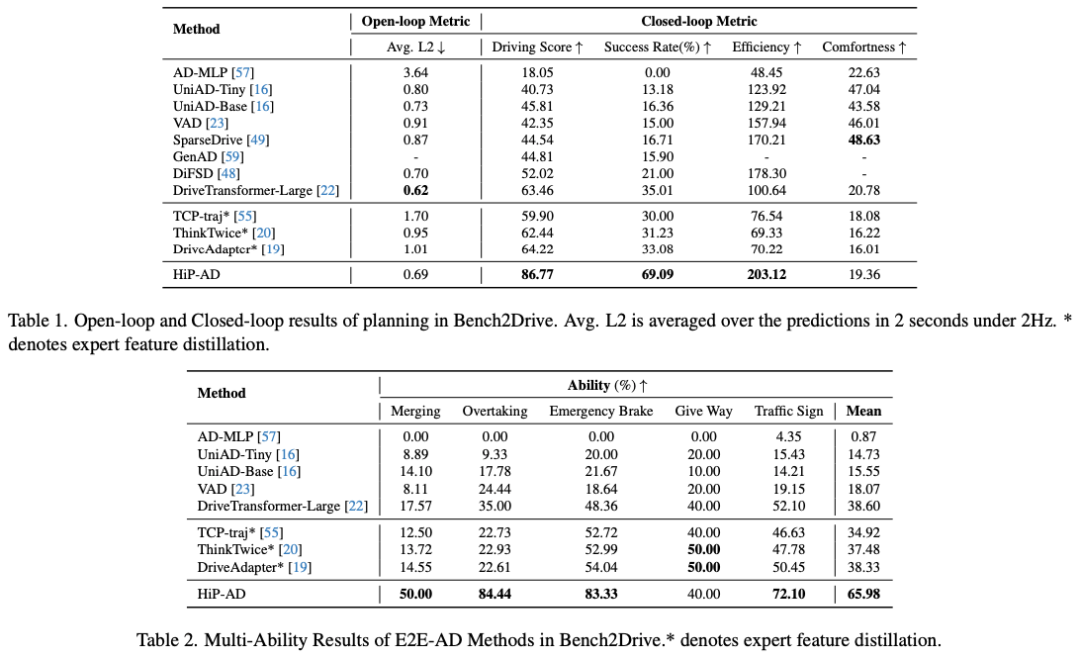
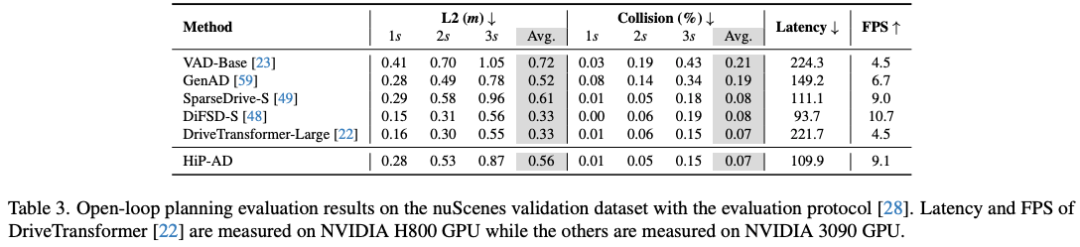
在闭环基准测试 Bench2Drive 上,HiP-AD 超越了所有现有的端到端自动驾驶方法,并在真实世界数据集 nuScenes 上取得了具有竞争力的表现。
技术亮点
规划查询与感知查询的交互:HiP-AD 允许规划查询与感知查询在 BEV 空间中进行迭代交互,增强了系统对环境的理解和预测能力。
动态特征提取:通过可变形注意力机制,模型能够根据规划轨迹的物理位置,从透视视图中动态提取相关的图像特征,提高了感知的准确性。
多任务融合:在一个统一的解码器中同时处理感知、预测和规划任务,减少了任务之间的信息损失,提高了整体系统的效率和性能。
自动驾驶之心
论文辅导来啦

知识星球交流社区
近4000人的交流社区,近300+自动驾驶公司与科研结构加入!涉及30+自动驾驶技术栈学习路线,从0到一带你入门自动驾驶感知(大模型、端到端自动驾驶、世界模型、仿真闭环、3D检测、车道线、BEV感知、Occupancy、多传感器融合、多传感器标定、目标跟踪)、自动驾驶定位建图(SLAM、高精地图、局部在线地图)、自动驾驶规划控制/轨迹预测等领域技术方案、大模型,更有行业动态和岗位发布!欢迎加入。

独家专业课程
端到端自动驾驶、大模型、VLA、仿真测试、自动驾驶C++、BEV感知、BEV模型部署、BEV目标跟踪、毫米波雷达视觉融合、多传感器标定、多传感器融合、多模态3D目标检测、车道线检测、轨迹预测、在线高精地图、世界模型、点云3D目标检测、目标跟踪、Occupancy、CUDA与TensorRT模型部署、大模型与自动驾驶、NeRF、语义分割、自动驾驶仿真、传感器部署、决策规划、轨迹预测等多个方向学习视频
学习官网:www.zdjszx.com

















 6699
6699

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









