






点击下方卡片,关注“具身智能之心”公众号
编辑丨具身智能之心
本文只做学术分享,如有侵权,联系删文
更多干货,欢迎加入国内首个具身智能全栈学习社区:具身智能之心知识星球(戳我),这里包含所有你想要的。
VLA现有模型的缺点
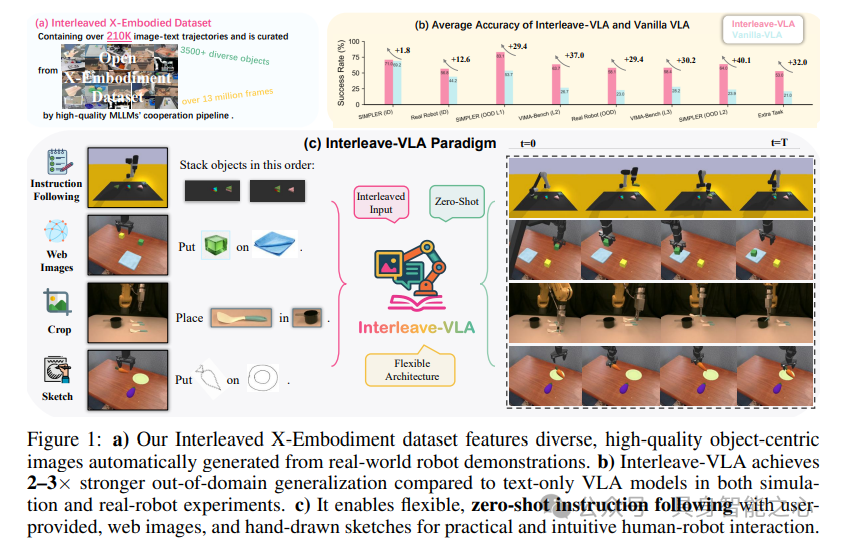
VLA模型在物理世界的通用机器人操作方面展现出巨大潜力。然而,现有模型局限于机器人观测和纯文本指令,缺乏数字世界基础模型最新进展所带来的交错式多模态指令灵活性。这里提出Interleave-VLA,首个能够理解交错式图文指令并在物理世界中直接生成连续动作序列的框架。它提供了一种灵活的、与模型无关的范式,只需对最先进的VLA模型进行最小程度的修改,就能显著提升零样本泛化能力。实现Interleave-VLA面临的一个关键挑战是缺乏大规模交错式具身数据集。为了填补这一空白,开发了一种自动流程,将Open X-Embodiment中真实世界数据集的纯文本指令转换为交错式图文指令,从而创建了首个包含21万个情节和1300万帧的大规模真实世界交错式具身数据集。通过在模拟基准测试和真实机器人实验中的全面评估,证明了Interleave-VLA具有显著优势:
1)与最先进的基线模型相比,它对未见物体的跨领域泛化能力提高了2 - 3倍;
2)支持灵活的任务接口;
3)能够以零样本方式处理用户提供的各种图像指令,如手绘草图。
这里也进一步分析了Interleave-VLA强大零样本性能背后的因素,发现交错式范式有效地利用了异构数据集和多样的指令图像,包括来自互联网的图像,这显示出强大的扩展潜力。
背景介绍
大语言模型(LLMs)和视觉 - 语言模型(VLMs)取得的显著成功,确立了数字世界基础模型的范式,这些模型能够在广泛的任务和领域中进行泛化。受此启发,机器人领域正积极开发机器人基础模型,旨在将类似的泛化能力引入物理实体世界,以应对未见的任务和场景。然而,尽管交错式多模态输入在数字基础模型中已证明有效,但如今大多数机器人策略仍仅接受观测图像和基于文本的指令,这落后于能够无缝处理混合模态序列并在灵活任务接口间进行泛化的VLMs。例如,用户可能希望机器人 “拿起像这样的物体”,同时指向一个形状不规则或颜色独特的物体。用语言描述这样的目标可能既繁琐又模糊。相比之下,交错式图文指令为传达此类目标提供了一种更直观、精确且可泛化的方式。
机器人操作的交错式指令概念最早由VIMA在模拟环境中探索,它引入了VIMA-Bench来研究用于2D物体姿态估计的视觉语言规划。由于VIMA的动作空间为高级2D空间,它主要侧重于接口统一,而未充分探索交错式指令的更广泛优势,如增强的泛化能力或在实际机器人低级动作中的适用性。因此,由于缺乏真实世界的数据集和能够处理此类输入的策略,这种范式的实际价值尚未得到充分挖掘。
为了开发一种通用且实用的机器人策略,使其能够在真实世界中基于交错式图文指令执行动作,一种直接的解决方案是在VLA模型的基础上进行构建。VLA模型通过整合动作理解和生成,自然地扩展了VLMs,使其非常适合机器人任务。然而,现有的VLA模型主要使用纯文本指令进行训练。这限制了它们从多模态指令信号中获益的能力,而多模态指令信号已被证明可以增强视觉语言学习中的泛化能力。这种限制不仅降低了指令的灵活性,还阻碍了这些模型利用交错式多模态信号所提供的更丰富语义和更好的基础。为了解决这一限制,我们提出了一种名为Interleave-VLA的新范式,这是一种简单且与模型无关的扩展,使VLA模型能够处理和推理交错式图文指令。
高质量的图文交错数据集对于训练Interleave-VLA至关重要。为了填补机器人操作领域缺乏图文交错数据集的空白,我们开发了一种流程,用于从现有数据集自动构建交错式指令。所提出的流程能够从真实世界的Open X-Embodiment数据集中自动、准确地生成交错式指令。由此产生的交错式数据集包含超过21万个情节和1300万帧,成为首个大规模的真实世界交错式具身数据集。这使得能够使用真实世界的交互数据和多样的视觉指令类型来训练Interleave-VLA。
通过对两个领先的VLA模型OpenVLA和π₀进行最小架构更改,展示了Interleave-VLA的有效性,因此该范式可广泛应用于未来的VLA模型。实验结果表明,Interleave-VLA在处理领域内和领域外任务时,始终优于其纯文本对应模型。值得注意的是,交错式格式实现了对新物体甚至训练数据集中从未见过的用户提供的草图的强大零样本泛化,突出了提出方法的稳健性和灵活性。
核心贡献如下:
引入了一种全自动流程,将纯文本指令转换为图文交错指令,基于Open X-Embodiment创建了首个大规模的真实世界交错式具身数据集,包含21万个情节和1300万帧。
提出了Interleave-VLA,这是一种简单、可泛化且与模型无关的适配方法,通过最小的架构更改,使VLA模型能够处理交错式图文指令。它代表了首个能够处理交错式输入的端到端机器人策略,标志着该范式首次扩展到物理VLA模型。
通过在SIMPLER、VIMA-Bench和真实机器人环境中对Interleave-VLA进行全面评估,证明了其在领域内任务上的持续改进,对新物体的跨领域泛化能力提升了2 - 3倍,同时还展现出对各种用户提供的视觉指令(如手绘草图)的零样本解释能力。
相关工作介绍
交错式视觉语言模型
在数字领域,视觉语言模型的最新进展已从处理简单的图像文本对发展到能够处理任意交错的图像和文本序列。这种交错式格式使模型能够利用大规模的多模态网络语料库,如新闻文章和博客,其中图像和文本自然地以混合序列出现。此类模型展示出了更高的灵活性和泛化能力,能够在不同的任务和模态之间进行迁移。尽管在数字世界中取得了这些成功,但物理世界中的机器人基础模型尚未充分利用交错式图文指令的优势。受交错式VLMs进展的启发,我们将这一范式扩展到动作模态,使视觉语言动作模型能够处理交错式指令。结果表明,使用交错式输入的多模态学习极大地提高了泛化能力,并在机器人操作任务中展现出新兴能力。
VLA模型
视觉语言动作(VLA)模型通过使策略能够基于视觉观测和语言指令进行调整,推动了机器人操作的发展。大多数先前的VLA模型使用纯文本指令处理单幅或多幅观测图像,也有一些探索了如3D和音频等额外模态。VIMA率先在机器人操作中使用交错式图文提示作为统一接口,主要在模拟环境中进行。然而,其重点局限于接口设计,没有系统地探索交错式指令的更广泛优势,如增强的泛化能力和真实世界适用性。因此,迄今为止,大多数VLA模型仍然依赖纯文本指令。在这项工作中,我们迈出了填补这一差距的第一步,提出Interleave-VLA:一种简单的、与模型无关的范式,通过最小的修改扩展现有VLA模型,以支持交错式图文指令。综合实验表明,交错式指令显著提高了对未见物体和环境的泛化能力,并为处理各种用户提供的输入解锁了强大的零样本能力。这突出了交错式图文指令在真实世界机器人操作中的实用价值和可扩展性。
Interleave-VLA和开放交错式跨实体数据集
问题公式化
数字基础模型可以将任意交错的图像、视频帧和文本作为输入来处理多模态提示,并输出文本。对于机器人基础模型而言,这个范式自然延伸为:模型接收一个多模态提示,并在机器人的动作空间中输出一个动作。例如:
常规指令:<观测>将[微波炉附近的蓝色勺子]放入[毛巾上的银色锅]中。
交错式指令:<观测>将[图片1]放入[图片2]。其中<观测>是观测图像,[图片1]和[图片2]分别是代表目标物体和目的地的图像。
Interleave-VLA
Interleave-VLA框架基于观测 对动作分布 进行建模。这里, 是观测图像, 是机器人的本体感受状态,(I)是图文交错指令。指令(I)是一个混合了文本段 和图像 的序列,即 。现有的使用文本指令的VLA是一种特殊情况,即 ,仅包含一个文本段。
Interleave-VLA是对现有VLA模型的一种简单而有效的改进。它修改了输入格式以接受交错的图像和文本tokens,而不改变核心模型架构。通过改进两个最先进的视觉语言动作(VLA)模型来展示这种方法。对于OpenVLA,用InternVL2.5替换了原来的Prismatic VLM骨干网络,InternVL2.5原生支持图文交错输入。对于π₀,保留了原来的架构,仅调整了输入管道以处理交错token。值得注意的是,即使底层的Paligemma VLM没有在交错数据上进行训练,Interleave-π₀仍然可以通过训练有效地处理交错指令。这种与模型无关的改进在架构上只需进行最小的更改,并且显著增强了基础模型的零样本泛化能力,正如实验所示。
(三)开放交错式跨实体数据集的构建
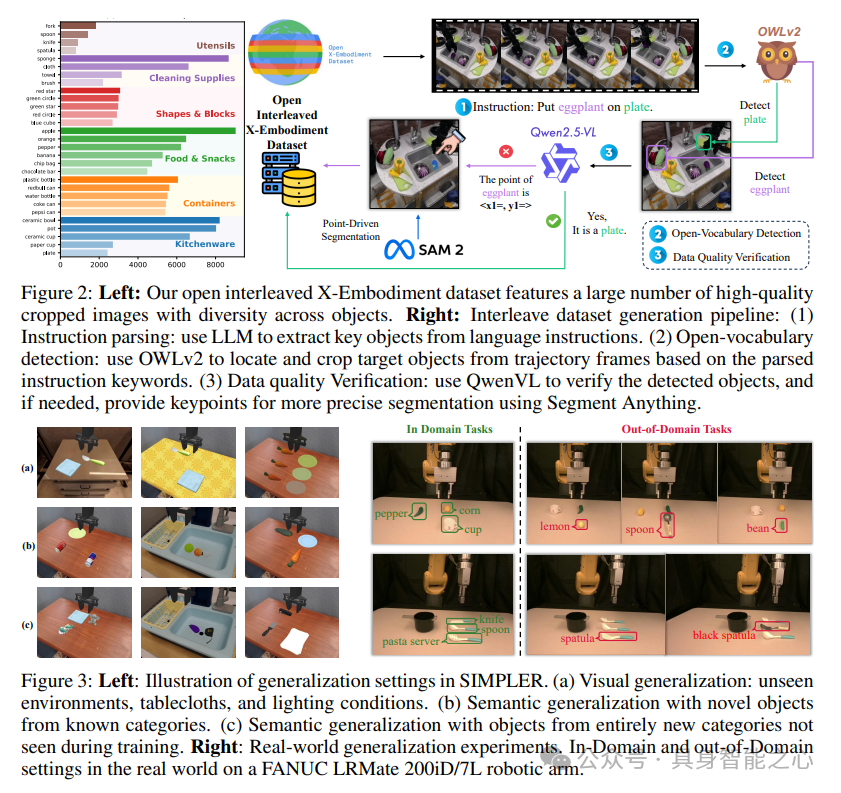
大规模的预训练数据集对于视觉语言动作(VLA)模型学习动作和进行泛化至关重要,OpenVLA和π₀的研究已证实这一点,Interleave-VLA也是如此。然而,目前大多数真实世界的数据集仅提供基于文本的指令,因此无法直接支持训练Interleave-VLA模型。因此,我们设计了一个统一的流程,用于在不同的数据集中自动重新token并生成交错数据。
整体数据集生成流程主要包括三个步骤:指令解析、开放词汇检测和数据质量验证。首先,在指令解析阶段,我们使用Qwen2.5从语言指令中提取关键对象。与基于规则的自然语言处理工具(如SPaCy)相比,大语言模型(LLM)的提示方法更加稳健,能够更好地适应各种指令格式。它还能够对复杂或冗长的指令进行简洁的总结。其次,在开放词汇检测阶段,我们使用最先进的开放词汇检测器OWLv2,根据解析出的指令关键词在轨迹帧中定位并裁剪目标对象,在大多数情况下,其准确率超过99%。最后,对于OWLv2检测失败的更具挑战性的情况,我们引入数据质量验证:Qwen2.5-VL对检测到的对象进行验证,如有需要,使用Segment Anything提供关键点以进行更精确的分割。这种组合方法将具有挑战性的对象(如茄子)的裁剪准确率从低于50%提高到95%,确保为下游任务提供高质量的交错数据。
将数据集生成流程应用于Open X-Embodiment中的11个数据集:RT-1、伯克利自动实验室UR5、卡内基梅隆大学IAM实验室拾取插入数据集、斯坦福Hydra、德克萨斯大学奥斯汀分校Sirius、Bridge、Jaco Play、加州大学圣地亚哥分校厨房数据集、BC-Z、语言桌数据集、德克萨斯大学奥斯汀分校Mutex,从而形成了现实世界中首个大规模交错式跨实体数据集。经过整理的数据集包含21万个情节和1300万帧,涵盖3500个独特对象和广泛的任务类型。
实验论证
在实验中旨在探讨以下问题:(1)Interleave-VLA与普通VLA相比,在域内和域外的性能如何?它对未见物体和环境的泛化能力怎样?(2)Interleave-VLA还展现出哪些额外的新兴泛化能力?(3)Interleave-VLA有扩展的潜力吗?
实验设置与任务
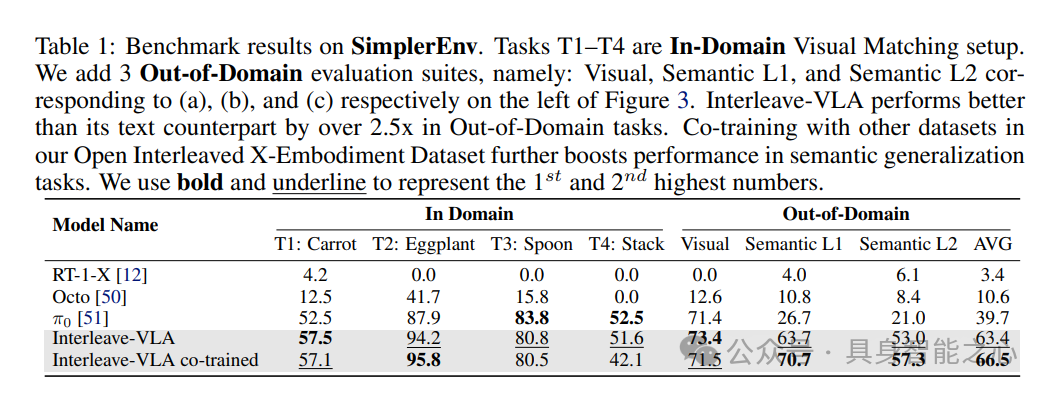
实验环境:在基于模拟器的评估和真实机器人评估中,对Interleave-VLA及其纯文本版本的对应模型进行了全面实验。我们采用SIMPLER和VIMA-Bench作为模拟环境。SIMPLER旨在紧密模拟现实世界的任务,缩小现实与模拟之间的差距。对SIMPLER进行了适配,使其支持交错图像文本指令,这样就能在真实的环境中评估Interleave-VLA模型的性能。VIMA-Bench旨在测试基于规划器的任务中模型遵循交错指令的能力,主要评估模型在物体识别和多任务理解方面的表现。还在配备SMC夹爪的FANUC LRMate 200iD/7L机械臂上进行了真实机器人实验。
实验任务:在SIMPLER中,在WidowX机器人的视觉匹配场景下进行评估。这个场景通过使训练和模拟评估的分布与现实世界紧密匹配,来测试模型的域内能力。为了全面评估泛化能力,依据Stone等人的研究设计了两类主要任务:视觉泛化和语义泛化。视觉泛化用于评估模型对新的桌布、光照和环境的鲁棒性。语义泛化则评估模型在存在各种干扰物的情况下,正确识别和操作目标物体的能力。该评估进一步分为两类:(1)来自先前见过类别的新颖物体;(2)来自全新未见类别的物体。在VIMA-Bench中,除了原始任务外,还引入了三个新任务,以展示Interleave模型能够有效地解释基于草图的指令,这是一种对人机交互友好的方式。在真实机器人实验中,我们评估了两种不同的操作任务:(1)“拿起胡椒/玉米/杯子”并泛化到“豆子/柠檬/杯子”;(2)“将意大利面勺/勺子/刀放入锅中”并泛化到“抹刀/黑色抹刀”。
(二)模拟性能
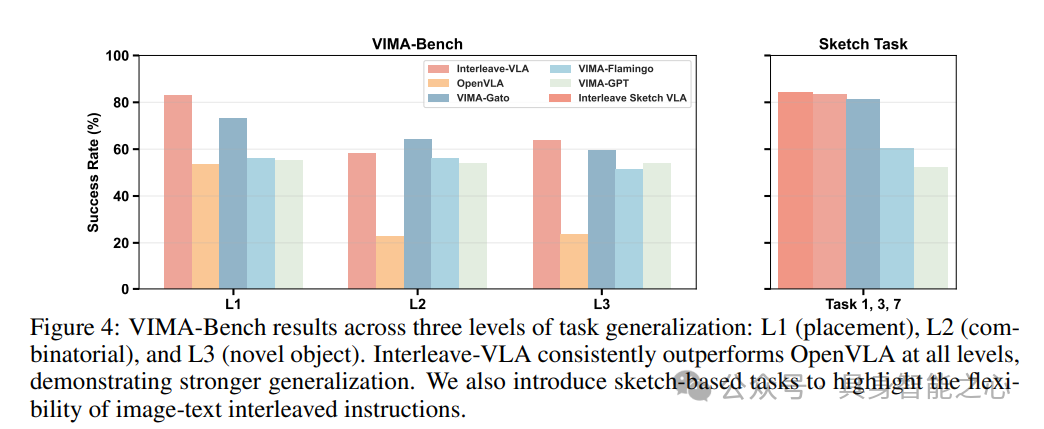
在SIMPLER中,将最先进的VLA模型π₀改进为Interleave-VLA,以支持交错指令。为了公平比较,Interleave-VLA和其他基线模型都在完整的Bridge Data V2上进行训练,Interleave-VLA使用交错版本的数据。结果表明,交错指令不仅提高了标准域内任务的性能,更重要的是,使模型对语义域外任务的泛化能力提升了2至3倍。为了探究交错跨实体数据集的优势,我们展示了使用我们的开放交错跨实体数据集进行联合训练的Interleave-VLA版本。尽管Bridge Dataset V2已经规模庞大且数据多样,进一步提升性能颇具挑战,但在语义泛化方面仍有额外的提升,这证实了交错训练能够实现跨实体技能迁移。详细结果见表1。
在VIMA-Bench中,将另一个最先进的VLA模型OpenVLA改进为Interleave-VLA以支持交错指令,展示了方法的广泛适用性。将Interleave-VLA与为交错指令输入而适配的端到端VLA模型(Gato、Flamingo、GPT)进行基准测试。结果表明,Interleave-VLA在所有泛化级别上的表现始终优于原始的OpenVLA,平均性能提高了两倍多。除了标准的VIMA-Bench任务外,还引入了三个新任务,在训练和评估中都使用草图,进一步突出了Interleave-VLA在处理多样指令模态方面的灵活性。需要注意的是,VIMA未参与比较,因为它依赖于单独训练的检测器来提供边界框,而端到端VLA模型无法获取这些边界框。
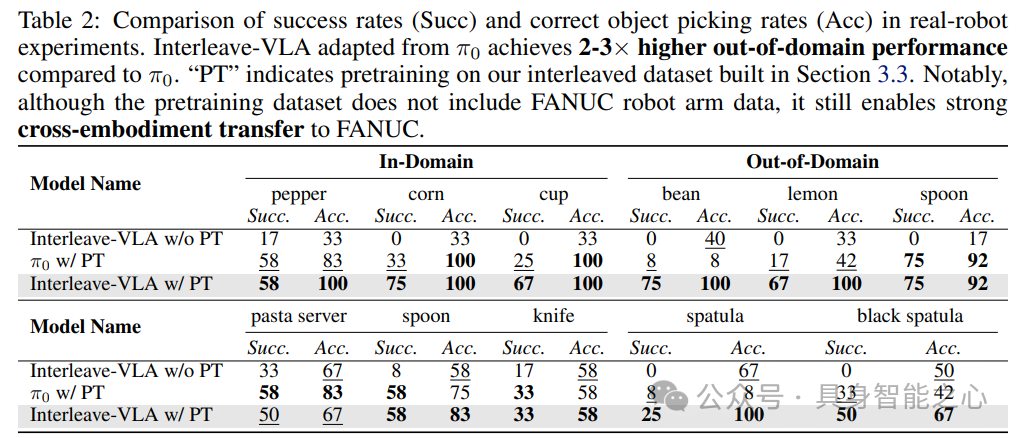
(三)真实机器人性能
在真实机器人实验中,评估了两组物体,使用空间鼠标为每个物体收集了20个远程操作演示。如表2所示,从π₀改进而来的Interleave-VLA与纯文本的π₀相比,在域外性能上提高了2至3倍。与SIMPLER实验不同,在SIMPLER实验中,在大规模的Bridge Data V2上进行训练能够直接实现强大的性能,而FANUC机器人实验仅限于一个小得多的数据集。在这种低数据条件下,直接训练π₀效果不佳。然而,在我们的开放交错跨实体数据集上进行预训练能够实现强大的跨实体迁移,显著提升性能。这种交错图像文本指令带来的新兴迁移能力与之前纯文本指令的研究结果一致。这种强大的跨实体迁移非常重要,因为它减少了对昂贵且耗时的大规模演示收集的需求。
(四)Interleave-VLA的泛化和新兴能力分析
1. Interleave-VLA的任务灵活性和新兴泛化能力
在多样的操作任务中,VIMA引入的交错格式提供了一个统一的基于序列的接口。Interleave-VLA有效地处理了VIMA-Bench中的任务,包括目标图像匹配和多步指令跟随(例如任务4和任务11),在这些任务中必须按顺序处理多个目标图像。这些结果证实了图像文本交错指令在通用机器人操作中的灵活性和有效性。
接下来评估交错格式在现实世界场景中的泛化能力,超越了VIMA-Bench中干净的模拟环境和高级的SE(2)动作空间,在SIMPLER和真实机器人实验中进行测试。结果(表1和表2)一致表明,Interleave-VLA在各种任务中,尤其是在具有未见物体和干扰物的具有挑战性的域外场景中,比纯文本基线模型具有更强的泛化能力。
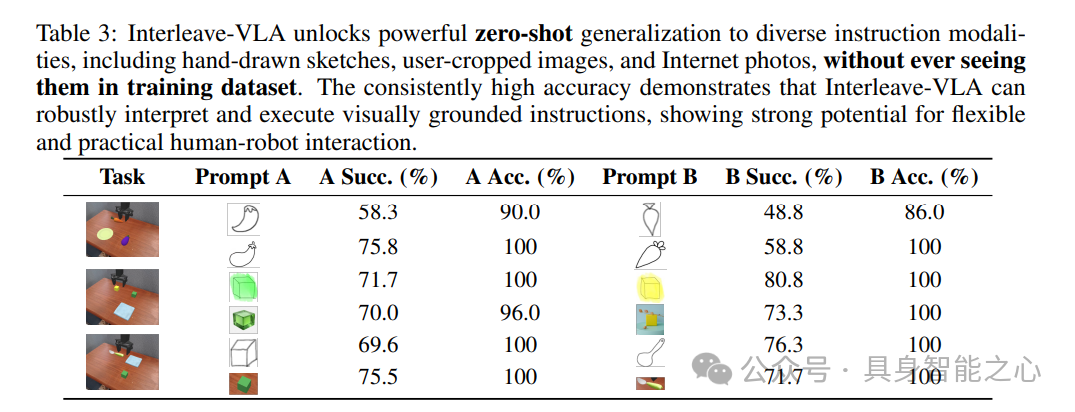
值得注意的是,Interleave-VLA展现出了一种显著的新兴能力:它允许用户以完全零样本的方式灵活指定指令,而无需对未见的输入模态进行任何额外的微调。表3展示了图像指令类型的示例及其相应的高成功率。指令可以采用多种格式,包括:(1)裁剪图像指令:用户可以直接从屏幕上裁剪一个区域来指示目标物体。(2)网络图像指令:用户可以提供任何图像,例如从互联网上检索到的照片,来代表所需的物体。(3)手绘草图指令:用户可以绘制关于物体的草图或卡通画。
交错指令格式自然地适应了这些多样的输入,从而增强了人机交互的直观性,消除了用精确文本明确命名、分类或描述物体的需求。在域内和域外任务中获得的显著性能提升,凸显了交错图像文本指令对于构建更具适应性和实用性的机器人系统的重要性。
2. Interleave-VLA训练:交错多样性的重要性
Interleave-VLA比标准VLA模型具有更强的泛化能力,这得益于从图像文本交错格式中进行的多模态学习。模拟实验和真实世界实验结果中都有直接体现。我们确定了驱动这种零样本泛化的两个关键因素:(1)训练数据集的规模和多样性;(2)提示图像的多样性。
实验表明,训练数据集的规模和多样性对于Interleave-VLA的强大性能至关重要,尤其是在域外泛化方面。当域内数据集有限时(例如真实机器人实验;见表2),在大规模数据集上进行预训练至关重要,没有这种预训练的模型表现会明显更差。当域内数据集规模大且多样时(例如SIMPLER;见表1),进一步提升性能本应更具挑战性,但纳入跨实体数据仍可以进一步提高语义泛化能力,并增强域外的鲁棒性。这表明跨实体联合训练对Interleave-VLA有益,与Open X-Embodiment的研究结果一致。研究结果凸显了我们大规模的开放交错跨实体数据集在使Interleave-VLA模型在不同规模的域内数据条件下都具有强大且可泛化能力方面的关键作用。

对于提示图像的多样性,表4表明,将网络图像与从机器人观测中裁剪的特定任务图像相结合,可获得最佳的整体性能。仅使用网络图像会由于任务相关性有限而导致域内准确率较低,而仅依赖裁剪图像虽然可以提高域内结果,但缺乏多样性。混合这两种来源具有互补优势,从而提高了准确率并增强了泛化能力。
局限性分析
虽然Interleave-VLA实现了强大的泛化能力,但由于图像token长度增加,使用交错输入进行训练在计算上要求更高,并且通常需要更多的训练步骤才能收敛。未来的工作可以集中在压缩图像token以提高效率。此外,构建一个真正的机器人基础模型可能需要支持交错输出以及输入。最近的研究表明,与动作一起生成文本或未来图像可以进一步提升VLA的性能。因此,开发具有交错输入和输出的统一VLA模型是一个有前途的研究方向。
参考
[1] Interleave-VLA: Enhancing Robot Manipulation with Interleaved Image-Text Instructions.
论文辅导计划

具身智能干货社区
具身智能之心知识星球是国内首个具身智能开发者社区,也是最专业最大的交流平台,近1500人。主要关注具身智能相关的数据集、开源项目、具身仿真平台、VLA、VLN、具身大脑、具身小脑、大模型、视觉语言模型、强化学习、Diffusion Policy、机器臂抓取、姿态估计、策略学习、轮式+机械臂、双足机器人、四足机器人、大模型部署、端到端、规划控制等方向。星球内部为大家汇总了近30+学习路线、40+开源项目、近60+具身智能相关数据集。

全栈技术交流群
具身智能之心是国内首个面向具身智能领域的开发者社区,聚焦大模型、视觉语言导航、VLA、机械臂抓取、Diffusion Policy、双足机器人、四足机器人、感知融合、强化学习、模仿学习、规控与端到端、机器人仿真、产品开发、自动标注等多个方向,目前近60+技术交流群,欢迎加入!扫码添加小助理微信邀请入群,备注:学校/公司+方向+昵称(快速入群方式)。


















 783
783

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









