









提出来金字塔CNN(PCNN)做人脸识别,使用greedy-filter-and-down-sample算子,在多尺度上特征共享描述人脸,学习到的8维特征在LFW数据库测试达到97.3%的结果。
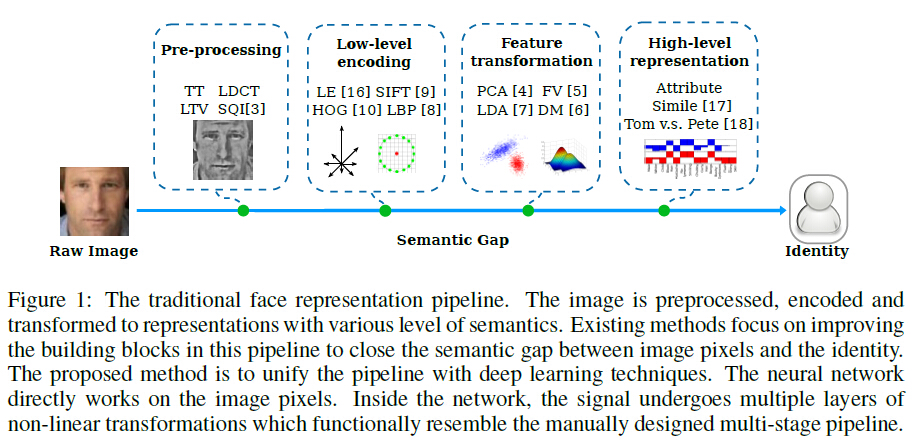
传统的人脸识别步骤有预处理,低层编码,特征转换,高层特征表示。深度网络将这些步骤一体化,直接对图像像素进行分析,信号经历多层非线性变换,与人工设计的多步骤方法类似。
人脸描述是从图像像素映射到数值向量
f:Rh×w→Rm
好的人脸描述方法标准
Indentity-preserving
Abstract and compact
Uniform and automatic
一般通过监督学习最小化损失L实现,非监督学习也能够挖掘出数据的模式,但他们的优化目标与识别任务不直接相关,因此学习到的表示容易受到光照,表情和姿态的影响。
Pyramid CNN
1.Indentity-preserving学习
对人脸对进行学习,属于或不属于同一个人的人脸对由相集得到。使用Siamese网络处理人脸对,使用同一个CNN处理两张图片生成对应的表示。输出节点使用距离函数比较两个图片的表示,预测图像对是否属于同一个人,损失函数是:
L=∑I1,I2log(1+exp(δ(I1,I2)D(I1,I2)))
D(I1,I2)=α⋅d(fθ(I1),fθ(I2))−β
其中
δ(I1,I2)
表示两个图像是否是同一个人,
fθ
为神经网络计算出的结果,d是衡量两个向量间距离的函数。
θ
是网络的权值,
α,β
是可训练的参数。
2.网络结构
卷积网络是高阶非线性实值多方差函数,由多层卷积和下采样实现:
Ii+1=Pmax(g(Ii⨂Wi+Bi))
g是非线性激活函数,卷积及下采样算子为:
(Ii⨂Wi)x,y,z=∑a,b,c,zIix−a,y−b,cWia,b,c,z
Pmax(Ii)x,y=max0<=a,b<sIixs+a,ys+b
金字塔CNN的目的是加速深度网络的训练,并使用人脸的多尺度结构。下图是PCNN的结构。
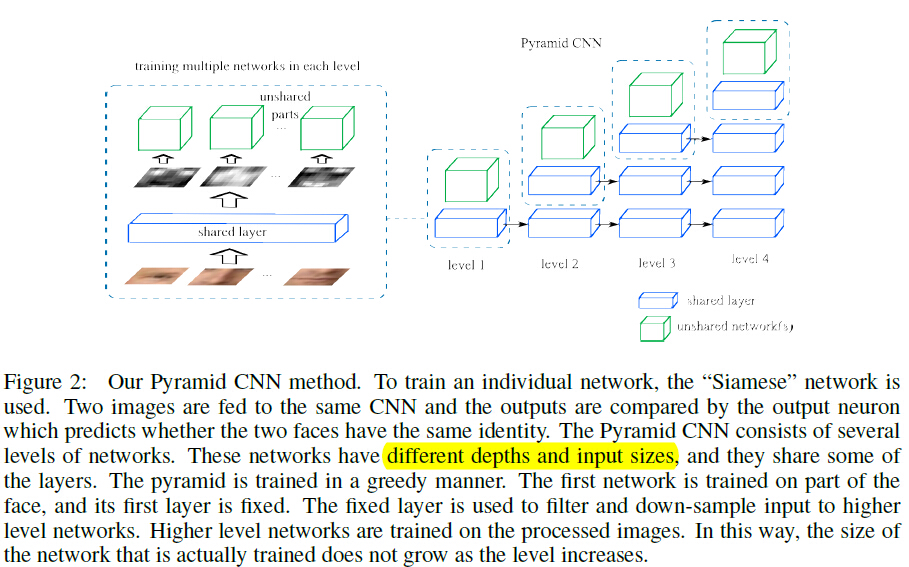
每个网路包含共享部分和非共享部分,非共享部分每级的结构相同。同一级上可能有多个网络,它们活跃在不同的区域上并共享他们第一层的参数,用来补偿低层网络对输入区域的低聚合特性。
训练过程可分解为训练几个小型的网络:

第一级的网络比较小,在人脸的局部区域上训练。训练完第一级后,第一层固定,固定层用来滤波及下采样训练图像。第二级网络在处理后的图像上训练。这样网络输入的大小不随着层级的增加而增加,这个训练步骤持续到所有的级被训练到。
PCNN是一个多尺度特征提取框架,不同尺寸的图像块将在不同的尺寸级输入到网络。
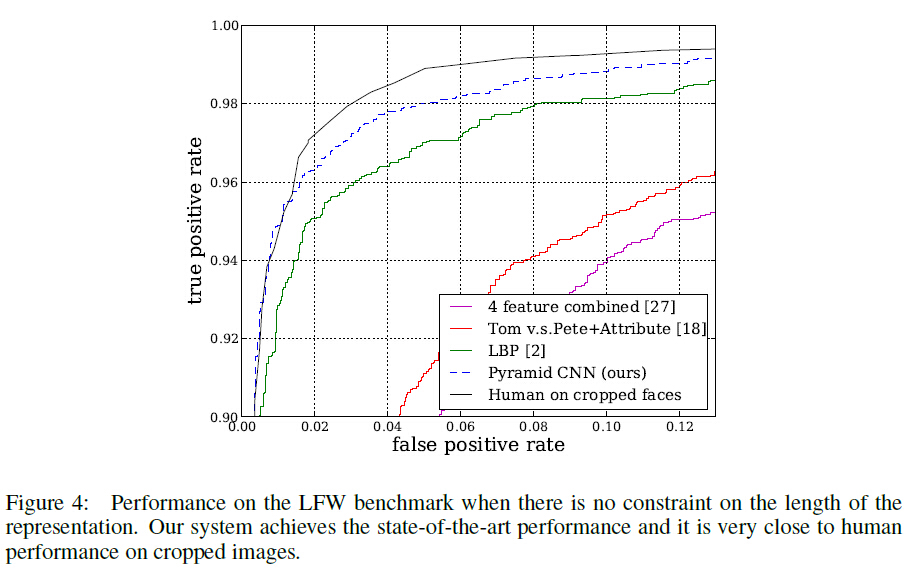
实验结果
在LFW上的实验结果如下:















 9077
9077











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









